内容来自@浙大疏锦行python打卡训练营
@浙大疏锦行
目录
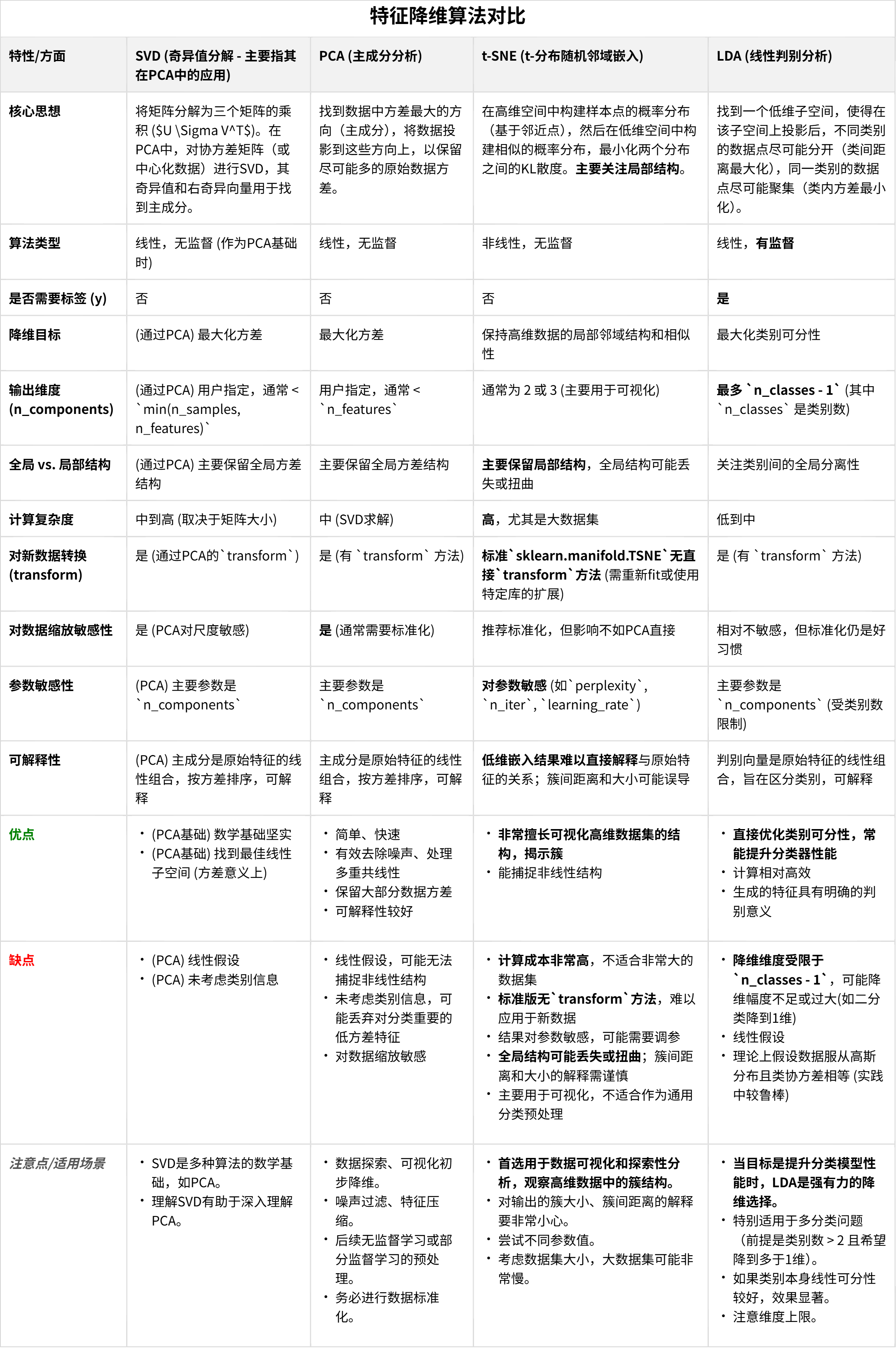
PCA主成分分析
t-sne降维
线性判别分析 (Linear Discriminant Analysis, LDA)
作业:
什么时候用到降维
降维的主要应用场景
知识点回顾:
- PCA主成分分析
- t-sne降维
- LDA线性判别
通常情况下,我们提到特征降维,很多时候默认指的是无监督降维,这种方法只需要特征数据本身。但是实际上还包含一种有监督的方法。


# 先运行之前预处理好的代码
import pandas as pd
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
import matplotlib.pyplot as plt #用于绘制各种类型的图表
import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。
import warnings
warnings.filterwarnings("ignore")# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
data = pd.read_csv('data.csv') #读取数据# 先筛选字符串变量
discrete_features = data.select_dtypes(include=['object']).columns.tolist()
# Home Ownership 标签编码
home_ownership_mapping = {'Own Home': 1,'Rent': 2,'Have Mortgage': 3,'Home Mortgage': 4
}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)# Years in current job 标签编码
years_in_job_mapping = {'< 1 year': 1,'1 year': 2,'2 years': 3,'3 years': 4,'4 years': 5,'5 years': 6,'6 years': 7,'7 years': 8,'8 years': 9,'9 years': 10,'10+ years': 11
}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)# Purpose 独热编码,记得需要将bool类型转换为数值
data = pd.get_dummies(data, columns=['Purpose'])
data2 = pd.read_csv("data.csv") # 重新读取数据,用来做列名对比
list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名
for i in data.columns:if i not in data2.columns:list_final.append(i) # 这里打印出来的就是独热编码后的特征名
for i in list_final:data[i] = data[i].astype(int) # 这里的i就是独热编码后的特征名# Term 0 - 1 映射
term_mapping = {'Short Term': 0,'Long Term': 1
}
data['Term'] = data['Term'].map(term_mapping)
data.rename(columns={'Term': 'Long Term'}, inplace=True) # 重命名列
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() #把筛选出来的列名转换成列表# 连续特征用中位数补全
for feature in continuous_features: mode_value = data[feature].mode()[0] #获取该列的众数。data[feature].fillna(mode_value, inplace=True) #用众数填充该列的缺失值,inplace=True表示直接在原数据上修改。# 最开始也说了 很多调参函数自带交叉验证,甚至是必选的参数,你如果想要不交叉反而实现起来会麻烦很多
