- 定义(非正式):不进行明确编程的情况下,提供大量数据让计算机进行自我学习
- 分类:监督(supervised)学习,无监督(unsupervised)学习
- 监督学习:提供的数据中包含了问题到正确答案(x到y)的映射,或者说每条数据都有对应的标签,分为回归(regression)和分类(classification),回归:正确答案不可枚举,是连续的,比如房子大小、位置到房价的映射关系;分类:正确答案可以枚举,离散的,比如肿瘤大小、形状->恶性或良性,邮件->垃圾邮件或非垃圾
- 无监督学习:提供的数据不包含正确答案,或者说无法为数据集中的数据人工生成标签。分为聚类(cluster):数据集中的数据没有具体类型的情况下,将数据分类,比如新闻分类,推荐系统
回归
- 假设函数(hypothesis): h θ ( x ) = θ 0 x 0 + θ 1 x 1 + . . . + θ n x n = θ x , θ 是行向量, x 是列向量 {h}_{\theta}(x)={\theta}_{0}{x}_{0}+{\theta}_{1}{x}_{1}+...+{\theta}_{n}{x}_{n}={\theta}x,{\theta}是行向量,x是列向量 hθ(x)=θ0x0+θ1x1+...+θnxn=θx,θ是行向量,x是列向量,线性回归的目的是找到x到y的线性关系,根据提供的数据得到 θ i {\theta}_{i} θi的值,使h(x)对数据的拟合度最高
- 特征值:就是x0,x1…xn,回归函数中的自变量
- 成本函数(cost function,或者代价函数):用来计算 y ˆ \^{y} yˆ和y的误差, y ˆ \^{y} yˆ是通过h(x)计算得到的估计值,y是数据集中的实际值。假设数据集中的样本数为m,第i个样本的估计值是 y ^ ( i ) = h θ ( x ( i ) ) \hat{y}^{(i)}={h}_{\theta}(x^{(i)}) y^(i)=hθ(x(i)),第i个实际值是 y ( i ) y^{(i)} y(i),成本函数(差方实现) J ( θ ) = 1 2 m ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) 2 = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 ,其中 θ 是假设函数的系数 J(\theta)=\frac{1}{2m}\sum_{i=1}^{m} {(\hat{y}^{(i)}-y^{(i)})^2} = \frac{1}{2m}\sum_{i=1}^{m} {({h}_{\theta}(x^{(i)})-y^{(i)})^2},其中\theta是假设函数的系数 J(θ)=2m1i=1∑m(y^(i)−y(i))2=2m1i=1∑m(hθ(x(i))−y(i))2,其中θ是假设函数的系数
- 当假设函数 h θ ( x ) = θ 0 x + θ 1 时, {h}_{\theta}(x)={\theta}_{0}{x}+{\theta}_{1}时, hθ(x)=θ0x+θ1时,成本函数是关于 θ 0 、 θ 1 {\theta}_{0}、{\theta}_{1} θ0、θ1的二元函数,它是一个空间曲面,存在极小值点的碗状曲面,当函数取极小值时,h(x)对数据的拟合度最高
- 成本函数有多种实现,差方只是其中一种实现
- 当有多个特征值时,如果不同特征值的取值范围相差很大,比如0<x0<5,1000<x1<3000,x0的系数 θ 0 \theta_{0} θ0的微小变化不会引起函数值的较大变化,而 θ 1 \theta_{1} θ1的微小变化会引起函数值的较大变化,导致运行递归下降时不同系数收敛速度相差较大,收敛速度大在收敛值2侧振荡,导致梯度下降效率降低
- 特征值缩放:用于解决不同特征值取值范围相乘较大的问题,有多种方法。1、每个特征值除以最大值,这样所有取值范围都是0~1。2、均值归一化: x − μ m a x − m i n , μ 是均值 \frac{x-\mu}{max-min},\mu是均值 max−minx−μ,μ是均值, 取值范围:-1~1。3、 x − μ σ , σ 是方差 \frac{x-\mu}{\sigma},\sigma是方差 σx−μ,σ是方差,类似于正态分布的标准化
- 检查梯度下降是否收敛:将部分特征值输入梯度下降函数,计算每一轮迭代的代价函数值,绘制代价函数值和迭代次数的函数,如果该函数收敛,则梯度下降收敛,否则不收敛,有可能是学习率过大
- 多项式回归:用于拟合曲线
分类(逻辑回归)
- 逻辑回归(logistic regresion)就是分类
- 假设函数: h θ ( x ) = 1 1 + e − θ x , θ 是行向量, x 是列向量 , θ x 是多项式 {h}_{\theta}(x)=\frac{1}{1+e^{-{\theta}x}},{\theta}是行向量,x是列向量,{\theta}x是多项式 hθ(x)=1+e−θx1,θ是行向量,x是列向量,θx是多项式
- 决策边界: g ( x ) = 0 , 也就是 θ x = 0 g(x)=0, 也就是{\theta}x=0 g(x)=0,也就是θx=0,因为当g(x)>0时, y ˆ = 1 \^y=1 yˆ=1;当g(x)<=时, y ˆ = 0 \^y=0 yˆ=0
- 分类问题的y是离散值,因此假设函数不能用线性函数,这里使用了sigmoid函数(S型函数)+线性函数的复合函数, h θ ( x ) = 1 1 + e − g ( x ) , g ( x ) = θ x {h}_{\theta}(x)=\frac{1}{1+e^{-g(x)}},g(x)={\theta}x hθ(x)=1+e−g(x)1,g(x)=θx,g(x)是线性函数,取值范围-∞+∞,当g(x)->+∞时,h(x)->1;当g(x)->-∞时,h(x)->0;当g(x)=0时,h(x)=0.5。h(x)取值范围01的关于(0,0.5)对称的连续函数,因此可以将h(x)的函数值作为 y ˆ \^y yˆ=1的概率值,通过它构造一个离散型随机变量 y ˆ \^y yˆ的概率分布函数 P ( y ˆ = k ) = [ 1 − h θ ( x ) ] 1 − k ⋅ [ h θ ( x ) ] k ( k = 0 , 1 ) P(\^y=k)=[1-h_{\theta}(x)]^{1-k}{\cdot}[h_{\theta}(x)]^k ~~~ (k=0,1) P(yˆ=k)=[1−hθ(x)]1−k⋅[hθ(x)]k (k=0,1)
- 求系数的问题转化成了:已知概率分布,求参数的参数估计问题,可以使用极大似然估计,对于样本空间 x i , y i x^{i},y^{i} xi,yi, 似然函数:
L ( θ ) = ∏ i = 1 m [ 1 − h θ ( x ( i ) ) ] 1 − y ( i ) ⋅ [ h θ ( x ( i ) ) ] y ( i ) L(\theta)=\prod_{i=1}^{m}[1-h_{\theta}(x^{(i)})]^{1-y^{(i)}}{\cdot}[h_{\theta}(x^{(i)})]^{y^{(i)}} L(θ)=i=1∏m[1−hθ(x(i))]1−y(i)⋅[hθ(x(i))]y(i),
ln L ( θ ) = ∑ i = 1 m ( 1 − y ( i ) ) ln [ 1 − h θ ( x ( i ) ) ] + y ( i ) ln [ h θ ( x ( i ) ) ] \ln{L(\theta)}=\sum_{i=1}^{m}({1-y^{(i)}})\ln[1-h_{\theta}(x^{(i)})]+{y^{(i)}}\ln[h_{\theta}(x^{(i)})] lnL(θ)=i=1∑m(1−y(i))ln[1−hθ(x(i))]+y(i)ln[hθ(x(i))]
- 极大似然估计就是求似然函数取极大值时的参数 θ \theta θ, 刚好和代价函数的作用类似,代价函数可以取似然函数的相反数,这样代价函数取极小值时,参数 θ \theta θ就是期望的结果。
J ( θ ) = − 1 m ln L ( θ ) = 1 m ∑ i = 1 m − ( 1 − y ( i ) ) ln [ 1 − h θ ( x ( i ) ) ] − y ( i ) ln [ h θ ( x ( i ) ) ] J(\theta)=-\frac{1}{m}\ln{L(\theta)}=\frac{1}{m}\sum_{i=1}^{m}-({1-y^{(i)}})\ln[1-h_{\theta}(x^{(i)})]-{y^{(i)}}\ln[h_{\theta}(x^{(i)})] J(θ)=−m1lnL(θ)=m1i=1∑m−(1−y(i))ln[1−hθ(x(i))]−y(i)ln[hθ(x(i))]
其中 L o s s ( h θ ( x ( i ) ) , y ( i ) ) = − ( 1 − y ( i ) ) ln [ 1 − h θ ( x ( i ) ) ] − y ( i ) ln [ h θ ( x ( i ) ) ] 其中Loss(h_{\theta}(x^{(i)}),y^{(i)})=-({1-y^{(i)}})\ln[1-h_{\theta}(x^{(i)})]-{y^{(i)}}\ln[h_{\theta}(x^{(i)})] 其中Loss(hθ(x(i)),y(i))=−(1−y(i))ln[1−hθ(x(i))]−y(i)ln[hθ(x(i))]又称为损失函数loss function,代价函数J是损失函数的算数均值
\
∂ h ∂ θ j = x j ( i ) e − θ x ( 1 + e − θ x ) 2 \frac{\partial{h}}{\partial{\theta_{j}}}=\frac{x^{(i)}_{j}e^{-{\theta}x}}{(1+e^{-{\theta}x})^2} ∂θj∂h=(1+e−θx)2xj(i)e−θx
- 过拟合问题(over fitting):假设函数能够精准拟合训练数据的特征,但对新数据拟合度较差,也就是泛化程度较差,通常由于过度学习了训练数据中的细节和噪声。与之相对的是欠拟合(under fitting):假设函数对训练数据和新数据都不能正确拟合
- 解决过拟合:1、加入更多的训练数据。2、去除部分特征。3、正则化
正则化代价函数
- 用于解决回归和逻辑回归中的过拟合问题
- 通过缩小假设函数中特征值的系数来解决,缩小系数后,函数的曲线会更加平滑,从而减小对训练数据中的细节和噪声的过度拟合
- 如何缩小系数:在原代价函数的基础上加一个正则化项:所有非常数系数的平方和的算数均值,在最小化代价函数时,系数也会随着变小
- 逻辑回归的正则化代价函数:
J ( θ ) = 1 m ∑ i = 1 m − ( 1 − y ( i ) ) ln [ 1 − h θ ( x ( i ) ) ] − y ( i ) ln [ h θ ( x ( i ) ) ] + λ 2 m ∑ j = 1 n θ j 2 J(\theta)=\frac{1}{m}\sum_{i=1}^{m}-({1-y^{(i)}})\ln[1-h_{\theta}(x^{(i)})]-{y^{(i)}}\ln[h_{\theta}(x^{(i)})]+\frac{\lambda }{2m}\sum\limits_{j=1}^{n}{\theta _{j}^{2}} J(θ)=m1i=1∑m−(1−y(i))ln[1−hθ(x(i))]−y(i)ln[hθ(x(i))]+2mλj=1∑nθj2
- 正则化项的理解:1、系数的平方:为了求偏导后,仍有1次幂的系数,从而梯度下降时减去系数的倍数,去除系数的符号。2、除2m:求导后系数是1,使代价函数值与样本数无关。3、lambda:是正则化的学习率,比如取1,过大会导致系数过小,约等于0,假设函数变成了常数h(x)=b,也就是欠拟合;过小会导致系数过大,过拟合
深度学习
- 如果机器学习的决策边界函数(S型函数的g(x))是非线性函数,该函数很难得到,深度学习通过神经网络,将初始的特征值经过多层神经元层,也就是多个决策边界是线性函数的S型函数,最终得到结果
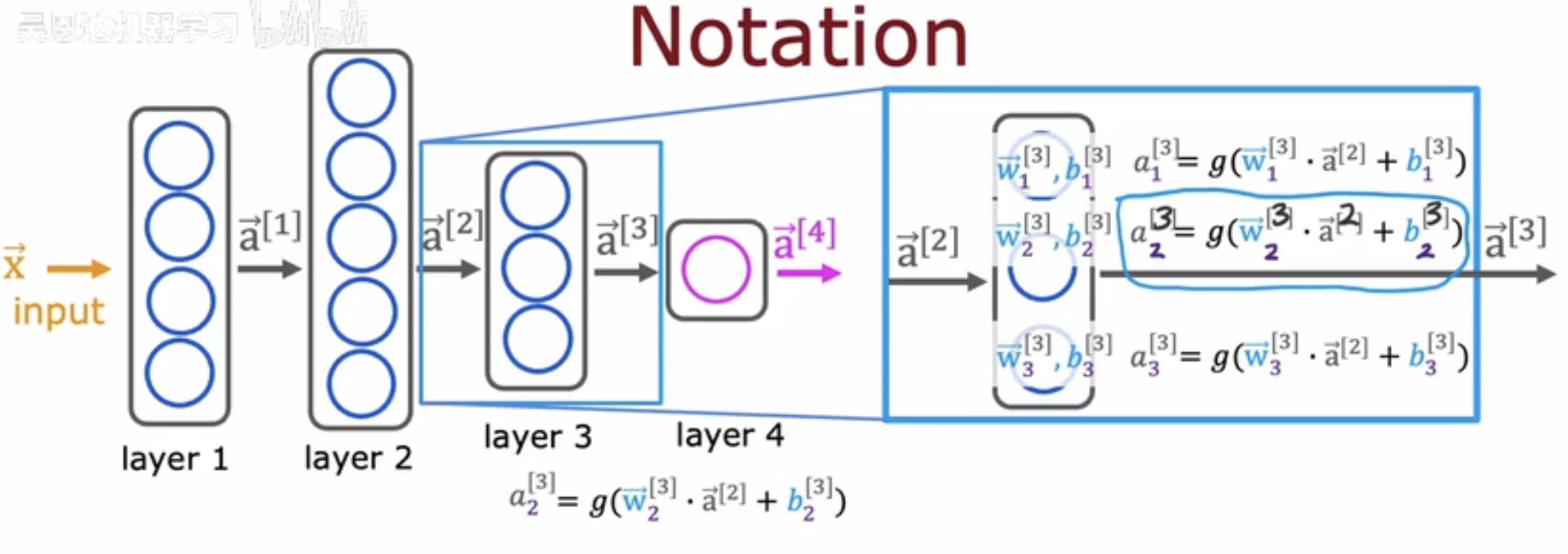
- 神经网络:神经网络包括多个神经元层,神经元层包括多个神经元
- 神经元层:分为输入层(第0层)、隐藏层(1~n-1)、输出层(第n层),输入层是起始特征向量,隐藏层是中间的神经元层,用于输入、计算、输出特征向量,输出层是最后一层,输出最终结果,神经元层串联形成神经网络,神经元层的输入是上一个层的输出
- 神经元:每个神经元包含1个S型函数,不同神经元的S型函数的参数不同,对于同层的神经元,每个S型函数的输入是上一个层的输出特征向量,输出是一个标量,同层所有的输出组成该层的输出特征向量
- 偏置值:就是激活函数的常数项,隐藏层中不包含偏置值的神经元,对于隐藏层,得到输出的特征向量后,再加一列偏置值,隐藏层的系数中包括了偏置值的系数
- 激活函数:每个神经元对应1个复合函数g(z(x)),复合函数的内层函数z(x)是线性函数,外层函数g(z)是激活函数,包括S型函数、线性函数、relu函数。
