BaseInfo
| Title | SAM2 for Image and Video Segmentation: A Comprehensive Survey |
| Adress | https://arxiv.org/abs/2503.12781 |
| Journal/Time | 2503 |
| Author | 四川大学,北京大学 |
1. Introduction
图像分割专注于识别单个图像中的目标、边界或纹理,而视频分割则将这一过程扩展到时间维度,旨在分割连续的视频帧,同时确保时空一致性。
大规模基础模型的出现彻底改变了人工智能研究领域,展现出卓越的零样本和少样本学习能力 。
首先,由于 SAM 的预训练主要依赖自然图像 ,它难以有效地适应其他领域,从而导致准确率降低。其次,SAM 主要在 2D 图像上进行训练,这限制了其在处理 3D 医学图像和其他复杂数据类型时的性能 。最后,SAM 在处理视频分割任务时遇到困难,因为视频数据中的时间连续性和动态特征与静态图像的要求有很大差异 。
- 全面回顾了分割的基础概念、基础模型的概念与分类,以及 SAM 和 SAM2 的技术特点。我们还讨论了将 SAM/SAM2 拓展到其他领域的努力。
- 总结当前的研究进展,并在视频和静态图像这两个主要方面评估 SAM2 的分割性能。在分析其在自然图像上的性能时,我们特别强调其在医学专业领域的应用,因为其他专业领域的研究仍然有限。
- 总结 SAM2 在图像和视频分割中的特点,讨论当前的技术挑战,并探索未来的发展方向。
2. 预备知识
- 图像分割:被定义为用语义标签对像素进行分类的任务(语义分割),将单个对象(实例分割)进行划分,或同时处理这两项任务(全景分割)。交互式分割使用户能够通过提供输入和反馈,参与分割过程。
- 视频分割:视频对象分割(VOS)分离视频中的特定对象,而无需详细的语义标注 ,视频语义分割(VSS)每个像素分配预定义的语义类别(如 “人” 或 “车”),同时确保帧间的标签一致性。
零样本学习在几乎没有训练样本的情况下执行分割任务,而少样本学习仅使用少量标记样本就能使模型有效训练。
2.2 基础模型 FMs
在大规模数据集上进行预训练、在特定任务中表现良好的机器学习模型 。大规模预训练、泛化能力和可迁移性。
- 视觉基础模型:统一处理各种视觉任务。这些模型通常在大规模数据集上进行预训练,通过多任务微调学习丰富的视觉特征,从而增强其在多个领域的性能 。CLIP 、ViT
- 通用分割模型:旨在处理各种类型的图像分割任务,能够有效地应对不同的输入和任务类型 。SAM、 SAM2
- 专用模型专注于特定任务,而基础模型可以处理更广泛的任务范围,无论是在单个领域还是跨多个学科 。