# 所以这里我们还是只划分一次数据集data.drop(columns=['Id'], inplace=True) # 删除 Loan ID 列
data.info() # 查看数据集的信息,包括数据类型和缺失值情况输出:(目前有31个特征,我们看看降维后的特征个数是多少)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7500 entries, 0 to 7499
Data columns (total 31 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 Home Ownership 7500 non-null int64 1 Annual Income 7500 non-null float642 Years in current job 7500 non-null float643 Tax Liens 7500 non-null float644 Number of Open Accounts 7500 non-null float645 Years of Credit History 7500 non-null float646 Maximum Open Credit 7500 non-null float647 Number of Credit Problems 7500 non-null float648 Months since last delinquent 7500 non-null float649 Bankruptcies 7500 non-null float6410 Long Term 7500 non-null int64 11 Current Loan Amount 7500 non-null float6412 Current Credit Balance 7500 non-null float6413 Monthly Debt 7500 non-null float6414 Credit Score 7500 non-null float6415 Credit Default 7500 non-null int64 16 Purpose_business loan 7500 non-null int32 17 Purpose_buy a car 7500 non-null int32 18 Purpose_buy house 7500 non-null int32 19 Purpose_debt consolidation 7500 non-null int32 20 Purpose_educational expenses 7500 non-null int32 21 Purpose_home improvements 7500 non-null int32 22 Purpose_major purchase 7500 non-null int32 23 Purpose_medical bills 7500 non-null int32 24 Purpose_moving 7500 non-null int32 25 Purpose_other 7500 non-null int32 26 Purpose_renewable energy 7500 non-null int32 27 Purpose_small business 7500 non-null int32 28 Purpose_take a trip 7500 non-null int32 29 Purpose_vacation 7500 non-null int32 30 Purpose_wedding 7500 non-null int32
dtypes: float64(13), int32(15), int64(3)
memory usage: 1.3 MBfrom sklearn.model_selection import train_test_split
