1.Pytorch – 加载数据初识
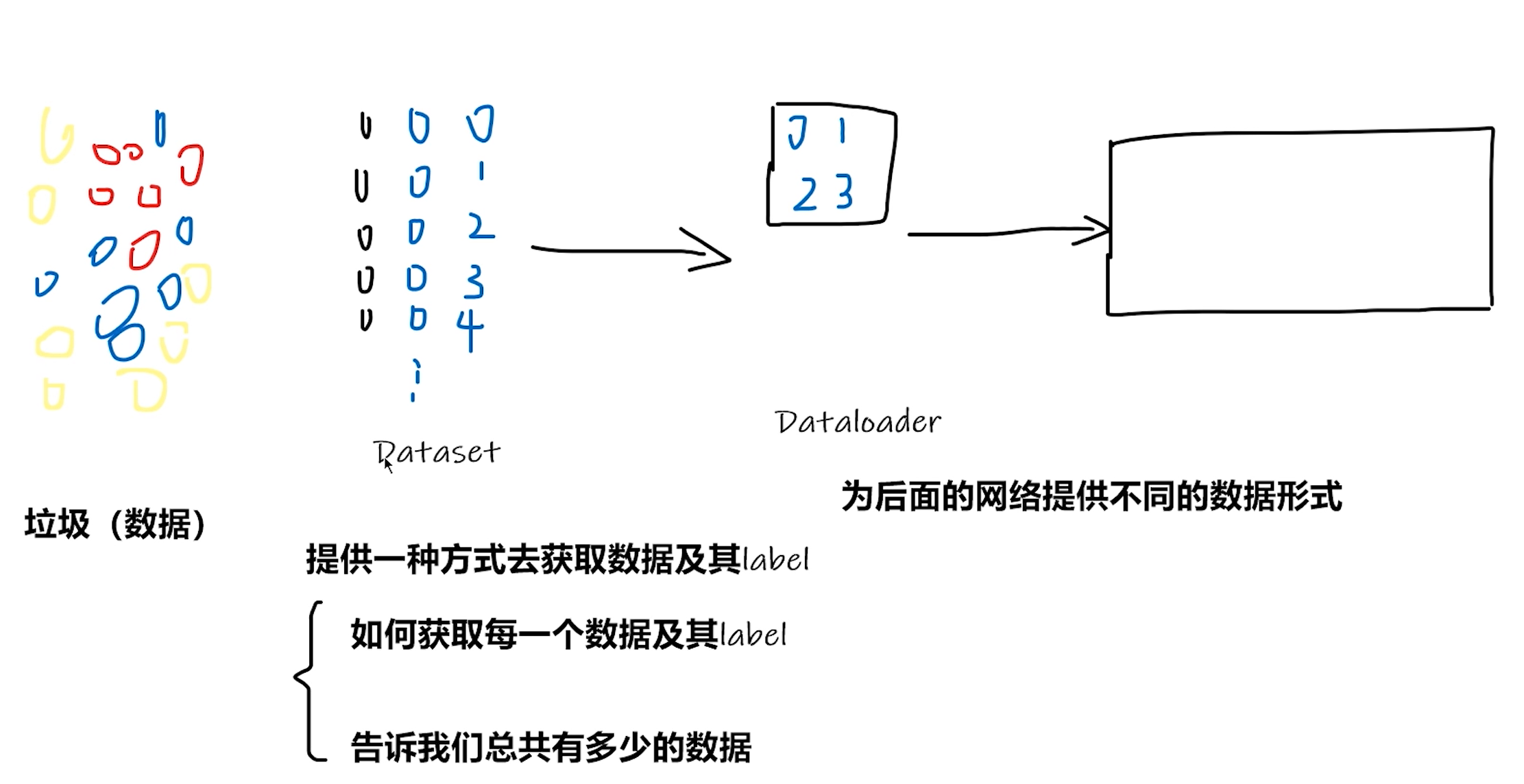
Dataset 和 DataLoader 在深度学习数据处理流程中的作用:
- “垃圾(数据)”:代表原始的、未经处理的数据,就像一堆待整理的“垃圾”,杂乱无章 ,是数据处理的起始点。
- “Dataset”
- 功能阐述:“提供一种方式去获取数据及其label”,进一步细化为“如何获取每一个数据及其label”以及“告诉我们总共有多少的数据” 。在代码实现上,通过继承
torch.utils.data.Dataset类并实现__getitem__方法来定义怎样获取单个数据及其标签 ,实现__len__方法来告知数据集的样本总数。图中用类似表格的形式(虽然较简略)示意数据和标签的组织方式。 - 角色定位:它是对原始数据的初步整理和规范,使得数据具备了可被后续处理的形式,即能按索引获取单个数据样本及其对应标签。
- 功能阐述:“提供一种方式去获取数据及其label”,进一步细化为“如何获取每一个数据及其label”以及“告诉我们总共有多少的数据” 。在代码实现上,通过继承
- 右侧“Dataloader”
- 功能阐述:“为后面的网络提供不同的数据形式” 。在深度学习训练过程中,模型并非一次处理一个数据,而是处理一批数据。
DataLoader从Dataset中按设定规则(如指定的批量大小、是否打乱顺序等)取出数据,将其整理成适合输入到神经网络中的批量数据形式,例如将多个样本及其标签组合成张量形式的批次。图中用箭头表示数据从Dataset流向DataLoader,以及最终要流向神经网络(右侧空白矩形框可理解为代表神经网络) 。 - 角色定位:
DataLoader是数据从Dataset到神经网络之间的“搬运工”和“组织者” ,它通过高效的批量处理和加载机制,让数据以合适的形式及时供应给模型进行训练或推理。
- 功能阐述:“为后面的网络提供不同的数据形式” 。在深度学习训练过程中,模型并非一次处理一个数据,而是处理一批数据。
2.Dataset类代码实战
2.1 代码
from torch.utils.data import Dataset
from PIL import Image
import osclass MyData(Dataset):def __init__(self, root_dir, label_dir):self.root_dir = root_dirself.label_dir = label_dirself.path = os.path.join(self.root_dir,self.label_dir)self.img_path = os.listdir(self.path) #获得图片地址的列表def __getitem__(self, idx):img_name = self.img_path[idx]img_item_path = os.path.join(self.root_dir, self.label_dir, img_name) #图片在文件中的相对路径img = Image.open(img_item_path)label = self.label_dirreturn img, labeldef __len__(self):return len(self.img_path)root_dir = "dataset/train"
ants_label_dir = "ants"
bees_label_dir = "bees"ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)train_dataset = ants_dataset + bees_datasetimg, label = train_dataset[125]
