
🔥个人主页:Quitecoder
🔥专栏:c++笔记仓

目录
- 01.图的遍历
- 广度优先
- **详细步骤与例子**
- **假设图如下(无向图):**
- **图的邻接表表示:**
- **从顶点 A 开始的广度优先遍历**
- 深度优先
01.图的遍历
给定一个图G和其中任意一个顶点v0,从v0出发,沿着图中各边访问图中的所有顶点,且每个顶点仅被遍历一次。"遍历"即对结点进行某种操作
广度优先
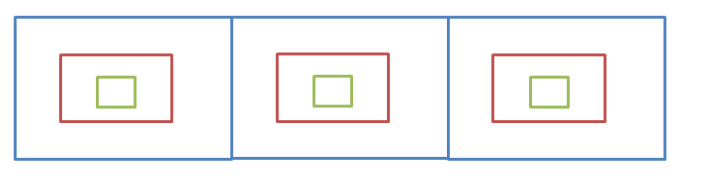
比如现在要找东西,假设有三个抽屉,东西在那个抽不清楚,现在要将其找到,广度优先遍历的做法是:
1.先将三个抽屉打开,在最外层找一遍
2.将每个抽屉中红色的盒子打开,再找一遍
3.将红色盒子中绿色盒子打开,再找一遍
直到找完所有的盒子,注意:每个盒子只能找一次,不能重复找
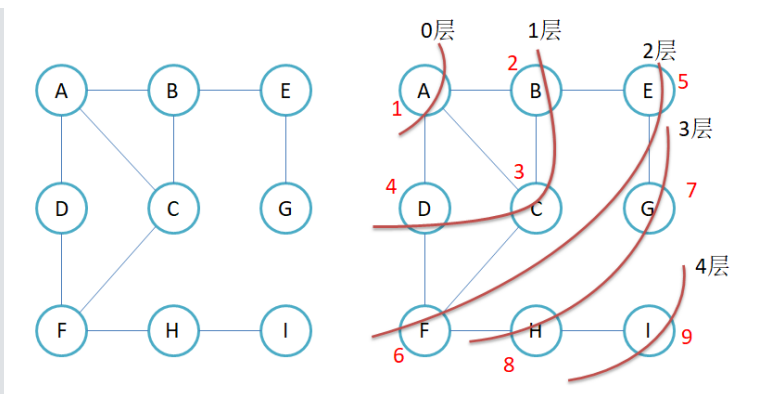
问题:如何防止节点被重复遍历
基本思路
- 初始化:
- 创建一个队列,用于记录待访问的顶点。
- 创建一个数组或集合,用于标记已经访问过的顶点。
- 从起始顶点开始:
- 将起始顶点加入队列,同时标记为已访问。
- 开始遍历:
- 只要队列不为空,重复以下步骤:
- 从队列中取出一个顶点,称为当前顶点。
- 遍历当前顶点的所有邻居:
- 如果某个邻居尚未被访问,则将其加入队列,并标记为已访问。
- 只要队列不为空,重复以下步骤:
- 结束条件:
- 当队列为空时,遍历结束。
void BFS(const V& src)
{size_t srci = GetVertexIndex(src);vector<bool> visited;visited.resize(_vertexs.size(), false);queue<int> q;q.push(srci);visited[srci] = true;while (!q.empty()){int front = q.front();q.pop();cout << front << ":" << _vertexs[front] << endl;//把front的邻接顶点入队列for (int i = 0; i < _vertexs.size(); i++){if (_matrix[front][i] != MAX_W && visited[i] == false){visited[i] = true;q.push(i);}}}
}
详细步骤与例子
假设图如下(无向图):
A -- B -- C
| |
D -- E
图的邻接表表示:
A: B, D
B: A, C, E
C: B
D: A, E
E: B, D
从顶点 A 开始的广度优先遍历
-
初始化:
- 队列:
q = [A] - 已访问集合:
visited = {A}
- 队列:
-
第一轮:
- 从队列取出
A,访问A。 - 遍历
A的邻居B和D:- 将
B和D加入队列:q = [B, D] - 标记
B和D为已访问:visited = {A, B, D}
- 将
- 从队列取出
-
第二轮:
- 从队列取出
B,访问B。 - 遍历
B的邻居A、C、E:A已访问,跳过。- 将
C和E加入队列:q = [D, C, E] - 标记
C和E为已访问:visited = {A, B, D, C, E}
- 从队列取出
-
第三轮:
- 从队列取出
D,访问D。 - 遍历
D的邻居A、E:A和E已访问,跳过。
- 从队列取出
-
第四轮:
- 从队列取出
C,访问C。 - 遍历
C的邻居B:B已访问,跳过。
- 从队列取出
-
第五轮:
- 从队列取出
E,访问E。 - 遍历
E的邻居B、D:B和D已访问,跳过。
- 从队列取出
-
结束:
- 队列为空,遍历完成。
遍历顺序:
A -> B -> D -> C -> E
关键点