X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列删除
y = data['Credit Default'] # 标签from sklearn.model_selection import train_test_split
X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列删除
y = data['Credit Default'] # 标签
# 按照8:2划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集from sklearn.ensemble import RandomForestClassifier #随机森林分类器from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 用于评估分类器性能的指标
from sklearn.metrics import classification_report, confusion_matrix #用于生成分类报告和混淆矩阵
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息
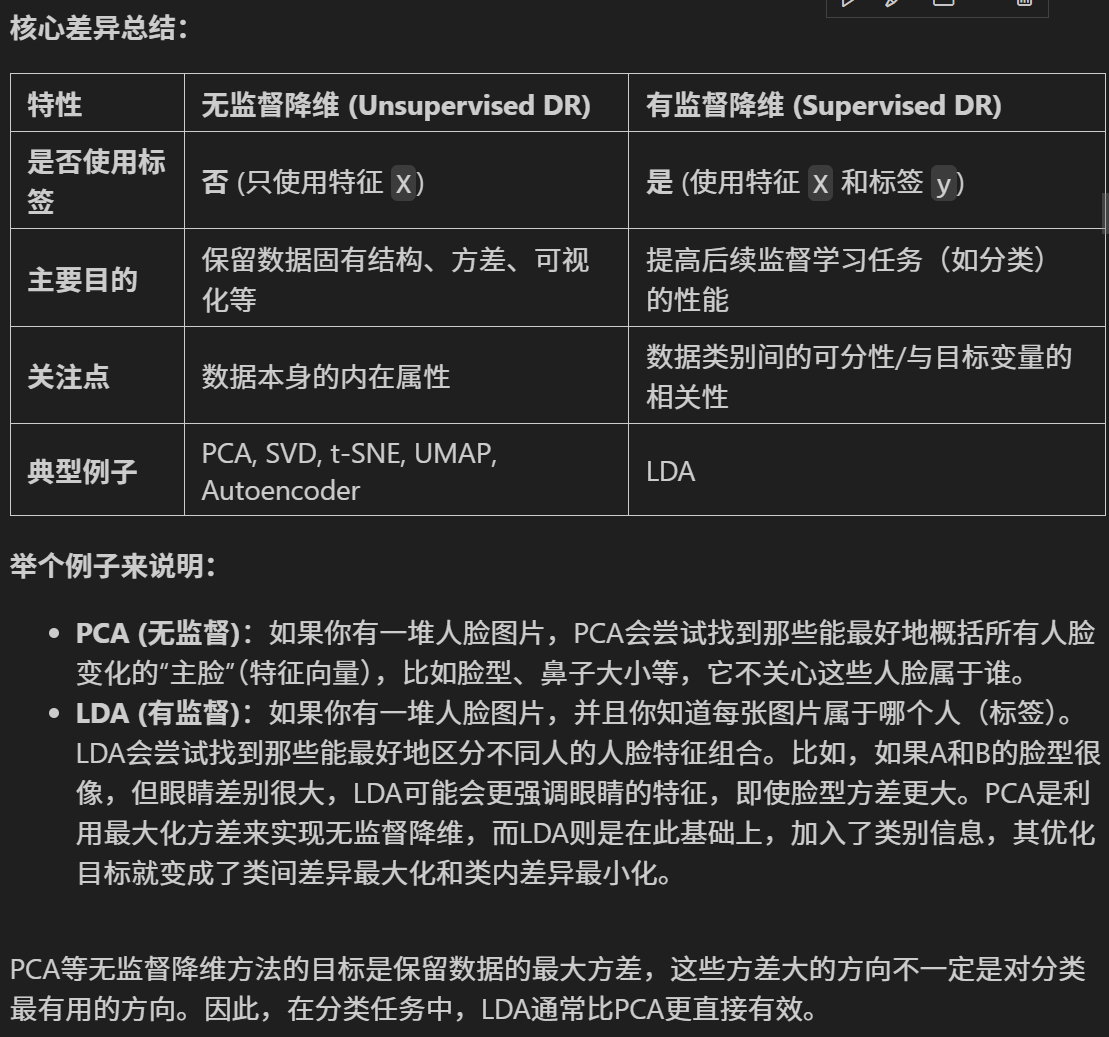
# --- 1. 默认参数的随机森林 ---
# 评估基准模型,这里确实不需要验证集
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
import time # 这里介绍一个新的库,time库,主要用于时间相关的操作,因为调参需要很长时间,记录下会帮助后人知道大概的时长
start_time = time.time() # 记录开始时间
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train) # 在训练集上训练
rf_pred = rf_model.predict(X_test) # 在测试集上预测
end_time = time.time() # 记录结束时间print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))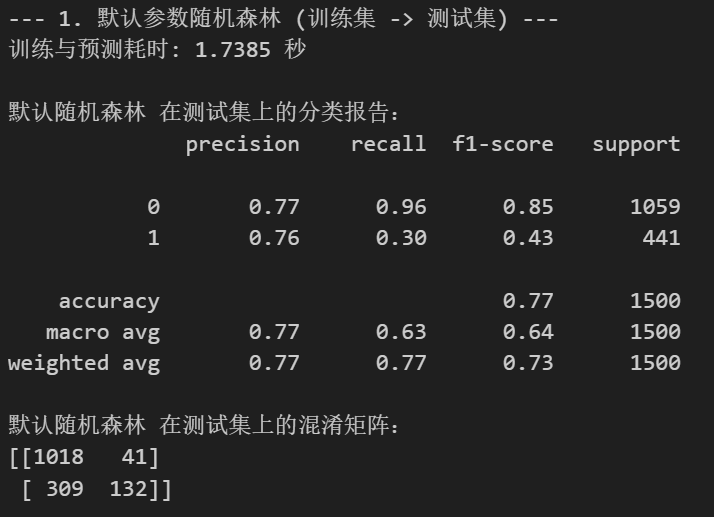
# umap-learn 是一个用于降维和可视化的库,特别适合处理高维数据。它使用了一种基于流形学习的算法,可以有效地将高维数据嵌入到低维空间中,同时保持数据的局部结构。
# !pip install umap-learn -i https://pypi.tuna.tsinghua.edu.cn/simple# 确保这些库已导入,你的原始代码中可能已经包含了部分
import time
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler # 特征缩放
from sklearn.decomposition import PCA # 主成分分析
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA # 线性判别分析
# UMAP 需要单独安装: pip install umap-learn
import umap # 如果安装了 umap-learn,可以这样导入from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix# 你的 X_train, X_test, y_train, y_test 应该已经根据你的代码准备好了
# 我们假设你的随机森林模型参数与基准模型一致,以便比较降维效果
# rf_params = {'random_state': 42} # 如果你的基准模型有其他参数,也在这里定义
# 为了直接比较,我们使用默认的 RandomForestClassifier 参数,除了 random_statePCA主成分分析
可以将PCA视为:
1. 对数据进行均值中心化。
2. 对中心化后的数据进行SVD。
3. 使用SVD得到的右奇异向量 `V` 作为主成分方向。
