👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- PostgreSQL数据分析实战:数据清洗之日期时间标准化(时区转换/格式统一)
- 4.1 日期时间标准化:从混乱到有序
- 4.1.1 数据乱象:非标准化日期时间的典型问题
- 4.1.2 时区转换:让时间在统一坐标系下对话
- 1. 存储时区感知型时间
- 2. 固定时区转换(如统一为UTC或北京时间)
- 3. 处理非时区感知型时间(TIMESTAMP WITHOUT TIME ZONE)
- 4.1.3 格式统一:消除字符表示差异
- 1. 解析不同格式的时间字符串
- 2. 统一输出格式
- 3. 处理特殊格式(如时间戳)
- 4.1.4 实战案例:电商订单时间清洗全流程
- 4.1.5 最佳实践与注意事项
- 总结
PostgreSQL数据分析实战:数据清洗之日期时间标准化(时区转换/格式统一)
在数据清洗与预处理环节,日期时间数据的标准化是至关重要的一步。
- 不规范的日期时间格式(如
2024/01/01 15:30与2024-01-01 3:30PM并存)和跨时区数据(如纽约时区与东京时区混合)会导致数据分析结果出现偏差,甚至引发业务逻辑错误。 - 本文将结合具体案例,深入解析PostgreSQL中日期时间标准化的核心技术——时区转换与格式统一,帮助读者掌握高效处理时间数据的实战技巧。
4.1 日期时间标准化:从混乱到有序
4.1.1 数据乱象:非标准化日期时间的典型问题
在实际业务场景中,日期时间数据常因以下原因出现混乱:
-
- 多系统对接:前端采集的时间可能带有时区(如
2024-05-01 09:30:00+08),而数据库存储为本地时间(2024-05-01 09:30:00)
- 多系统对接:前端采集的时间可能带有时区(如
-
- 历史数据遗留:旧系统导出的时间格式为
DD/MM/YYYY HH24:MI(如01/05/2024 09:30),新系统采用YYYY-MM-DD HH:MI:SS
- 历史数据遗留:旧系统导出的时间格式为
-
- 跨区域业务:用户行为日志中包含不同时区的时间戳(如纽约时区
2024-05-01 00:00:00-04与东京时区2024-05-01 12:00:00+09)
- 跨区域业务:用户行为日志中包含不同时区的时间戳(如纽约时区
以电商订单表orders为例,原始数据存在以下问题:
| order_id | create_time(原始) | timezone |
|---|---|---|
| 1001 | 2024-03-15 14:45:23 | UTC+8 |
| 1002 | 2024/03/15 06:45:23 AM | America/New_York |
| 1003 | 15/03/2024 14:45 | UTC |
这种混乱的数据状态会导致时间序列分析(如按小时统计订单量)、时间窗口计算(如7天复购率)等操作无法正确执行。
4.1.2 时区转换:让时间在统一坐标系下对话
PostgreSQL通过TIMESTAMP WITH TIME ZONE(简称TIMESTAMPTZ)数据类型和AT TIME ZONE函数,实现跨时区数据的标准化转换。
1. 存储时区感知型时间
创建带时区的时间字段:
CREATE TABLE orders (order_id INT PRIMARY KEY,create_time TIMESTAMPTZ -- 自动存储为UTC,并记录原始时区偏移
);
插入带时区的时间:
INSERT INTO orders (order_id, create_time)
VALUES
(1001, '2024-03-15 14:45:23+08'), -- 北京时间(1002, '2024-03-15 06:45:23-04'); -- 纽约时间(夏令时)
PostgreSQL会将所有TIMESTAMPTZ数据转换为UTC存储,查询时根据会话时区自动转换为本地时间(默认使用服务器时区)。
2. 固定时区转换(如统一为UTC或北京时间)
使用AT TIME ZONE函数进行时区转换:
-- 将TIMESTAMPTZ转换为北京时间(UTC+8)