-
队列的作用:
- 保证顶点按层次顺序访问(即先访问距离起点较近的顶点,再访问较远的顶点)。
-
访问标记的作用:
- 防止重复访问顶点,避免死循环。例如,在无向图中,访问
A时会发现B,然后访问B时会发现A,没有标记的话会导致无限循环。
- 防止重复访问顶点,避免死循环。例如,在无向图中,访问
-
适用图的存储结构:
- 邻接表:遍历顶点的邻居时高效。
- 邻接矩阵:需要遍历整行寻找邻居,效率稍低。
-
时间复杂度:
- 对于邻接表表示的图:
- 时间复杂度: O ( V + E ) O(V + E) O(V+E),其中 V V V 是顶点数, E E E 是边数。
- 遍历所有顶点需要 O ( V ) O(V) O(V),遍历每个顶点的所有邻居需要 O ( E ) O(E) O(E)。
- 对于邻接矩阵表示的图:
- 时间复杂度: O ( V 2 ) O(V^2) O(V2),因为需要检查矩阵中的每个元素。
- 对于邻接表表示的图:
-
空间复杂度:
- 主要由队列和访问标记占用,复杂度为 O ( V ) O(V) O(V)。
深度优先
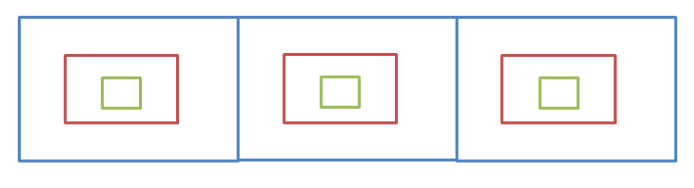
比如现在要找东西,假设有三个抽屉,东西在那个抽屉不清楚,现在
要将其找到,广度优先遍历的做法是:
-
先将第一个抽屉打开,在最外层找一遍
-
将第一个抽屉中红盒子打开,在红盒子中找一遍
-
将红盒子中绿盒子打开,在绿盒子中找一遍
-
递归查找剩余的两个盒子
深度优先遍历:将一个抽屉一次性遍历完(包括该抽屉中包含的小盒
子),再去递归遍历其他盒子

void _DFS(size_t srci,vector<bool> & visited)
{cout << srci << ":" << _vertexs[src] << " ";visited[srci] = true;for (int i = 0; i < _vertexs.size(); i++){if (_matrix[srci][i] != MAX_W && visited[i] == false){_DFS(i, visited);}}
}
void DFS(const V& src)
{size_t srci = GetVertexIndex(src);vector<bool> visited(_vertexs.size(), false);_DFS(src, visited);
}
深度优先遍历的特点
- 优先深入:每次选择一个尚未访问的邻居节点递归访问,直到没有未访问的邻居为止。
- 回溯策略:当某节点的所有邻居都被访问后,回溯到其上一个节点,继续探索其未访问的邻居。
- 递归实现或使用栈:DFS 可以通过递归或显式栈来实现。
- 标记节点:需要记录哪些节点已经被访问过,以避免重复访问或陷入死循环。
基本思路
1. 初始化
- 创建一个访问标记的数组或集合,用于记录已访问的顶点。
- 从起始顶点开始,将其标记为已访问,然后递归或借助栈访问其邻居。
2. 递归实现
- 对于每个顶点,访问其第一个未访问的邻居。
- 如果该邻居存在,递归调用深度优先遍历函数继续访问其邻居。
- 如果该顶点的所有邻居都被访问过,则回溯到上一层。
3. 使用显式栈
- 使用栈模拟递归的行为:
- 初始时,将起始顶点入栈。
- 每次从栈中取出顶点,访问该顶点,并将其所有未访问的邻居依次压入栈。
非递归实现(使用栈)
