文章目录
- 🌏索引(上)回顾
- 🌏使用索引
- 🪐自动创建索引
- 🪐手动创建索引
- 🚀主键索引
- 🚀普通索引
- 🚀唯一索引
- 🚀复合索引
- 🪐查看索引
- 🪐删除索引
- 🚀删除主键索引
- 🚀删除其他索引
- 🌏查看执行计划
🌏索引(上)回顾
- MySQL选择使用B+树这种数据结构进行索引
可以有效的控制树高
非叶子节点仅具有索引功能,叶子结点保存真实数据
所有叶子结点构成一个有序链表 实现范围查找
- B+树与B树对比
叶子结点中的数据连续,相互连接,便于区间查找和搜索
非叶子结点的值都包含在叶子结点中
树高相同的情况下,查找任一元素时间复杂度都一样,性能均衡
- 页是内存与磁盘交互的最小单元,默认大小为16KB
读取数据时,不是单单读取一条数据,而是读取一整页查遍历到相应的数据行
空间不够了 InooDB会提前申请好一页的空间,所以页的磁盘空间是连续的,便于数据的遍历
- B+树在MySQL索引中的应用
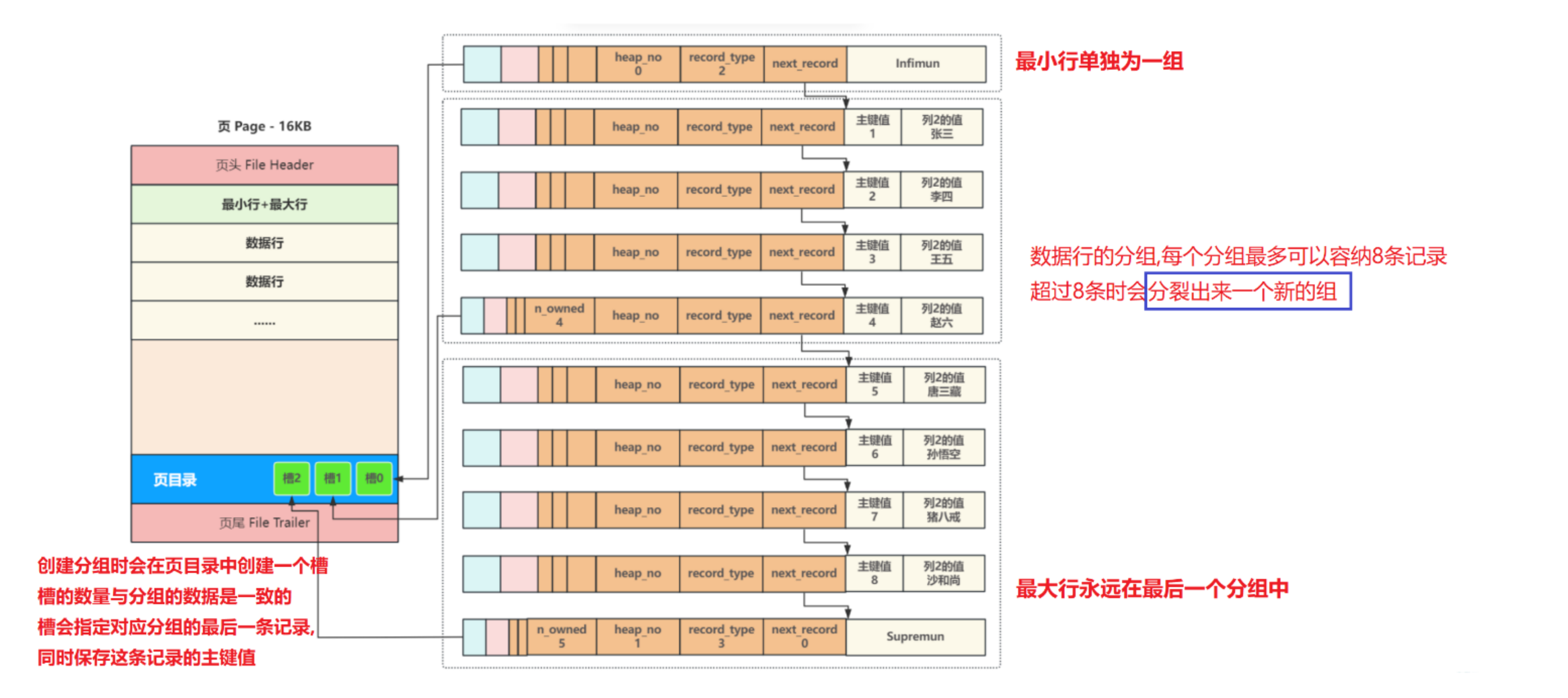
比如查找id 为 6的数据行
现在遍历槽1 通过槽拿到主键值进行判断, 能看到图中槽1的主键值是4 5 > 4 就到槽2中遍历
槽2 中存在主键值为6 的值
先比对槽中记录的主键值,定位到最后⼀个槽2,再从最后⼀个槽中的第⼀条记录遍历,第⼆条记录就是我们要查询的目标行
