
摘要
由于提示膨胀和选择复杂性,大型语言模型 (LLM) 难以有效利用越来越多的外部工具,例如模型上下文协议 (MCP)[1]中定义的那些工具。 我们引入了 RAG-MCP,这是一个检索增强生成框架,通过卸载工具发现来克服这一挑战。 RAG-MCP 使用语义检索从外部索引中识别给定查询最相关的 MCP,然后才能使用 LLM。 只有选定的工具描述才会传递给模型,从而大大减少了提示大小并简化了决策过程。 实验(包括 MCP 压力测试)表明,RAG-MCP 显着减少了提示符元(token)(例如,减少了 50% 以上),并且在基准任务上的工具选择准确率提高了三倍多(43.13% 对比基线的 13.62%)。 RAG-MCP 使得 LLM 能够进行可扩展且准确的工具集成。
关键词: 检索增强生成模型上下文协议工具选择
1、引言
1.1、背景和动机
大型语言模型 (LLM) 在自然对话、推理甚至代码生成方面展现出了 remarkable 的能力。 然而,它们仍然受到其参数中编码的知识和推理时可用的固定上下文窗口的根本性限制。 本质上,一个没有外部访问权限的大语言模型 (LLM) 只拥有其训练数据,就像被“困住”了一样,难以轻松更新其知识或执行现实世界中的操作 [12]。 为了解决这一限制,最近的研究工作重点在于用外部工具和函数调用能力增强LLM [3]。 通过定义的函数或 API 调用工具(例如,网络搜索、数据库、计算器),LLM 可以获取最新信息并执行超出其内置功能范围的复杂操作 [12]。 这种范式——通常被称为零样本工具使用或函数调用——允许 AI 助手与最新的数据和服务交互,从而解锁从实时知识查询到金融和旅行规划等专业任务的应用 [3]。 事实上,主要的 AI 提供商已经接受了这一趋势:例如,领先的 LLM 平台现在支持插件 API 和结构化函数调用,以便 GPT-4 或 Claude 等模型可以通过定义良好的接口调用外部服务 [12]。
在研究界,已经提出了各种方法来启用和改进 LLM 工具的使用。 基于提示的策略,例如ReAct,将推理步骤与动作命令混合,允许 LLM 在多轮“思考过程”的上下文中决定何时咨询工具 [15]。 模型中心的方法也出现了:例如,Toolformer 微调 LLM 以自主决定调用哪个 API,何时调用以及如何整合结果,每个工具只需少量演示即可 [13] 。其他研究人员通过将工具使用纳入训练数据和模型调优来改进工具使用。 这包括将函数调用演示混合到指令遵循数据集中,并探索有效地向模型描述可用函数的提示格式 [3]。 这些努力显著提高了零样本工具使用的性能。 例如,在一个包含大量工具使用数据的 API 调用任务上微调模型可以产生令人印象深刻的结果——Gorilla 系统使用相关的 API 文档检索增强了一个基于 7B LLaMA 的模型,使其能够在为各种工具生成正确的 API 调用方面甚至超过 GPT-4 [12]。 这些研究的一个重要见解是,提供及时的相关上下文(无论是通过优化的提示还是检索到的文档)都极大地提高了 LLM 工具选择和使用的准确性,而模型明确决定工具使用的机制(例如,“回答与行动”的特殊决策符元)可以进一步提高可靠性 [3]。
尽管取得了这些进展,但随着向 LLM 提供的工具数量的增加,一个新的挑战出现了。 大多数之前的研究和部署都考虑了一组相对较小的工具或 API,这些工具或 API 通常是手工挑选的,并且模型很容易在提示中处理 [12]。 然而,在实践中,工具生态系统正在迅速发展。 例如,Anthropic 最近推出的模型上下文协议 (MCP)定义了一个连接 AI 系统与外部数据源和服务的通用开放标准。 MCP 能够通过统一协议让单个助手与许多数据存储库和业务工具交互,从而取代了支离破碎的一次性集成。 因此,先进的大语言模型 (LLM) 代理很快就能拥有数十种功能——从 Google Drive 和 Slack 连接器到 GitHub、数据库、地图等等——所有这些都注册为它可以调用的 MCP“工具”[1]。 可用工具的激增带来了巨大的挑战。