- 如何选择激活函数:如果隐藏层和输出层都用线性函数,那么整个神经网络就相当于是线性函数的复合函数,仍是线性函数,无法拟合非线性关系。对于逻辑回归,输出层一般用S形函数;线性回归,输出层用线性函数;结果只能为正数的回归,输出层用ReLU。隐藏层大多数情况用relu函数
- ReLU函数(Rectified Linear Unit,整流线性函数):g(z)=max{0,z},是分段线性函数,不同系数的relu函数相加是多分段的线性函数,可以近似非线性函数,比如relu_(-2x+1)+relu_(3x-3)+relu_(-2x-5)+relu_(4x-100),可以近似看成1元2次函数。设神经网络中有隐藏层A,B,B是A的上一层,对于B中的神经元b1,它接受A的所有神经元的输出,也就是多个relu函数值,将这些函数值输入自己的线性函数,相当于对多个relu函数相加
- relu函数的优点:1、相比于S型函数,便于计算。2、S型函数的代价函数很多地方较为平坦(导数绝对值较小),这导致用梯度下降最小化S型函数时,迭代次数增多,而relu函数是线性函数,它的代价函数梯度较大,梯度下降效率高
- softmax函数:用于多分类的激活函数,用在输出层,比如3个分类,识别照片中的汽车、人、树木,输入照片的像素数组,对于每张照片,输出长度为3的向量,(a0,a1,a2)
z 0 = w 0 x 0 + b 0 z 1 = w 1 x 1 + b 1 z 2 = w 2 x 2 + b 2 a 0 = g ( z 0 ) = e z 0 e z 0 + e z 1 + e z 2 = P ( y = 0 ) a 1 = g ( z 1 ) = e z 1 e z 0 + e z 1 + e z 2 = P ( y = 1 ) a 2 = g ( z 2 ) = e z 2 e z 0 + e z 1 + e z 2 = P ( y = 2 ) ( a 0 , a 1 , a 2 ) 是神经网络的输出向量,是 3 个概率值, y 是训练数据的真实标签值 z_0=w_0x_0+b_0 \\ z_1=w_1x_1+b_1\\ z_2=w_2x_2+b_2\\ a_0=g(z_0)=\frac{e^{z_0}}{e^{z_0}+e^{z_1}+e^{z_2}}=P(y=0)\\ a_1=g(z_1)=\frac{e^{z_1}}{e^{z_0}+e^{z_1}+e^{z_2}}=P(y=1)\\ a_2=g(z_2)=\frac{e^{z_2}}{e^{z_0}+e^{z_1}+e^{z_2}}=P(y=2)\\ (a_0,a_1,a_2)是神经网络的输出向量,是3个概率值,y是训练数据的真实标签值 z0=w0x0+b0z1=w1x1+b1z2=w2x2+b2a0=g(z0)=ez0+ez1+ez2ez0=P(y=0)a1=g(z1)=ez0+ez1+ez2ez1=P(y=1)a2=g(z2)=ez0+ez1+ez2ez2=P(y=2)(a0,a1,a2)是神经网络的输出向量,是3个概率值,y是训练数据的真实标签值
- softmax的损失函数:
L o s s = { − ln a 0 , y = 0 − ln a 1 , y = 1 − ln a 2 , y = 2 Loss= \begin{equation} \begin{cases} -\ln{a_0}, y=0 \\ -\ln{a_1}, y=1 \\ -\ln{a_2}, y=2 \\ \end{cases} \end{equation} Loss=⎩ ⎨ ⎧−lna0,y=0−lna1,y=1−lna2,y=2
- 改进的softmax写法:1、将输出层激活函数由softmax改为linear。2、将from_logits=True
tf.keras.layers.Dense(units=10,activation='linear')
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True))
- 使用改进的softmax,防止因指数值过大或过小导致数值溢出,输出层返回线性函数值,也就是logits值,损失函数的from_logits设为true,在损失函数中计算softmax概率和损失函数值时,通过指数值缩放、对数化简等操作,防止计算过程中的中间值发生溢出
M = m a x ( z 0 , z 1 , z 2 ) 1 、如果指数值过大,将指数值减去最大值,从而减小指数值 2 、为了防止 l n ( x / y ) 中的 x / y 过小,接近 0 ,导致对数值下溢,将它化为 l n x − l n y 假设 y = 2 , L o s s = − ln a 2 = − ln e z 2 e z 0 + e z 1 + e z 2 = − ln e z 2 − M e z 0 − M + e z 1 − M + e z 2 − M = − ( z 2 − M − ln ∑ j = 1 m e z j − M ) M=max(z_0,z_1,z_2) \\ 1、如果指数值过大,将指数值减去最大值,从而减小指数值\\ 2、为了防止ln(x/y)中的x/y过小,接近0,导致对数值下溢,将它化为lnx-lny \\ 假设y=2,Loss = -\ln{a_2}=-\ln{\frac{e^{z_2}}{e^{z_0}+e^{z_1}+e^{z_2}}}=-\ln{\frac{e^{z_2-M}}{e^{z_0-M}+e^{z_1-M}+e^{z_2-M}}}=-(z_2-M-\ln{\sum_{j=1}^{m}e^{z_j-M}}) M=max(z0,z1,z2)1、如果指数值过大,将指数值减去最大值,从而减小指数值2、为了防止ln(x/y)中的x/y过小,接近0,导致对数值下溢,将它化为lnx−lny假设y=2,Loss=−lna2=−lnez0+ez1+ez2ez2=−lnez0−M+ez1−M+ez2−Mez2−M=−(z2−M−lnj=1∑mezj−M)
- 密集层:神经元层有不同的类型,这是其中一种类型,密集层的神经元的激活函数是上一层所有神经元输出值的函数
- 卷积层:神经元层的一种类型,密集层的神经元的激活函数是上一层部分神经元输出值的函数。优点:1、因为只计算部分输出值,计算速度更快。2、更少的训练数据,更不容易过拟合
- 不同类型的神经元层可以组合在同一个神经网络
度量指标
- 测试训练结果:可以将样本随机分成2份,1份占70%,1份30%,第1份作为训练数据,第2份作为测试数据,对于测试数据,回归和分类问题可以通过计算测试数据的损失函数的均值来测试模型准确率,分类问题还可以直接计算每个标签的预测值的准确率来测试模型
- 交叉验证(cross validation data):用于调试模型时的样本,和测试样本的区别:交叉验证用于调整模型中的参数,测试样本用于模型确定后,计算损失函数值
- J t r a i n J_{train} Jtrain是训练数据计算的平均预测误差, J c v J_{cv} Jcv交叉验证数据计算的平均预测误差, J t e s t J_{test} Jtest测试数据,是代价函数的基础上去掉了正则化项的函数。
- 偏差(bias):训练数据的预测值和真实值的平均预测误差( J t r a i n J_{train} Jtrain),高偏差意味着欠拟合,对训练数据和测试数据都不能很好的拟合。
- 方差(variance):交叉验证数据的预测值和真实值的平均预测误差( J c v J_{cv} Jcv),高方差意味着过拟合,对训练数据能很好拟合,但对交叉验证数据拟合差
- J c v ≈ J t r a i n > > 基准值 = > 高偏差, J c v > > J t r a i n ≈ 基准值 = > 高方差, J c v > > J t r a i n > > 基准值 = > 高偏差和高方差 J_{cv} \approx J_{train} >>基准值 => 高偏差,J_{cv}>>J_{train} \approx 基准值 =>高方差,J_{cv}>>J_{train} >> 基准值 => 高偏差和高方差 Jcv≈Jtrain>>基准值=>高偏差,Jcv>>Jtrain≈基准值=>高方差,Jcv>>Jtrain>>基准值=>高偏差和高方差
- 神经网络中,使用更复杂的神经网络,比如更多神经元层、每层更多神经元,可以降低偏差,也就是可以更好拟合训练数据;增大正则化参数,可以降低方差
- 增加训练数据只对高方差的模型有效,可以降低方差,但不能降低偏差。因为高方差意味着过拟合,增加训练数据可以增加模型泛化程度,而高偏差是模型本身过于简单;增加特征数:解决高偏差;减少特征数:解决高方差,相当于将一些系数减至0;
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
# Adam算法:是自适应学习率的梯度下降算法,会在梯度下降的过程中自适应调整学习率,从而加快最小化的过程,learning_rate是初始学习率
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),metrics=['accuracy'] #对于分类问题,可以加accuracy,针对每个分类测试预测的准确率,加上它后,evaluate函数返回的dict多了一个accuracy
)
# 用训练数据最小化损失函数:比如使用梯度下降算法,epochs是迭代次数
model.fit(X_train, y_train, epochs=20)
# Jtrain: {'accuracy': 0.978857159614563, 'loss': 0.10094927251338959}
print(f"Jtrain: {model.evaluate(X_train, y_train,verbose=2,return_dict=True)}")
# 根据测试样本、真实标签值、训练好的系数,计算损失函数
result = model.evaluate(X_test, y_test,verbose=2,return_dict=True)
# Jtest: {'accuracy': 0.9246666431427002, 'loss': 0.27228856086730957}, 0.2828-0.0978=0.185
print(f"Jtest: {result}")
- 正则化函数:分为l1和l2两种正则化函数,l1正则化允许将系数减为0,l2不会减为0,而是->0,不同神经元层允许使用不同正则化函数,输入层到隐藏层通常需要更大的正则化参数,从而减小对初始特征的拟合
- 如何实现:l1正则化项是权重绝对值之和,l2是权重平方和。反向传播计算权重的偏导数时,根据权重所在层,使用对应的正则化参数
l 1 的正则化项: λ m ∑ i = 1 m ∣ w i ∣ l 2 的正则化项: λ 2 m ∑ i = 1 m w i 2 l1的正则化项:\frac{\lambda}{m}\sum_{i=1}^{m}{\lvert{w_i}\rvert} \\ l2的正则化项:\frac{\lambda}{2m}\sum_{i=1}^{m}{{w_i}^2} l1的正则化项:mλi=1∑m∣wi∣l2的正则化项:2mλi=1∑mwi2
model = tf.keras.models.Sequential([tf.keras.layers.Dense(units=35,activation='relu',# 正则化函数:分为l1和l2两种正则化函数,l1正则化允许将系数减为0,l2不会减为0,而是->0,不同神经元层允许使用不同正则化函数,输入层到隐藏层通常需要更大的正则化参数,从而减小对初始特征的拟合,# 如何实现:l1正则化项是权重绝对值之和,l2是权重平方和。反向传播计算权重的偏导数时,根据权重所在层,使用对应的正则化参数kernel_regularizer=tf.keras.regularizers.l2(0.01)),tf.keras.layers.Dense(units=25,activation='relu',kernel_regularizer=tf.keras.regularizers.l2(0.001)),tf.keras.layers.Dense(units=10,activation='linear',kernel_regularizer=tf.keras.regularizers.l2(0.0001))])
- 机器学习项目开发流程:1、确定需求,机器学习需要实现什么,比如识别垃圾邮件。2、收集训练数据。3、训练神经网络,使用偏差-方差分析,误差分析调整神经网络。4、部署机器学习应用(MLOps)
- 错误分析(error analysis):训练好神经网络后,使用交叉验证数据得到预测值,获取其中不符合真实值的,对于分类问题,分析其中占比多的类别,针对性的加强这些类别的数据的训练。比如识别垃圾邮件,预测值中,原本是垃圾邮件但未识别到的,医药广告占比较多,增加医药广告的垃圾邮件样本的训练
- 如果能获取的训练数据较少,有2种方法解决:
- 数据增强:用训练数据,增加噪声或变型来得到新的真实值相同的训练数据,比如手写字母识别,将字母旋转、扭曲、镜像,得到新数据;语音识别,将原音频加上背景人声或车声,得到新数据
- 迁移学习:对于同类型的神经网络,可以将得到大量训练数据训练的隐藏层,复用到少量训练数据神经网络中。比如识别手写字母,训练数据较少(50),可以先从网上下载已经训练1百万张识别猫、狗、车、人等物体的神经网络,复用隐藏层参数,用较少的手写字母照片训练输出层参数。