想要查询页里面的内容,先将页加载到内存,根节点一页,二级节点一页,叶子结点的数据页也是一页,所以说通过三次IO就可以把我们想要的数据找到 --三层树高的B+树
- 三层树高的B+树可以存多少记录
一个数据页默认为16KB。假设一条数据为1KB,一页中至多可以存16条数据
索引页中存的是主键值和子节点的引用,也就是说下一个节点的偏移(地址)
主键 bigint类型 占8Byte 下一页地址 6Byte 也就是说一条索引记录占 8 + 6 = 14Byte
一个索引页可以存 16 * 1024 / 14 = 1170
理论上一个三层树高的B+树可以存:1170 * 1170 * 16 = 21,902,400 条记录
在当前的场景下,表中有21,902,400条记录的情况下,通过3次IO就可以完成数据的查询
- 索引分类
创建索引之前考虑需不需要创建索引,创建一个索引就会生成一个索引树占磁盘空间,对数据的增删改效率影响较大
如果某一列的重复度过高,像是gender 这种只有两个值的列 数据一多,重复度就会很高,就非常不适合创建索引来提高查询效率
如果要存储文档类的数据,我们会专门使用文档类的数据库,全文索引用的并不多
🌏使用索引
🪐自动创建索引
- 当我们为一张表加主键约束(PRIMARY KEY),外键约束(FOREIGN KEY),唯一约束(UNIQUE)时,MySQL会为对应的列自动创建一个索引
- 如果表中不指定任何约束,MySQL会自动为每一列生成一个索引并用ROW_ID字段进行标识
🪐手动创建索引
🚀主键索引
- 方式一:创建表时指定主键
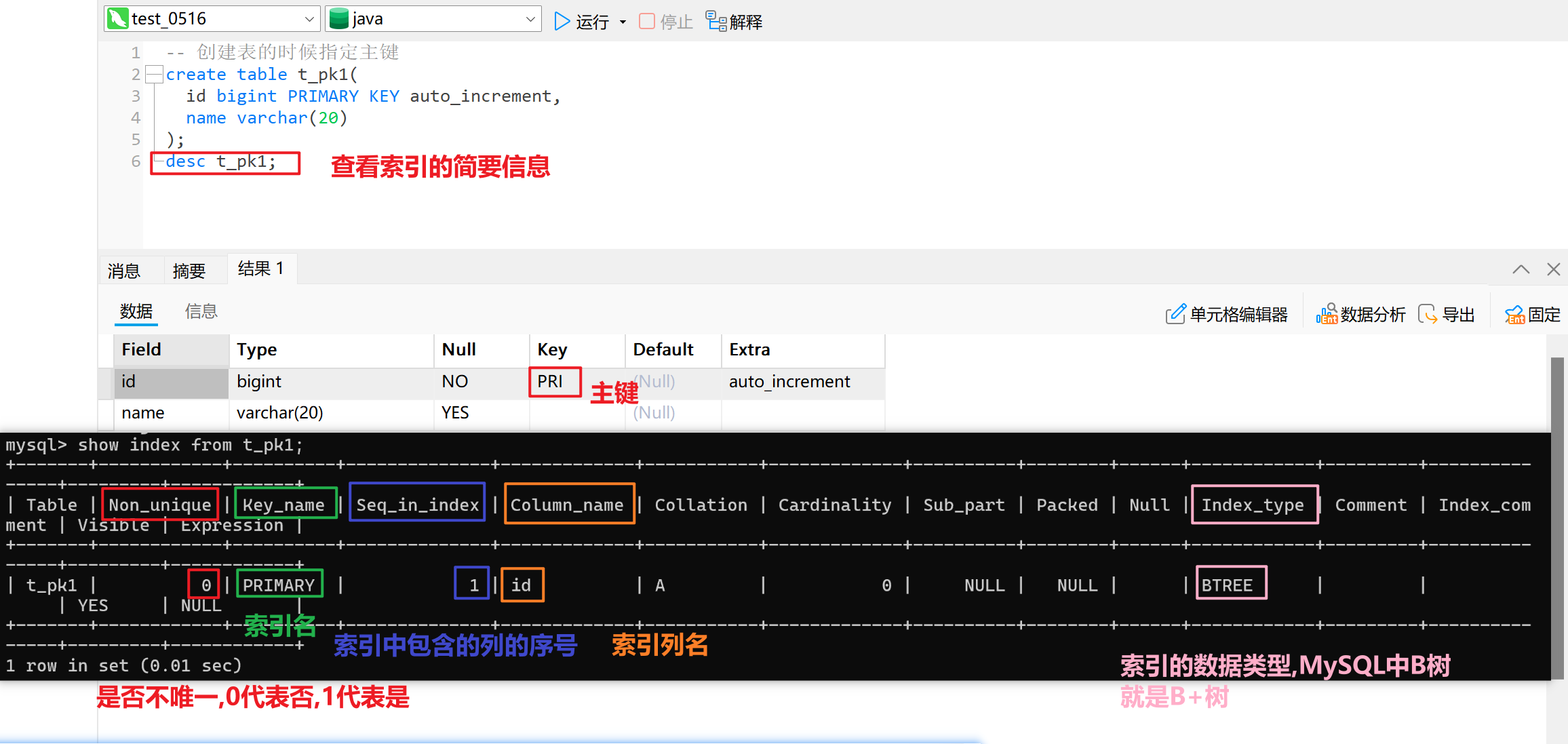
-- 创建表的时候指定主键
create table t_pk1(id bigint PRIMARY KEY auto_increment,name varchar(20)
);
desc t_pk1;
- 创建表时单独指定主键列
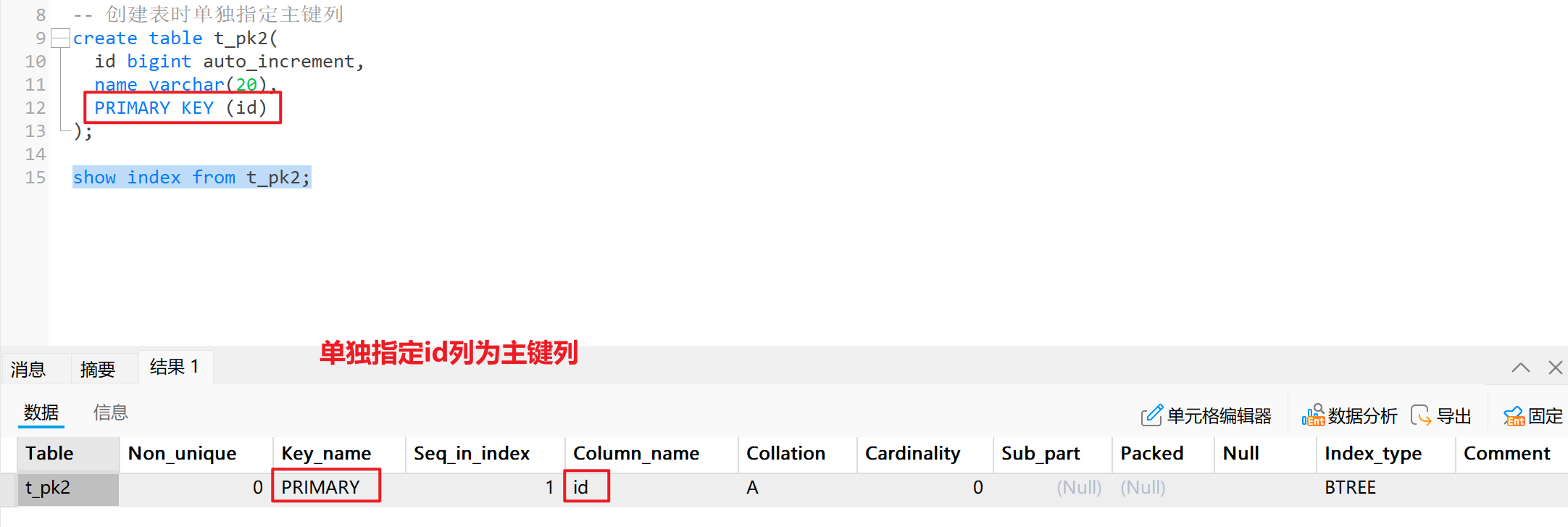
-- 创建表时单独指定主键列
create table t_pk2(id bigint auto_increment,name varchar(20),PRIMARY KEY (id)
);
show index from t_pk2;
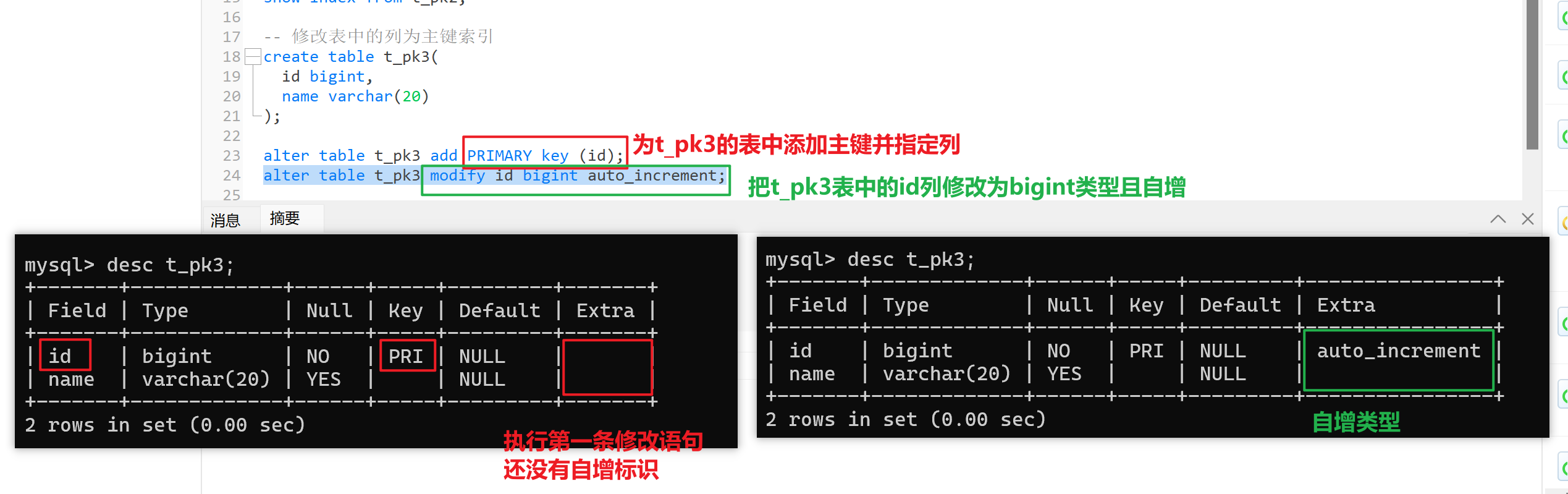
- 方式三:修改表中的列为主键索引
修改表结构和列语法:
alter table 表名 [add | modify | drop] 要修改的内容
🚀普通索引
创建的时机:
1.创建表的时候,明确的知道某些列需要频繁查询,就创建好(当表中数据过少时,全表扫描效率可能比索引还高)
2.随着业务的不断发展,在版本迭代的过程中会添加索引
1.方式一:创建表时指定索引列
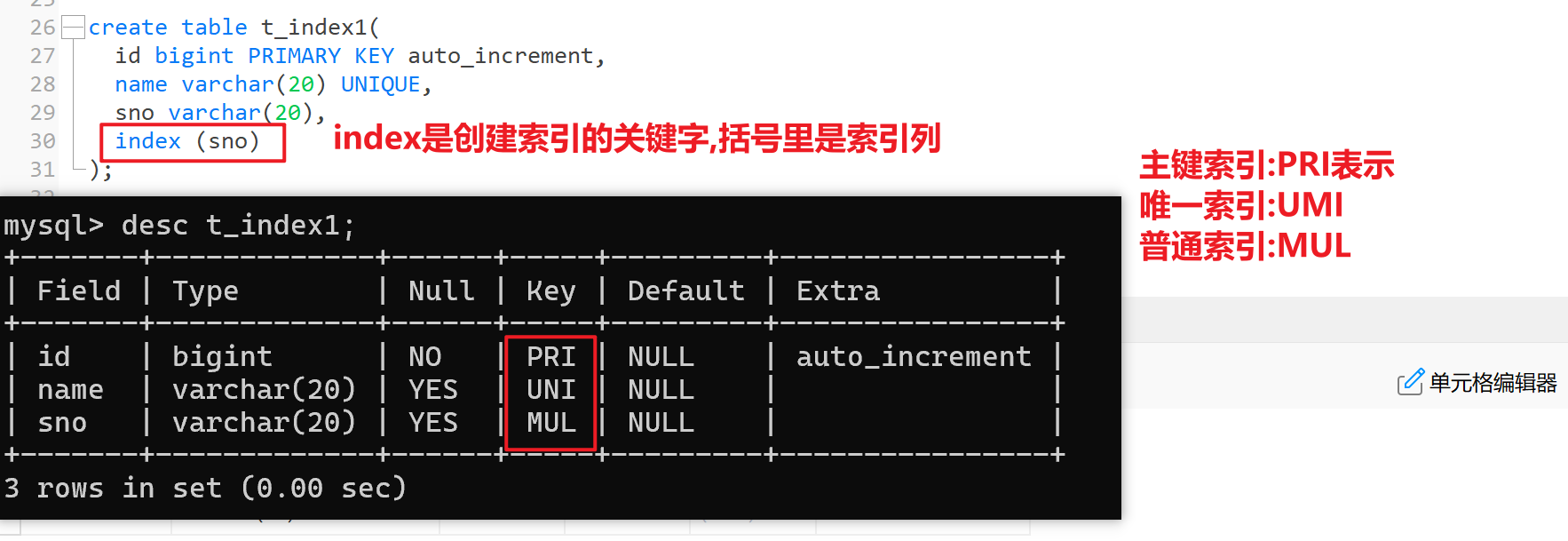
create table t_index1(id bigint PRIMARY KEY auto_increment,name varchar(20) UNIQUE,sno varchar(20),index (sno)
);desc t_index1;
或者使用show keys from 表名
查看关系
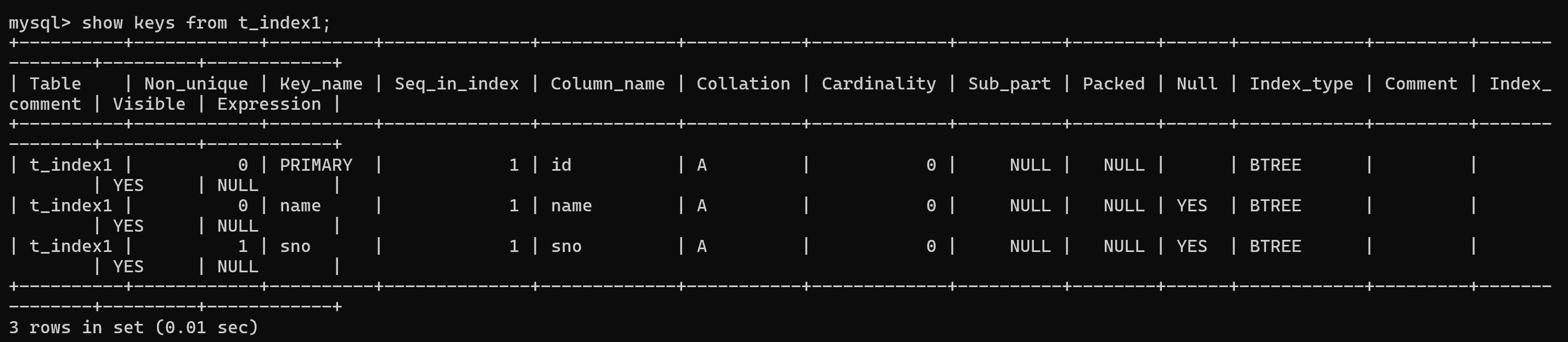
2. 方式二:修改表中的列为普通索引列
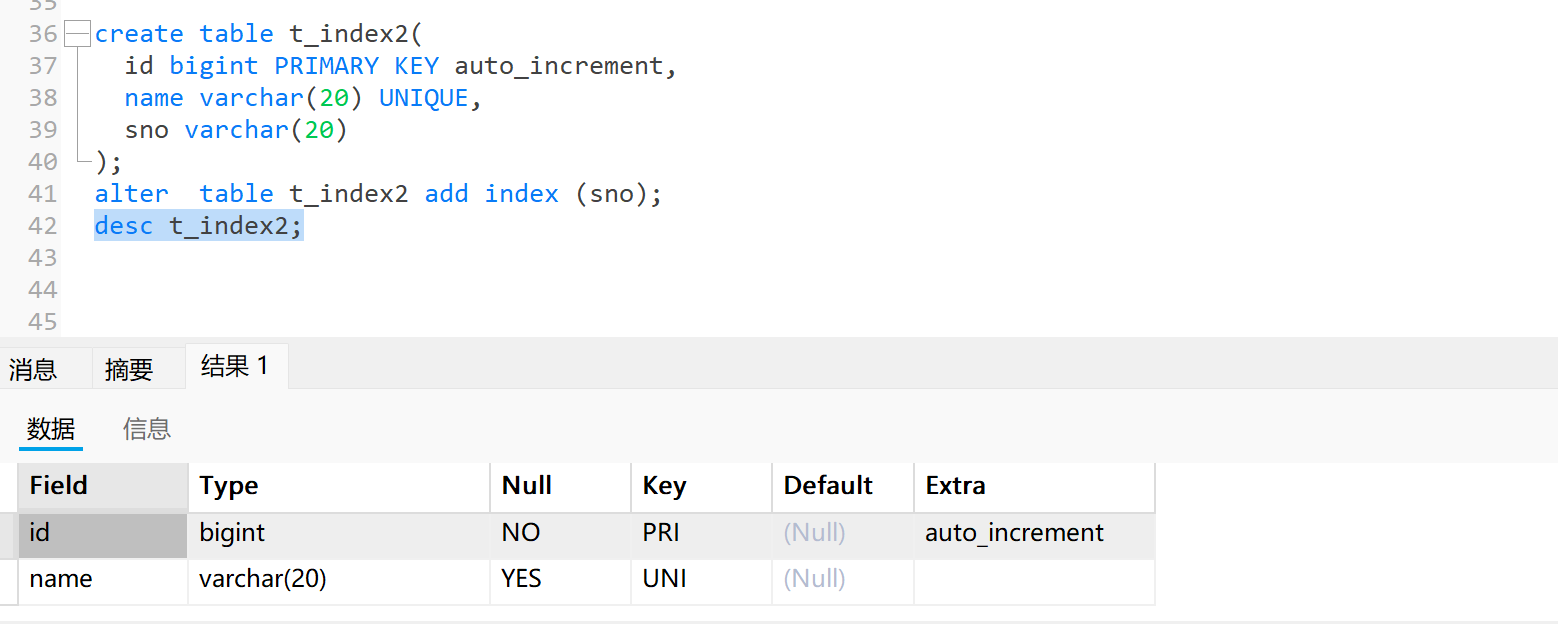
create table t_index2(id bigint PRIMARY KEY auto_increment,name varchar(20) UNIQUE,sno varchar(20)
);
alter table t_index2 add index (sno);
desc t_index2;- 方式三:单独创建索引并指定索引名
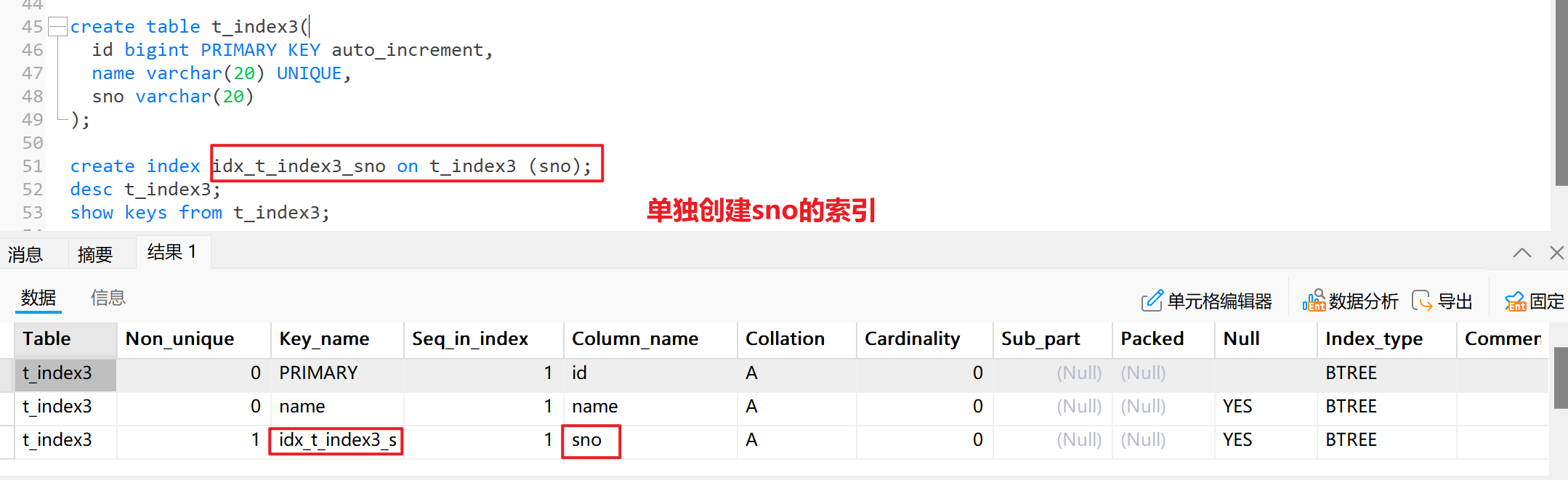