提示膨胀 (Prompt Bloat) 是一个关键问题:在模型上下文中提供每个可能工具的定义或使用说明将消耗大量的符元,并可能压垮模型。 人们已经观察到,随着工具数量的增长,在一个提示中描述大量 API 或工具实际上是不可能的,而且许多 API 具有重叠的功能,只有细微的差别。 同时包含太多工具不仅会耗尽上下文长度,还会混淆模型——这些功能可能会开始模糊。 这直接导致了第二个问题:决策开销 (decision overhead)。 借助一长串工具(其中许多工具在范围中相似),该模型在选择是否和哪种工具时会面临更复杂的决定。 选择越多,出错的可能性就越高,例如选择次优工具或误解工具的功能。 事实上,即使是最先进的模型在这种情况下也会失误:例如,在一个有多种 API 选项的场景中,据报道 GPT-4 会幻化出一个实际上不存在的 API,而 Anthropic 的 Claude 为用户的请求选择了错误的库[12]。 这些失败案例强调了简单地扩展工具集会降低 LLM 的性能,这是因为提示的容量压力和模型决策过程中的模糊性。
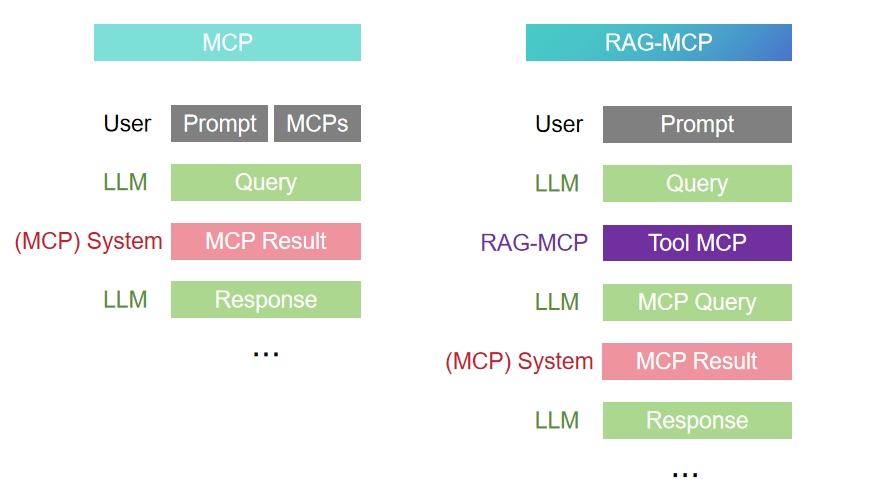
为了应对这些挑战,我们提出了RAG-MCP,这是一种将检索增强生成 (RAG) 与模型上下文协议 (MCP) 框架结合的解决方案。 RAG-MCP 的关键思想是避免一次性地将所有工具呈现给语言模型,而是根据用户的查询动态检索相关的工具子集。 在我们的方法中,大量的可用工具描述(MCP 功能模式、使用示例等)存储在外部内存中,并按其语义进行索引。 当新的查询到达时,一个专用的检索器(例如,向量空间语义搜索)首先选择最有可能对该查询有用的顶级 k 候选工具。 只有这些 k 工具描述随后被注入到LLM的提示中(或通过函数调用API提供),从而大大减少了上下文长度和复杂性。 此检索步骤充当一种聚焦的上下文过滤,它减少了提示膨胀并指导模型的选择。 这种方法类似于检索增强型问答系统的工作方式:与其向模型提供整个维基百科,不如只检索相关的文章[6]。 在这里,我们不是检索静态知识,而是动态检索可操作的工具知识。 额外的好处是可扩展性——因为工具信息存储在外部索引中,所以可以通过更新该索引来合并新的工具或更新的API,而无需重新训练LLM,从而确保系统保持最新[12]。 简而言之,检索有助于控制不断增长的工具集,它能够在正确的时间提供正确的工具,从而减少模型的决策负担。
1.2、贡献
总而言之,本文做出了以下贡献:
- RAG-MCP框架:我们引入了一种新颖的架构,它在MCP设置中将检索机制与LLM函数调用集成在一起。 据我们所知,这是首批能够让LLM通过查询工具库以获取相关选项(而不是简单地使用所有工具进行提示)来处理大量工具的框架之一。 这种设计保留了开放式MCP生态系统的灵活性,同时又施加了结构以保持易处理性。
- 可扩展的工具检索:我们开发了一个语义工具检索模块,该模块在向量空间中表示每个可用工具的描述,并有效地将用户查询与最相关的工具匹配。 这大大减少了提示的大小和复杂性(减轻了提示词膨胀),并通过缩小选择范围来改进决策。 在检索到的上下文指导下,即使工具总数大幅增加,大型语言模型 (LLM) 也可以更准确地选择和使用正确的外部工具。 值得注意的是,我们的方法允许通过索引动态添加新工具,而无需额外微调大型语言模型 (LLM)。
- 改进的工具使用性能:通过全面的实验,我们证明 RAG-MCP 有效地解决了简单地扩展工具集时出现的性能下降问题。 在一套工具增强的自然语言处理 (NLP) 任务中,我们展示了随着可用功能数量的增加,基线大型语言模型 (LLM) 在选择和执行正确工具方面的成功率显著下降(说明了前面提到的挑战)。 然而,在 RAG-MCP 策略下,模型的性能在很大程度上恢复到其原始水平,在某些情况下甚至超过了小型工具集的基线。 特别是,RAG-MCP 在选择合适的工具方面产生了更高的准确性,并减少了诸如幻觉或参数错误的函数调用等错误。 这些结果强调了使用检索来扩展工具使用的有效性:所提出的方法使大型语言模型 (LLM) 即使拥有大量的工具池,也能保持较高的工具选择准确性和可靠性,为更可扩展和功能更强大的工具增强型人工智能系统铺平了道路。
