最近迷上了多模态,正好读到一篇多模态相关的文章,于是就写博客总结和大家分享一下:https://arxiv.org/pdf/2411.10442v1
【导读】多模态大语言模型(MLLMs)虽然在许多任务上表现出色,但在链式思考(Chain-of-Thought, CoT)推理方面仍存在不足。为此,上海人工智能实验室的研究团队提出了一种基于混合偏好优化(MPO)的新方法,通过自动化偏好数据构建管道和创新的训练策略,显著提升了MLLMs的多模态推理能力。这一研究成果不仅为多模态大语言模型的发展带来了新的突破,也为未来的AI研究提供了新的思路。
多模态大语言模型(MLLMs)在预训练和监督微调(SFT)的训练范式下,已经在多个领域和任务中取得了显著成就。然而,这些模型在链式思考(CoT)推理方面的表现却不尽如人意,尤其是在处理多模态数据时。为了克服这一挑战,上海人工智能实验室的研究团队提出了一种基于混合偏好优化(MPO)的新方法,旨在通过自动化偏好数据构建管道和创新的训练策略,提升MLLMs的多模态推理能力。
多模态大语言模型的推理瓶颈
多模态大语言模型(MLLMs)在预训练和监督微调的训练范式下,已经在多个领域和任务中取得了显著成就。然而,这些模型在链式思考(CoT)推理方面的表现却不尽如人意。如图1所示,在MathVista这一多模态推理基准上,InternVL2-8B模型使用直接答案时得分为58.3,但在使用链式思考推理时得分却下降到56.8,这表明链式思考推理实际上降低了模型的性能。
这种下降现象在多模态大语言模型中普遍存在,主要原因在于监督微调(SFT)过程中引入的分布偏移。SFT依赖于教师强制(teacher forcing),即模型在训练时根据先前的真实标记令牌来预测下一个令牌。然而,在推理过程中,模型必须基于自己的先前输出来预测每个令牌,这导致了训练和推理之间的分布偏移。由于直接答案方法只需要简短的响应,而链式思考推理需要生成详细的推理过程,因此在链式思考推理中分布偏移问题更为严重,导致模型性能下降。
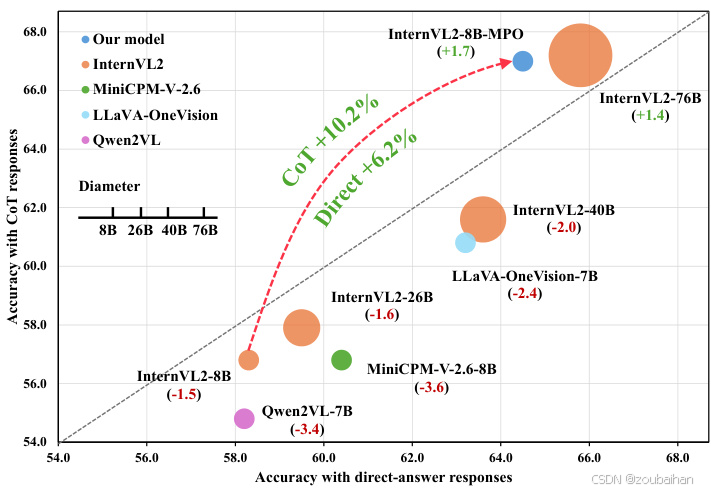 从图中可以看到明显的模型准确率变化。开源模型在MathVista上的表现。X轴和Y轴分别表示使用直接答案和链式思考响应评估的准确性。气泡大小与模型参数数量正相关。括号中的值表示链式思考与直接答案响应之间的性能差距。值得注意的是,大多数开源模型在使用链式思考回答时表现更差。
