提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 摘要
- Abstract
- 一、DELTA:基于多级内存的文档代理
- 1.现有LLM在机器翻译中的不足
- 2.模型设计
- 二、实验
- 1.实验设置
- 2.实验代码
- 3.实验结果
- 总结
摘要
本博客介绍了论文聚焦文档级机器翻译(DocMT)中大型语言模型(LLMs)面临的翻译不一致和不准确问题,提出基于多级记忆组件的在线文档级翻译代理DELTA。DELTA采用多级记忆结构,包括专有名词记录、双语摘要、长期和短期记忆,存储不同粒度和跨度的信息。实验表明,DELTA在翻译一致性和质量上显著优于基线方法,能避免句子遗漏,降低内存消耗。此外,DELTA还能提高代词和上下文依赖翻译的准确性,其摘要组件可用于基于查询的摘要任务。不过,DELTA推理效率有待提高,文章提出了一些潜在的优化方向。
Abstract
This blog introduces a paper that focuses on the issues of translation inconsistency and inaccuracy faced by large language models (LLMs) in document-level machine translation (DocMT), and proposes DELTA, an online document-level translation agent based on a multi-level memory component. DELTA adopts a multi-level memory structure, including proper noun records, bilingual summaries, long-term and short-term memory, to store information of different granularities and spans. Experiments show that DELTA significantly outperforms baseline methods in translation consistency and quality, avoids sentence omissions, and reduces memory consumption. Additionally, DELTA can improve the accuracy of pronoun and context-dependent translations, and its summary component can be used for query-based summarization tasks. However, the inference efficiency of DELTA needs to be improved, and the paper proposes some potential optimization directions.
一、DELTA:基于多级内存的文档代理
1.现有LLM在机器翻译中的不足
由于llm固有的最大上下文限制,在一次传递中翻译冗长的文档变得不可行的。传统的策略是将文档分割成更小的翻译窗口,然后依次翻译。,研究中最初利用GPT-3.5-turbo-0125模型来翻译IWSLT2017 En⇒Zh测试集,该测试集包括来自TED演讲的12个文档。使用大小为l的窗口来促进文档翻译,其中l个源句子被同时处理以生成l个假设句子。一旦所有的源句子都被翻译完,它们就会被连接起来,形成完整的目标文档。与docmt - llm相关的主要挑战来自以下两个方面。翻译不一致性给定源文档Ds= (s1,s2,…,sN)及其对应的目标文档Dt存在专有名词p∈p (p表示Ds中所有专有名词的集合,包括人、= (t1,t2,…,tN),如果地点和组织的名称),并且p在Ds出现多次,结果期望其翻译在Dt中的所有出现应该是一致的。
为了判断专有名词的翻译结果是否一致,在论文中引入了两个指标: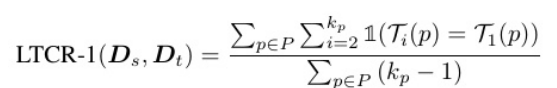
引入LTCR-1指标,该指标计算专有名词翻译与文档中初始翻译一致的比例,Ti§表示Dt中p的第i次翻译,kp表示p在文档中出现的次数。如果Ti §和T1§的译文相同,指示函数1(Ti§=T1§)返回1,否则返回0。分子是专有名词再次出现的次数,并且它们的翻译保持与第一次出现的次数相同,分母表示除第一次出现外所有专有名词的所有出现次数的总和。
为了减轻对齐工具的错误影响,研究者引入了这个度量的模糊匹配版本,当一个是另一个的子串时,两个专有名词的翻译被认为是一致的:
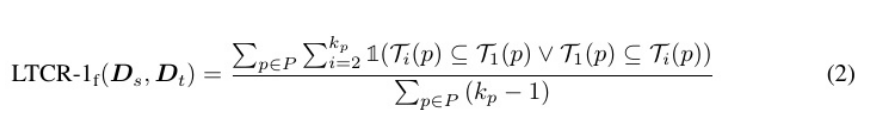
持续增加窗口大小会导致在所有三个一致性指标上得分更高。这表明,当在单个翻
译过程中处理更多的句子时,LLM能够更好地对话语现象进行建模,并在整个文档中保持专有名词的一致翻译。然而,由于llm上下文长度的固有限制,解决翻译不一致问题不能仅仅通过无限扩大窗口大小来实现。
2.模型设计
考虑到文档翻译过程中关键信息的多粒度、多尺度,引入了在线文档翻译代理DELTA。DELTA采用多级记忆流来捕获和保存整个翻译过程中遇到的关键信息。这种记忆流容纳了广泛的视角,从近期到历史,从具体到抽象,从粗粒度到细粒度的细节。DELTA以逐句的方式翻译源文档,同时实时更新其内存。这种方法解决了大型语言模型的上下文限制,并确保生成句子级对齐的目标文档,从而既保证了翻译的质量又保证了翻译的严谨性。DELTA的主要框架如下图所示:
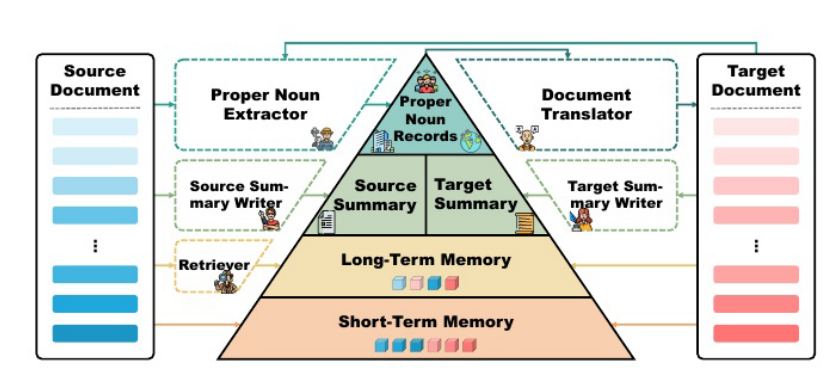