create table t_index3(id bigint PRIMARY KEY auto_increment,name varchar(20) UNIQUE,sno varchar(20)
);create index idx_t_index3_sno on t_index3 (sno);
desc t_index3;
show keys from t_index3;🚀唯一索引
- 方式一:创建表时指定索引列
create table t_test_index (id bigint primary key auto_increment,name varchar(20) uniquesno varchar(10),index(sno)
);
- 方式二:修改表中的列为普通索引
create table t_test_index1 (id bigint primary key auto_increment,name varchar(20),sno varchar(10)
);
alter table t_test_index1 add index (sno) ;
- 方式三:单独创建索引并指定索引名
create table t_test_index2 (id bigint primary key auto_increment,name varchar(20),sno varchar(10)
);
create index index_name on t_test_index2(sno);
使用create index 创建索引

🚀复合索引
索引中包含多个列
创建语法和创建普通索引的方式相同,只不过指定多个列,列与列之间用逗号隔开
- 方式一:创建表时指定索引列
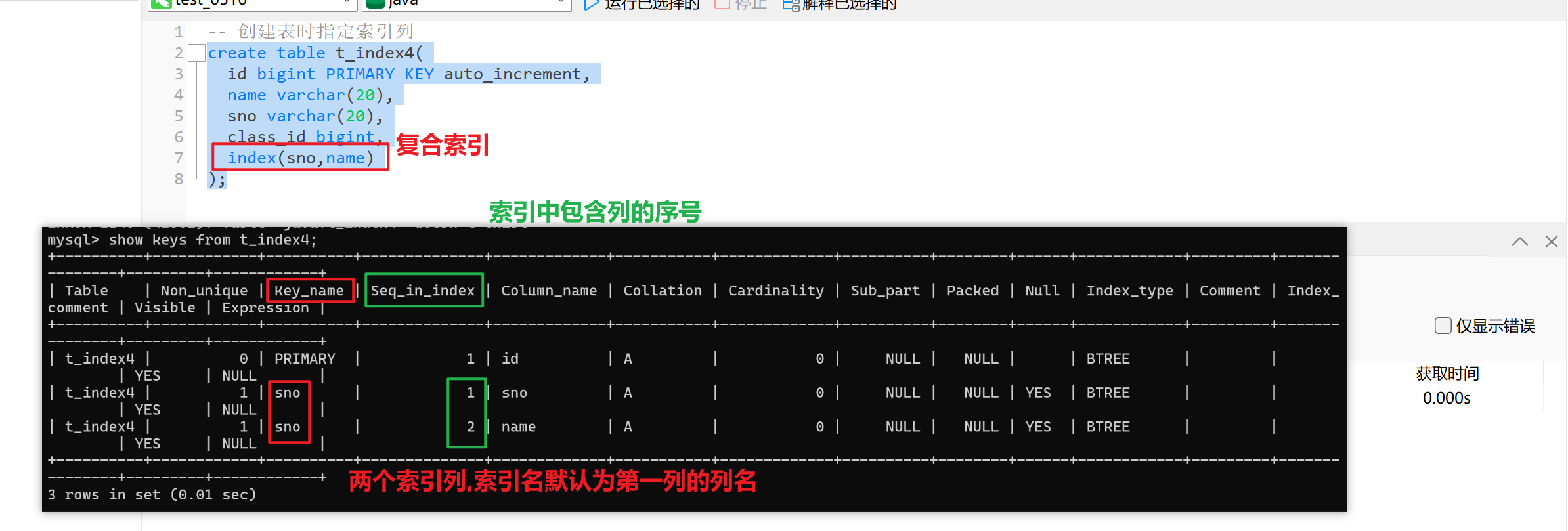
create table t_index4(id bigint PRIMARY KEY auto_increment,name varchar(20),sno varchar(20),class_id bigint,index(sno,name)
);
- 方式二:修改表中的列为复合索引
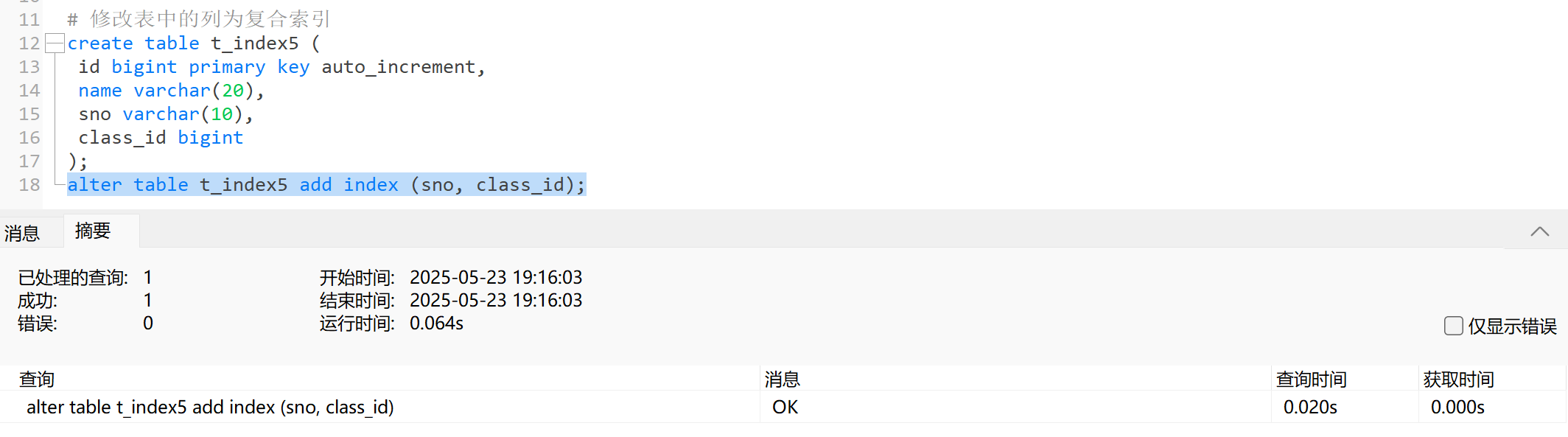
create table t_index5 (id bigint primary key auto_increment,name varchar(20),sno varchar(10),class_id bigint
);
alter table t_index5 add index (sno, class_id);
- 方式三:单独创建索引并指定索引名