2.3 图像分割的演变

- SAM主要由三个主要组件构成:图像编码器、掩码解码器和提示编码器。图像编码器对 MAE预训练的视觉 Transformer(ViT) 进行了最小程度的调整,以处理高分辨率输入。提示编码器通过纳入位置编码来处理各种用户输入,如点、框或文本,从而引导分割过程。它将这些提示编码为与图像特征空间对齐的特征,以便在分割过程中实现无缝集成和有效引导。掩码解码器使用经过修改的 Transformer 解码器模块,随后是动态掩码预测头,以生成将分割掩码与提示嵌入有效结合的嵌入。
- SAM2 是一种先进的视觉分割模型,它在其前身 SAM 的基础上进行构建,通过纳入基于 Transformer 的架构与流式记忆组件相结合。这一增强功能使 SAM2 能够支持实时视频分割和对象跟踪,以应对移动场景带来的动态挑战。SAM2 的架构针对实时视频分割和对象跟踪进行了优化,分层图像编码器对每一帧执行初始特征提取,生成未编码的特征,并在每次交互后运行内存表示。记忆注意力模块通过将当前帧特征与过去帧的特征以及任何新提示进行对比,利用高效的自注意力和交叉注意力机制,从过去帧中调节时间上下文。为处理用户输入,提示编码器(与 SAM 相同)将提示(如点、框或掩码点击)作为正或负信号进行包围。然后,掩码解码器(类似于 SAM)使用分割头将这些信号与图像特征相结合,生成最终的分割掩码,保持了 SAM 方法的连续性。记忆编码器通过对输出掩码进行下采样并将其与无条件层嵌入相结合来优化记忆特征,通过轻量级卷积层实现。最后,memory bank 存储预测结果,提高准确性并减少用户输入。
- SAM 和 SAM2 在适用范围、架构以及实际应用场景方面存在显著差异。SAM2 增加了 a streaming memory component,包括 图像编码器、记忆注意力模块和memory bank。SAM 通常用于单帧分割任务,如对象识别,而 SAM2 支持跨视频序列的对象跟踪,使其特别适用于需要时间连续性的场景,如视频编辑和动态对象检测,尤其是在自动驾驶领域。在适用范围方面,SAM 主要针对静态图像分割任务,如对象分割、单帧图像分析(如医学图像分析)或卫星图像分割等领域。另一方面,SAM2 进一步扩展到视频分割和动态场景,专注于实时处理,使其非常适合连续帧任务,如自动驾驶和视频监控。
3. SAM2 for Image
3.1 Networks
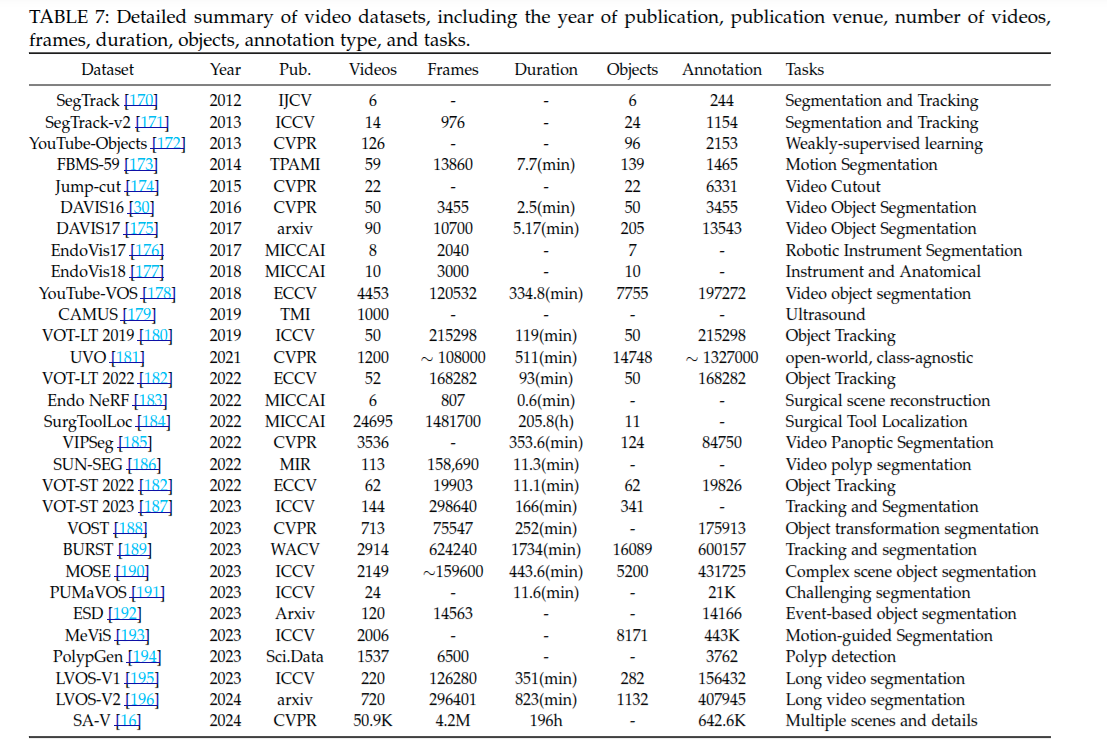
图像分割网络的近期进展进行了梳理,依据基础架构对方法分类,突出各方法独特特征与目标应用,重点关注基于 SAM 和 SAM2 方法的演变及能力.