专有名词记录介绍的代理的记忆组件的第一层是一个称为专有名词记录R的字典,用于在文档中存储专有名词p以及它们在文档中第一次遇到时的翻译T1§:R(i)= {(p,T1§)| p∈sj,1≤j < i},其中R(i)表示R在翻译第i个句子之前的状态,同样适用于其他组件。在翻译后续句子si时,代理会查询R(i),获取所有记录的专有名词,这些专有名词也包含在si:Rˆ(i)={(p,T1§)| p∈si,(p,T1§)∈R(i)})中。{(p,T1§)| p∈si,(p,T1§)∈R(i)})中。
专有名词记录由一个称为专有名词提取器LExtract的基于llm的组件不断更新。在每个句子被翻译之后,它从源句子中提取新发现的专有名词,并从目标句子中提取它们的译文,粽()={(p,Tj§) | p∈si,§,∀(p’,,p =)并将它们添加到R中。
双语摘要方法作为代理的记忆组件的第二层,以解决源端和目标端广泛上下文的挑战。在整个翻译过程中保持一对摘要,以提高准确性和流畅性。Source-Side SummaryAs封装了文档先前翻译部分的主要内容、领域、风格和语气。该摘要用于保持对文本整体上下文的连贯理解,从而帮助法学硕士产生更准确的翻译。相反,目标端摘要At只关注先前翻译的目标文本的主要内容。
这对摘要由代理的两个基于llm的组件生成:源摘要编写器LWriteS和目标摘要编写器LWriteT。这些摘要通过两个步骤的过程每m个句子更新一次。最初,作者从源文本和目标文本中为最后m个句子生成片段摘要:A˜(i+1)
s=LWriteS(si−m+1,…,si),

将这些片段摘要与之前双方进行汇总合并的总体摘要合并,得到新的总体摘要:As (i+1) = LMergeS(As (i), A ~ s(i+1)), At(i+1) = LMergeT(At)(i), A ~ t(i+1))。这个过程迭代重复,直到源文档中的所有句子都被读完。
长期和短期记忆代理的记忆组件的最后两层分别是长期记忆和短期记忆。这两个组件旨在解决跨文档级翻译所需的一致性。短期记忆M保留了最后k个源句子及其相应的翻译,其中k代表一个相对较小的数字:M(i)={(si−k,ti−k),…,(si−1,ti−1)}。该组件专门用于捕获相邻句子中的即时上下文信息,然后将其无缝集成到翻译提示中,作为当前句子的上下文。
文档翻译器使用一个名为文档翻译器LTranslate的基于LLMS的组件来执行最终的翻译过程。来自多级存储器的信息被集成到提示符中,以支持翻译人员产生高质量和一致的翻译:ti=LTranslate(si,Rˆ(i),Nˆ(i),A(i)s,At ,M(i))。逐句的方法确保了生成的目标文档(i)在句子级别上与源文档保持一致,有效地将目标句子缺失的风险降至最低。此外,该方法允许使用句子级度量(如sCOMET)直接评估翻译质量。
二、实验
1.实验设置
研究者在两个测试集上进行实验。第一个是来自IWSLT翻译任务测试集,它由来自TED演讲的并行文档组成,涵盖12对语言。实验是在八种语言对上进行的:En⇔Zh、De、Fr和Ja。有10到12个句子级对齐平行每个语言对大约有1.5K个句子的文档。二是国丰网络小说7,一个高质量的、话语级的网络小说语料库。在Zh⇒En方向的国丰V1 TEST 2装置上进行实验。使用LTCR-1和LTCR-1f进行专有名词翻译一致性评估,并采用sCOMET和dCOMET作为翻译质量指标。
模型和超参数在这项工作中,使用GPT模型的两个版本,GPT-3.5- turbo -0125和GPT-40 -mini作为我们的基础模型。我们通过OpenAI8提供的官方API来访问这些模型。实验中介绍了开源的Qwen2-7B-Instruct9和Qwen2-72B-Instruct10。最大新令牌设置为2048,其他超参数保持默认值。双语摘要m和长期记忆长度l的更新窗口设置为20。从长期记忆n中检索的相对句子的数量设置为2。短期记忆k的长度设置为3。
2.实验代码
完整项目链接:https://github.com/YutongWang1216/DocMTAgent。
以下是模型的实现机器翻译逻辑的关键代码:
import argparse
import numpy as np
from numpy.linalg import norm
import json
from typing import Tuple, Union, List
from tqdm import tqdm
from copy import deepcopy
import random
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import osTRANS_CNT = 0sep_map = {'zh': '', 'ja': '', 'en': ' ', 'de': ' ', 'fr': ' '}
SRC_SEP, TGT_SEP = None, Nonelang_dict = {'zh': 'Chinese', 'ja': 'Japanese', 'en': 'English', 'de': 'German', 'fr': 'French'}model, tokenizer = None, Nonedef invoke_chat(prompt: str) -> str:messages = [{"role": "user", "content": prompt},]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(device)generated_ids = model.generate(**model_inputs, max_new_tokens=2048)generated_ids = [output_ids[len(input_ids) :]for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]return responsedef cosine_similarity(a: Union[np.array, List], b: Union[np.array, List]):if isinstance(a, list):a = np.array(a)if isinstance(b, list):b = np.array(b)return np.dot(a, b) / (norm(a) * norm(b))class EmbeddingDict():def __init__(self, total: int, recency_weight: float, similarity_weight: float, skip_context: int) -> None:self.embedding_list = []self.src_text_list = []self.tgt_text_list = []self.total = totalassert recency_weight + similarity_weight == 10.0, "The weights should be added up to 10!"self.recency_weight = recency_weight / 10.0self.similarity_weight = similarity_weight / 10.0def insert(self, new_src: str, new_tgt: str) -> None:if self.total == -1 or len(self.embedding_list) < self.total:self.src_text_list.append(new_src)self.tgt_text_list.append(new_tgt)else:self.src_text_list = self.src_text_list[1:] + [new_src]self.tgt_text_list = self.tgt_text_list[1:] + [new_tgt]def match(self, query: str, num: int) -> Tuple[List[str]]:if len(self.embedding_list) <= num:return (self.src_text_list, self.tgt_text_list)query_embedding = invoke_embedding(query)sim_list = [cosine_similarity(query_embedding, i) for i in self.embedding_list]rec_list = [i / (len(self.embedding_list) - 1) for i in range(len(self.embedding_list))]score_list = [self.recency_weight * i + self.similarity_weight * j for i, j in zip(rec_list, sim_list)]idx_list = list(range(len(score_list)))idx_list.sort(key=lambda x: score_list[x], reverse=True)if self.total == -1 or len(self.embedding_list) < self.total:self.embedding_list.append(query_embedding)else:self.embedding_list = self.embedding_list[1:] + [query_embedding]return ([self.src_text_list[i] for i in idx_list[:num]], [self.tgt_text_list[i] for i in idx_list[:num]])class RetrieveAgent():def __init__(self, total: int, recency_weight: float, similarity_weight: float, prompt_template: str, skip_context: int) -> None:self.src_text_list = []self.tgt_text_list = []self.total = totalassert recency_weight + similarity_weight == 10.0, "The weights should be added up to 10!"self.recency_weight = recency_weight / 10.0self.similarity_weight = similarity_weight / 10.0self.prompt_template = prompt_templateself.example_number = Nonedef insert(self, new_src: str, new_tgt: str) -> None:if self.total == -1 or len(self.src_text_list) < self.total:self.src_text_list.append(new_src)self.tgt_text_list.append(new_tgt)else:self.src_text_list = self.src_text_list[1:] + [new_src]self.tgt_text_list = self.tgt_text_list[1:] + [new_tgt]def match(self, query: str, num: int) -> Tuple[List[str]]:if len(self.src_text_list) <= num:return (self.src_text_list, self.tgt_text_list)sent_list = ''for idx, src in enumerate(self.src_text_list):sent_list += f'<Sentence {idx + 1}> {src}\n'sent_list = sent_list.strip()if