SELECT order_id,create_time AS original_time,create_time AT TIME ZONE 'UTC' AS utc_time, -- 转换为UTCcreate_time AT TIME ZONE 'Asia/Shanghai' AS bjt_time -- 转换为北京时间
FROM orders;
转换结果如下表:
| order_id | original_time | utc_time | bjt_time |
|---|---|---|---|
| 1001 | 2024-03-15 14:45:23+08 | 2024-03-15 06:45:23 | 2024-03-15 14:45:23 |
| 1002 | 2024-03-15 06:45:23-04 | 2024-03-15 10:45:23 | 2024-03-15 18:45:23 |
3. 处理非时区感知型时间(TIMESTAMP WITHOUT TIME ZONE)
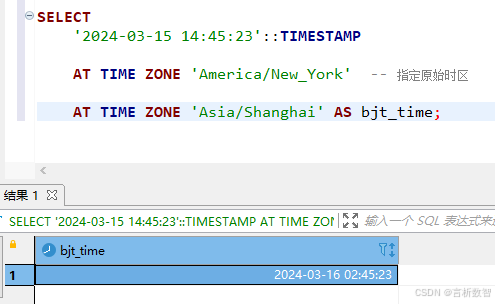
若原始数据为不带时区的TIMESTAMP,需显式指定其所属时区后再转换:
-- 假设'2024-03-15 14:45:23'是纽约时间(UTC-4),转换为北京时间
SELECT '2024-03-15 14:45:23'::TIMESTAMP AT TIME ZONE 'America/New_York' -- 指定原始时区AT TIME ZONE 'Asia/Shanghai' AS bjt_time;
4.1.3 格式统一:消除字符表示差异
PostgreSQL提供TO_CHAR(格式化输出)和TO_TIMESTAMP(解析字符串为时间)函数,解决日期时间格式不统一问题。
1. 解析不同格式的时间字符串
使用TO_TIMESTAMP配合格式掩码解析数据:
CREATE TABLE raw_logs (log_time TEXT -- 包含多种格式的时间字符串
);INSERT INTO raw_logs (log_time) VALUES
('2024-05-01 15:30:00'), -- 格式1:YYYY-MM-DD HH24:MI:SS('05/01/2024 03:30:00 PM'), -- 格式2:MM/DD/YYYY HH:MI:SS AM('20240501153000'); -- 格式3:YYYYMMDDHH24MISS-- 统一解析为TIMESTAMP类型
SELECT log_time,TO_TIMESTAMP(log_time, 'YYYY-MM-DD HH24:MI:SS') AS fmt1,TO_TIMESTAMP(log_time, 'MM/DD/YYYY HH12:MI:SS AM') AS fmt2,TO_TIMESTAMP(log_time, 'YYYYMMDDHH24MISS') AS fmt3
FROM raw_logs;
| log_time | fmt1 | fmt2 | fmt3 |
|---|---|---|---|
| 2024-05-01 15:30:00 | 2024-05-01 15:30:00 | null | 2024-05-01 15:30:00 |
| 05/01/2024 03:30:00 PM | null | 2024-05-01 15:30:00 | null |
| 20240501153000 | null | null | 2024-05-01 15:30:00 |
注意:解析失败会返回NULL,需通过CASE WHEN或TRY_CAST函数处理异常数据。
2. 统一输出格式
使用TO_CHAR将时间转换为指定格式的字符串:
-- 将时间统一为'YYYY-MM-DD HH24:MI'格式
SELECT create_time,TO_CHAR(create_time, 'YYYY-MM-DD HH24:MI') AS standardized_time
FROM orders;
| create_time | standardized_time |
|---|---|
| 2024-03-15 14:45:23+08 | 2024-03-15 14:45 |
| 2024-03-15 06:45:23-04 | 2024-03-15 10:45 |
3. 处理特殊格式(如时间戳)
将Unix时间戳(秒级/毫秒级)转换为可读时间:
SELECT epoch_time,TO_TIMESTAMP(epoch_time) AS sec_level, -- 秒级时间戳TO_TIMESTAMP(epoch_time/1000) AS ms_level -- 毫秒级时间戳FROM unix_timestamps;
4.1.4 实战案例:电商订单时间清洗全流程
假设我们需要将orders表的create_time字段标准化为:
-
时区:统一为北京时间(UTC+8)
-
格式:
YYYY-MM-DD HH24:MI:SS -
步骤1:检测数据类型与格式
-- 查看时间字段的数据类型分布
SELECT CASE WHEN create_time ~ '\+\d+' THEN '带时区TIMESTAMP'WHEN create_time ~ '\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}' THEN '标准TIMESTAMP'ELSE '其他格式'END AS time_type,COUNT(*) AS record_count
FROM raw_orders;
-
步骤2:分阶段清洗
-
- 转换时区:将带时区的时间转为北京时间,非时区时间假设为本地时间(需业务确认)
UPDATE orders SET create_time = CASE WHEN create_time::TEXT LIKE '%+%' OR create_time::TEXT LIKE '%-%%' -- 带时区标识THEN create_time AT TIME ZONE 'Asia/Shanghai'ELSE create_time::TIMESTAMP WITHOUT TIME ZONE -- 假设为本地时间,直接转换END;-
- 统一格式:将清洗后的时间转换为指定字符串格式
ALTER TABLE orders ADD COLUMN standardized_time TEXT;UPDATE orders SET standardized_time = TO_CHAR(create_time, 'YYYY-MM-DD HH24:MI:SS');- 步骤3:验证清洗结果
SELECT DISTINCT standardized_time FROM orders;输出结果应全部符合
YYYY-MM-DD HH24:MI:SS格式,且时区统一为北京时间。 -
4.1.5 最佳实践与注意事项
-
- 时区选择原则:
- 业务分析若涉及
全球数据,建议统一存储为UTC,查询时按需转换 本地化业务(如中国地区)可直接使用本地时区(如Asia/Shanghai)
-
- 格式掩码参考:
格式代码 说明 示例(2024-05-01 15:30:00) YYYY 四位年份 2024 MM 两位月份(01-12) 05 DD 两位日期(01-31) 01 HH24 24小时制(00-23) 15 MI 分钟(00-59) 30
- 格式掩码参考:
-
- 性能优化:
- 对时间字段建立索引(
CREATE INDEX idx_orders_time ON orders(create_time);) - 避免在
WHERE条件中对时间字段使用函数转换,改用::TIMESTAMP强制类型转换
总结
日期时间标准化是数据清洗中技术性与业务性结合的关键环节:
- 时区转换解决了时间的空间一致性问题,确保不同地区的时间在同一坐标系下比较
- 格式统一消除了字符表示的差异,为后续时间序列分析、时间窗口计算奠定基础
通过PostgreSQL的TIMESTAMPTZ、AT TIME ZONE、TO_CHAR、TO_TIMESTAMP等工具,我们能够高效处理复杂的日期时间数据。
-
在实际操作中,需紧密结合业务需求(如时区选择、格式定义),并通过数据验证(如唯一性检查、格式正则匹配)确保清洗结果的准确性。
-
标准化后的日期时间数据将为后续的数据分析(如用户行为时序分析)、可视化(如按小时流量图)提供可靠的基础,
真正实现"垃圾进,精品出"的数据清洗目标。 -
如果你在处理日期时间数据时遇到特殊场景(如跨夏令时转换、历史数据时区修正),欢迎分享具体问题,我们可以共同探讨解决方案。
- 以上内容系统梳理了PostgreSQL日期时间标准化的核心方法。
- 在实际项目中是否遇到过复杂的时间数据清洗问题?比如跨夏令时转换或多格式混合场景,欢迎提出具体案例进一步探讨。