- 必须是同类型的网络才能迁移学习:比如识别照片中的物体的神经网络,识别语音的。因为同类型的前几层是公共的,比如照片,第1层识别灰度或颜色不同像素的边缘,第2层识别夹角,第3层识别各种基础图形
精准率和召回率
- 精准率(P,Precision)和召回率(R,Recall)通常用在分类问题中,对于2分类,精准率是预测为正的样本中预测正确的概率,召回率是实际为正的样本中预测为正的概率
| 预测值/真实值/个数 | 1 | 0 |
|---|---|---|
| 1 | 15 | 70 |
| 0 | 10 | 5 |
- 精准率=15/(15+70),召回率=15/(15+10)
- 精准率和召回率一个增加,另一个就会减小,比如2分类问题中,预测概率>90%为正,则精准率增加,召回率减小;预测概率>20%为正,则召回率增加,精准率减小
- F1值:用于平衡精准率和召回率,使它们不会相差过大,等于精准率和召回率的调和平均数
F 1 = 1 1 2 ( 1 P + 1 R ) = 2 P R P + R F1=\frac{1}{\frac{1}{2}(\frac{1}{P}+\frac{1}{R})}=\frac{2PR}{P+R} F1=21(P1+R1)1=P+R2PR
决策树、随机森林
- 决策树模型(Decision Tree):和神经网络一样,是一种机器学习模型,可以用于拟合分类问题的数据
- 如何生成决策树:
- 选择最优特征分割数据:假设训练的样本数据为S,特征包括a1,a2,a3…an,遍历每个特征,对于特征ai,根据ai将数据S分割成2部分,计算这2部分的熵值的加权平均值avg,再用S的熵值减avg,得到熵的减少值detaH,选择detaH最大的特征,使用该特征分割数据,原数据S作为父节点,分割后的2份数据作为左右子节点
- 对左右子节点递归进行第1步,直到树的深度达到预定最大值,或者熵减为某个值以下、节点的样本数小于某个值。这时的叶子节点,占比较大的标签为叶子结点的标签
- 特征值的取值都是2元的,对于多元特征,可以通过one-hot编码转为2元的
- one-hot编码:比如3元特征值A取值a,b,c,可以转成3个2元特征值:是否为a,是否为b,是否为c
- 熵值(entropy):表示了数据的混乱程度,或者不纯净程度,熵越小,越纯净,每次分割数据,取使数据最纯净的特征值
对于数据 S ,分类的标签是 C 1 , C 2 . . . C n , H = − ∑ i = 1 n p i l o g 2 p i p i 是标签 C i 占数据 S 总数的比例 对于数据S,分类的标签是C_{1},C_2...C_n,\\ H=-\sum_{i=1}^{n}p_{i}log_{2}p_{i}\\ p_{i}是标签C_i占数据S总数的比例\\ 对于数据S,分类的标签是C1,C2...Cn,H=−i=1∑npilog2pipi是标签Ci占数据S总数的比例
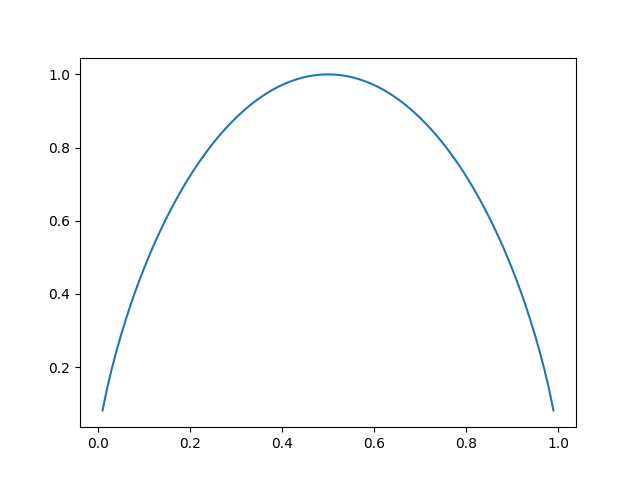
- 对于2分类,当分类C占比过多或过少时,熵值较小,当C占比是0.5时,熵值最大,熵值在0~1之间
- 对于连续型的特征值,可以选择一个阈值,根据特征值是否大于该阈值,将数据分成2份。阈值的选择:和特征值的选择类似,尝试多个阈值,将数据分成2份,选择熵减小值最大的阈值
- 回归树:决策树用于解决分类问题,回归树解决回归问题,也就是标签值是连续的,无法使用标签的占比来计算熵值,而是使用标签值的样本方差来表示数据的离散程度,根据特征将数据分成2份后,计算这2份的方差的加权平均avg,再用分割前的数据的方差减去avg,得到方差减小值,选择方差减小最大的特征。递归,直到方差低于阈值。这样相当于将标签值大小相似的数据聚合到同一叶子节点。叶子结点的标签值取它包含数据的平均值
- 决策树的过拟合问题:如果树的深度过大,会导致过拟合,一般只会选用部分特征值来生成决策树
- 预测:生成决策树的过程就是训练数据的过程,对于新数据,从根节点开始,使用特征值对决策树自顶向下遍历,直到根节点,根节点对应的标签就是新数据的预测值
- 随机森林:特征值在单个决策树的位置很容易受样本数据影响,比如样本空间的一个样本的不同,就可能导致训练出来的决策树不同,从而影响预测结果。随机森林通过n次放回抽样,每次从样本空间中选取样本,来构造n个多个决策树,构造每个决策树时,只随机取部分特征中的最优特征来分割节点。
- 随机森林预测:输入特征值,求每个决策树的输出,对于分类问题,通过投票选择票数最多的标签值;对应回归,取均值
- 放回抽样:假设样本空间S的样本数为m,每次放回抽样取m个样本,但因为是放回抽样,会有重复的和未被抽到的。好处:增加数据的不确定性,从而减少过度拟合,增加泛化能力
- XGBoost(extrime gradient boosting):分布式的决策树库
- 决策树和神经网络的区别:
- 决策树只适合结构化数据,对于非结构化数据,比如图片、语音等二进制数据,只能用神经网络
- 决策树训练和预测速度快,人类易于理解的模型
无监督学习
- 无监督学习:只有样本X,没有标签值y
k-meas聚类
- 均值聚类算法,是一种聚类算法,将样本X分成多个聚类,每个聚类是X的子集,相同聚类的特征值相近
- 如何衡量特征值的远近:样本的特征向量的距离,比如2个样本(a1,a2,a3),(b1,b2,b3)
距离 D = ( a 1 − b 1 ) 2 + ( a 2 − b 2 ) 2 + ( a 3 − b 3 ) 2 距离D=\sqrt{(a_1-b_1)^2+(a_2-b_2)^2+(a_3-b_3)^2} 距离D=(a1−b1)2+(a2−b2)2+(a3−b3)2
- 算法逻辑:
- 假设样本S={x1,x2…xn},随机选择k个初始中心点,遍历S,找到距离样本xi最近的中心点 x i j ( 0 < = j < = k ) x_i^j (0<=j<=k) xij(0<=j<=k),也就是根据中心点到样本的距离,将样本分成k份
- 遍历k份样本,求每一份样本的中心点,并更新初始中心点。中心点的特征值是聚类中样本特征值的均值
- 重复1,2,直到达到迭代次数
- k-means++:初始中心点的选择算法,选择相互距离最远的中心点,用于减少算法运行次数,加快收敛
- 算法逻辑:逐个选择中心点,第一个点随机选择,后续的点按概率选择
样本 x i 被选中的概率 P ( x i ) = D i 2 ∑ j = 1 n D j D i 是 x i 与当前最近中心点的距离 样本x_i被选中的概率P(x_i)=\frac{D_{i}^2}{\sum_{j=1}^{n}D_j} \\ D_i是x_i与当前最近中心点的距离 样本xi被选中的概率P(xi)=∑j=1nDjDi2Di是xi与当前最近中心点的距离
- 距离最近的已选的中心点的距离最远的点概率最大,从而保证中心点选点过于集中,导致局部最优的问题
- 为什么用概率而不直接用最远的点:防止噪声影响
- k-means可用于图像压缩:将图片中的像素进行k-means聚类,将像素值相近的分到同一个聚类中,用聚类的像素均值代替聚类中的所有像素。聚类中的像素不一定是位置相近的,而是颜色相近的,用一种颜色替换多个颜色相近的
from sklearn.cluster import KMeans#导入kmeans库# 创建一个k-means模型,n_clusters是聚类的个数,也就是中心点的个数,n_init是使用不同初始中心点运行k-means算法的次数
# init参数是选择中心点的策略,默认k-means++,选择相互距离最远的中心点,用于减少算法运行次数,加快收敛
# 算法逻辑:逐个选择中心点,第一个点随机选择,后续的点按概率
# 选择,距离最近的已选的中心点的距离最远的点概率最大,从而保证中心点选点过于集中,导致局部最优的问题
# 为什么用概率而不直接用最远的点:防止噪声影响
# max_iter:单次算法逼近收敛的迭代次数
model = KMeans(n_clusters=16, n_init=100)
model.fit(data)
centroids = model.cluster_centers_
print(centroids.shape)C = model.predict(data)
print(C.shape)
异常检测
- 用于检测数据是否是异常数据,类似于2分类,但样本中的异常数据较少,不足以覆盖所有的异常情况。比如根据CPU负载、网络IO、磁盘IO等特征检测服务器是否异常
- 中心极限定理:当样本数足够多时,n个独立同分布的随机变量(期望和方差收敛)之和满足正态分布。很多特征是多个随机因素的叠加,因此满足正态分布,比如身高受到遗传、后天因素、测量误差的影响
- 训练:根据样本的每个特征计算均值和方差即可
训练:根据极大似然估计,可得单个特征值 x ( j ) 的均值和方差的估计值: μ j = ∑ i = 1 m x i ( j ) , σ j 2 = 1 m ∑ i = 1 m ( x i ( j ) − μ ) x ( j ) 的概率密度函数 P ( x ( j ) = x ) = N ( μ j , σ j 2 ) n 个特征值的概率密度函数 P ( X = x ) = ∏ j = 1 n N ( μ j , σ j 2 ) 预测:取一个阈值 ϵ , 当 P ( X = x ) < ϵ 时,说明该样本出现的概率较小,为异常数据 训练:根据极大似然估计,可得单个特征值x^{(j)}的均值和方差的估计值:\mu_j=\sum_{i=1}^{m}x^{(j)}_i ~~~,~~~~ \sigma_j^2=\frac{1}{m}\sum_{i=1}^{m}(x^{(j)}_i-\mu) \\ x^{(j)}的概率密度函数P(x^{(j)}=x)=N(\mu_j,\sigma_j^2) \\ n个特征值的概率密度函数P(X=x)=\prod_{j=1}^{n}N(\mu_j,\sigma_j^2) \\ 预测:取一个阈值\epsilon,当P(X=x)<\epsilon时,说明该样本出现的概率较小,为异常数据 训练:根据极大似然估计,可得单个特征值x(j)的均值和方差的估计值:μj=i=1∑mxi(j) , σj2=m1i=1∑m(xi(j)−μ)x(j)的概率密度函数P(x(j)=x)=N(μj,σj2)n个特征值的概率密度函数P(X=x)=j=1∏nN(μj,σj2)预测:取一个阈值ϵ,当P(X=x)<ϵ时,说明该样本出现的概率较小,为异常数据
- 对于不满足正态分布的特征x,可以取ln(x+C),常数C是为了防止x等于0,或者取x^u (0<u<1)
- 什么时候用异常检测,什么时候用监督学习:样本的异常数据较少,不足以覆盖所有异常情况,或者说异常的种类无法穷尽时,使用异常检测,否则监督学习
- 如何选择阈值:从概率密度的最小值和最大值之间选择,将最小值到最大值的区间分成1000个待选的阈值,计算每一个阈值对应的精准率和召回率,从而得到F1值,选择使F1值最大的阈值
- 预测:如果样本x的任意一个特征值小于阈值,则为异常样本
- 精准率和召回率的计算需要知道样本的真实标签值
推荐系统
协同过滤
- 基于打分的推荐系统实际上是线性回归,商品的分数可以是用户手动打分,也可以是根据用户对商品的行为进行打分,比如是否购买、收藏、点赞、视频是否播放完,训练的样本数据是已经打分的分数,预测未打分的分数
- 协同过滤算法:是一种线性回归,但权重和特征值都是未知数(商品的特征值未知),所以代价函数是权重theta和特征值X的函数,X是电影的特征值,theta是用户的特征值,用户和商品的特征值个数相同,X.shape=(num_movies, num_features), theta.shape=(num_users, num_features), X * theta.T是预测评分
- 使用均方差代价函数
J ( θ , x ) = 1 2 ∑ ( i , j ) : r ( i , j ) = 1 ( ( θ ( j ) ) T x ( i ) − y ( i , j ) ) 2 + 1 2 ∑ j = 1 n u ∑ k = 1 n θ k ( j ) + 1 2 ∑ j = 1 n m ∑ k = 1 n x k ( j ) 其中 i 是电影索引, x ( i ) 是第 i 部电影的特征值向量, j 是用户索引, θ ( j ) 是第 j 个用户的系数向量, y ( i , j ) 是实际评分 协同过滤的代价函数去掉了样本数 m n 是特征数, n u 是用户数, n m 是电影数 J(\theta,x)=\frac{1}{2}\sum_{(i,j):r(i,j)=1}((\theta^{(j)})^Tx^{(i)}-y^{(i,j)})^2+\frac{1}{2}\sum_{j=1}^{n_u}\sum_{k=1}^{n}\theta_{k}^{(j)}+\frac{1}{2}\sum_{j=1}^{n_m}\sum_{k=1}^{n}x_{k}^{(j)} \\ 其中i是电影索引,x^{(i)}是第i部电影的特征值向量,j是用户索引,\theta^{(j)}是第j个用户的系数向量,y^{(i,j)}是实际评分 \\ 协同过滤的代价函数去掉了样本数m \\ n是特征数,n_u是用户数,n_m是电影数 J(θ,x)=21(i,j):r(i,j)=1∑((θ(j))Tx(i)−y(i,j))2+21j=1∑nuk=1∑nθk(j)+21j=1∑nmk=1∑nxk(j)其中i是电影索引,x(i)是第i部电影的特征值向量,j是用户索引,θ(j)是第j个用户的系数向量,y(i,j)是实际评分协同过滤的代价函数去掉了样本数mn是特征数,nu是用户数,nm是电影数