self.example_number is None or len(self.example_number) != num:random.seed(0)self.example_number = random.sample(list(range(max(10, num))), num)self.example_number.sort()example_num_prompt = [str(i) for i in self.example_number]example_num_prompt = ', '.join(example_num_prompt[:-1]) + ' and ' + example_num_prompt[-1] if num > 1 else example_num_prompt[0]example_list_prompt = str(self.example_number)prompt = self.prompt_template.format(top_num=num,sentence_list=sent_list,example_number=example_num_prompt,example_list=example_list_prompt,query=query)chosen_ids = invoke_chat(prompt)if chosen_ids is None:return ([], [])try:chosen_ids = eval(chosen_ids)except Exception as e:chosen_ids = []chosen_ids = [i for i in chosen_ids if type(i) is int and 1 <= i <= len(self.src_text_list)]chosen_ids.sort()return ([self.src_text_list[i-1] for i in chosen_ids], [self.tgt_text_list[i-1] for i in chosen_ids])def init_memory(approach: str):if approach == 'embedding':class LongTimeMemory(EmbeddingDict):def __init__(self, total: int, recency_weight: float, similarity_weight: float, skip_context: int) -> None:super().__init__(total, recency_weight, similarity_weight, skip_context)elif approach == 'agent':class LongTimeMemory(RetrieveAgent):def __init__(self, total: int, recency_weight: float, similarity_weight: float, prompt_template: str, skip_context: int) -> None:super().__init__(total, recency_weight, similarity_weight, prompt_template, skip_context)else:print('The approach of the retriever must be "embedding" or "agent"!')return LongTimeMemorydef translate(src_lang: str, tgt_lang:str,src_text: str,rel_src_sents: List[str], rel_tgt_sents: List[str],src_summary: str, tgt_summary: str,historical_prompt: str,src_context: list, tgt_context: list, context_window: int,prompt_template: str) -> dict:if rel_src_sents is None or len(rel_src_sents) == 0:rel_instances = 'N/A'else:rel_instances = ''for rel_src, rel_tgt in zip(rel_src_sents, rel_tgt_sents):rel_instances += f'<{lang_dict[src_lang]} source> {rel_src}\n<{lang_dict[tgt_lang]} translation> {rel_tgt}\n'rel_instances = rel_instances.strip()if src_summary is None:src_summary = 'N/A'if tgt_summary is None:tgt_summary = 'N/A'if historical_prompt is None or historical_prompt == '':historical_prompt = 'N/A'if src_context is None or len(src_context) == 0:src_context_prompt, tgt_context_prompt = 'N/A', 'N/A'else:global SRC_SEP, TGT_SEPsrc_context_prompt = SRC_SEP.join(src_context)tgt_context_prompt = TGT_SEP.join(tgt_context)prompt = prompt_template.format(src_lang=lang_dict[src_lang],tgt_lang=lang_dict[tgt_lang],src_summary=src_summary,tgt_summary=tgt_summary,rel_inst=rel_instances,src=src_text,hist_info=historical_prompt,src_context=src_context_prompt,tgt_context=tgt_context_prompt,context_window=context_window,)hyp = invoke_chat(prompt)if hyp is None:hyp = ''else:hyp = hyp.split('\n')[0]global TRANS_CNTif (TRANS_CNT + 1) % 10 == 0:print('\n\nprompt:')print(prompt + '\n\n')TRANS_CNT += 1return hypclass Summary():def __init__(self, src_gen_template: str, tgt_gen_template: str, src_merge_template: str, tgt_merge_template: str) -> None:self.src_summary = Noneself.tgt_summary = Noneself.src_gen_template = src_gen_templateself.tgt_gen_template = tgt_gen_templateself.src_merge_template = src_merge_templateself.tgt_merge_template = tgt_merge_templatedef set_summary(self, s_sum: str, t_sum) -> None:self.src_summary = s_sumself.tgt_summary = t_sumdef gen_summary(self, record_list: List[dict]) -> Tuple[str]:src_list = [i['src'] for i in record_list]hyp_list = [i['hyp'] for i in record_list]src_para = SRC_SEP.join(src_list)hyp_para = TGT_SEP.join(hyp_list)prompt = self.src_gen_template.format(src_para=src_para)src_summary = invoke_chat(prompt)prompt = self.tgt_gen_template.format(src_para=hyp_para)tgt_summary = invoke_chat(prompt)return (src_summary, tgt_summary)def merge_summary(self, src_new_sum, tgt_new_sum) -> Tuple[str]:if self.src_summary is None:return (src_new_sum, tgt_new_sum)prompt = self.src_merge_template.format(summary_1=self.src_summary, summary_2=src_new_sum)src_sum = invoke_chat(prompt)prompt = self.tgt_merge_template.format(summary_1=self.tgt_summary, summary_2=tgt_new_sum)tgt_sum = invoke_chat(prompt)return (src_sum, tgt_sum)def update_summary(self, record_list: List[dict]) -> Tuple[str]:tmp_src_summary, tmp_tgt_summary = self.gen_summary(record_list)self.src_summary, self.tgt_summary = self.merge_summary(tmp_src_summary, tmp_tgt_summary)return (self.src_summary, self.tgt_summary)def get_summary(self) -> Tuple[str, str]:return (self.src_summary, self.tgt_summary)class History():def __init__(self, prompt_template: str, src_lang: str, tgt_lang: str) -> None:self.src_lang = src_langself.tgt_lang = tgt_langself.entity_dict = dict()self.prompt_template = prompt_templatedef extract_entity(self, src: str, tgt: str) -> List[str]:prompt = self.prompt_template.format(src_lang=lang_dict[self.src_lang],tgt_lang=lang_dict[self.tgt_lang],src=src,tgt=tgt)new_info = invoke_chat(prompt)conflicts = list()if new_info is not None and new_info not in ['N/A', 'None', '', '无']:new_proper_noun_pairs = new_info.split(', ')for ent_pair in new_proper_noun_pairs:if len(ent_pair.split(' - ')) == 2:src_ent, tgt_ent = ent_pair.split(' - ')src_ent = src_ent.replace('\"', '').replace('\'', '')tgt_ent = tgt_ent.replace('\"', '').replace('\'', '')if self.entity_dict.get(src_ent, '') == '':self.entity_dict[src_ent] = tgt_ent if tgt_ent != 'N/A' else src_entelif self.entity_dict[src_ent] != tgt_ent:conflicts.append(f'"{src_ent}" - "{self.entity_dict[src_ent]}"/"{tgt_ent}"')return conflictsdef buildin_history(self, sentence: str, only_relative: bool) -> str:if only_relative:entity_list = [ent for ent in self.entity_dict if ent in sentence]hist_list = [f'"{ent}" - "{self.entity_dict[ent]}"' for ent in entity_list if ent in self.entity_dict]hist_prompt = ', '.join(hist_list)return hist_promptelse:hist_list = [f'"{ent}" - "{self.entity_dict[ent]}"' for ent in self.entity_dict]hist_prompt = ', '.join(hist_list)return hist_promptdef get_history_dict(self) -> dict:return deepcopy(self.entity_dict)def set_history_dict(self, h_dict: dict) -> None:self.entity_dict = h_dictclass Context():def __init__(self, window_size: int) -> None:self.windows_size = window_sizeself.src_context = []self.tgt_context = []def update(self, src: str, tgt: str) -> None:if self.windows_size == -1:self.src_context.append(src)self.tgt_context.append(tgt)else:self.src_context = self.src_context[-(self.windows_size - 1):] + [src]self.tgt_context = self.tgt_context[-(self.windows_size - 1):] + [tgt]def get_context(self) -> Tuple[List[str]]:return (self.src_context, self.tgt_context)def init(args, src_sum_tpl, tgt_sum_tpl, src_mer_tpl, tgt_mer_tpl, src_lang, tgt_lang):trans_context, long_memory, doc_summary, ent_history = None, None, None, Noneif 'context' in args.settings:trans_context = Context(args.context_window)if 'long' in args.settings:LongMemory = init_memory(args.retriever)if args.retriever == 'agent':with open(args.retrieve_prompt) as trf:long_tpl = trf.read()long_memory = LongMemory(args.long_window, args.recency_weight, args.similarity_weight, long_tpl, args.context_window)else:long_memory = LongMemory(args.long_window, args.recency_weight, args.similarity_weight, args.context_window)if 'summary' in args.settings:doc_summary = Summary(src_sum_tpl, tgt_sum_tpl, src_mer_tpl, tgt_mer_tpl)if 'history' in args.settings:with open(args.history_prompt) as thf:history_tpl = thf.read()ent_history = History(history_tpl, src_lang, tgt_lang)trans_records = []if os.path.isfile(args.output):with open(args.output, 'r') as f:trans_records = json.load(f)for record in trans_records:if doc_summary is not None and 'new_src_summary' in record:doc_summary.set_summary(record['new_src_summary'], record['new_tgt_summary'])if long_memory is not