总体而言,我们的工作表明,基于检索的上下文管理的集成是应对大型语言模型 (LLM) 中工具激增挑战的一个有前景的方向。 通过使模型能够学习在众多工具中使用哪个工具,并且只为这些工具提供信息,RAG-MCP 为下一代使用广泛工具包运行的人工智能代理提供了一个切实可行的解决方案。 它结合了检索增强和标准化工具 API 的优势,以确保更多的工具并不意味着更差的性能,而是模型可以准确有效地部署更广泛的技能。
2、相关工作
2.1、大型语言模型 (LLM) 中的工具使用
大型语言模型 (LLM) 已通过外部工具进行增强,以克服其在算术、检索和代码执行方面的局限性。 Toolformer 演示了一种自监督方法,通过该方法,模型可以学习何时以及如何调用计算器或搜索引擎等 API,从而提高跨任务的零样本性能 [13]。 ReAct 将链式思维推理与操作步骤交织在一起,以与外部环境(例如,维基百科 API)进行交互,从而产生更易解释和更准确的多步骤解决方案 [15]。 WebGPT 在模拟的浏览器环境中微-调 GPT-3,训练它导航、搜索和引用长-篇问答的来源,通过基于事实的检索减少幻觉 [9]。 最近,ChatGPT Plugins 引入了一个生产插件生态系统,使 ChatGPT 能够在受控的、以安全为导向的框架中访问最新信息和第三方服务 [11]。
2.2、检索增强生成
检索增强生成 (RAG) 首先在密集向量索引中将参数化 LLM 与非参数化内存相结合,在推理时检索相关段落,以改进知识密集型任务 [6]。后续工作已将RAG扩展到广泛的NLP范式,包括模块化和高级RAG变体,这些变体可以根据每个符元或每个查询动态调整检索[4]。 RAG对内存访问和生成分离启发了我们的MCP-RAG方法,其中MCP 发现被视为检索子问题,与核心文本生成正交。
2.3、模型上下文协议
模型上下文协议通过将资源提示、身份验证和参数模式捆绑到模块化“MCP”服务中,标准化了 LLM 到 API 的交互。MCP充当函数调用扩展,类似于OpenAI函数调用API,但社区可扩展性更大。 MCP存储库的快速增长(截至2025年4月,mcp.so上有4400多个MPC服务[14])凸显了对可扩展的发现和验证机制的需求。
3、方法论
概述。 我们研究了可用 MCP 服务器的数量如何影响 LLM 选择和调用正确工具(“提示膨胀”)的能力,并提出了 MCP-RAG,这是一个检索增强框架,通过动态检索每个查询最相关的 MCP 来缓解这种性能下降。
3.1、提示膨胀和MCP压力测试
现代LLM通常必须在许多可能的外部工具中进行选择,每个工具都由MCP模式描述。 随着MCP数量的增长,在单个提示中包含所有描述会导致提示膨胀:上下文窗口被干扰项,从而降低了模型区分和回忆正确工具的能力。
这种现象与大海捞针(NIAH)测试相似,该测试将随机事实(“针”)嵌入长上下文中(“ haystack”),并测量了LLM的能力,并衡量 LLM 在不同的上下文长度和深度下检索它的能力 [6] [10] 。 在NIAH中,随着大海捞针的增长,性能急剧下降,揭示了上下文检索的局限性。
受 NIAH 的启发,我们在 WebSearch 任务上设计了一个MCP 压力测试:对于每次试验,我们向模型展示 N 个 MCP模式(一个基本事实和 N−1 个干扰项),并要求它选择并调用正确的 WebSearch MCP。 我们改变 N 从 1 到 11100,间隔为 26,测量选择准确性、任务成功率、提示词符元使用情况和延迟。 此设置量化了工具选择能力如何随着 MCP 池大小的增加而下降。
3.2、RAG-MCP 框架
为了克服提示符膨胀问题,RAG-MCP 将检索增强生成 (RAG) 原理应用于工具选择。 我们没有向 LLM 填充所有 MCP 描述,而是维护所有可用 MCP 元数据的外部向量索引。 查询时:
- 检索。 基于轻量级 LLM 的检索器(例如,Qwen)对用户的任务描述进行编码,并在 MCP 索引上执行语义搜索,返回与任务最相似的顶级 k 候选 MCP[6]。
- 验证。 对于每个检索到的 MCP,RAG-MCP 可以生成一个少样本示例查询并测试其响应,以确保基本兼容性,在调用之前充当“健全性检查”。
- 调用。 仅将最佳的 MCP 描述(包括其工具使用参数)注入到 LLM 提示或函数调用 API 中,然后执行规划和执行,无需考虑工具发现[2]。
此设计产生以下几个优点:
- 减少提示大小。 通过仅提供相关的 MCP 元数据,RAG-MCP 避免了即使在完整工具注册表很大的情况下上下文窗口过载。
- 降低认知负荷。 LLM 不再需要筛选数百个干扰项,从而提高选择准确性并减少幻觉[2]。
- 资源效率。 与必须在交互之前实例化所有已注册 MCP 服务器的传统 MCP 客户端(例如,Claude 或早期的 GPT-4 集成)不同,MCP-RAG 只激活选定的 MCP,降低了启动成本,并能够支持任意大的工具集,而不会出现基础设施瓶颈[10]。
- 多轮鲁棒性。 在跨越多个轮次的对话中,LLM 不需要重新包含所有 MCP 提示;RAG-MCP 的检索器动态处理工具的调用,为特定任务的推理释放上下文空间。
3.3、三步流水线图
我们将 RAG-MCP 的操作总结为三个核心步骤。 流程图如图3所示:
- 任务输入 → 检索器:用户的自然语言任务被编码并提交给检索器。
- 检索器 → MCP选择 & 验证:检索器搜索 MCP 模式向量索引,根据语义相似度对候选者进行排名,并可以选择通过合成示例测试每个候选者。
- 使用选定MCP的大语言模型执行:大语言模型仅接收选定MCP的模式和参数,并通过函数调用接口执行任务。
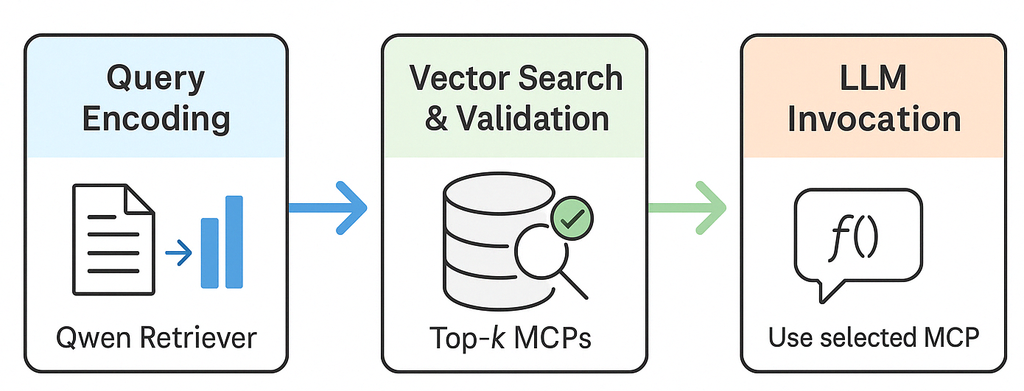
通过将工具发现与生成解耦,RAG-MCP确保大语言模型可以扩展到数百或数千个MCP,而不会出现提示膨胀或决策疲劳,这与RAG系统通过仅检索相关段落来避免用整个语料库压垮大语言模型的方式类似。
3.4、讨论
我们的方法将压力测试(通过MCP压力测试)的严谨性与检索增强型工具使用的有效性相结合。 压力测试量化了当干扰MCP使提示膨胀时发生的性能急剧下降,这反映了NIAH评估[5]中长上下文回忆失败的情况。 然后,RAG-MCP通过动态缩小工具集来抵消这种情况,从而减少提示词符元和决策复杂性,从而恢复(并且通常会提高)任务成功率。
此外,通过使用外部索引,RAG-MCP保持可扩展性:可以通过索引其元数据来添加新的MCP,而无需重新训练大语言模型。 并且通过按需选择性地激活服务器,它规避了先前工具增强型大语言模型部署面临的MCP同时实例化的实际限制。
4、实验
4.1、压力测试
4.1.1、设置
为了量化大语言模型的工具选择能力如何随着MCP池大小而变化,我们进行了一项压力测试,其中候选MCP服务的数量N,以一定间隔从1变化到11100,而关键MCP服务则从上到下定位。 对于每个值 N ,其中我们随机选择一个“真实值”MCP(即唯一能够满足任务要求的服务器),并 N−1 从我们超过4400个公开列出的服务的完整注册表中抽取干扰项MCP [14]。 此设计确保每个 N 候选者中只有一个是相关的。 然后,我们将每个 20 网络搜索任务呈现给模型,要求它 (a) 选择正确的MCP,(b) 发出有效的查询或答案,以及 (c) 返回最终结果。
4.1.2、结果
图3绘制了选择准确性和任务成功率随着 N 的增加而变化的情况。 我们观察到一个明显的非单调趋势:这些结果定量地证实,虽然MCP-RAG极大地减轻了提示膨胀的影响,并在小型到中型池中保持高性能,但随着工具注册表扩展到数千个MCP,其检索精度和整体吞吐量会下降。“‘
4.2、RAG-MCP
4.2.1、设置