从图中可以看到明显的模型准确率变化。开源模型在MathVista上的表现。X轴和Y轴分别表示使用直接答案和链式思考响应评估的准确性。气泡大小与模型参数数量正相关。括号中的值表示链式思考与直接答案响应之间的性能差距。值得注意的是,大多数开源模型在使用链式思考回答时表现更差。
基于偏好优化的新突破
为了克服多模态大语言模型在链式思考推理方面的不足,研究团队从自然语言处理(NLP)领域借鉴了偏好优化(PO)技术,旨在通过偏好信号使模型生成的响应更好地符合用户需求。具体来说,他们提出了一种名为混合偏好优化(MPO)的新方法,通过结合偏好损失、质量损失和生成损失,来增强模型的多模态推理能力。
数据端的创新:自动化偏好数据构建管道
为了支持MPO方法的实施,研究团队设计了一个自动化偏好数据构建管道,用于生成高质量的大规模多模态推理偏好数据集MMPR。该管道包括两种主要方法:
- 基于正确性的管道:对于具有明确真实值的指令,通过采样多个解决方案并将匹配真实答案的解决方案作为首选响应,不匹配真实答案的解决方案作为拒绝响应来构建偏好对。
- 基于Dropout Next-Token Prediction(DropoutNTP)的管道:对于没有明确真实值的指令,通过截断模型生成的响应的一半,并提示模型在没有图像输入的情况下完成剩余部分来生成拒绝响应。原始响应作为首选响应,而生成的完成部分作为拒绝响应。
这种自动化数据构建方法不仅提高了数据生成的效率,还确保了数据的多样性和高质量。
 上面的图里面展示的是具有明确真实值的指令示例。首选响应与真实答案匹配,而拒绝响应则不匹配。
上面的图里面展示的是具有明确真实值的指令示例。首选响应与真实答案匹配,而拒绝响应则不匹配。
模型端的创新:混合偏好优化方法
在模型端,研究团队提出了混合偏好优化(MPO)方法,该方法结合了偏好损失、质量损失和生成损失来增强模型的训练效果。具体来说:
- 偏好损失:使用直接偏好优化(DPO)作为偏好损失,使模型能够学习首选响应和拒绝响应之间的相对偏好。
- 质量损失:采用二进制分类器优化(BCO)作为质量损失,帮助模型理解单个响应的绝对质量。
- 生成损失:使用监督微调损失作为生成损失,帮助模型学习生成首选响应的过程。
通过结合这三种损失,MPO方法旨在使模型能够同时学习响应之间的相对偏好、单个响应的绝对质量以及生成首选响应的过程。