4. 使用奇异值 `S` 来评估每个主成分的重要性(解释的方差)。
5. 使用 U*S(或 X_centered * V)来获得降维后的数据表示。
PCA主要适用于那些你认为最重要的信息可以通过数据方差来捕获,并且数据结构主要是线性的情况。
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time
import numpy as np # 确保numpy导入# 假设 X_train, X_test, y_train, y_test 已经准备好了print(f"\n--- 2. PCA 降维 + 随机森林 (不使用 Pipeline) ---")# 步骤 1: 特征缩放
scaler_pca = StandardScaler()
X_train_scaled_pca = scaler_pca.fit_transform(X_train)
X_test_scaled_pca = scaler_pca.transform(X_test) # 使用在训练集上fit的scaler# 步骤 2: PCA降维
# 选择降到10维,或者你可以根据解释方差来选择,例如:
pca_expl = PCA(random_state=42)
pca_expl.fit(X_train_scaled_pca)
cumsum_variance = np.cumsum(pca_expl.explained_variance_ratio_)
n_components_to_keep_95_var = np.argmax(cumsum_variance >= 0.95) + 1
print(f"为了保留95%的方差,需要的主成分数量: {n_components_to_keep_95_var}")

# 我们测试下降低到10维的效果
n_components_pca = 10
pca_manual = PCA(n_components=n_components_pca, random_state=42)X_train_pca = pca_manual.fit_transform(X_train_scaled_pca)
X_test_pca = pca_manual.transform(X_test_scaled_pca) # 使用在训练集上fit的pcaprint(f"PCA降维后,训练集形状: {X_train_pca.shape}, 测试集形状: {X_test_pca.shape}")
start_time_pca_manual = time.time()
# 步骤 3: 训练随机森林分类器
rf_model_pca = RandomForestClassifier(random_state=42)
rf_model_pca.fit(X_train_pca, y_train)# 步骤 4: 在测试集上预测
rf_pred_pca_manual = rf_model_pca.predict(X_test_pca)
end_time_pca_manual = time.time()print(f"手动PCA降维后,训练与预测耗时: {end_time_pca_manual - start_time_pca_manual:.4f} 秒")print("\n手动 PCA + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_pca_manual))
print("手动 PCA + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_pca_manual))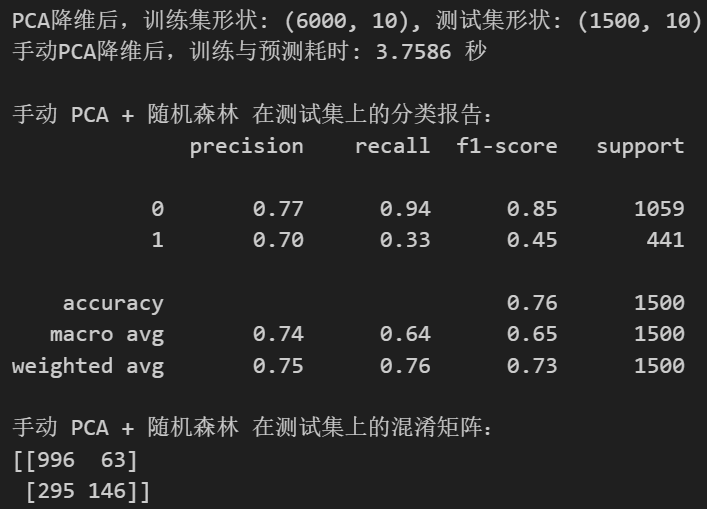
t-sne降维
这是一种与PCA截然不同的降维算法,尤其在理解其核心思想和适用场景上。
t-SNE:保持高维数据的局部邻域结构,用于可视化
PCA 的目标是保留数据的全局方差,而 t-SNE 的核心目标是在高维空间中相似的数据点,在降维后的低维空间中也应该保持相似(即彼此靠近),而不相似的点则应该相距较远。它特别擅长于将高维数据集投影到二维或三维空间进行可视化,从而揭示数据中的簇结构或流形结构。---深度学习可视化中很热门