我们在MCPBench [8]的网络搜索子集中评估了所有方法,我们将其用作我们的保留测试平台。 对于每个基线,我们执行20次独立试验,如果某个基线产生超过10个正确的答案,我们就认为该基线成功。 在每次试验中,模型最多可以与MCP服务器进行10轮交互以得出最终响应。
为了以自动化和可重复的方式评估答案的正确性,我们采用Deepseek-v3 [7]作为我们的评估器。 由于MCP服务器需要外部网络访问——因此可能对延迟或瞬态故障敏感——我们在所有实验中都强制执行受控网络环境,确保没有请求因连接问题而失败。 最后,所有试验都由qwen-max-0125作为我们底层的大语言模型(LLM)。
4.2.2、基线
我们在实验中评估了三种选择策略:
- 空白条件:同时向LLM提供所有 N MCP描述,并要求它选择正确的描述。
- 实际匹配:使用任务描述和MCP元数据上的简单关键词匹配预先过滤候选池,然后在此缩减后的集合上提示模型。
- RAG-MCP:使用我们的向量索引检索器对所有 N MCP进行语义排序,并仅将排名最高的候选者的模式注入LLM提示中以进行执行。
4.2.3、指标
我们使用三个关键指标来评估每种基线方法的性能:
- 准确性(%):模型选择真实 MCP 的试验百分比。
- 平均提示符元数量:提示消耗的符元平均数量,包括注入的MCP元数据。
- 平均完成符元数量:模型作为最终输出生成的符元平均数量。
使用基于Llama的验证器(“Llama作为裁判”)将模型输出与真实结果进行比较,从而自动判断最终答案。
4.2.4、结果
表格1总结了评估的基线方法的性能,清楚地证明了MCP-RAG的有效性:
| Baseline | Accuracy (%) | Avg Prompt Tokens | Avg Completion Tokens |
|---|---|---|---|
| RAG-MCP | 43.13 | 1084.00 | 78.14 |
| Actual Match | 18.20 | 1646.00 | 23.60 |
| Blank | 13.62 | 2133.84 | 162.25 |
表格 1: 基线性能在准确性和符元使用方面的比较
如表所示,RAG-MCP 达到了43.13% 的最高准确率,显著优于实际匹配和空白条件方法,它们的得分分别为18.20% 和13.62%。 此外,MCP-RAG显着地将平均提示符元数量减少到1084,这与其他基线相比,特别是需要2133.84个符元的空白条件方法相比,是一个实质性的减少。 虽然与实际匹配(23.60)相比,MCP-RAG的完成符元数量有所增加(78.14),但这是一种有利的权衡,因为它与更高的准确性和整体任务成功率相关。
5、分析
5.1、压力测试分析
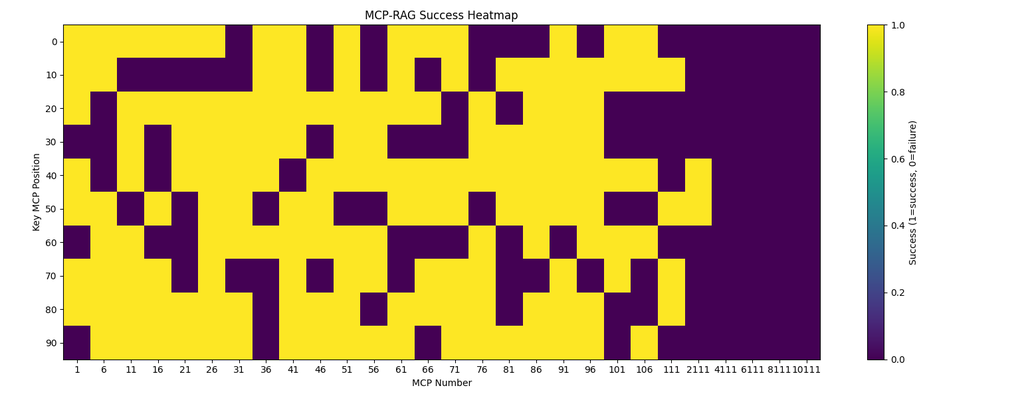
图3显示了MCP位置从1到11100的每次试验成功率,其中黄色表示选择成功,紫色表示失败。 我们观察到:
- 早期阶段高成功率:低于30的MCP位置主要显示黄色区域,表明当候选池最小时,成功率超过90%。
- 中等范围的可变性:在31-70的位置范围内,紫色集群间歇性出现,反映出随着MCP描述之间语义重叠的增加,准确率降低。
- 大规模性能下降:超过约100的位置,紫色占主导地位,这表明在处理非常大的工具注册表时,检索精度会降低。
- 剩余成功区域:在较高位置偶尔出现的黄色斑块表明,某些MCP仍然与特定查询很好地对齐,即使在大型池中也能提供鲁棒性。
这些模式证实,虽然MCP-RAG有效地抑制了提示膨胀并在小型到中型MCP池中保持较高的准确性,但随着MCP总数的增加,检索精度面临挑战,这促使我们未来研究分层或自适应检索机制。
5.2、RAG-MCP结果分析
RAG-MCP的优越性能可归因于以下几个因素:
- 聚焦上下文过滤:通过仅注入单个最相关的MCP模式,模型避免了无关工具描述造成的干扰,从而产生了更清晰的决策边界。
- 提示效率:提示符元的大幅减少使模型能够将其更多上下文窗口分配给任务本身的推理,而不是解析无关的元数据。