# 代价函数,
def cofiCostFuncV(X,Theta,Y,R,lamda): # 转换为 TensorFlow 张量(若尚未转换)Y = tf.convert_to_tensor(Y, dtype=tf.double)R = tf.convert_to_tensor(R, dtype=tf.double)# 计算预测误差(仅对已评分项)predictions = tf.matmul(X, Theta, transpose_b=True) # X @ Theta^Terror = tf.multiply(predictions - Y, R)# 成本函数(均方误差部分)squared_error = tf.square(error)J = 0.5 * tf.reduce_sum(squared_error)# 添加正则化项(L2正则化)reg_cost = (lamda / 2) * (tf.reduce_sum(tf.square(Theta)) + tf.reduce_sum(tf.square(X)))J = J + reg_costreturn Jimport tensorflow as tf
X_tf = tf.Variable(np.random.random(size=(movies, features)))
Theta_tf = tf.Variable(np.random.random(size=(users, features)))
learning_rate = 0.001 # 典型Adam初始学习率
lambda_ = 0.1 # 正则化系数
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
iterations = 200
for iter in range(iterations):# tensorflow使用GradientTape计算梯度(导数),通过tf.Variable对象,实现代价函数时,要注意不能将tensorflow张量的运算和numpy的运算混用,tensorflow张量的运算内部会将每一步对tf.Variable的运算操作记录到tape的DAG中,执行tape.gradient(target,sources)时,会从target开始查找到每个source的运算路径,如果1个source对应多个路径,单个路径,执行复合函数求导的乘法法则,多个路径,将它们相加# tf.GradientTape()返回的对象的__enter__方法会将tape保存到threadLocal中,__exit__方法清理,因此代价函数必须放到with块,否则tape记录不到运算操作with tf.GradientTape() as tape:cost_value = cofiCostFuncV(X_tf,Theta_tf,Ynorm,R,lambda_)grads = tape.gradient(cost_value,[X_tf,Theta_tf])# 使用Adam优化器运行一次梯度下降,也就是用X_tf,Theta_tf减去对应的梯度*学习率,并更新optimizer.apply_gradients(zip(grads,[X_tf,Theta_tf]))print(X_tf.numpy()[0,:5])
print(Theta_tf.numpy()[0,:5])
基于内容的过滤
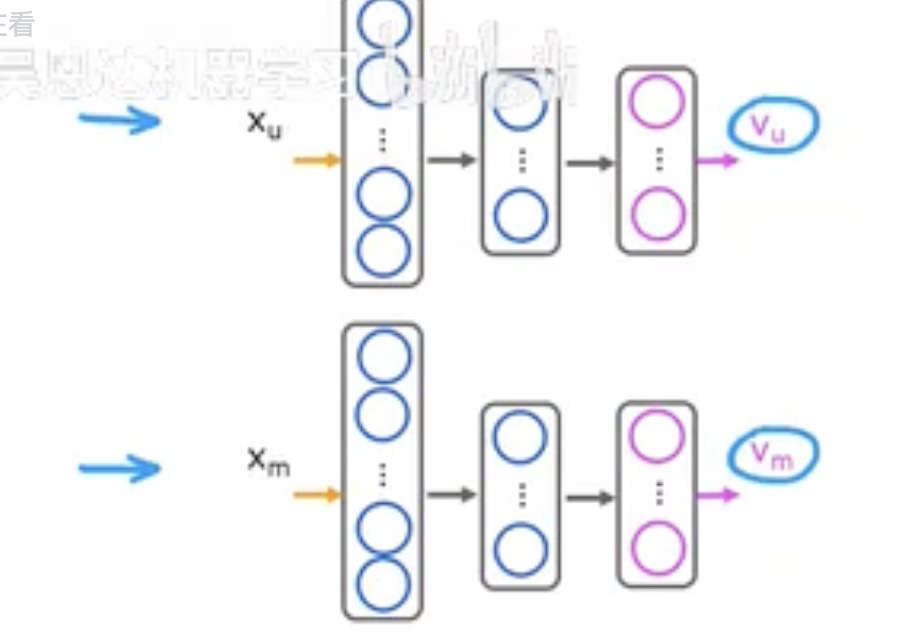
- 与协同过滤的区别:基于内容的过滤,用户和商品的特征值个数可以不同,通过2个神经网络分别将用户和商品的特征向量降维成相同维度,再求它们的向量点积,点积就是预测的分数
- 也需要打分,推荐分值高的
- 商品之间的特征向量的距离:可以用来实现相似推荐,比如用户与一个商品互动过,查找与该商品距离最近的商品
- 需要组合2个神经网络,神经网络的输入分别是用户特征x_u(姓名、年龄、性别、国家等信息)和商品特征x_m,输出v_u和v_m维数相同,v_u * v_m是预测分数,跟实际分数的训练数据进行训练,得到神经网络的参数
user_NN = tf.keras.models.Sequential([tf.keras.layers.Dense(256,activation='relu'),tf.keras.layers.Dense(128,activation='relu'),tf.keras.layers.Dense(32)
])
item_NN = tf.keras.models.Sequential([tf.keras.layers.Dense(256,activation='relu'),tf.keras.layers.Dense(128,activation='relu'),tf.keras.layers.Dense(32)
])
num_user_features=100
input_user = tf.keras.layers.Input(shape=(num_user_features))
# 将高维的特征向量降维,比如输入100维,输出32维,返回一个矩阵,shape=(batch_size,num_user_features),batch_size如果大于1,一次性可以处理多个用户
vu = user_NN(input_user)
# 将特征值归一化,也就是向量单位化,使向量的坐标值范围不会相差过大,从而影响梯度下降效率
vu = tf.linalg.l2_normalize(vu,axis=1)
num_item_features=50
input_item=tf.keras.layers.Input(shape=(num_item_features))
vm=item_NN(input_item)
vm=tf.linalg.l2_normalize(vm,axis=1)output=tf.keras.layers.Dot(axes=1)([vu,vm])
# 创建训练模型,用于训练和预测
model=tf.keras.Model([input_user,input_item],output)
cost_fn=tf.keras.losses.MeanSquaredError()
强化学习
- 状态S、动作A、奖励值R:系统中的实例任一时刻都会处于某种状态S,执行某个动作后会变更为另一种状态,每个状态对应一个奖励值,强化学习的目的是处于状态S时,找到一个使奖励值最大的动作
- 和监督学习的区别:如果能找到每个状态到动作映射,那么可以用监督学习,但有些场景下x->y的映射是模糊的,比如控制无人机飞行时,无人机的状态->操控动作,棋类AI中,落子状态->下一步落子,这时强化学习更好。强化学习在x,y的基础上引入了奖励函数,根据状态返回奖励值,通过训练,让程序多做使奖励值高的动作,少做奖励值低的动作
- 折扣因子:0~1之间的数,较大的折扣因子使算法倾向于寻找更远的奖励,较小的折扣因子使算法倾向于寻找更近的奖励
R = R 1 + γ R 2 + γ 2 R 3 + . . . + γ n − 1 R n γ 是折扣因子, R 是最终的奖励值, R 1 是当前状态的奖励值, R 2 是下一个状态的奖励值 . . . R=R_1+\gamma R_2+\gamma^2 R_3+...+\gamma^{n-1} R_n \\ \gamma是折扣因子,R是最终的奖励值,R_1是当前状态的奖励值,R_2是下一个状态的奖励值... R=R1+γR2+γ2R3+...+γn−1Rnγ是折扣因子,R是最终的奖励值,R1是当前状态的奖励值,R2是下一个状态的奖励值...
- 马尔科夫决策过程:根据当前状态来决定下一步的动作,神经网络学习的是当前状态到下一步动作以及对应奖励值的映射
- 状态-动作函数:Q(s,a)函数
Q ( s , a ) = R ( s ) + γ max a ′ ( Q ( s ′ , a ′ ) ) s 是当前状态, a 是 s 对应的 1 个动作, s ′ 是 s 经过 a 到达的动作, a ′ 是 s ′ 对应的所有动作 R ( s ) 是 s 对应的奖励值, max a ′ ( Q ( s ′ , a ′ ) ) 是 s ′ 对应的所有动作的 Q 的最大值 Q(s,a)=R(s)+\gamma\max_{a'}(Q(s',a')) \\ s是当前状态,a是s对应的1个动作,s'是s经过a到达的动作,a'是s'对应的所有动作 \\ R(s)是s对应的奖励值,\max_{a'}(Q(s',a'))是s'对应的所有动作的Q的最大值 Q(s,a)=R(s)+γa′max(Q(s′,a′))s是当前状态,a是s对应的1个动作,s′是s经过a到达的动作,a′是s′对应的所有动作R(s)是s对应的奖励值,a′max(Q(s′,a′))是s′对应的所有动作的Q的最大值
- 强化学习逻辑:
- 使用神经网络来拟合Q函数,神经网络的输入是状态向量(包含多个状态值),输出是所有的动作的Q函数值,从而可以选择最大的Q值的动作
- 一开始神经网络的参数是随机的,也就是Q函数是随机的。
- 生成训练样本(replay buffer,重放缓冲):随机生成10000个样本(s,a,R(s),s’),其中s随机生成,a和s’使用随机的Q函数得到
- 计算y值
将 s ′ 传入当前 Q 函数,输出的 Q 值的最大值就是 max a ′ ( Q ( s ′ , a ′ ) ) 根据 Q ( s , a ) = R ( s ) + γ max a ′ ( Q ( s ′ , a ′ ) ) 得到 Q ( s , a ) ,也就是 y 值 , x = s , 使用 ( x , y ) 训练 将s'传入当前Q函数,输出的Q值的最大值就是\max_{a'}(Q(s',a'))\\ 根据Q(s,a)=R(s)+\gamma\max_{a'}(Q(s',a'))得到Q(s,a),也就是y值,x=s,使用(x,y)训练 将s′传入当前Q函数,输出的Q值的最大值就是a′max(Q(s′,a′))根据Q(s,a)=R(s)+γa′max(Q(s′,a′))得到Q(s,a),也就是y值,x=s,使用(x,y)训练
- 用训练样本训练神经网络,得到Q_new,令Q=Q_new,完成一轮迭代,重复第4步,直到最大迭代次数
- ε-贪婪策略:因为一开始Q函数是随机的,有可能导致有些动作的Q值总是过小,导致选不到该动作,缺少该动作的训练数据。贪婪策略在初始生成动作时,使用概率(ε是概率值,比如ε=0.95)使用Q函数,0.05的概率随机选择动作,从而确保没有动作饥饿,概率值可以浮动,初始设为1,根据迭代次数逐渐降为0
五子棋AI
- 蒙特卡洛树搜索(MCTS):用于棋类、游戏AI,是一棵多叉数,根节点表示当前棋局状态,子节点表示执行合法的落子动作后的棋局状态,通过UCB(Upper Confidence Bound,上界置信区间)算法计算不同落子动作的分值,选择UCB值最大的节点
- UCB:平衡了探索(exploration)和利用(exploitation),利用代表过去的经验,是过去的平均奖励,等于当前节点胜利次数/访问次数,探索代表将来的潜力
U C B ( t , i ) = μ i ( t ) + C ln t / n i ( t ) t 是当前时间, i 是第 i 个动作, μ i ( t ) 是第 i 个动作到时间 t 的平均奖励, C 是常数, n i ( t ) 是第 i 个动作到时间 t 的尝试次数 第 2 项会随着探索次数增加而减少,因为 l n 增长更慢 UCB(t,i)=\mu_i(t)+C\sqrt{\ln{t}/n_i(t)} \\ t是当前时间,i是第i个动作,\mu_i(t)是第i个动作到时间t的平均奖励,C是常数,n_i(t)是第i个动作到时间t的尝试次数 \\ 第2项会随着探索次数增加而减少,因为ln增长更慢\\ UCB(t,i)=μi(t)+Clnt/ni(t)t是当前时间,i是第i个动作,μi(t)是第i个动作到时间t的平均奖励,C是常数,ni(t)是第i个动作到时间t的尝试次数第2项会随着探索次数增加而减少,因为ln增长更慢
- 平均奖励相同的情况下,探索次数少的UCB更高,防止某个动作因为一开始平均奖励较高而总是选择该节点
- 蒙特卡洛树搜索过程:1、选择:从根节点开始,选择UCB值高的子节点,直到棋局结束或叶子节点。2、扩展:如果到达叶子节点棋局未结束,创建一层新的子节点,该层子节点对应当前棋局的所有合法落子动作。3、反向传播:从叶子节点开始反向更新value值,value值正负号交替更新,直到根节点,如果棋局结束,value=1,否则用神经网络计算得到的。
- 五子棋AI结合了蒙特卡洛树搜索和强化学习,自我对弈时,使用蒙特卡洛树保存棋局状态
卷积神经网络(CNN, Convolution Neurual network)
- 全连接网络参数过多的缺点:对于图片等输入特征值较多的场景,全连接网络会导致参数过多,需要更多训练数据来防止过拟合。比如100010003(1000像素,3通道)的彩色RGB图片,如果全连接有1000个神经元,则大约有100010003*1000=30亿。