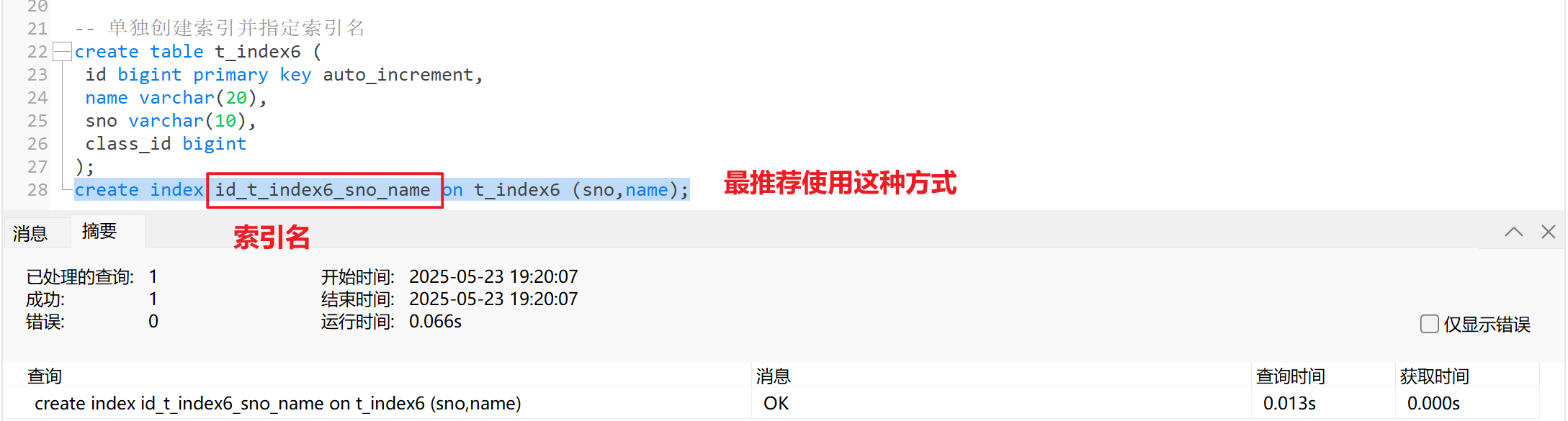
create table t_index6 (id bigint primary key auto_increment,name varchar(20),sno varchar(10),class_id bigint
);
create index id_t_index6_sno_name on t_index6 (sno,name);
🪐查看索引
-
方式一:show keys from 表名\G;
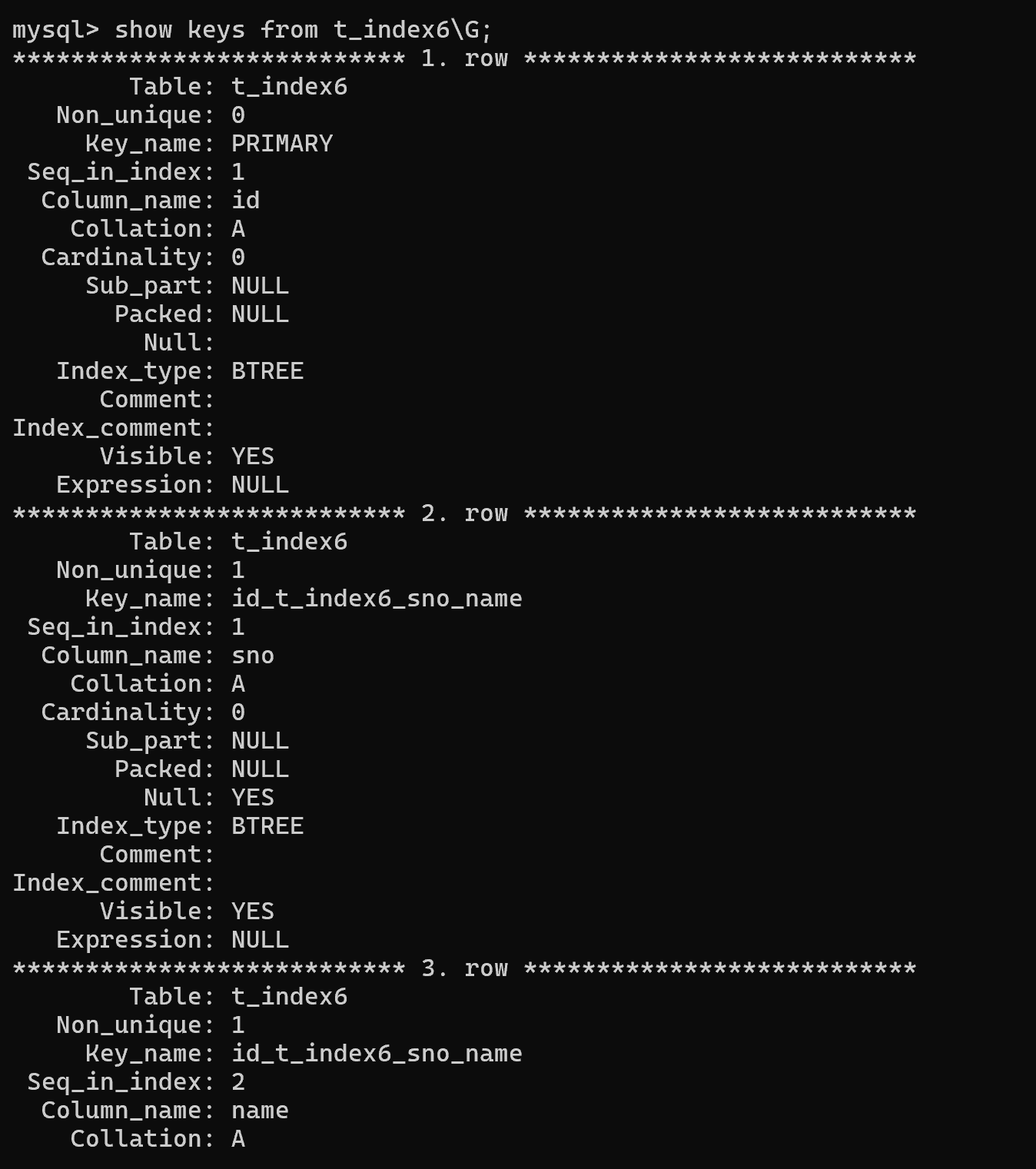
-
方式二: show index from 表名;
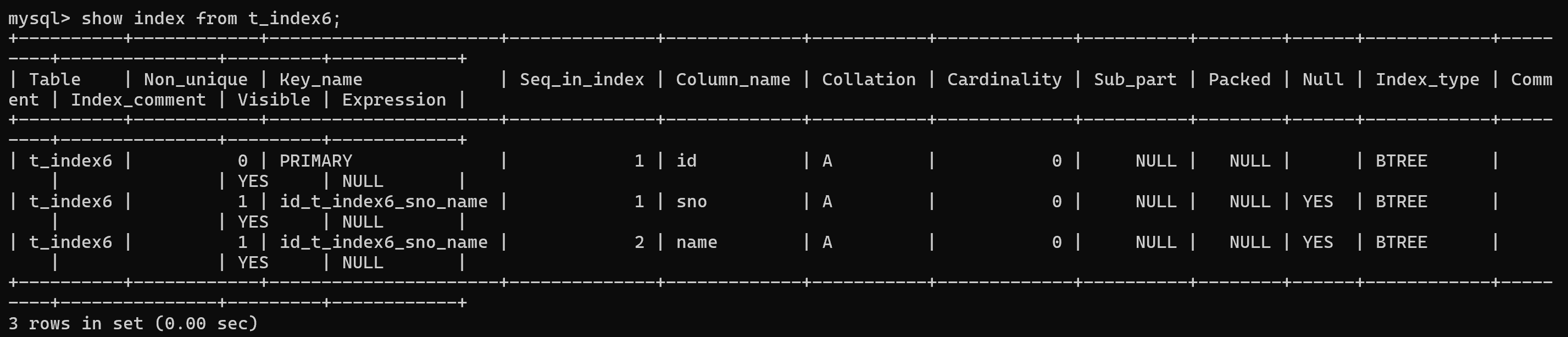
-
方式三:简要信息 desc 表名;
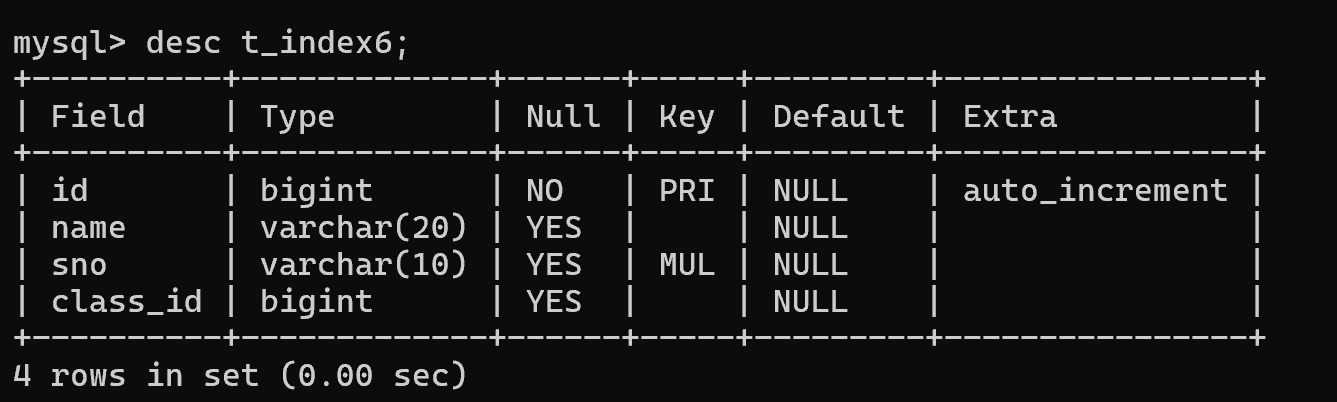
🪐删除索引
🚀删除主键索引
语法:
alter table 表名 drop primary key ;


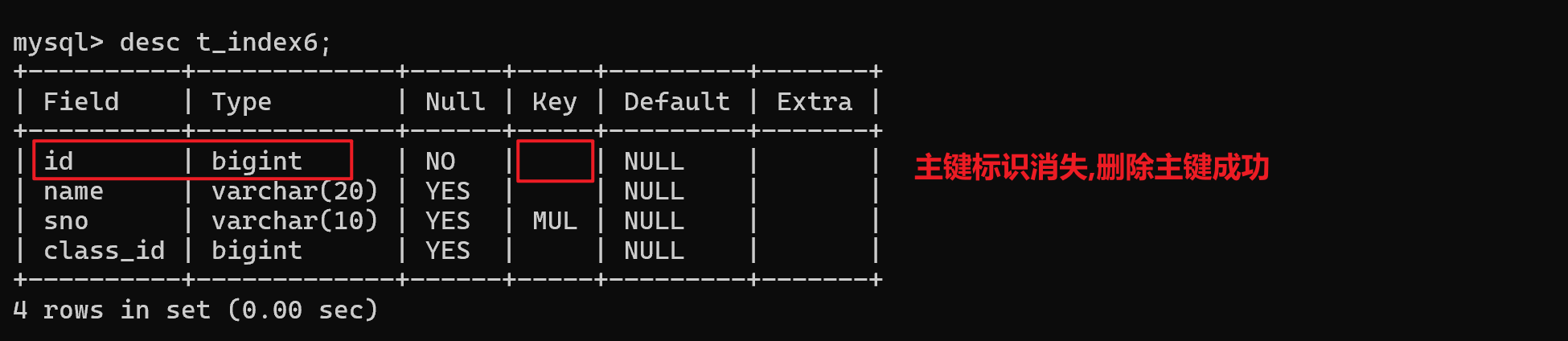
🚀删除其他索引
语法:
alter table 表名 drop index 索引名;

🌏查看执行计划
怎么查看自己写的SQL走没走索引?