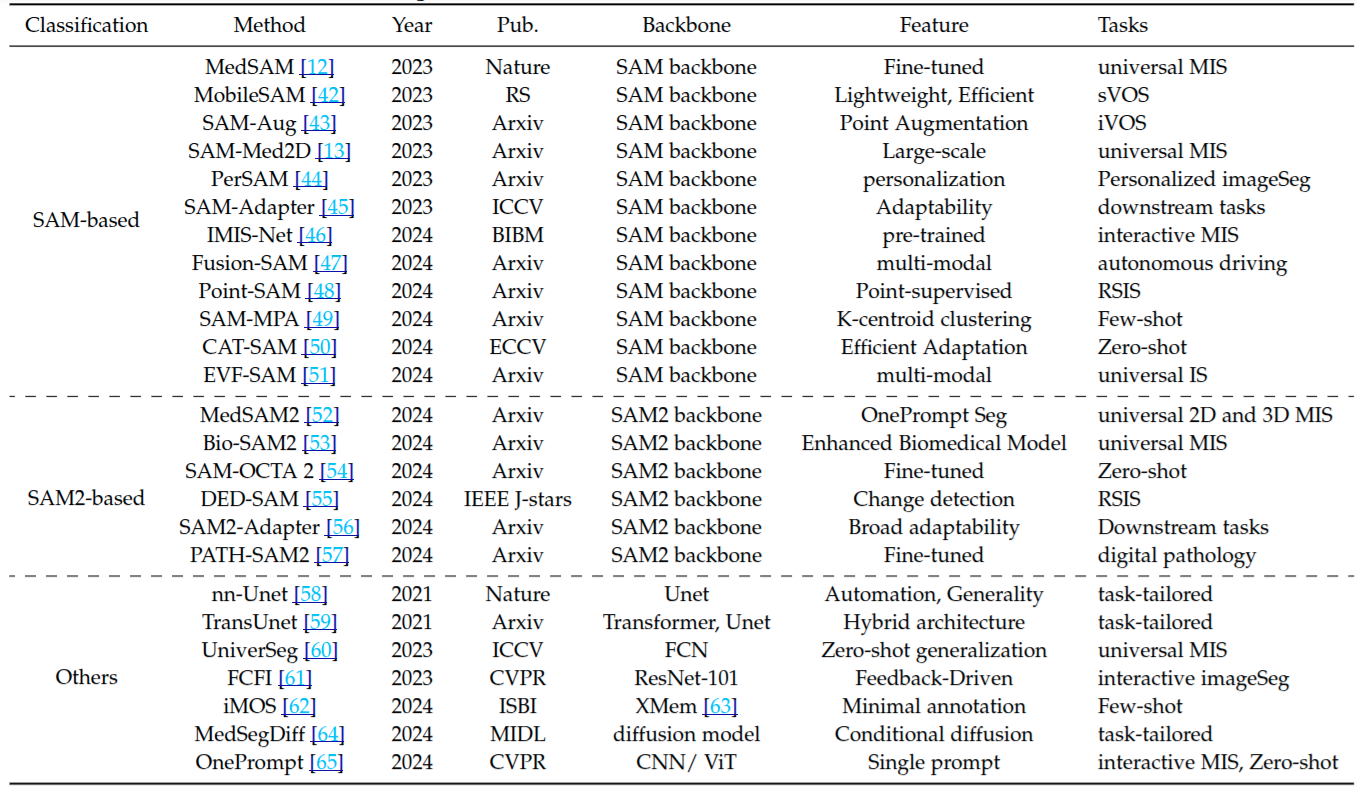
3.2 Datasets
关于自然图像数据集的,详细说明了类别、数据集名称、描述、掩码类型、采样图像数量、采样掩码数量以及发布来源

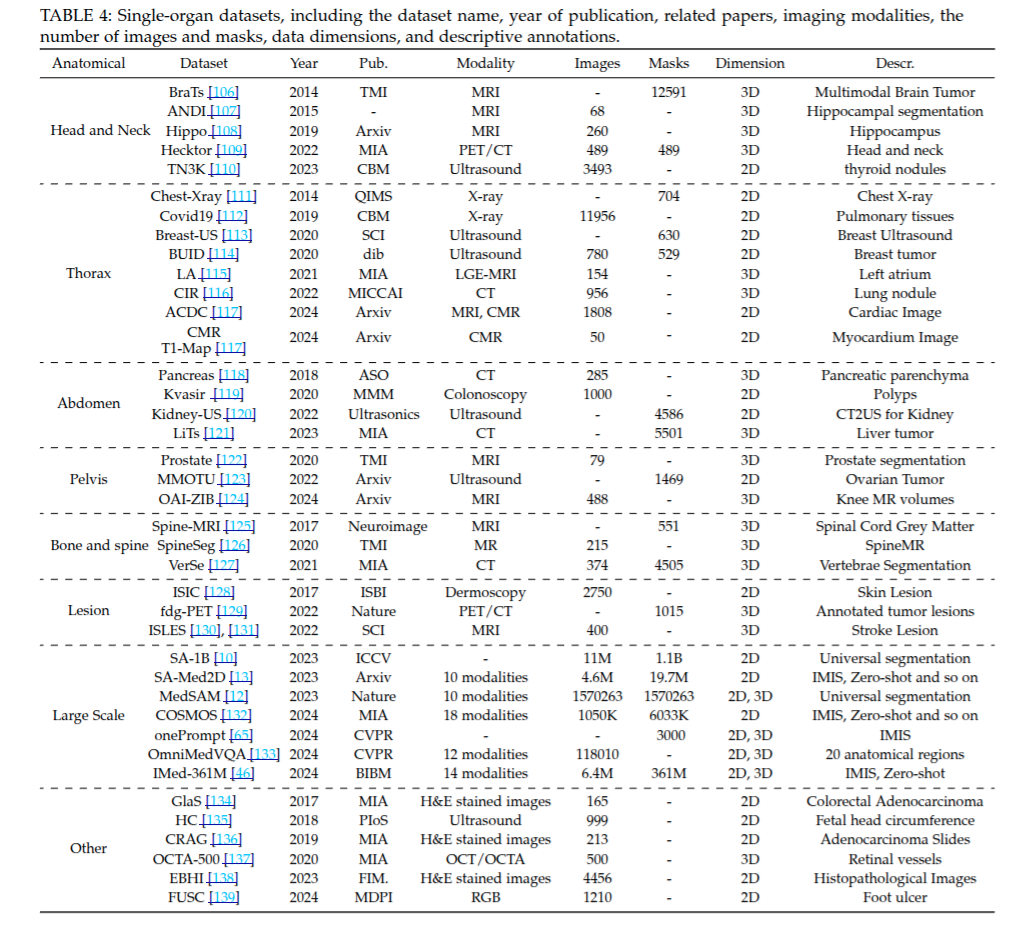
关于医学的单器官数据集的信息汇总,包含数据集名称、发布年份、发表出处、成像模态、图像数量、掩码数量、数据维度以及描述性注释
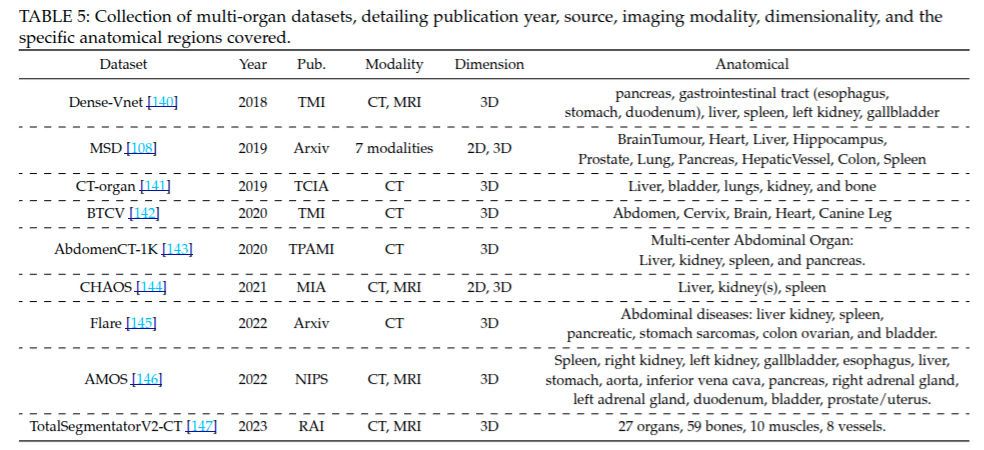
多器官数据集的汇总,详细列出了数据集的发布年份、来源、成像模态、维度以及涵盖的特定解剖区域
3.3 Evaluate Metrics
主要集中于分割结果的准确性和模型的稳健性。