- 平衡生成:尽管与实际匹配相比,RAG-MCP略微增加了完成符元的用量,但这部分开销反映了更彻底的推理和验证步骤,这与更高的准确性相关。
总体而言,这些发现证实,检索增强的MCP选择有效地抑制了提示膨胀,并增强了LLM的工具选择可靠性,使RAG-MCP成为可扩展外部工具集成的引人注目的解决方案。
6、结论
我们提出了RAG-MCP,这是一个简单而强大的框架,它通过仅检索每个查询最相关的模式来控制大型MCP工具集。 通过聚焦检索,RAG-MCP:
- 大幅减少提示大小,与一次性提供所有工具相比,符元使用量减少了一半以上。
- 提高选择准确性,在高负荷情况下,成功率是基于朴素方法和关键词-方法的三倍多。
- 保持可扩展性,因为可以在无需重新训练模型的情况下动态索引新的MCP。
本质上,RAG-MCP 将数百或数千个工具的庞大库转变为精简的按需工具包。未来的工作将通过分层索引或自适应策略改进极端规模的检索,并探索多工具工作流程和真实世界的代理部署。RAG-MCP 为可扩展、可靠的 LLM 代理奠定了“黄金核心”,这些代理可以精确、高效地运用大量外部服务。
7、参考文献
- [1]Anthropic: Introducing the model context protocol (2024), Introducing the Model Context Protocol \ Anthropic
- [2]Blog, N.: What is retrieval-augmented generation aka rag (2025), What Is Retrieval-Augmented Generation aka RAG | NVIDIA Blogs
- [3]Chen, Y.C., Hsu, P.C., Hsu, C.J., Shiu, D.s.: Enhancing function-calling capabilities in llms: Strategies for prompt formats, data integration, and multilingual translation. arXiv preprint arXiv:2412.01130 (2024)
- [4]Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Wang, H., Wang, H.: Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997 2 (2023)
- [5]gkamradt: The needle in a haystack test (2024), https://github.com/gkamradt/LLMTest_NeedleInAHaystack
- [6]Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., Riedel, S., Kiela, D.: Retrieval-augmented generation for knowledge-intensive nlp tasks. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H. (eds.) Advances in Neural Information Processing Systems. vol. 33, pp. 9459–9474. Curran Associates, Inc. (2020), https://proceedings.neurips.cc/paper_files/paper/2020/file/6b493230205f780e1bc26945df7481e5-Paper.pdf
- [7]Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al.: Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437 (2024)