–查看执行计划
- 先为学生表创建一个索引(复合索引)
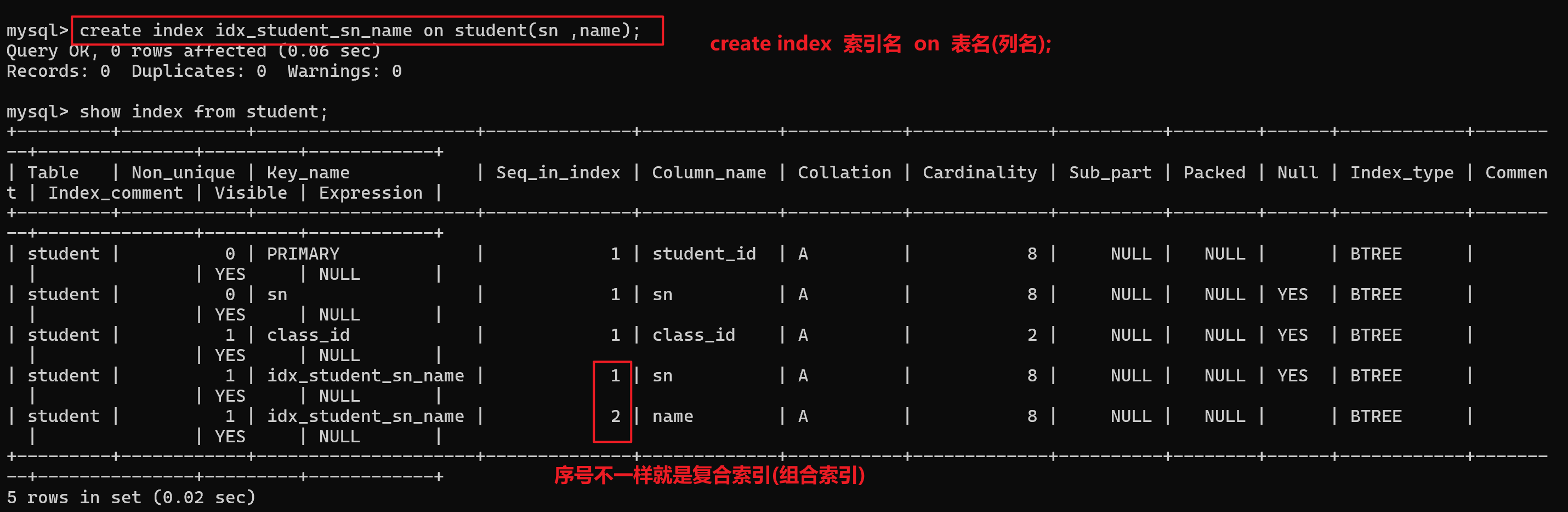
- 1.不加条件,查询所有(全表扫描)

- 2.使用主键查询
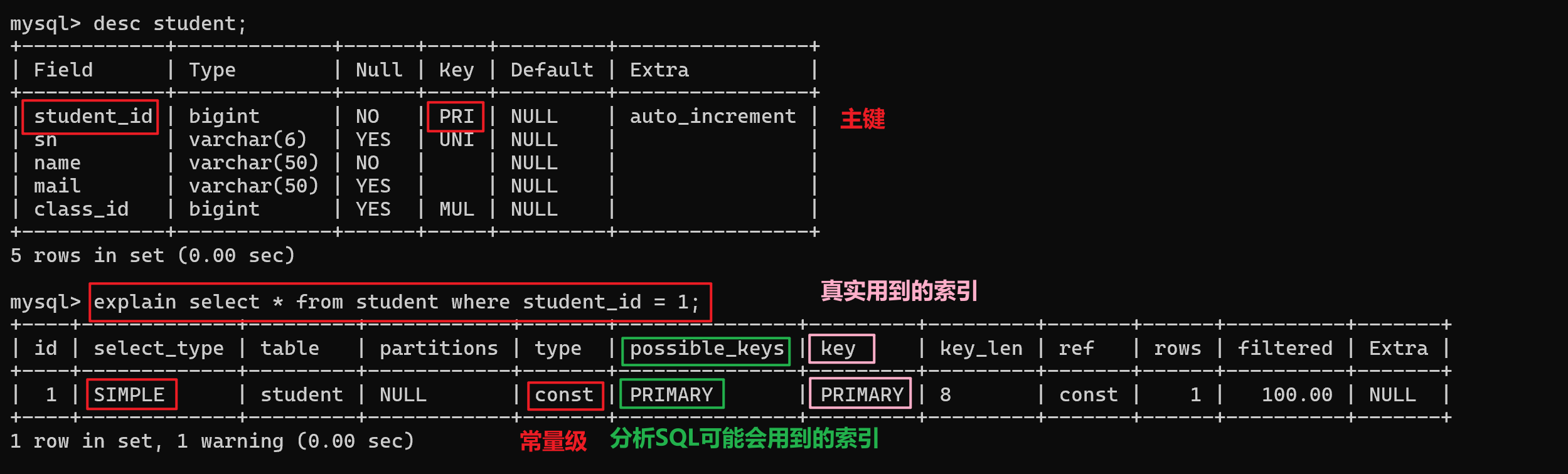
-
- 子查询中使用索引

- 子查询中使用索引
type类型:

-
4.使用普通索引

-
5.使用复合索引
回表查询

索引覆盖
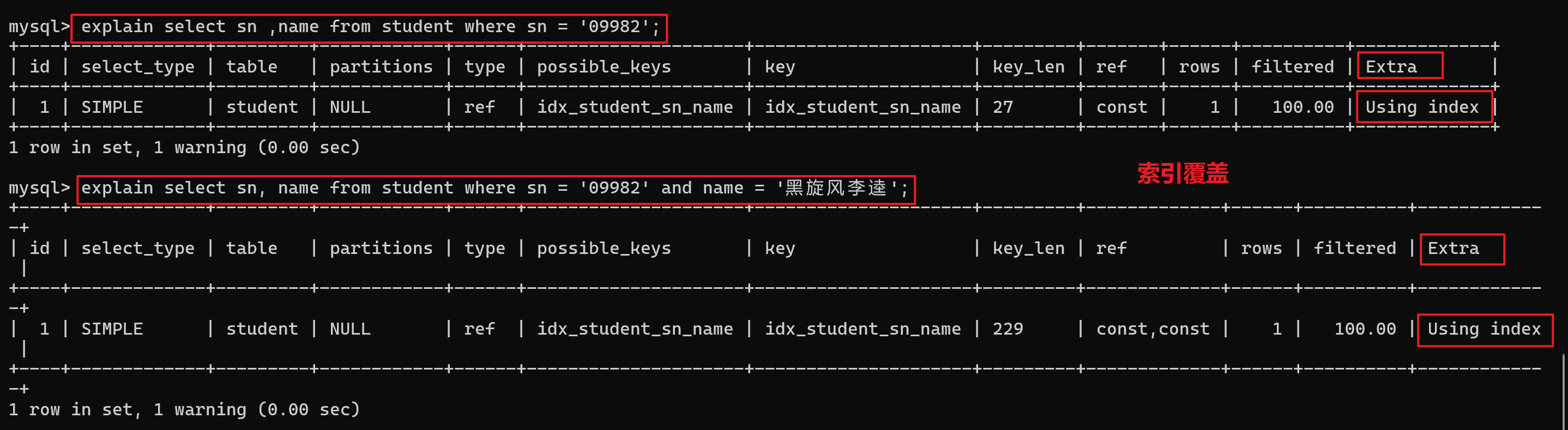

Extra: 执行情况的说明和描述,包含不适合在其他列中显示但十分重要的额外信息。
1.Using index: 表示使用索引,如果只有Using index,说明他没有查询到数据表,只用索引表就完成了这个查询,这个叫覆盖索引。
2.Using where: 表示条件查询,如果不读取表的所有数据,或不是仅仅通过索引就可以获取所有需要的数据,则会出现Using where。