总结一下:t-SNE是一种强大的非线性降维技术,主用于高维数据的可视化。它通过在低维空间中保持高维空间中数据点之间的局部相似性(邻域关系)来工作。与PCA关注全局方差不同,t-SNE 更关注局部细节。理解它的超参数(尤其是困惑度)和结果的正确解读方式非常重要。
from sklearn.manifold import TSNE
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time
import numpy as np
import matplotlib.pyplot as plt # 用于可选的可视化
import seaborn as sns # 用于可选的可视化# 假设 X_train, X_test, y_train, y_test 已经准备好了
# 并且你的 X_train, X_test 是DataFrame或Numpy Arrayprint(f"\n--- 3. t-SNE 降维 + 随机森林 ---")
print(" 标准 t-SNE 主要用于可视化,直接用于分类器输入可能效果不佳。")# 步骤 1: 特征缩放
scaler_tsne = StandardScaler()
X_train_scaled_tsne = scaler_tsne.fit_transform(X_train)
X_test_scaled_tsne = scaler_tsne.transform(X_test) # 使用在训练集上fit的scaler# 步骤 2: t-SNE 降维
# 我们将降维到与PCA相同的维度(例如10维)或者一个适合分类的较低维度。
# t-SNE通常用于2D/3D可视化,但也可以降到更高维度。
# 然而,降到与PCA一样的维度(比如10维)对于t-SNE来说可能不是其优势所在,
# 并且计算成本会显著增加,因为高维t-SNE的优化更困难。
# 为了与PCA的 n_components=10 对比,我们这里也尝试降到10维。
# 但请注意,这可能非常耗时,且效果不一定好。
# 通常如果用t-SNE做分类的预处理(不常见),可能会选择非常低的维度(如2或3)。# n_components_tsne = 10 # 与PCA的例子保持一致,但计算量会很大
n_components_tsne = 2 # 更典型的t-SNE用于分类的维度,如果想快速看到结果# 如果你想严格对比PCA的10维,可以将这里改为10,但会很慢# 对训练集进行 fit_transform
tsne_model_train = TSNE(n_components=n_components_tsne,perplexity=30, # 常用的困惑度值n_iter=1000, # 足够的迭代次数init='pca', # 使用PCA初始化,通常更稳定learning_rate='auto', # 自动学习率 (sklearn >= 1.2)random_state=42, # 保证结果可复现n_jobs=-1) # 使用所有CPU核心
print("正在对训练集进行 t-SNE fit_transform...")
start_tsne_fit_train = time.time()
X_train_tsne = tsne_model_train.fit_transform(X_train_scaled_tsne)
end_tsne_fit_train = time.time()
print(f"训练集 t-SNE fit_transform 完成,耗时: {end_tsne_fit_train - start_tsne_fit_train:.2f} 秒")# 对测试集进行 fit_transform
# 再次强调:这是独立于训练集的变换
tsne_model_test = TSNE(n_components=n_components_tsne,perplexity=30,n_iter=1000,init='pca',learning_rate='auto',random_state=42, # 保持参数一致,但数据不同,结果也不同n_jobs=-1)
print("正在对测试集进行 t-SNE fit_transform...")
