回归和分类
回归问题得到的结果都是连续的,比如通过学习时间预测成绩
分类问题是将数据分成几类,比如根据邮件信息将邮件分成垃圾邮件和有效邮件两类。
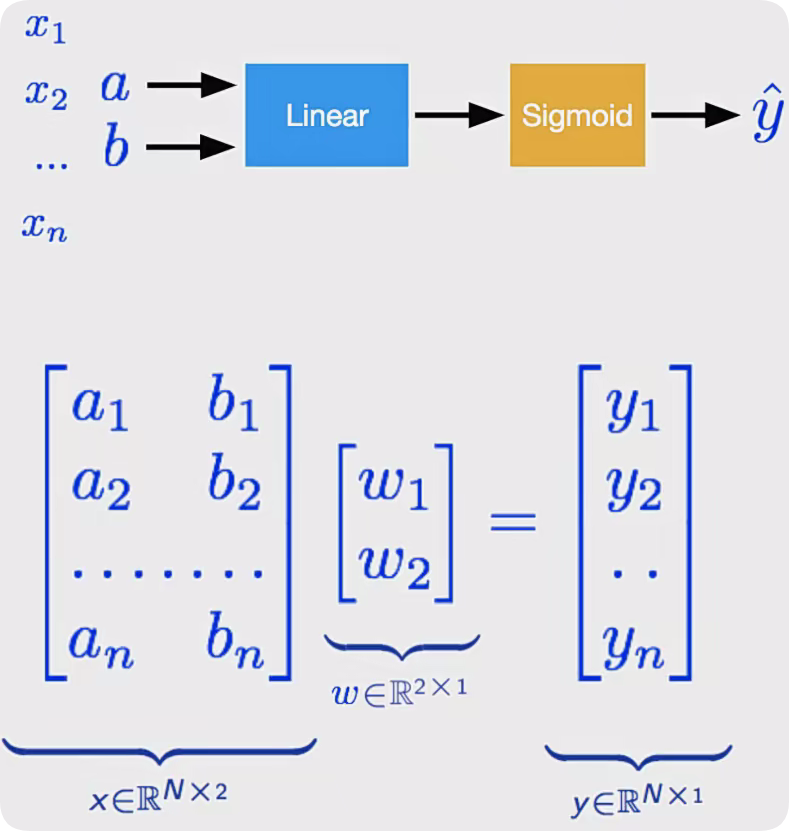
相比于基础的线性回归其实就是增加了一个sigmod函数。
代码
import matplotlib.pyplot as plt
import torch
import pandas as pd
import numpy as np
import torch.nn as nn# 设定随机种子
torch.manual_seed(2017)# 从 data.txt 中读入点
with open('./data.txt', 'r') as f:data_list = [i.split('\n')[0].split(',') for i in f.readlines()]data = [(float(i[0]), float(i[1]), float(i[2])) for i in data_list]# 标准化
x0_max = max([i[0] for i in data])
x1_max = max([i[1] for i in data])
data = [(i[0]/x0_max, i[1]/x1_max, i[2]) for i in data]#把两个类别的点分别保存起来,后续方便绘图
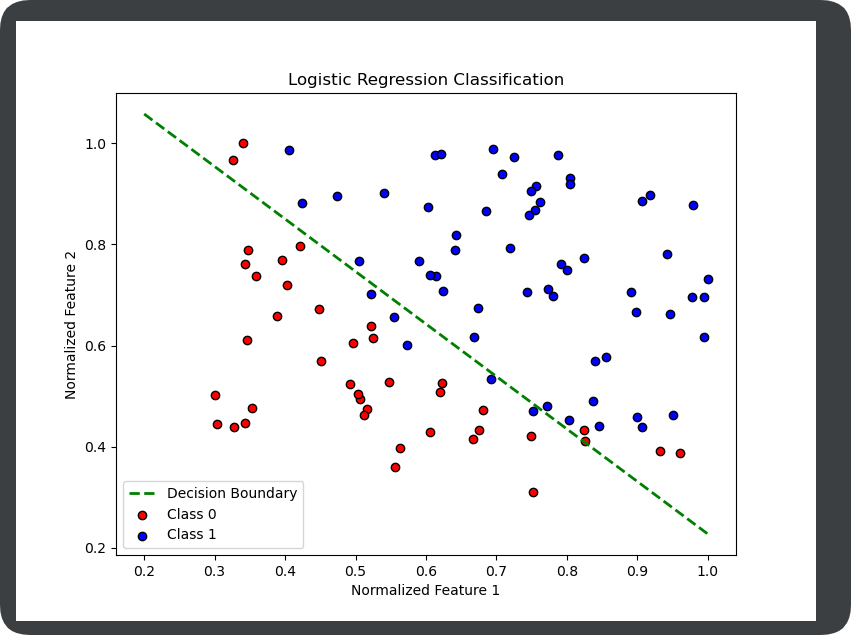
x0 = list(filter(lambda x: x[-1] == 0.0, data)) # 选择第一类的点
x1 = list(filter(lambda x: x[-1] == 1.0, data)) # 选择第二类的点plot_x0 = [i[0] for i in x0] #第0类点的x坐标
plot_y0 = [i[1] for i in x0]#第0类点的y坐标
plot_x1 = [i[0] for i in x1]#第1类点的x坐标
plot_y1 = [i[1] for i in x1]#第1类点的y坐标#数据转化为numpy,再转化为tensor
np_data = np.array(data, dtype='float32') # 转换成 numpy array
x_data = torch.from_numpy(np_data[:, 0:2]) # 转换成 Tensor, 大小是 [100, 2]
y_data = torch.from_numpy(np_data[:, 2]).unsqueeze(1) # 转换成 Tensor,大小是 [100, 1]#定义模型