img.show()
运行结果:跳出一张这样的图片

2.2 对上述代码的解释
-
导入必要的库
torch.utils.data.Dataset:这是 PyTorch 中用于自定义数据集的基类,我们需要继承这个类来创建自己的数据集。
PIL.Image:Python Imaging Library(Pillow)中的图像操作模块,用于打开和处理图像文件。
os:Python 的标准库,用于处理文件和目录路径。 -
定义自定义数据集类 MyData(self 相当于全局变量,能被整个类使用)
init 方法:
root_dir:数据集的根目录,例如包含所有训练数据的文件夹。
label_dir:特定类别的子目录,例如 “ants” 或 “bees”。
self.path:通过 os.path.join 方法将根目录和类别子目录拼接成完整的路径。
self.img_path:使用 os.listdir 函数获取该类别子目录下所有图像文件的名称列表。getitem 方法:
idx:表示要获取的样本的索引。
img_name:根据索引从 self.img_path 中获取对应的图像文件名。
img_item_path:将根目录、类别子目录和图像文件名拼接成完整的图像文件路径。
img:使用 Image.open 函数打开图像文件。
label:将类别子目录名作为该图像的标签。
最后返回图像和对应的标签。len 方法:
返回该类别数据集中图像的数量,即 self.img_path 列表的长度。 -
实例化数据集对象
root_dir:指定数据集的根目录。
ants_label_dir 和 bees_label_dir:分别指定蚂蚁和蜜蜂图像的子目录。
ants_dataset 和 bees_dataset:分别创建蚂蚁和蜜蜂图像的数据集对象。 -
获取并展示图像
train_dataset[125]:通过索引访问合并数据集中的第 125 个样本,返回图像和对应的标签。
img.show():使用 PIL.Image 的 show 方法展示图像。
综上所述,这段代码的主要目的是创建一个自定义的图像数据集,并将不同类别的数据集合并成一个训练数据集,最后展示合并数据集中的一张图像。
注意:
-
当你运行 ants_dataset = MyData(root_dir, ants_label_dir) 时,Python 会执行 MyData 类的 init 方法,对实例进行初始化操作,将传入的 root_dir 和 ants_label_dir 赋值给实例的属性,最终得到一个代表蚂蚁图像数据集的对象 ants_dataset。同理,bees_dataset 是代表蜜蜂图像数据集的对象
-
getitem 方法允许你通过索引来获取数据集中的特定样本及其标签。例如,要获取 ants_dataset 中索引为 10 的样本,可以这样做:
img, label = ants_dataset[10]这里,Python 会自动调用 ants_dataset 对象的 getitem 方法,并将索引 10 作为参数传入。方法执行后,会返回对应的图像和标签,分别赋值给 img 和 label 变量
-
len 方法用于返回数据集的样本数量。你可以使用内置的 len() 函数来调用该方法,例如:
ants_count = len(ants_dataset) bees_count = len(bees_dataset) print(f"蚂蚁图像数据集的样本数量: {ants_count}") print(f"蜜蜂图像数据集的样本数量: {bees_count}")
当你使用 len(ants_dataset) 时,Python 会自动调用 ants_dataset 对象的 len 方法,并返回该数据集的样本数量。