- IoU 是一种用于衡量预测分割区域与真实区域之间重叠程度的指标。oU 值越高,表示分割准确性越好。 I o U = ∣ A ∩ B ∣ ∣ A ∪ B ∣ IoU = \frac{|A \cap B|}{|A \cup B|} IoU=∣A∪B∣∣A∩B∣其中,A 是预测分割区域,B 是真实区域。
- Dice 当目标区域较小或不规则时(这在医学图像分割中很常见),它特别适用于评估两个集合之间的相似度。$Dice = \frac{2 \cdot |A \cap B|}{|A| + |B|}$
- mIoU 是多类别分割任务中所有类别的平均 IoU。 m I o U = 1 N ∑ i = 1 N ∣ A i ∩ B i ∣ ∣ A i ∪ B i ∣ mIoU = \frac{1}{N}\sum_{i = 1}^{N}\frac{|A_{i} \cap B_{i}|}{|A_{i} \cup B_{i}|} mIoU=N1∑i=1N∣Ai∪Bi∣∣Ai∩Bi∣ N 为类别总数。
- PA 像素准确率衡量正确预测的像素数占总像素数的比例。可用于评估模型的整体性能,但在类别不平衡的情况下可能无法反映真实性能。 P A = 1 N ∑ i = 1 N ( y ^ i = y i ) PA = \frac{1}{N}\sum_{i = 1}^{N}(\hat{y}_{i} = y_{i}) PA=N1∑i=1N(y^i=yi)
4. SAM2 FOR VIDEO
对视频分割网络进行了分类梳理,依据方法、发表年份、骨干架构、独特特征以及处理任务来划分,涵盖前沿方法、基于 SAM 和基于 SAM2 的方法.
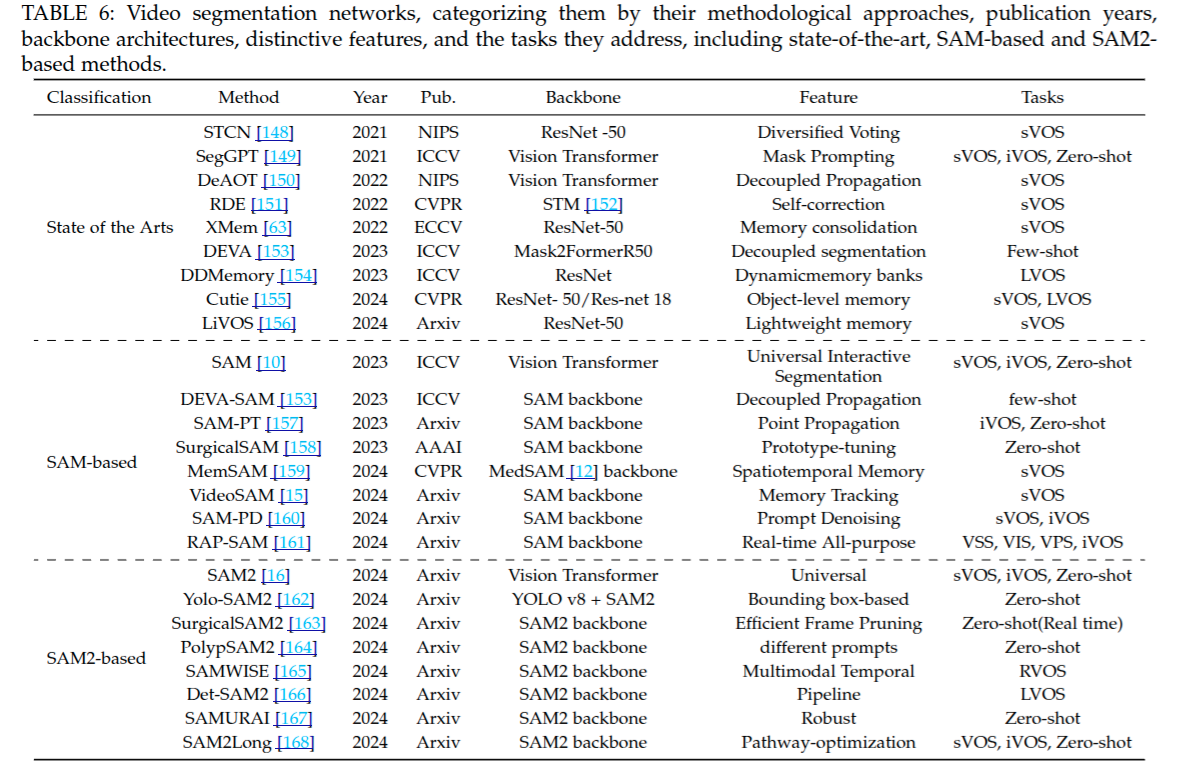
对视频数据集的详细总结,包含了数据集的发布年份、发表出处、视频数量、帧数、时长、对象数量、注释类型以及相关任务.