- 卷积运算:比如a1a2n的RGB图,m个ffn的过滤器(卷积核),步长=s,padding=p,会得到bbm的m通道的数据,其中每个过滤器输出bb的数据,每个ff*n的小区块只输出1个值,也就是对应位置相乘,在求和
b = a i + 2 p − f s + 1 ( i = 1 , 2 ) b=\frac{a_i+2p-f}{s}+1 ~~~~~(i=1,2) b=sai+2p−f+1 (i=1,2)
- 卷积层参数个数:(ffn+1)*m,卷积运算时,是先将n通道的卷积核乘以窗口内的矩阵,再加1个偏置值,而不是每个通道乘完之后分别加偏置值
- valid卷积:padding=0的卷积,same卷积:输入和输出(a=b)保持相同长宽的卷积
- padding作用:防止图片大小减小,充分利用图片边缘的像素
- 卷积网络的前几层用来识别不同角度的边缘(比如水平边缘、垂直边缘),比如A矩阵可以识别垂直边缘,因为左右列符号不同,当2侧像素值有相近差值,且差值较大时,输出的像素矩阵会有绝对值较大的像素,从而识别边缘
A = [ 1 0 − 1 1 0 − 1 1 0 − 1 ] A = \begin{bmatrix} 1 & 0 & -1 \\ 1 & 0 & -1 \\ 1 & 0 & -1 \end{bmatrix} A= 111000−1−1−1
- 池化层:卷积层用于计算卷积,池化层一般用在卷积层之后,用于提取卷积后的特征,比如卷积后若干像素代表眼睛,池化层提取其中的像素最大值来代表眼睛,从而减小特征值数。包括最大池化层和平均池化层,池化运算和卷积类似,aam的数据,池化层ff,步长=s,padding=p,输出bb*m,b的计算公式和卷积层相同。
- 和卷积层的区别:1、池化层窗口是单通道的,卷积层过滤器通道数必须和输入相同。2、池化层计算不会跨通道进行,窗口内多个通道分别计算池化层,而卷积层会跨通道计算。3、池化层的输出通道和输入通道相同,而卷积层的输出通道和过滤器的个数相同,每个过滤器输出是单通道的。4、池化层没有参数,只有超参数,池化层只有窗口大小,没有参数,因为只需要计算窗口内的最大值或均值
- 全连接层:通常位于CNN最后几层,卷积1->池化1->卷积2->池化2->…->扁平化层->全连接层。卷积层得到的是多维数组,经过扁平化后得到1D,输入全连接层
- 卷积层优点:1、参数共享:1个卷积核对应输入数据的多个窗口的计算,从而较少参数个数,防止过拟合。另外相似应用的卷积核参数可以复用(迁移学习)。2、稀疏连接:每个输出像素只对应部分输入像素
- 典型的卷积神经网络:卷积1->池化1->卷积2->池化2->…->扁平化层->全连接层->softmax层/tanh层。越往后,长宽缩小,通道数增加,激活数减小(到达全连接层时特征数相比于输入特征数减小)
残差网络、MobileNetV2
- 梯度消失或梯度爆炸:神经网络过深(层数过多)时,反向传播使用链式法则计算梯度,浅层梯度等于它的更深层梯度乘积,因此可能导致梯度消失(梯度<1)或梯度爆炸(梯度>1)
- 残差网络(ResNets,Residual Networks):用来解决神经网络过深导致梯度消失或梯度爆炸的问题,残差网络由多个残差块组成
- 残差块:由2条路径组成,1条主路径,多个卷积层+池化层组成,1条短路路径,是等值映射或瓶颈映射,等值映射将输入直接传给最后一个卷积层的relu函数之前,将输入和主路径的输出相加;瓶颈映射用来解决输入和主路径的输出形状不匹配的问题,在短路路径中加入了1*1,步长不为1,数量和主路径输出通道数相同的卷积核,从而将短路的输出形状修改成和主路径一致
- 为什么可以解决梯度消失问题:通过引入短路路径,将深层的梯度直接传递到浅层
- 数据增强:将若干用于数据增强的层加进列表中,数据增强的层有翻转RandomFlip,旋转RandomRotation,注意它们都是随机的,有概率不进行增强操作,并且默认只会在训练的时候执行,预测时不执行,如果将train=true,则预测时也会执行。
- RandomFlip:进行水平或垂直翻转
- RandomRotation:将图片旋转(不是扭曲),旋转的角度取决于旋转因子factor, [-factor2pi,factor2pi]
# UNQ_C1
# GRADED FUNCTION: data_augmenter
def data_augmenter():'''Create a Sequential model composed of 2 layers数据增强:将若干用于数据增强的层加进列表中,数据增强的层有翻转RandomFlip,旋转RandomRotation,注意它们都是随机的,有概率不进行增强操作,并且默认只会在训练的时候执行,预测时不执行,如果将train=true,则预测时也会执行。RandomFlip:进行水平或垂直翻转RandomRotation:将图片旋转(不是扭曲),旋转的角度取决于旋转因子factor, [-factor*2pi,factor*2pi]Returns:tf.keras.Sequential'''### START CODE HEREdata_augmentation = tf.keras.Sequential()data_augmentation.add(RandomFlip("horizontal"))data_augmentation.add(RandomRotation(0.2))### END CODE HEREreturn data_augmentation
- MobileNetV2:tensorflow自带的图片识别网络,是1个残差网络,如果weights=imagenet,会从网上下载参数,也可以手动下载,再指定文件路径。支持迁移学习
- MobileNetV2实现迁移学习:将include_top=False,不包含最顶层的全连接层,添加自定义的全连接层,比如识别图片中是否有猫的2分类,自定义的全连接层为1个神经元。trainable = False,将其中所有的层冻结,训练时不训练其中的参数,只训练自定义添加的层。手动添加全连接层
mobilenet_h5_file='/Users/chenwenjie/Downloads/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_160.h5'
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,include_top=True,weights=mobilenet_h5_file)
# include_top:是否包含最顶层的全连接层,迁移学习中,通常为False
base_model = tf.keras.applications.MobileNetV2(input_shape=input_shape,include_top=False, # <== Important!!!!weights=mobilenet_h5_file_no_top) # From imageNet
base_model.trainable = False
# validation_data指定交叉验证数据集
history = model2.fit(train_dataset, validation_data=validation_dataset, epochs=initial_epochs)
import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
print(tf.version.VERSION)
import tensorflow.keras.layers as tflfrom tensorflow.keras.preprocessing import image_dataset_from_directory
from tensorflow.keras.layers import RandomFlip, RandomRotation
# from tensorflow.keras.layers.experimental.preprocessing import RandomFlip, RandomRotation
from tensorflow.keras.preprocessing import image
# UNQ_C1
# GRADED FUNCTION: data_augmenter
def data_augmenter():'''Create a Sequential model composed of 2 layers数据增强:将若干用于数据增强的层加进列表中,数据增强的层有翻转RandomFlip,旋转RandomRotation,注意它们都是随机的,有概率不进行增强操作,并且默认只会在训练的时候执行,预测时不执行,如果将train=true,则预测时也会执行。RandomFlip:进行水平或垂直翻转RandomRotation:将图片旋转(不是扭曲),旋转的角度取决于旋转因子factor, [-factor*2pi,factor*2pi]Returns:tf.keras.Sequential'''### START CODE HEREdata_augmentation = tf.keras.Sequential()data_augmentation.add(RandomFlip("horizontal"))data_augmentation.add(RandomRotation(0.2))### END CODE HEREreturn data_augmentation
IMG_SIZE = (160, 160)
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
# UNQ_C2
# GRADED FUNCTION
def alpaca_model(image_shape=IMG_SIZE, data_augmentation=data_augmenter()):''' Define a tf.keras model for binary classification out of the MobileNetV2 modelArguments:image_shape -- Image width and heightdata_augmentation -- data augmentation functionReturns:Returns:tf.keras.model'''input_shape = image_shape + (3,)mobilenet_h5_file_no_top='/Users/chenwenjie/Downloads/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_160_no_top.h5'### START CODE HERE# include_top:是否包含最顶层的全连接层base_model = tf.keras.applications.MobileNetV2(input_shape=input_shape,include_top=False, # <== Important!!!!weights=mobilenet_h5_file_no_top) # From imageNet# Freeze the base model by making it non trainablebase_model.trainable = False# create the input layer (Same as the imageNetv2 input size)inputs = tf.keras.Input(shape=input_shape) # apply data augmentation to the inputsx = data_augmentation(inputs)# data preprocessing using the same weights the model was trained on# Already Done -> preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input# 数据预处理,比如归一化处理,对于mobilenet_v2.preprocess_input,mobilenetV2的预处理,将像素值缩放到-1~1区间x = preprocess_input(x) # set training to False to avoid keeping track of statistics in the batch norm layerx = base_model(x, training=False) # Add the new Binary classification layers# use global avg pooling to summarize the info in each channelx = tfl.GlobalAveragePooling2D()(x) #include dropout with probability of 0.2 to avoid overfittingx = tfl.Dropout(0.2)(x)# create a prediction layer with one neuron (as a classifier only needs one)prediction_layer = tfl.Dense(1)### END CODE HEREoutputs = prediction_layer(x) model = tf.keras.Model(inputs, outputs)return model