None:long_memory.insert(record['src'], record['hyp'])if ent_history is not None:ent_history.set_history_dict(record['entity_dict'])if 'context' in args.settings:trans_context.update(record['src'], record['hyp'])return trans_context, long_memory, doc_summary, ent_history, trans_recordsdef main():src_lang = args.language[:2]tgt_lang = args.language[-2:]global SRC_SEP, TGT_SEPSRC_SEP, TGT_SEP = sep_map[src_lang], sep_map[tgt_lang]with open(args.src, 'r') as sf:src_list = [line.strip() for line in sf]if args.ref:with open(args.ref, 'r') as rf:ref_list = [line.strip() for line in rf]with open(args.src_summary_prompt, 'r') as ssf, open(args.tgt_summary_prompt, 'r') as tsf, \open(args.src_merge_prompt, 'r') as smf, open(args.tgt_merge_prompt, 'r') as tmf, \open(args.trans_prompt, 'r') as tf:src_sum_tpl = ssf.read()tgt_sum_tpl = tsf.read()src_mer_tpl = smf.read()tgt_mer_tpl = tmf.read()trans_tpl = tf.read()if 'context' not in args.settings:args.context_window = 0trans_context, long_memory, doc_summary, ent_history, trans_records = init(args, src_sum_tpl, tgt_sum_tpl, src_mer_tpl, tgt_mer_tpl, src_lang, tgt_lang)print(f'### Resuming from {len(trans_records)} records...')if len(trans_records) >= len(src_list):exit()else:global tokenizer, modeltokenizer = AutoTokenizer.from_pretrained(modelpath, cache_dir=modelpath)model = AutoModelForCausalLM.from_pretrained(modelpath, cache_dir=modelpath, torch_dtype="auto", device_map="auto")for idx in tqdm(range(len(trans_records), len(src_list), 1)):record = dict()src = src_list[idx]ref = ref_list[idx] if args.ref else Nonelong_mem_srcs, long_mem_tgts = None, Nonesrc_summary, tgt_summary = None, Nonehist_info = Nonesrc_context, tgt_context = None, Noneif 'long' in args.settings:long_mem_srcs, long_mem_tgts = long_memory.match(src, args.top_k)long_mem_srcs, long_mem_tgts = deepcopy(long_mem_srcs), deepcopy(long_mem_tgts)if 'summary' in args.settings:src_summary, tgt_summary = doc_summary.get_summary()if 'history' in args.settings:hist_info = ent_history.buildin_history(src, args.only_relative)if 'context' in args.settings:src_context, tgt_context = trans_context.get_context()result = translate(src_lang, tgt_lang, src, long_mem_srcs, long_mem_tgts, src_summary, tgt_summary, hist_info, src_context, tgt_context, args.context_window, trans_tpl)hyp = resultrecord['idx'] = idxrecord['src'] = srcif ref:record['ref'] = refrecord['hyp'] = hypif 'summary' in args.settings and (idx + 1) % args.summary_step == 0:record['new_src_summary'], record['new_tgt_summary'] = doc_summary.update_summary(trans_records[-args.summary_step:])if 'long' in