start_tsne_fit_test = time.time()
X_test_tsne = tsne_model_test.fit_transform(X_test_scaled_tsne) # 注意这里是 X_test_scaled_tsne
end_tsne_fit_test = time.time()
print(f"测试集 t-SNE fit_transform 完成,耗时: {end_tsne_fit_test - start_tsne_fit_test:.2f} 秒")print(f"t-SNE降维后,训练集形状: {X_train_tsne.shape}, 测试集形状: {X_test_tsne.shape}")start_time_tsne_rf = time.time()
# 步骤 3: 训练随机森林分类器
rf_model_tsne = RandomForestClassifier(random_state=42)
rf_model_tsne.fit(X_train_tsne, y_train)# 步骤 4: 在测试集上预测
rf_pred_tsne_manual = rf_model_tsne.predict(X_test_tsne)
end_time_tsne_rf = time.time()print(f"t-SNE降维数据上,随机森林训练与预测耗时: {end_time_tsne_rf - start_time_tsne_rf:.4f} 秒")
total_tsne_time = (end_tsne_fit_train - start_tsne_fit_train) + \(end_tsne_fit_test - start_tsne_fit_test) + \(end_time_tsne_rf - start_time_tsne_rf)
print(f"t-SNE 总耗时 (包括两次fit_transform和RF): {total_tsne_time:.2f} 秒")print("\n手动 t-SNE + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_tsne_manual))
print("手动 t-SNE + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_tsne_manual))
线性判别分析 (Linear Discriminant Analysis, LDA)
1. 核心定义与目标:
线性判别分析 (LDA) 是一种经典的有监督降维算法,也常直接用作分类器。作为降维技术时,其核心目标是找到一个低维特征子空间(即原始特征的线性组合),使得在该子空间中,不同类别的数据点尽可能地分开(类间距离最大化),而同一类别的数据点尽可能地聚集(类内方差最小化)。
2. 工作原理简述:
LDA 通过最大化“类间散布矩阵”与“类内散布矩阵”之比的某种度量(例如它们的行列式之比)来实现其降维目标。它寻找能够最好地区分已定义类别的投影方向。
3. 关键特性:
* 有监督性 (Supervised): 这是 LDA 与 PCA 最根本的区别。LDA 在降维过程中必须使用数据的类别标签 (y) 来指导投影方向的选择,目的是优化类别的可分离性。
* 降维目标维度 (Number of Components): LDA 降维后的维度(即生成的判别特征的数量)有一个严格的上限:min(n_features, n_classes - 1)。
* n_features:原始特征的数量。
* n_classes:类别标签 (y) 中不同类别的数量。
* 这意味着,例如,对于一个二分类问题 (n_classes = 2),LDA 最多能将数据降至 1 维。如果有 5 个类别,最多能降至 4 维(前提是原始特征数不少于4)。这个特性直接源于其优化目标。
* 线性变换 (Linear Transformation):与 PCA 类似,LDA 也是一种线性方法。它找到的是原始特征的线性组合来形成新的、具有判别能力的低维特征(称为判别向量或判别成分)。
* 数据假设 (Assumptions):
* 理论上,LDA 假设每个类别的数据服从多元高斯分布。
* 理论上,LDA 假设所有类别具有相同的协方差矩阵。
* 在实践中,即使这些假设不完全满足,LDA 通常也能表现良好,尤其是在类别大致呈椭球状分布且大小相似时。
4. 输入要求:
* 特征 (X):数值型特征。如果存在类别型特征,通常需要先进行预处理(如独热编码)。
* 标签 (y):一维的、代表类别身份的数组或 Series(例如 [0, 1, 0, 2, 1])。LDA 不需要标签进行独热编码。标签的类别数量直接决定了降维的上限。
5. 与特征 (X) 和标签 (y) 的关系:
* LDA 的降维过程和结果直接由标签y中的类别结构驱动。它试图找到最能区分这些由 y 定义的类别的特征组合。