- 模型微调:base_model.trainable = True,将所有层设为可训练,再将前n层冻结,也就是训练部分深层的隐藏层
- 断点续训:另一种实现断点续训的方法:通过fit函数的callbacks参数设置回调,在回调函数中保存检查点,第二次训练加载检查点,再继续训练
# 实际训练轮次从initial_epoch+1~epochs,这种方式只影响日志中的轮次记录,不会加载上一次训练的模型参数
history_fine = model2.fit(train_dataset,epochs=total_epochs,initial_epoch=history.epoch[-1],validation_data=validation_dataset)
Dropout失活层
- Dropout: 失活层,用于防止高方差(过拟合),该层会随机将一部分比例p输入的特征值置为0,再将保留的样本值除以1-p。
- 为什么能防止过拟合:因为是随机将任意位置的特征值清0,使网络在训练过程中不过度依赖某些特定位置的特征值
- 为什么要除以1-p:使输入特征值的无论是否dropout,期望保持不变(训练阶段会dropout,测试和预测阶段不会dropout),如果不缩放,会导致训练出来的模型参数在测试阶段预测不准确。每个特征值X相当于随机变量,满足:
P ( X = 0 ) = p , P ( X = x ) = 1 − p 如果不缩放: 期望 E ( X ) = 0 ∗ p + x ∗ ( 1 − p ) = x ( 1 − p ) ≠ x 如果缩放: X = x / ( 1 − p ) , E ( X ) = x P(X=0)=p, ~~ P(X=x)=1-p\\ 如果不缩放: ~~期望E(X)=0*p+x*(1-p)=x(1-p) \neq x \\ 如果缩放:X=x/(1-p),E(X)=x P(X=0)=p, P(X=x)=1−p如果不缩放: 期望E(X)=0∗p+x∗(1−p)=x(1−p)=x如果缩放:X=x/(1−p),E(X)=x
- dropout不管多少维度,即便是输入是多维数组,丢弃都是按照元素来进行的,假设输入的形状是(batch, height, width, channel),会生成1个和输入形状相同的掩码矩阵,用该矩阵乘以输入,再除以1-p
- dropout一般放在全连接层之前,或者残差块之后,不放在残差块里面
- Dropout多用于图片识别,因为通常数据量较少,容易发生过拟合
批归一化(BatchNorm)和层归一化(LayerNorm)
- 作用:加速训练,提高模型性能
- 批归一化(Batch Normalization,BN)分为2步:1、标准化:将当前批次的数据计算均值和方差,再将批次中的样本依次标准化。2、使用参数γ 和 β调整标准化后的值
训练模式: 标准化: x i N = x i − μ σ 2 调整: y i = γ x i N + β 推断模式: μ = m o m e n t u m ∗ μ h i s + ( 1 − m o m e n t u m ) ∗ μ c u r r e n t σ 2 = m o m e n t u m ∗ σ h i s 2 + ( 1 − m o m e n t u m ) ∗ σ c u r r e n t 2 μ c u r r e n t 和 σ c u r r e n t 2 是训练阶段保存的每一个小批次的均值和方差,计算它们的指数平均 训练模式:\\ 标准化:x_{i}^N=\frac{x_i-\mu}{\sigma^2} \\ 调整:y_i=\gamma x_{i}^N+\beta \\ 推断模式:\\ \mu=momentum*\mu_{his}+(1-momentum)*\mu_{current}\\ \sigma^2=momentum*\sigma^2_{his}+(1-momentum)*\sigma^2_{current}\\ \mu_{current}和\sigma^2_{current}是训练阶段保存的每一个小批次的均值和方差,计算它们的指数平均 训练模式:标准化:xiN=σ2xi−μ调整:yi=γxiN+β推断模式:μ=momentum∗μhis+(1−momentum)∗μcurrentσ2=momentum∗σhis2+(1−momentum)∗σcurrent2μcurrent和σcurrent2是训练阶段保存的每一个小批次的均值和方差,计算它们的指数平均
- 标准化的作用是将输入的数据缩放到相同的范围,从而提高梯度下降效率,但是标准化后的数据缩放到了均值为0,方差为1的分布,损失了数据的原来的分布特性,所以需要参数γ 和 β在标准化的基础上进一步缩放,γ 和 β初始值一般为1和0,并且和权重、偏置值一样会随着反向传播调整,这样一开始训练时特征值的分布较为同一,训练效率高,后续自适应调整到最适合的分布。比如一开始x~N(5,3), 标准化后N(0,1), 最终调整到N(1,5)
- 训练模式和推断模式批归一化的不同:计算均值和方差的计算方法不同,后者使用前者的指数加权平均
- 指数加权平均:超参数β,约等于最近若干个数的均值(实现滑动窗口的一种方法)。相比于直接求均值,计算占用内存更少,也就是说训练时不会保存每次计算的均值和方差,而是计算指数加权平均,只需要保存2个值
v n = β v n − 1 + ( 1 − β ) θ n ≈ θ n , θ n − 1 . . . 最近 1 1 − β 个数的平均值 v_n=\beta v_{n-1}+(1-\beta)\theta_n \approx \theta_n,\theta_{n-1}...最近\frac{1}{1-\beta} 个数的平均值 vn=βvn−1+(1−β)θn≈θn,θn−1...最近1−β1个数的平均值
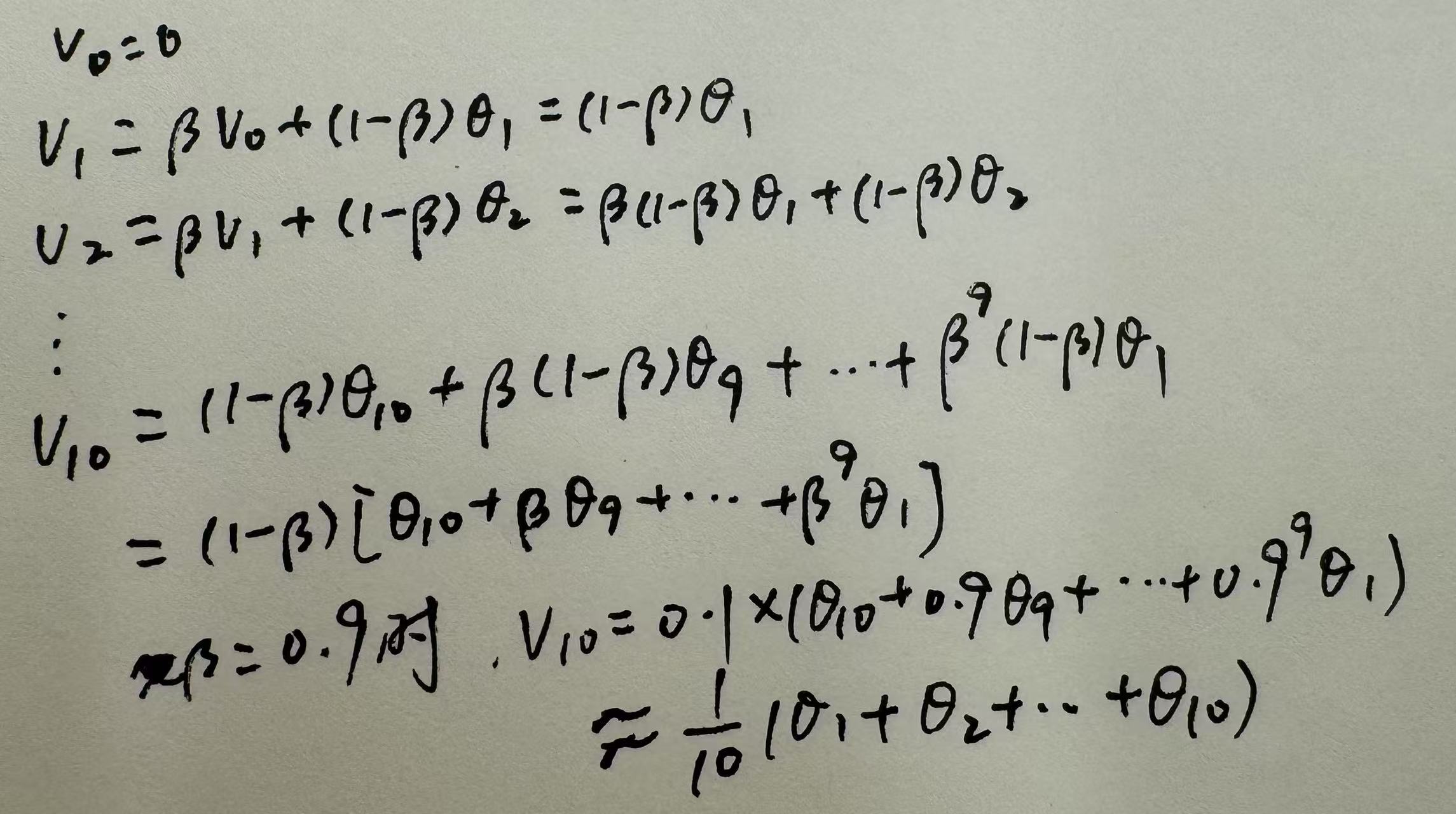
- 批归一化的维度:沿着指定维度的轴进行归一化,比如对于输入形状(batch,height,width,channel),通常沿着通道归一化,也就是不同通道的数据单独计算均值和方差,输出维度不变,只是分布改变
- 批归一化一般放在卷积层之后:卷积层输出容易发送偏移,导致后续层在训练过程中不断调整来适应前面层的输出变化,加入BN后,卷积层的输出更稳定;激活函数之前:卷积层输出可能很多负数,导致relu激活值为0,梯度消失,加入批归一化后调整为正
X = Conv2D(filters = F1, kernel_size = 1, strides = (s, s), padding='valid', kernel_initializer = initializer(seed=0))(X)
X = BatchNormalization(axis=3)(X, training=training) #training用于指定训练模式还是推断模式
X = Activation('relu')(X)
- 层归一化(LayerNorm):和批归一化的区别:批归一化训练阶段对小批次的所有样本进行归一化,而层归一化对单个样本的所有特征值进行归一化。批归一化适合小批次样本较多的场景,比如图像处理,层归一化适合小批次样本较少的场景,比如自然语言处理NLP,输入序列的词语数相比于图像的像素要少很多
梯度下降
- 梯度下降包括前向传播、反向传播、参数更新
- 前向传播:样本值从输入层开始,经过隐藏层,到输出层,得到预测值和代价函数值
- 反向传播:从输出的预测值开始,使用链式法则,从后往前计算代价函数对每一层参数的偏导数值。因为代价函数是预测值的函数,代价函数对预测值的导数也是对预测值和真实值的函数,所以该导数可以带入预测值和真实值求出
- 单样本,单层网络,逻辑回归的反向传播:其中的a对z的导数,可以转换成对a的函数
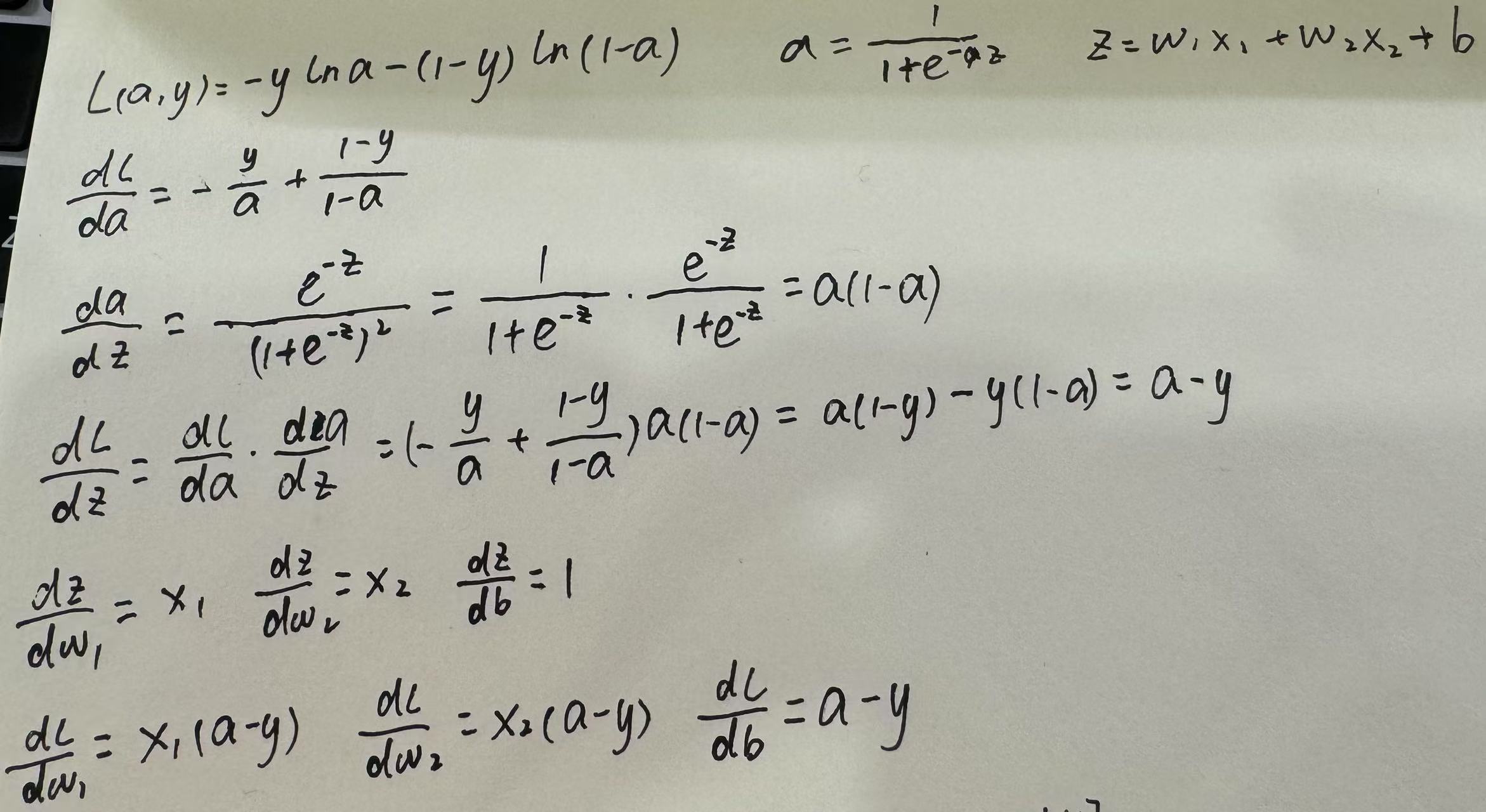
- 单样本,多层网络的反向传播:根据链式法则计算,其中da根据深层网络得到
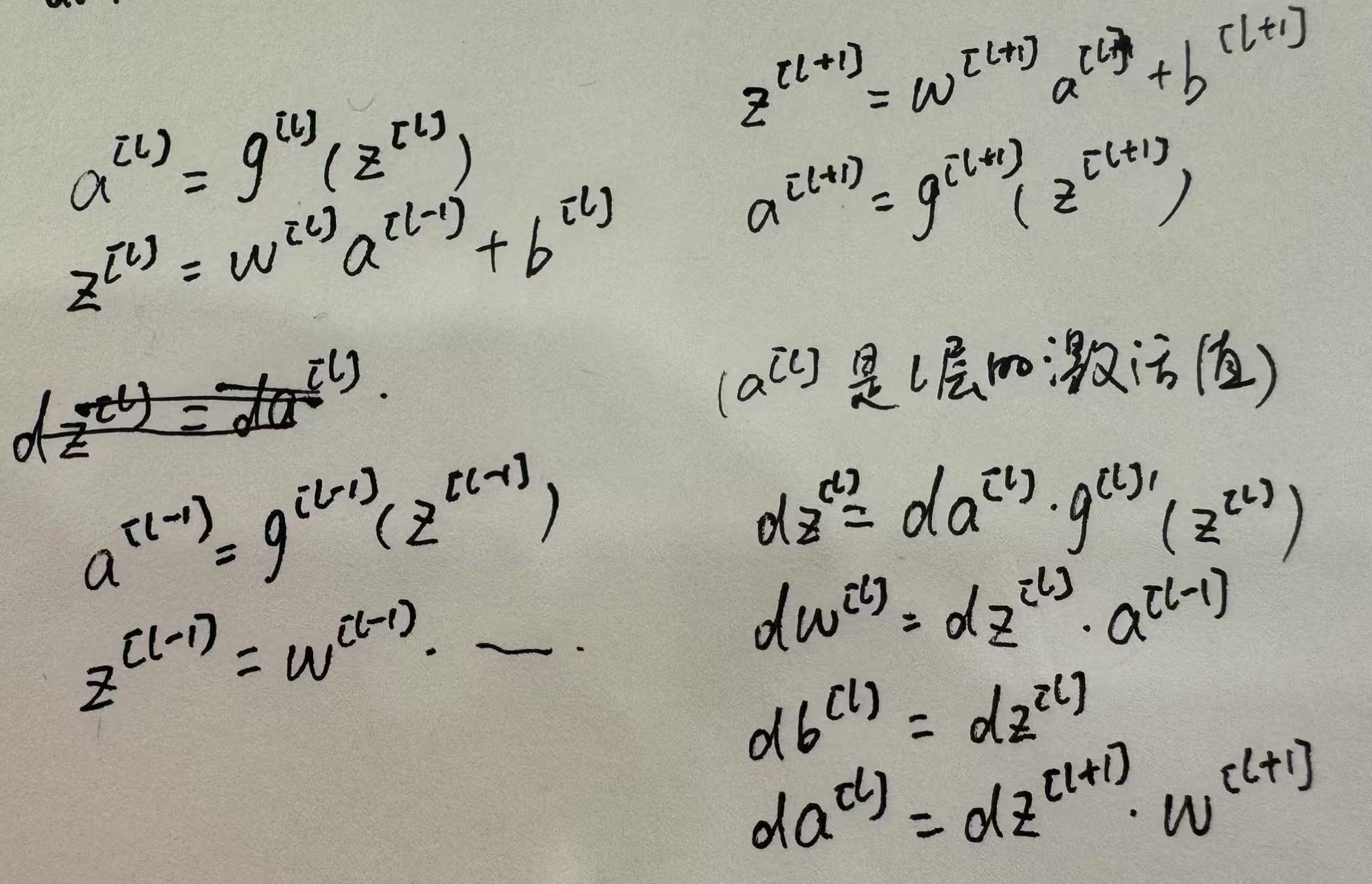
- 多样本反向传播:多样本输出多个预测值,代价函数值等于这些预测值、真实值对应的损失函数值的均值,代价函数对每层参数的导数,等于单样本导数的均值,从而复用单样本的计算方式
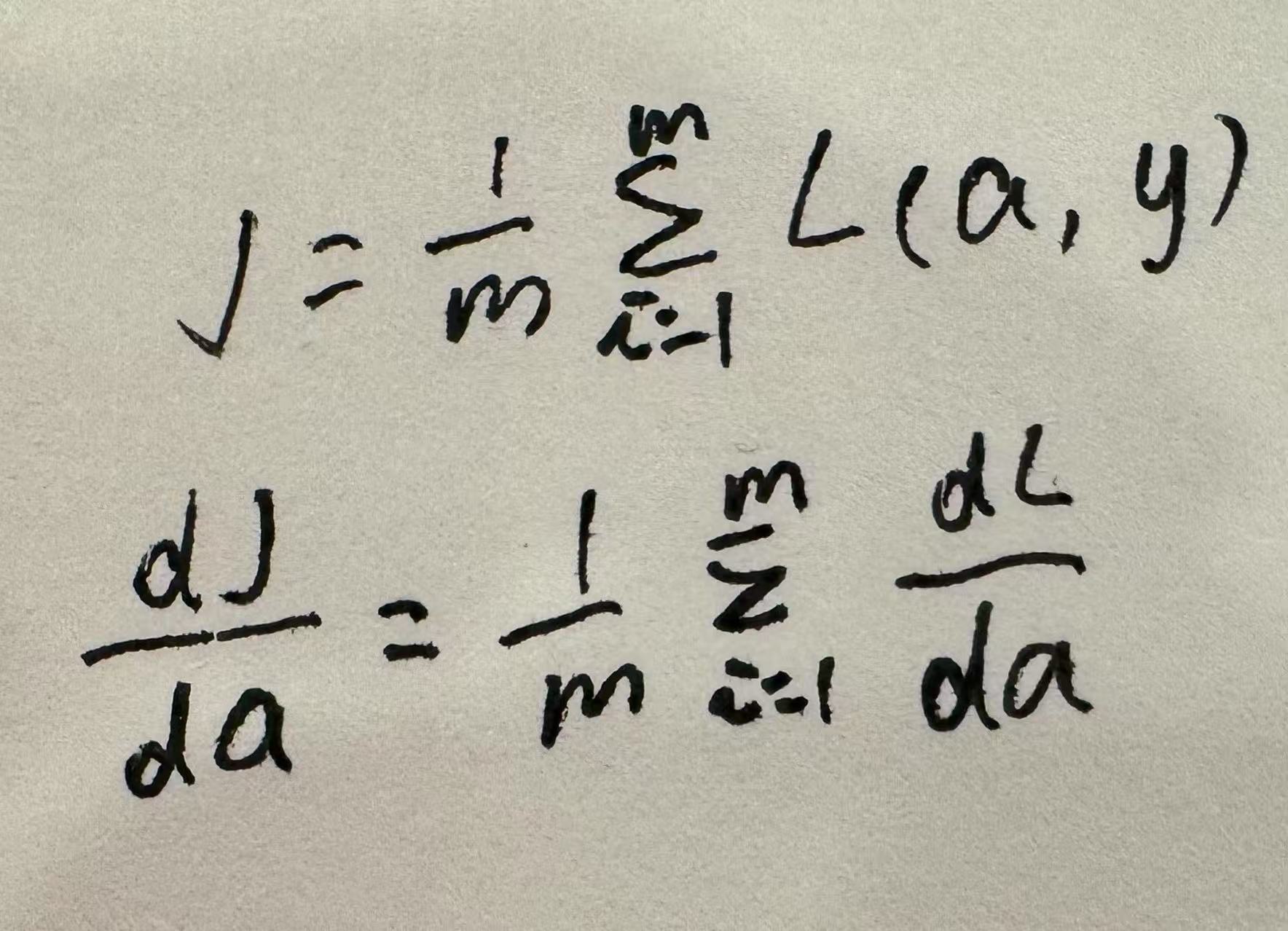
- mini-batch梯度下降:batch梯度下降需要一次性计算整个数据集导数的均值,效率低,mini-batch利用了向量化运算提高效率,将数据集分成多个小批次,对整个数据集一共迭代epoch次,每个epoch梯度下降每个小批次一次,每次计算**一次**前向传播、反向传播和参数更新。
# X_train shape: (1080, 64, 64, 3)
# Epoch 1/10
# 34/34 ━━━━━━━━━━━━━━━━━━━━ 104s 2s/step - accuracy: 0.3050 - loss: 2.9573
# Epoch 2/10
# 34/34 ━━━━━━━━━━━━━━━━━━━━ 40s 1s/step - accuracy: 0.6972 - loss: 0.8145
# 整个数据集一共1080个样本,mini-batch大小32,对整个数据集一共迭代10次,每次梯度下降每个小批次一次,所以每个epoch有1080/32=33.75~34次梯度下降(前向传播、反向传播和参数更新)。step就是梯度下降
model.fit(X_train, Y_train, epochs = 10, batch_size = 32)
- 动量梯度下降:参数更新时,不使用本次反向传播计算出来的梯度,而是使用梯度的指数加权平均值,有超参数β1。
- 动量梯度下降好处:梯度是一个向量,指向函数值减小最快的方向(向量γ),mini-batch梯度下降,因为数据不完整,计算出来的梯度有误差,从而导致梯度在垂直于γ的方向有分量,使用梯度的均值,能够将垂直于γ的方向的分量抵消,而γ方向的分量能够累加,从而提高梯度下降的效率
- RMSProp(Root Mean Square Propagation)优化算法:也是用来加快梯度下降,相当于修改了不同参数的学习率,让梯度大的使用小的学习率,梯度小的使用大的学习率,用来消除不同参数梯度变化不均衡的问题
d w , d b 是一个 m i n i − b a t c h 的梯度 S d w = β 2 S d w + ( 1 − β 2 ) ( d w ) 2 w = w − α d w S d w 超参数: β 2 平方会让大的梯度值更大,小的梯度值更小,除以 S d w 后,大的梯度变的更小,小于 1 的梯度更大 dw,db是一个mini-batch的梯度\\ S_{dw}=\beta_2S_{dw}+(1-\beta_2)(dw)^2 \\ w=w-\alpha \frac{dw}{\sqrt{S_{dw}}} \\ 超参数:\beta_2 \\ 平方会让大的梯度值更大,小的梯度值更小,除以\sqrt{S_{dw}}后,大的梯度变的更小,小于1的梯度更大\\ dw,db是一个mini−batch的梯度Sdw=β2Sdw+(1−β2)(dw)2w=w−αSdwdw超参数:β2平方会让大的梯度值更大,小的梯度值更小,除以Sdw后,大的梯度变的更小,小于1的梯度更大
- Adam算法:融合了动量梯度下降和RMSProp
V d w 是梯度的指数加权平均, S d w 是 R M S p r o p 得到的 w = w − α V d w S d w V_{dw}是梯度的指数加权平均,S_{dw}是RMSprop得到的 \\ w=w-\alpha \frac{V_{dw}}{\sqrt{S_{dw}}} \\ Vdw是梯度的指数加权平均,Sdw是RMSprop得到的w=w−αSdwVdw
目标检测
- 功能:识别图片中不同类别的目标物体,获取它们在图片中的位置坐标
- yolo(you only look once)神经网络:是一个卷积神经网络,输入(w,h,c)的图片,输出(n,n,anchor,pc,bx,by,bw,bh,c),n是将图片分成的格子数,anchor是锚框数,pc是格子是否包含目标物体中心点的概率值,bx,by,bw,bh是物体的中心点坐标和宽高,c是识别到的物体的类别的概率,r维向量
- 锚框:1、用来检测重叠的物体,当1个格子包含多个物体中心点时,(n,n)中需要保存多个物体中心点。2、可以加快收敛,锚框大致定位物体位置,bx,by,bw,bh再详细定位
- yolo算法:
- 得到预测值后,pc*c_i求每个格子,每个锚框的,每种类别的分值
- 获取每个格子,每个锚框中最大分值的类别
- 根据阈值过滤,去除分值低于阈值的锚框,满足条件的锚框的分值、左上右下xy坐标、类别
- 使用非极大值抑制算法:一共执行max_boxes轮,每轮获取分值最大的锚框a,去除与a的iou值大于iou阈值的锚框