args.settings:record['rel_src'] = long_mem_srcsrecord['rel_tgt'] = long_mem_tgtslong_memory.insert(src, hyp)if 'history' in args.settings:conflict_list = ent_history.extract_entity(src, hyp)if args.only_relative:record['hist_info'] = hist_inforecord['entity_dict'] = ent_history.get_history_dict()if len(conflict_list) > 0:record['conflict'] = conflict_listif 'context' in args.settings:trans_context.update(src, hyp)trans_records.append(record)json.dump(trans_records, open(args.output, 'w'), ensure_ascii=False, indent=4)if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('-l', '--language', type=str)parser.add_argument('-s', '--src', type=str)parser.add_argument('-r', '--ref', type=str, default=None)parser.add_argument('--src_summary_prompt', type=str)parser.add_argument('--tgt_summary_prompt', type=str)parser.add_argument('--src_merge_prompt', type=str)parser.add_argument('--tgt_merge_prompt', type=str)parser.add_argument('--retrieve_prompt', type=str, default=None)parser.add_argument('--history_prompt', type=str, default=None)parser.add_argument('--trans_prompt', type=str)parser.add_argument('--summary_step', type=int, default=10)parser.add_argument('--long_window', type=int, default=10)parser.add_argument('--top_k', type=int, default=2)parser.add_argument('-o', '--output', type=str)parser.add_argument('-rw', '--recency_weight', type=float, default=0.0)parser.add_argument('-sw', '--similarity_weight', type=float, default=10.0)parser.add_argument('--only_relative', type=bool, default=True)parser.add_argument('--settings', nargs='+', type=str)parser.add_argument('--context_window', type=int, default=3)parser.add_argument('--retriever', type=str)parser.add_argument('--model', type=str)args = parser.parse_args()modelpath = args.modeldevice = "cuda"main()
3.实验结果
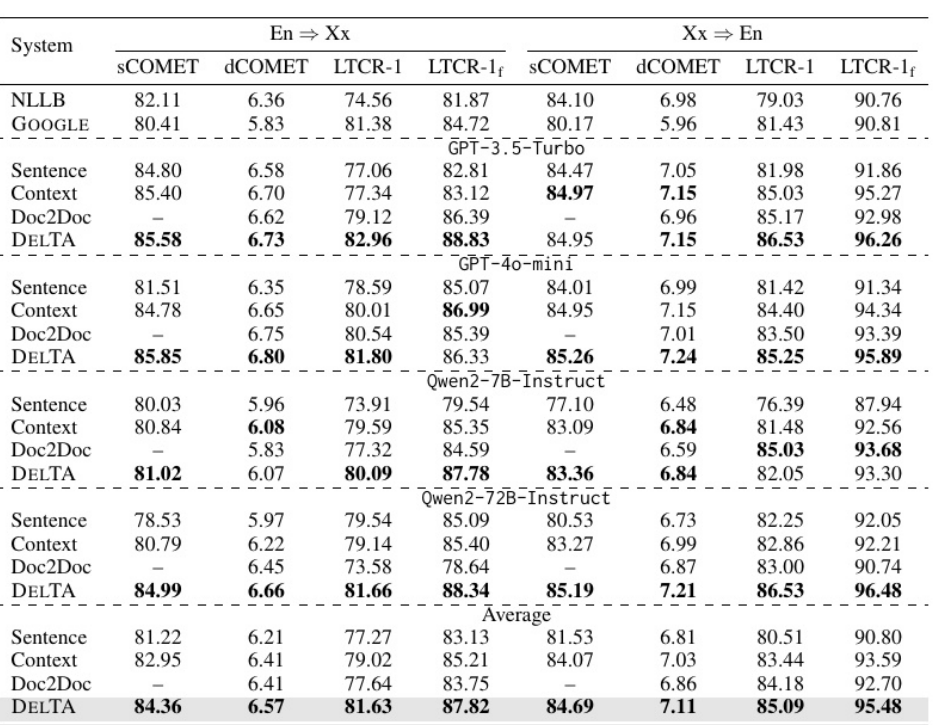
很明显,DELTA在几乎所有翻译方向和模型中都优于LTCR-1和LTCR-1f
度量分数的基线方法。这表明在文档级翻译的专有名词翻译一致性方面产生了显著的增强。此外,DELTA显著提高了文档翻译的整体质量,sCOMET和dCOMET分数一直较高就是证明。较高的dCOMET分数表明DELTA有效地捕获上下文信息以支持翻译过程。在En⇒Zh方向上,平移一致性得到了显著改善,而在En⇒De方向上的提高则不大。例如,使用GPT-3.5-Turbo, En⇒Zh的LTCR-1提高了6.17个百分点(86.44比80.27),但En⇒De的LTCR-1仅提高了1.40个百分点(93.46比92.06)(见附录D的表13)。这种差异源于语言差异:英语专有名词需要转换成汉字,这给保持一致性带来了挑战,而在德语中,由于共享字母表,它们可以直接复制。尽管如此,En⇒De中合理的LTCR-1改进仍然证明了我们方法的有效性。En⇔Xx,翻译质量DELTA与句子/上下文的t检验的p值小于0.05,而En⇔Zh,翻译一致性的t检验的p值小于0.05

总结
DELTA在代词翻译准确性(APT)和上下文依赖翻译的生成准确性上均优于基线,表明多级记忆有助于解决文档中的指代和语篇问题。与基于LLM的Doc2Doc方法相比,DELTA的内存增长缓慢,不会因处理句子数量增加而导致内存耗尽,更适合在本地设备上部署。
DELTA在不同句子距离区间内的专有名词翻译一致性几乎都优于Sentence和Context方法,在距离超过50个句子时表现更优,证明其在长上下文翻译中能有效保持一致性。短期记忆和长期记忆能提升翻译质量,但对一致性有一定负面影响,二者结合可相互补充。专有名词记录和双语摘要对翻译质量和一致性都有积极作用,且双语摘要的效果优于单源或单目标摘要。所有模块协同工作的效果最佳。