* 原始特征 X 提供了构建这些判别特征的原材料。特征 X 的质量和相关性会影响 LDA 的效果,但降维的“方向盘”是由 y 控制的。
6. 优点:
* 直接优化类别可分性,非常适合作为分类任务的预处理步骤,往往能提升后续分类器的性能。
* 计算相对高效。
* 生成的低维特征具有明确的判别意义。
7. 局限性与注意事项:
* 降维的维度受限于 n_classes - 1,这可能比 PCA 能达到的降维程度低很多,尤其是在类别数较少时。
* 作为线性方法,可能无法捕捉数据中非线性的类别结构。如果类别边界是非线性的,LDA 效果可能不佳。
* 对数据的高斯分布和等协方差假设在理论上是存在的,极端偏离这些假设可能影响性能。
* 如果类别在原始特征空间中本身就高度重叠,LDA 的区分能力也会受限。
8. 适用场景:
* 当目标是提高后续分类模型的性能时,LDA 是一个强有力的降维工具。
* 当类别信息已知且被认为是区分数据的主要因素时。
* 当希望获得具有良好类别区分性的低维表示时,尤其可用于数据可视化(如果能降到2D或3D)。
简而言之,LDA 是一种利用类别标签信息来寻找最佳类别分离投影的降维方法,其降维的潜力直接与类别数量挂钩。
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time
import numpy as np
# 假设你已经导入了 matplotlib 和 seaborn 用于绘图 (如果需要)
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # 如果需要3D绘图
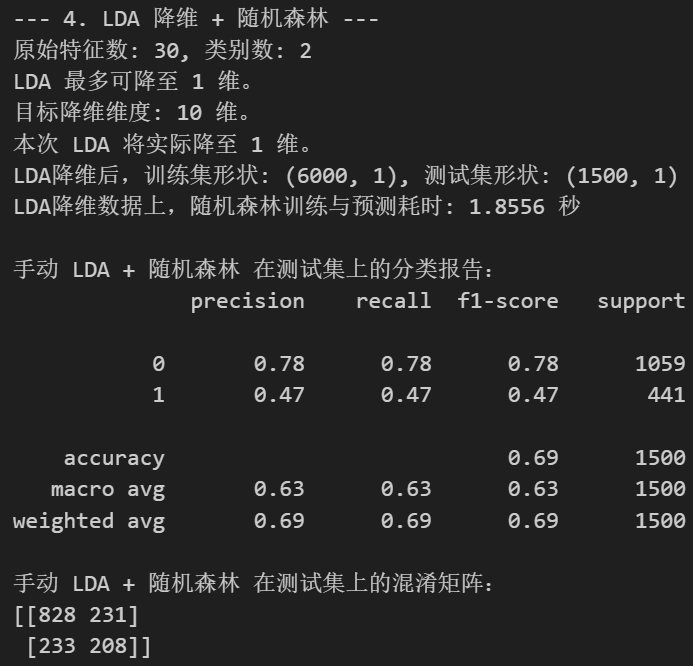
import seaborn as snsprint(f"\n--- 4. LDA 降维 + 随机森林 ---")# 步骤 1: 特征缩放
scaler_lda = StandardScaler()
X_train_scaled_lda = scaler_lda.fit_transform(X_train)
X_test_scaled_lda = scaler_lda.transform(X_test) # 使用在训练集上fit的scaler# 步骤 2: LDA 降维
n_features = X_train_scaled_lda.shape[1]
if hasattr(y_train, 'nunique'):n_classes = y_train.nunique()
elif isinstance(y_train, np.ndarray):n_classes = len(np.unique(y_train))
else:n_classes = len(set(y_train))max_lda_components = min(n_features, n_classes - 1)# 设置目标降维维度
n_components_lda_target = 10if max_lda_components < 1:print(f"LDA 不适用,因为类别数 ({n_classes})太少,无法产生至少1个判别组件。")X_train_lda = X_train_scaled_lda.copy() # 使用缩放后的原始特征X_test_lda = X_test_scaled_lda.copy() # 使用缩放后的原始特征actual_n_components_lda = n_featuresprint("将使用缩放后的原始特征进行后续操作。")
else:# 实际使用的组件数不能超过LDA的上限,也不能超过我们的目标(如果目标更小)actual_n_components_lda = min(n_components_lda_target, max_lda_components)if actual_n_components_lda < 1: # 这种情况理论上不会发生,因为上面已经检查了 max_lda_components < 1print(f"计算得到的实际LDA组件数 ({actual_n_components_lda}) 小于1,LDA不适用。")X_train_lda = X_train_scaled_lda.copy()X_test_lda = X_test_scaled_lda.copy()actual_n_components_lda = n_featuresprint("将使用缩放后的原始特征进行后续操作。")else:print(f"原始特征数: {n_features}, 类别数: {n_classes}")print(f"LDA 最多可降至 {max_lda_components} 维。")print(f"目标降维维度: {n_components_lda_target} 维。")print(f"本次 LDA 将实际降至 {actual_n_components_lda} 维。")