# GRADED FUNCTION: yolo_filter_boxesdef yolo_filter_boxes(box_confidence, boxes, box_class_probs, threshold = .6):"""Filters YOLO boxes by thresholding on object and class confidence.使用yolo算法处理神经网络预测值,是1个19*19的85维向量。1、pc*c_i求每个格子,每个锚框的,每种类别的分值2、获取每个格子,每个锚框中最大分值的类别3、根据阈值过滤,去除分值低于阈值的锚框,返回满足条件的锚框的分值、左上右下xy坐标、类别Arguments:box_confidence -- tensor of shape (19, 19, 5, 1)boxes -- tensor of shape (19, 19, 5, 4)box_class_probs -- tensor of shape (19, 19, 5, 80)threshold -- real value, if [ highest class probability score < threshold], then get rid of the corresponding boxReturns:scores -- tensor of shape (None,), containing the class probability score for selected boxesboxes -- tensor of shape (None, 4), 左上右下y,x坐标classes -- tensor of shape (None,), containing the index of the class detected by the selected boxesNote: "None" is here because you don't know the exact number of selected boxes, as it depends on the threshold. For example, the actual output size of scores would be (10,) if there are 10 boxes."""# Step 1: Compute box scores### START CODE HERE ### (≈ 1 line)# box_scores是(19, 19, 5, 80)box_scores = box_confidence * box_class_probs### END CODE HERE #### Step 2: Find the box_classes using the max box_scores, keep track of the corresponding score### START CODE HERE ### (≈ 2 lines)# (19,19,5,1)box_classes = K.argmax(box_scores, axis = -1)# (19,19,5)box_class_scores = K.max(box_scores, axis = -1, keepdims=False)### END CODE HERE #### Step 3: Create a filtering mask based on "box_class_scores" by using "threshold". The mask should have the# same dimension as box_class_scores, and be True for the boxes you want to keep (with probability >= threshold)### START CODE HERE ### (≈ 1 line)# (19,19,5),小于threshold的格子,认为不包含任何类别的物体的中心点filtering_mask = (box_class_scores >= threshold)### END CODE HERE #### Step 4: Apply the mask to box_class_scores, boxes and box_classes### START CODE HERE ### (≈ 3 lines)# scores是1D的,(None,),None表示filtering_mask中True的个数,取包含物体中线点的格子的分值,掩码数组和目标数组维度相同时,boolean_mask返回1Dscores = tf.boolean_mask(box_class_scores, filtering_mask)#boxes是(19, 19, 5, 4),filtering_mask是(19,19,5),所以返回的boxes是2D的,(None,4),包含物体中线点的格子的左上角和右下角y,x坐标boxes = tf.boolean_mask(boxes, filtering_mask)# box_classes是(19,19,5,1),filtering_mask是(19,19,5),classes是(None,1),包含中心点的格子的类别索引classes = tf.boolean_mask(box_classes, filtering_mask)### END CODE HERE ###return scores, boxes, classes
- 分值计算为什么相乘,而不先判断pc>0.5再取c_i最大值:pcc_i的联合概率值更好,如果pc=0.49,c_i=0,9,那么即使pcc_i很大,仍不会选中
- IOU(Interception over Union,交并比):用来判断2个锚框是否过于重叠,IOU=2个锚框的交集面积/并集面积
人脸识别
- 人脸检测(face verify):根据人脸照片和ID,判断是否对应
- 人脸识别(face recognition):根据人脸照片,判断人是否在数据库中,并返回ID,需要n次人脸检测
- 三元损失函数:人脸识别的神经网络输入人脸照片,输出一个编码值,是128维向量,同一个人脸照片的编码值的欧式距离较近,不同人较远。三元损失函数输入3张图片(A,P,N)的编码值,A和P是同1个人,N不同的人,A和P的距离应该小于A和N的距离,损失函数=max(A和P的距离-A和N的距离+alpha,0),当A和P的距离小于A和N的距离时,损失函数为0,否则大于0,最小化损失函数时,就会使A和P的距离小于A和N的距离
# GRADED FUNCTION: triplet_lossdef triplet_loss(y_true, y_pred, alpha = 0.2):"""Implementation of the triplet loss as defined by formula (3)Arguments:y_true -- true labels, required when you define a loss in Keras, you don't need it in this function.y_pred -- python list containing three objects:anchor -- the encodings for the anchor images, of shape (None, 128)positive -- the encodings for the positive images, of shape (None, 128)negative -- the encodings for the negative images, of shape (None, 128)Returns:loss -- real number, value of the loss"""anchor, positive, negative = y_pred[0], y_pred[1], y_pred[2]# YOUR CODE STARTS HERE (≈ 4 lines)# Step 1: Compute the (encoding) distance between the anchor and the positive# anchor和positive是m张图片的编码预测值,shape=(m,128)
# tf.square(tf.subtract(anchor,positive)是(m,128),是m对图片的编码差值的平方# pos_list的shape=(m,),是m对图片编码差值的平方和pos_dist = tf.reduce_sum(tf.square(tf.subtract(anchor,positive)),axis=-1)# Step 2: Compute the (encoding) distance between the anchor and the negativeneg_dist = tf.reduce_sum(tf.square(tf.subtract(anchor,negative)),axis=-1)# Step 3: subtract the two previous distances and add alpha.
# basic_loss是(m,),是m对AP和m对AN的距离+alpha,与0的最大值,求最大值是为了使小于0的结果都等于0,
# 如果不将负数改为0,会导致求和后,为负数的3元样本影响到总体的损失函数值basic_loss = tf.maximum(tf.add(tf.subtract(pos_dist,neg_dist),alpha),0)# Step 4: Take the maximum of basic_loss and 0.0. Sum over the training examples.loss = tf.reduce_sum(basic_loss)# YOUR CODE ENDS HEREreturn loss
# GRADED FUNCTION: verifydef verify(image_path, identity, database, model):"""Function that verifies if the person on the "image_path" image is "identity".Arguments:image_path -- path to an imageidentity -- string, name of the person you'd like to verify the identity. Has to be an employee who works in the office.database -- python dictionary mapping names of allowed people's names (strings) to their encodings (vectors).model -- your Inception model instance in KerasReturns:dist -- distance between the image_path and the image of "identity" in the database.door_open -- True, if the door should open. False otherwise."""# YOUR CODE STARTS HERE#Step 1: Compute the encoding for the image. Use img_to_encoding() see example above. (≈ 1 line)encoding = img_to_encoding(image_path,model)# Step 2: Compute distance with identity's image (≈ 1 line)dist = np.linalg.norm(encoding - database[identity])# Step 3: Open the door if dist < 0.7, else don't open (≈ 3 lines)if dist < 0.7:print("It's " + str(identity) + ", welcome in!")door_open = Trueelse:print("It's not " + str(identity) + ", please go away")door_open = False# YOUR CODE ENDS HEREreturn dist, door_open
# GRADED FUNCTION: who_is_itdef who_is_it(image_path, database, model):"""Implements face recognition for the office by finding who is the person on the image_path image.Arguments:image_path -- path to an imagedatabase -- database containing image encodings along with the name of the person on the imagemodel -- your Inception model instance in KerasReturns:min_dist -- the minimum distance between