实验结果与性能提升
为了验证MPO方法的有效性,研究团队在多个基准上进行了广泛的实验。实验结果表明,经过MPO训练的模型InternVL2-8B-MPO在多模态推理任务上表现出色,特别是在MathVista基准上取得了67.0%的准确率,比基线模型InternVL2-8B高出8.7个百分点,甚至达到了比10倍大的InternVL2-76B模型相当的性能。
此外,MPO方法还在复杂视觉问答(VQA)和幻觉评估任务上表现出了优越的性能。这些结果表明,MPO方法不仅提高了模型的多模态推理能力,还减少了幻觉现象的发生。
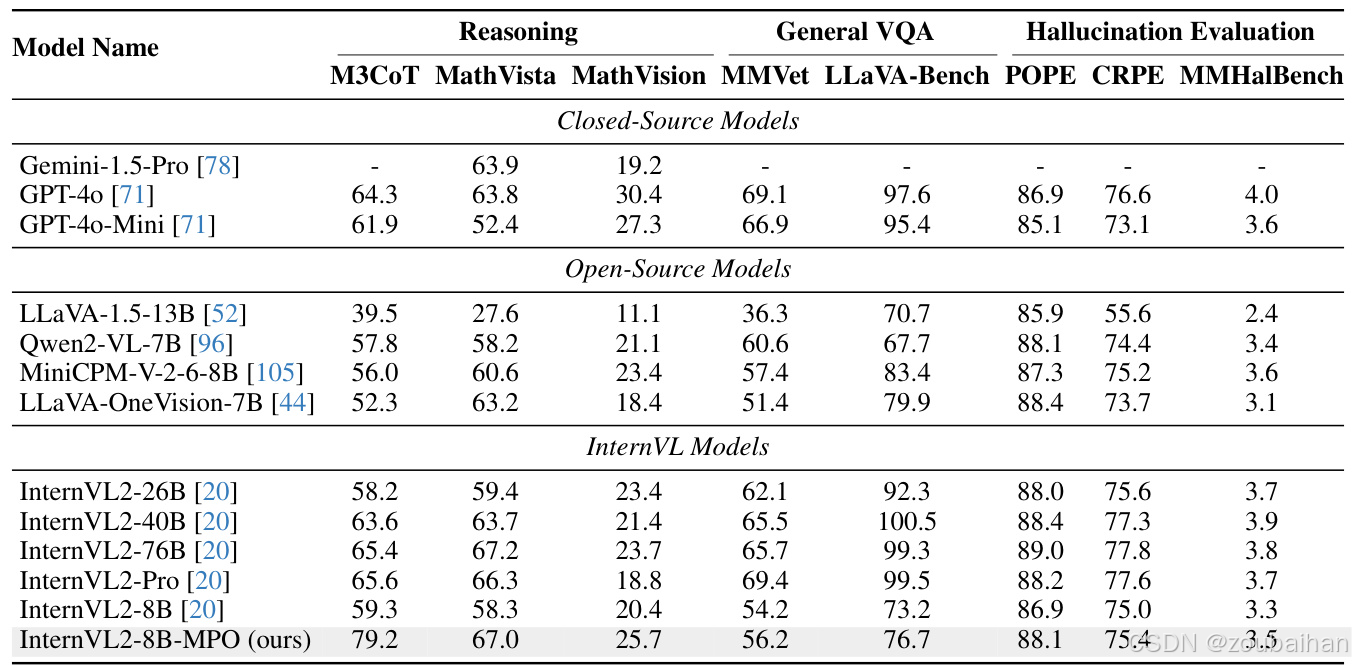 在8个多模态基准上的结果。看起来还是很不错的。
在8个多模态基准上的结果。看起来还是很不错的。
消融实验与算法比较
为了深入分析MPO方法的有效性,研究团队还进行了一系列消融实验和算法比较。实验结果表明:
- MPO方法显著优于仅使用监督微调(SFT)训练的模型,在多模态推理、复杂VQA和幻觉评估任务上均表现出更好的性能。
- 在与RLAIF-V中的divide-and-conquer方法进行比较时,DropoutNTP方法以更低的成本实现了相当的性能。
- 在比较不同偏好优化算法时,结合SFT损失的DPO和BCO变体(即MPO方法)表现出了最佳的性能。
这些消融实验和算法比较进一步验证了MPO方法的有效性和鲁棒性。
 上图中是在M3CoT上训练的不同偏好优化算法的结果。作者为了简洁起见,将算法X与SFT损失相结合称为X+。例如,DPO+表示DPO损失和SFT损失的组合。
上图中是在M3CoT上训练的不同偏好优化算法的结果。作者为了简洁起见,将算法X与SFT损失相结合称为X+。例如,DPO+表示DPO损失和SFT损失的组合。
未来研究方向与应用前景
尽管MPO方法已经取得了显著的成果,但研究团队认为仍有许多值得探索的方向。比如说,可以进一步扩展MMPR数据集以包含更多样化的指令和图像;可以探索更有效的偏好优化算法以进一步提高模型性能;还可以将MPO方法应用于其他类型的多模态模型中以验证其普适性。
此外,MPO方法在多模态推理任务上的成功也为其在其他领域的应用提供了可能。例如,在医疗影像分析、自动驾驶和智能机器人等领域中,多模态推理能力对于准确理解和响应复杂场景至关重要。通过引入MPO方法,可以显著提升这些领域中的模型性能和应用效果。