lda_manual = LinearDiscriminantAnalysis(n_components=actual_n_components_lda, solver='svd')X_train_lda = lda_manual.fit_transform(X_train_scaled_lda, y_train)X_test_lda = lda_manual.transform(X_test_scaled_lda)print(f"LDA降维后,训练集形状: {X_train_lda.shape}, 测试集形状: {X_test_lda.shape}")start_time_lda_rf = time.time()
# 步骤 3: 训练随机森林分类器
rf_model_lda = RandomForestClassifier(random_state=42)
rf_model_lda.fit(X_train_lda, y_train)# 步骤 4: 在测试集上预测
rf_pred_lda_manual = rf_model_lda.predict(X_test_lda)
end_time_lda_rf = time.time()print(f"LDA降维数据上,随机森林训练与预测耗时: {end_time_lda_rf - start_time_lda_rf:.4f} 秒")print("\n手动 LDA + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_lda_manual))
print("手动 LDA + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_lda_manual))
还有一些其他的降维方式,也就是最重要的词向量的加工,我们未来再说
作业:
自由作业:探索下什么时候用到降维?降维的主要应用?或者让ai给你出题,群里的同学互相学习下。可以考虑对比下在某些特定数据集上t-sne的可视化和pca可视化的区别。
降维(Dimensionality Reduction)是机器学习和数据分析中的关键技术,主要用于解决高维数据带来的计算复杂度、噪声干扰和可视化难题。
什么时候用到降维
-
高维数据导致计算成本高
当特征维度极高(如文本、图像、基因数据)时,模型训练速度显著下降,降维可减少计算资源消耗。 -
缓解维度灾难(Curse of Dimensionality)
高维空间中数据稀疏,模型容易过拟合,降维可提升模型泛化能力。 -
数据可视化需求
将高维数据压缩到2D/3D,便于人类直观理解数据分布(如客户分群、异常检测)。 -
特征相关性高或冗余
当多个特征高度相关(如温度与季节)时,降维可提取核心信息。 -
数据去噪
通过保留主要成分(如PCA),过滤噪声或无关特征。
降维的主要应用场景
1. 数据可视化
目标:将高维数据映射到 2D/3D 空间,直观展示数据分布。
药物场景:
-
使用 t-SNE 或 UMAP 将药物的成分、剂型、强度等特征降维,可视化不同聚类的药物群体。
-
示例:横轴表示主成分 1(如 “抗生素类成分”),纵轴表示主成分 2(如 “口服剂型”),可清晰区分不同类型药物的聚集区域,发现空白领域(如 “注射型抗生素” vs “口服降压药”)。
2. 特征去噪与压缩
目标:去除冗余特征,保留关键信息,提升模型效率。
药物场景:
-
主成分分析(PCA):对文本向量化后的高维特征(如 TF-IDF 矩阵)进行降维,保留前 100 个主成分,减少计算量。
-
应用:
-
加速 K-Means 聚类,避免因高维导致的 “距离失效” 问题。
-
提升随机森林等模型的训练速度,同时避免过拟合。
-
3. 无监督学习前预处理
目标:为聚类、异常检测等无监督任务提供更优质的特征空间。
药物场景:
-
K-Means 聚类前降维:
-
对 “成分 + 剂型 + 强度” 的高维特征降维后,聚类结果更聚焦于核心差异(如 “高剂量注射剂” vs “低剂量片剂”)。
-
-
异常检测:
-
使用 Autoencoder 降维后,在低维空间中更容易识别罕见药物配方(如成分独特的复方制剂)。
-
4. 特征相关性分析
目标:揭示特征间的潜在关联,辅助业务洞察。
药物场景:
-
因子分析(FA):发现隐藏的 “因子”(如 “抗炎因子” 由多个成分共同构成),解释药物分类的本质驱动因素。
-
应用:
-
识别核心成分组合(如 “布洛芬 + 对乙酰氨基酚” 常出现在止痛药中),指导新药配方设计。
-
5. 推荐系统与市场空白挖掘
目标:在低维空间中计算药物 / 制造商的相似性,预测潜在需求。
药物场景:
-
矩阵分解:将 “制造商 - 药物” 高维交互矩阵降维,预测制造商未生产但可能相关的药物类型。
-
示例:某制造商擅长生产 “口服抗生素片剂”,降维后发现其邻近区域存在 “注射型抗生素” 空白,可作为研发方向。