- [8]Luo, Z., Shi, X., Lin, X., Gao, J.: Evaluation report on mcp servers (2025), https://arxiv.org/abs/2504.11094
- [9]Nakano, R., Hilton, J., Balaji, S., Wu, J., Ouyang, L., Kim, C., Hesse, C., Jain, S., Kosaraju, V., Saunders, W., Jiang, X., Cobbe, K., Eloundou, T., Krueger, G., Button, K., Knight, M., Chess, B., Schulman, J.: Webgpt: Browser-assisted question-answering with human feedback (2022), https://arxiv.org/abs/2112.09332
- [10]OpenAI: Openai function calling, https://platform.openai.com/docs/guides/function-calling
- [11]OpenAI: Chatgpt plugins (2023), https://openai.com/index/chatgpt-plugins
- [12]Patil, S.G., Zhang, T., Wang, X., Gonzalez, J.E.: Gorilla: Large language model connected with massive apis. Advances in Neural Information Processing Systems 37, 126544–126565 (2024)
- [13]Schick, T., Dwivedi-Yu, J., Dessi, R., Raileanu, R., Lomeli, M., Hambro, E., Zettlemoyer, L., Cancedda, N., Scialom, T.: Toolformer: Language models can teach themselves to use tools. In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S. (eds.) Advances in Neural Information Processing Systems. vol. 36, pp. 68539–68551. Curran Associates, Inc. (2023), https://proceedings.neurips.cc/paper_files/paper/2023/file/d842425e4bf79ba039352da0f658a906-Paper-Conference.pdf
- [14]ShipAny: Mcp servers (2025), MCP Servers
- [15]Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., Cao, Y.: React: Synergizing reasoning and acting in language models. International Conference on Learning Representations (ICLR) (2023), https://par.nsf.gov/biblio/10451467
8、致谢
我们衷心感谢罗志玲、石小荣、林宣睿和高金阳撰写的开创性报告“MCP服务评估报告”。他们公开发布的代码框架和配套的WebSearch数据集构成了我们工作的基础。
)

)