class LogisticRegression(torch.nn.Module):def __init__(self):super(LogisticRegression, self).__init__()self.linear = torch.nn.Linear(2,1) #这里会自动初始化w和b,所以不需要自己再设置def forward(self, x):return self.linear(x) #这里自己第一次写的时候,写成torch.sigmoid(self.linear(x)),其实在后续损失函数中,已经包含了sigmoid函数,所以这里可以直接返回线性层的输出
#实例化
model = LogisticRegression()
#损失函数
criterion = nn.BCEWithLogitsLoss()optimizer = torch.optim.SGD(model.parameters(), lr=1) #优化器,自己也是入门,这里学习率往往按照经验设置,也可以多多尝试设置# 训练函数
def train(epochs):model.train()for e in range(epochs):optimizer.zero_grad() #梯度归零y_pred = model(x_data) #前向传播loss = criterion(y_pred, y_data) #计算损失loss.backward() #反向传播optimizer.step() #更新参数if e % 1000 == 0:print(f"Epoch {e}, Loss: {loss.item()}")if __name__ == '__main__':train(10000)# 获取训练后的参数w = model.linear.weight.detach().numpy().flatten()b = model.linear.bias.detach().numpy().item()# 计算决策边界 (w1*x1 + w2*x2 + b = 0)plot_x = np.linspace(0.2, 1, 100)plot_y = (-w[0] * plot_x - b) / w[1]# 绘制结果plt.figure(figsize=(8, 6)) #设置画布#描点plt.scatter(plot_x0, plot_y0, c='red', label='Class 0', edgecolors='k')plt.scatter(plot_x1, plot_y1, c='blue', label='Class 1', edgecolors='k')#划分割线plt.plot(plot_x, plot_y, 'g--', linewidth=2, label='Decision Boundary')plt.title("Logistic Regression Classification")plt.xlabel("Normalized Feature 1")plt.ylabel("Normalized Feature 2")plt.legend()plt.show()训练:
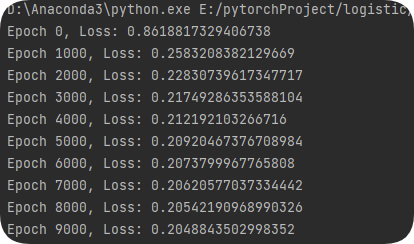
最后效果