4.3 Evaluate Metrics
在时间分析方面,对分割的稳定性、一致性和单个分割帧的连续性提出了更高要求。在视频分割中,分割掩码必须同时确保空间分割精度和时间一致性,避免出现如对象跳跃或跨帧漂移等问题。因此,在评估视频分割模型时,除了使用如 IoU 和 Dice 等图像分割指标外,还必须考虑时间维度,以全面评估分割结果在空间和时间方面的性能。
- 区域相似度 J 和轮廓精度 F
给定预测分割掩码 J ∈ { 0 , 1 } H × W J \in \{0, 1\}^{H \times W} J∈{0,1}H×W 和真实掩码 M ∈ { 0 , 1 } H × W M \in \{0, 1\}^{H \times W} M∈{0,1}H×W,M 和 J 之间的区域相似度(交并比,IoU)为:
J = J ∩ M J ∪ M J = \frac{J \cap M}{J \cup M} J=J∪MJ∩M为评估 M 的轮廓质量,我们使用比特图匹配计算轮廓召回率 R c R_c Rc 和轮廓精度 P c P_c Pc,然后通过调和平均数计算轮廓准确率 F:
F = 2 P c R c P c + R c F = \frac{2P_cR_c}{P_c + R_c} F=Pc+Rc2PcRc该指标量化了预测掩码的轮廓与真实掩码的轮廓紧密匹配的程度。对于多个对象,我们对所有对象取该指标的平均值。最后,通过计算区域相似度和轮廓准确率的算术平均值来衡量整体性能,即联合度量 J & F J\&F J&F:
J & F = J + F 2 J\&F = \frac{J + F}{2} J&F=2J+F - 全局准确率Global Accuracy 预测分割中正确分类的像素数与总像素数的比例。
- 时间指标:帧率(FPS)视频分割或分析系统在一秒内处理的帧数,反映了系统在实时应用中的稳定性和速度。更高的 FPS 表示模型能够更快地处理视频数据,使其适合实时任务。
5. DISCUSSION
5.1 Current Challenges
- 域适应限制(Domain Adaptation Limitations ):SAM2 在零样本任务表现尚可,但在医学影像、遥感等特定领域,需专门微调才能达最佳性能。因常依赖复杂上下文信息且缺乏针对性数据,模型泛化能力受限。微调还面临计算成本高、数据标注不足等问题,凸显高效域适应技术和高质量标注数据集的迫切需求。
- 多模态集成(Multimodal Integration ):将 SAM2 与多模态模型高效集成颇具挑战。虽 SAM2 有结合文本描述处理多模态数据的潜力,但有效融合多模态数据复杂,需处理数据对齐、模态特异性差异,且要维持各模态性能。未来需提升模型多模态交互融合能力,以处理复杂多模态数据流。
- 推理速度与资源需求(Inference Speed and Resource Requirements ):SAM2 规模大且复杂,用于实时应用(如自动驾驶、视频分析)时,因尺寸大,推理速度慢、资源消耗高,影响部署。处理多帧分割等任务,需兼顾速度与准确性,降低计算开销并维持性能,高效资源管理是关键。
5.2 Future Works
- 特定领域微调(Fine - Tuning for Specialized Field ):开发更高效针对特定领域(医学影像、遥感等)的微调策略,提升模型适应性和性能,使其能更好处理实际应用任务,提高分割精度。
- 轻量化优化(Lightweight Optimization ):运用模型剪枝、知识蒸馏等技术,降低模型计算开销,提升推理效率,优化架构确保在资源受限实时应用中仍有高性能。
- 增强多模态交互(Enhanced Multimodal Interaction ):深入研究 SAM2 与多模态模型集成,探索文本与视觉信息互补性,用于复杂多样任务(智能问答、图像文本分析)。
- 提高稳健性(Improving Robustness ):训练时纳入更多复杂多样数据集,使模型适应遮挡、目标重现等复杂场景,提升稳定性和适应性。
References
这个的 17-22 参考文献都是 SAM 或 SAM2 的综述


?)
![[C#] Winform - 进程间通信(SendMessage篇)](http://pic.xiahunao.cn/nshx/[C#] Winform - 进程间通信(SendMessage篇))