void DFS(Graph& graph, const V& start) {stack<V> s; // 栈用于存储待访问的顶点unordered_set<V> visited; // 标记已访问顶点s.push(start); // 将起始顶点压入栈while (!s.empty()) {V current = s.top(); // 取出栈顶顶点s.pop();if (visited.find(current) == visited.end()) {// 标记当前顶点为已访问visited.insert(current);// 处理当前顶点(例如打印)cout << current << " ";// 将未访问的邻居压入栈for (const auto& neighbor : graph.GetNeighbors(current)) {if (visited.find(neighbor) == visited.end()) {s.push(neighbor);}}}}
}
详细过程与示例
假设图如下(无向图):
A -- B -- C
| |
D -- E
邻接表表示:
A: B, D
B: A, C, E
C: B
D: A, E
E: B, D
从顶点 A 开始的深度优先遍历
- 递归实现
初始状态:
- 访问标记:
visited = {}
遍历过程:
- 访问顶点
A,标记为已访问:visited = {A} - 从
A的邻居中选择未访问的B,递归进入顶点B:- 访问顶点
B,标记为已访问:visited = {A, B} - 从
B的邻居中选择未访问的C,递归进入顶点C:- 访问顶点
C,标记为已访问:visited = {A, B, C} C的邻居B已访问,递归返回到顶点B。
- 访问顶点
- 返回到
B,继续访问其未访问的邻居E,递归进入顶点E:- 访问顶点
E,标记为已访问:visited = {A, B, C, E} - 从
E的邻居中选择未访问的D,递归进入顶点D:- 访问顶点
D,标记为已访问:visited = {A, B, C, D, E} D的邻居A、E均已访问,递归返回到顶点E。
- 访问顶点
- 返回到
E,无更多未访问的邻居。
- 访问顶点
- 返回到
B,无更多未访问的邻居。
- 访问顶点
- 返回到
A,继续访问其未访问的邻居D:D已访问,跳过。
最终结果:A -> B -> C -> E -> D
- 非递归实现
初始状态:
- 栈:
s = [A] - 访问标记:
visited = {}
遍历过程:
-
从栈中弹出顶点
A,访问A:visited = {A},将邻居B和D压入栈:- 栈:
s = [B, D]
- 栈:
-
从栈中弹出顶点
D,访问D:visited = {A, D},将邻居E压入栈:- 栈:
s = [B, E]
- 栈:
-
从栈中弹出顶点
E,访问E:visited = {A, D, E},将邻居B压入栈:- 栈:
s = [B, B]
- 栈:
-
从栈中弹出顶点
B,访问B:visited = {A, D, E, B},将邻居C压入栈:- 栈:
s = [B, C]
- 栈:
-
从栈中弹出顶点
C,访问C:visited = {A, D, E, B, C}。- 栈:
s = [B]
- 栈:
-
从栈中弹出顶点
B,发现已访问,跳过。 -
栈为空,遍历结束。
最终结果:A -> D -> E -> B -> C
深度优先遍历的时间和空间复杂度
-
时间复杂度:
- 邻接表表示: O ( V + E ) O(V + E) O(V+E),其中 V V V 是顶点数, E E E 是边数。
- 每个顶点最多被访问一次。
- 每条边最多被遍历一次。
- 邻接矩阵表示: O ( V 2 ) O(V^2) O(V2),因为需要检查矩阵中的每一项。
- 邻接表表示: O ( V + E ) O(V + E) O(V+E),其中 V V V 是顶点数, E E E 是边数。
-
空间复杂度:
- 栈或递归调用的深度为 O ( V ) O(V) O(V)。
应用**
- 连通性检测:
- 判断无向图是否连通,或找到所有连通分量。
- 检测环:
- 深度优先遍历可以检测图中是否存在环。
- 拓扑排序:
- 用于有向无环图(DAG)的拓扑排序。
- 路径搜索:
- 找到从起点到终点的所有路径。