image_path encoding and the encodings from the databaseidentity -- string, the name prediction for the person on image_path"""# YOUR CODE STARTS HERE## Step 1: Compute the target "encoding" for the image. Use img_to_encoding() see example above. ## (≈ 1 line)encoding = img_to_encoding(image_path,model)## Step 2: Find the closest encoding ### Initialize "min_dist" to a large value, say 100 (≈1 line)min_dist = 100#Loop over the database dictionary's names and encodings.for (name, db_enc) in database.items():# Compute L2 distance between the target "encoding" and the current db_enc from the database. (≈ 1 line)dist = np.linalg.norm(encoding - db_enc)# If this distance is less than the min_dist, then set min_dist to dist, and identity to name. (≈ 3 lines)if dist < min_dist:min_dist = distidentity = name# YOUR CODE ENDS HEREif min_dist > 0.7:print("Not in the database.")else:print ("it's " + str(identity) + ", the distance is " + str(min_dist))return min_dist, identity
序列模型
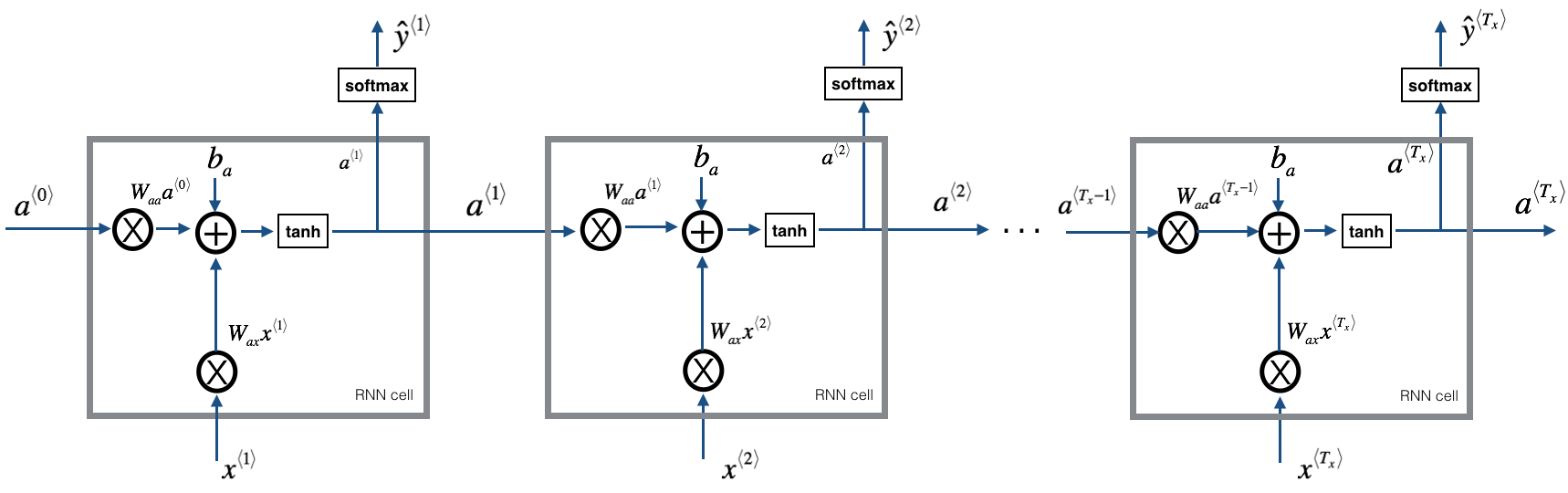
- 循环神经网络(RNN, Recurrent Neural Network):卷积网络的输入和输出长度固定,而RNN可以处理变长的输入和输出。循环使用t次相同参数的神经元层,从而输入和输出的特征向量可以任意长度
a < t > = t a n h ( W a a a t − 1 + W a x x < t > + b a ) y ˜ < t > = s o f t m a x ( W y a a < t > + b a ) 其中 x < t > 是 t 时刻的输入, a < t > 是隐藏状态, W 和 b 是参数,每一轮参数相同,输入、隐藏状态、输出不同 a^{<t>}=tanh(W_{aa}a^{t-1}+W_{ax}x^{<t>}+b_a) \\ \~y^{<t>}=softmax(W_{ya}a^{<t>}+b_a) \\ 其中x^{<t>}是t时刻的输入,a^{<t>}是隐藏状态,W和b是参数,每一轮参数相同,输入、隐藏状态、输出不同 a<t>=tanh(Waaat−1+Waxx<t>+ba)y˜<t>=softmax(Wyaa<t>+ba)其中x<t>是t时刻的输入,a<t>是隐藏状态,W和b是参数,每一轮参数相同,输入、隐藏状态、输出不同
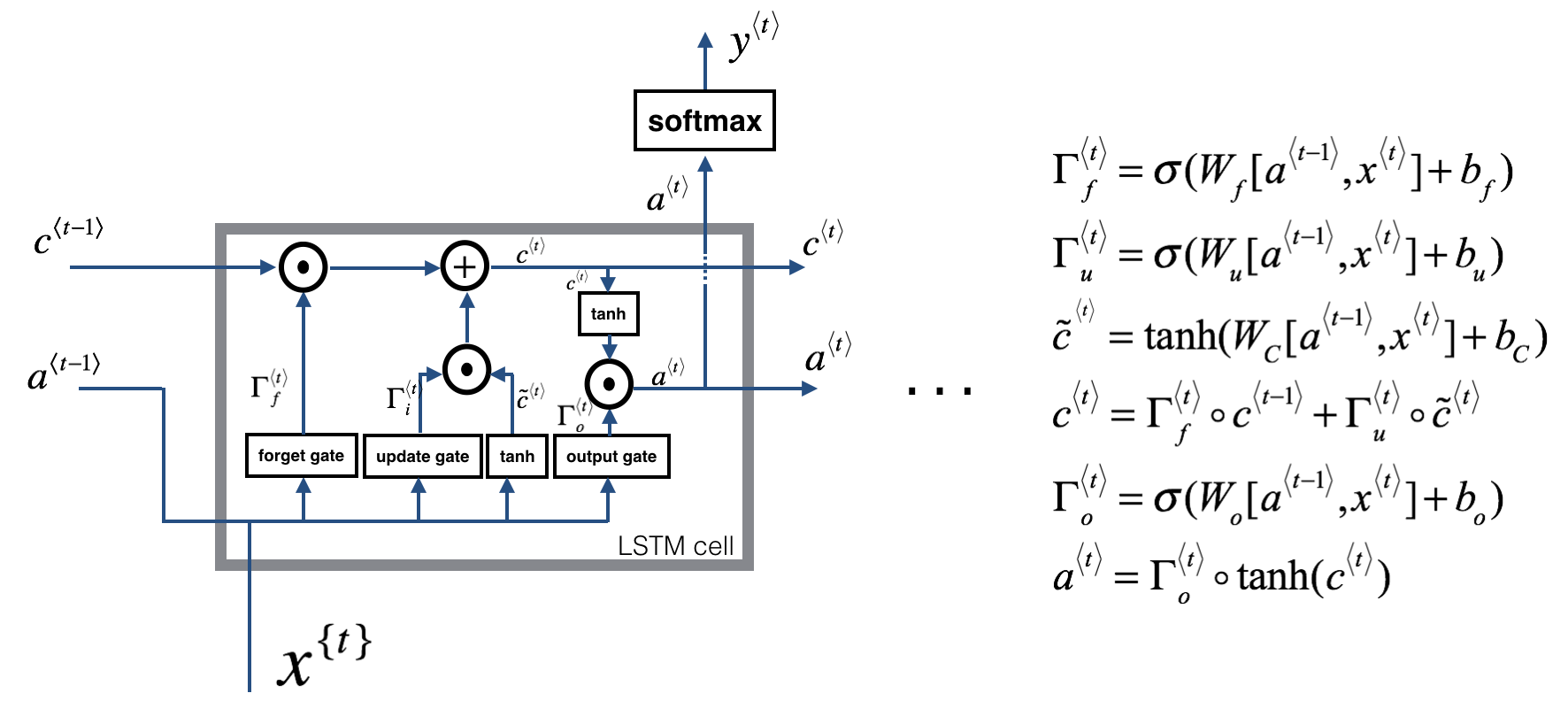
- LSTM(长短期记忆,Long Short Time Memory):用于解决序列过长导致的梯度消失\爆炸问题,在RNN的基础上增加了1个细胞状态和3个门
c ˜ < t > = t a n h ( W c [ a < t − 1 > , x < t > + b c ] ) Γ u = σ ( W u [ a < t − 1 > , x t ] + b u ) Γ f = σ ( W f [ a < t − 1 > , x t ] + b f ) Γ o = σ ( W o [ a < t − 1 > , x t ] + b o ) c < t > = Γ u ∗ c ˜ < t > + Γ f ∗ c < t − 1 > a t = Γ o ∗ tanh c < t > σ 是 S 型函数,所以 3 个门控向量的值在 ( 0 , 1 ) 之间,门控向量和状态逐元素相乘,从而实现选择性遗忘 Γ u 是更新门,它越接近 1 时,表示更新越多的新状态 Γ f 遗忘门,越接近 1 保留越多的旧状态 Γ o 输出门 \~c^{<t>}=tanh(W_{c}[a^{<t-1>},x^{<t>}+b_c]) \\ \Gamma_u=\sigma(W_u[a^{<t-1>,x^{t}}]+b_u) \\ \Gamma_f=\sigma(W_f[a^{<t-1>,x^{t}}]+b_f) \\ \Gamma_o=\sigma(W_o[a^{<t-1>,x^{t}}]+b_o) \\ c^{<t>}=\Gamma_u*\~c^{<t>}+\Gamma_f*c^{<t-1>} \\ a^{t}=\Gamma_o*\tanh c^{<t>} \\ \sigma是S型函数,所以3个门控向量的值在(0,1)之间,门控向量和状态逐元素相乘,从而实现选择性遗忘 \\ \Gamma_u是更新门,它越接近1时,表示更新越多的新状态 \\ \Gamma_f遗忘门,越接近1保留越多的旧状态 \\ \Gamma_o输出门 \\ c˜<t>=tanh(Wc[a<t−1>,x<t>+bc])Γu=σ(Wu[a<t−1>,xt]+bu)Γf=σ(Wf[a<t−1>,xt]+bf)Γo=σ(Wo[a<t−1>,xt]+bo)c<t>=Γu∗c˜<t>+Γf∗c<t−1>at=Γo∗tanhc<t>σ是S型函数,所以3个门控向量的值在(0,1)之间,门控向量和状态逐元素相乘,从而实现选择性遗忘Γu是更新门,它越接近1时,表示更新越多的新状态Γf遗忘门,越接近1保留越多的旧状态Γo输出门
- 序列生成模型:比如文本生成模型,通过前面的文本来预测后续文本出现的概率,通过概率随机抽样,来实现文本生成。训练:输入是合法的文本,输出是和输出相同的左移1个词的合法的文本。预测:初始输入可以为任意值,输出为每个可能的词出现的概率,通过概率随机抽样(不是选择概率最大的),后续的输入为上一次的输出值
词嵌入
- 词嵌入(词向量,emmbeding):类似于人脸识别中将照片转成1个编码值,词嵌入将词语转成1个300维左右的向量
- 余弦相似度函数:词向量的夹角可以用来表示是否同类词语,夹角接近0表示是相类似的词语,90度表示不相似,180度表示相反,0度和180度表示相关性较强,90度表示不相关
c o s _ s i m i l a r i t y = u ⋅ v ∣ u ∣ ∗ ∣ v ∣ = c o s θ 余弦相似度 = 夹角余弦值 = 向量内积除以模长乘积 cos\_similarity=\frac{u \cdot v}{|u|*|v|}=cos \theta \\ 余弦相似度=夹角余弦值=向量内积除以模长乘积 cos_similarity=∣u∣∗∣v∣u⋅v=cosθ余弦相似度=夹角余弦值=向量内积除以模长乘积
- word2vec:用于训练词向量的模型,分为2种架构:skip-gram和CBOW
- skip-gram
- 从大量的自然语言的句子中选择中心词语和上下文词语,先选择中心词语,再从中心词语的正负n个词距选择上下文词语,使用神经网络根据中心词预测上下文词,
- 神经网络结构:假设词汇表长度为D,词向量长度为V,输入层(长度为D中心词的one-hot向量)->隐藏层(参数为DV的中心词的词向量矩阵,输出1V的中心词的词向量)->输出层(全连接+softmax,全连接为V*D的上下文词的词向量矩阵)
o u t p u t = e θ c e t ∑ j = 1 m e e t θ j t 是中心词, c 是上下文词, θ c 是中心词的词向量, e t 是上下文词的词向量 output=\frac{e^{\theta_ce_t}}{\sum_{j=1}^{m}e^{e_t\theta_{j}}} \\ t是中心词,c是上下文词,\theta_c是中心词的词向量,e_t是上下文词的词向量 output=∑j=1meetθjeθcett是中心词,c是上下文词,θc是中心词的词向量,et是上下文词的词向量
- 同1个词对应2个词向量,作为中心词和上下文词的词向量不同,训练时中心词和上下文词的词向量矩阵是训练参数
- softmax的问题:词汇表一般很大,每1轮训练分母需要计算所有词汇内积之和,计算量过大。解决方法:负采样
- 负采样:每1轮训练只取1个正例和少数几个负例,正例是中心词和上下文词,负例是中心词和非上下文词,从而将softmax转成2分类问题。每1轮负例根据词频的3/4的概率随机采样
- Glov
机器翻译
- 编码器-解码器模型:编码器和解码器模型是2个RNN网络连接而成,编码器是多对1的RNN,输入是翻译原文序列,输出1个隐藏状态向量,解码器是1对多的RNN,输入是编码器的输出,输出是译文序列。解码器RNN文本生成模型类似,不同点:1、输入不是0向量,而是从编码器的输入开始执行下一步预测。2、输出序列不使用随机采样,而是选择概率最大的序列模型
max y P ( y ^ < 1 > , y ^ < 2 > . . . y ^ < T y > ∣ x ) = P ( y ^ < 1 > ∣ x ) ⋅ P ( y ^ < 2 > ∣ x , y ^ < 1 > ) ⋅ ⋅ ⋅ P ( y ^ < T y > ∣ x , y ^ < 1 > . . . y ^ < T y − 1 > ) 所有可能的序列中,选择使上述条件概率最大的序列 \max_y P(\hat{y}^{<1>},\hat{y}^{<2>}...\hat{y}^{<T_y>}|x)=P(\hat{y}^{<1>}|x) \cdot P(\hat{y}^{<2>}|x,\hat{y}^{<1>}) \cdot \cdot \cdot P(\hat{y}^{<T_y>}|x,\hat{y}^{<1>}...\hat{y}^{<T_y-1>}) \\ 所有可能的序列中,选择使上述条件概率最大的序列 ymaxP(y^<1>,y^<2>...y^<Ty>∣x)=P(y^<1>∣x)⋅P(y^<2>∣x,y^<1>)⋅⋅⋅P(y^<Ty>∣x,y^<1>...y^<Ty−1>)所有可能的序列中,选择使上述条件概率最大的序列
- 为什么不能选择每一个时间步条件概率最大的序列(贪心算法):如果每个时间步彼此独立,可以这么干,但每个时间步的选择会影响后续时间步的选择,局部最优不等于全局最优。比如时间步[a1,b1]的概率分别为[0.9,0.1],时间步[a2,b2]的概率分别为[0.5,0.6],如果优先选择下一步概率最大的,P(a1)*P(b1)=0.09,而没有选到概率更大的P(a2)*P(b2)=0.3
- Beam-search(集束搜索):贪心算法和全局最优的折中,超参数:束宽k,首先第一个时间步选择前k个最大的概率的词语,作为候选词语,假设词汇表长度为V,从k个候选的所有下一步(k*V个)中再选择前k个最大联合概率的词语,依次类推。当k=1时,为贪心算法,当k=V时,为全局最优。k越大,结果越准确,计算复杂度越高
- 长度归一化:1、联合概率是乘积,多个概率连乘可能会导致数值下溢,最后结果为0,取对数值,将连乘转为连加,对数函数是单增的,取对数后仍可以通过取最大值来获取概率最大值的序列。2、取对数后,函数是多个负数连加,会导致长序列的值更小,算法倾向于寻找短序列,解决方法:对时间步取均值
原概率公式: max y ∏ t = 1 T y P ( y ^ < t > ∣ x , y ^ < 1 > . . . y ^ < t − 1 > ) 归一化后: 1 T y α max y ∑ t = 1 T y log P ( y ^ < t > ∣ x , y ^ < 1 > . . . y ^ < t − 1 > ) ( α 取 0 到 1 之间的数,比如 0.7 ) 原概率公式:\max_{y}\prod_{t=1}^{T_y}P(\hat{y}^{<t>}|x,\hat{y}^{<1>}...\hat{y}^{<t-1>}) \\ 归一化后:\frac{1}{T_y^{\alpha}} \max_{y}\sum_{t=1}^{T_y}\log P(\hat{y}^{<t>}|x,\hat{y}^{<1>}...\hat{y}^{<t-1>}) ~~~ (\alpha取0到1之间的数,比如0.7) \\ 原概率公式:ymaxt=1∏TyP(y^<t>∣x,y^<1>...y^<t−1>)归一化后:Tyα1ymaxt=1∑TylogP(y^<t>∣x,y^<1>...y^<t−1>) (α取0到1之间的数,比如0.7)
- 定向搜索的误差分析:训练完成后,进行预测翻译时,将错误的译文的序列概率值求出来P1,参考译文的序列概率值为P2,如果P1>P2,说明是RNN的问题,可以通过增加训练数据、改进网络结构解决;如果P1<P2,说明是搜索算法的问题,可以通过增大束宽解决
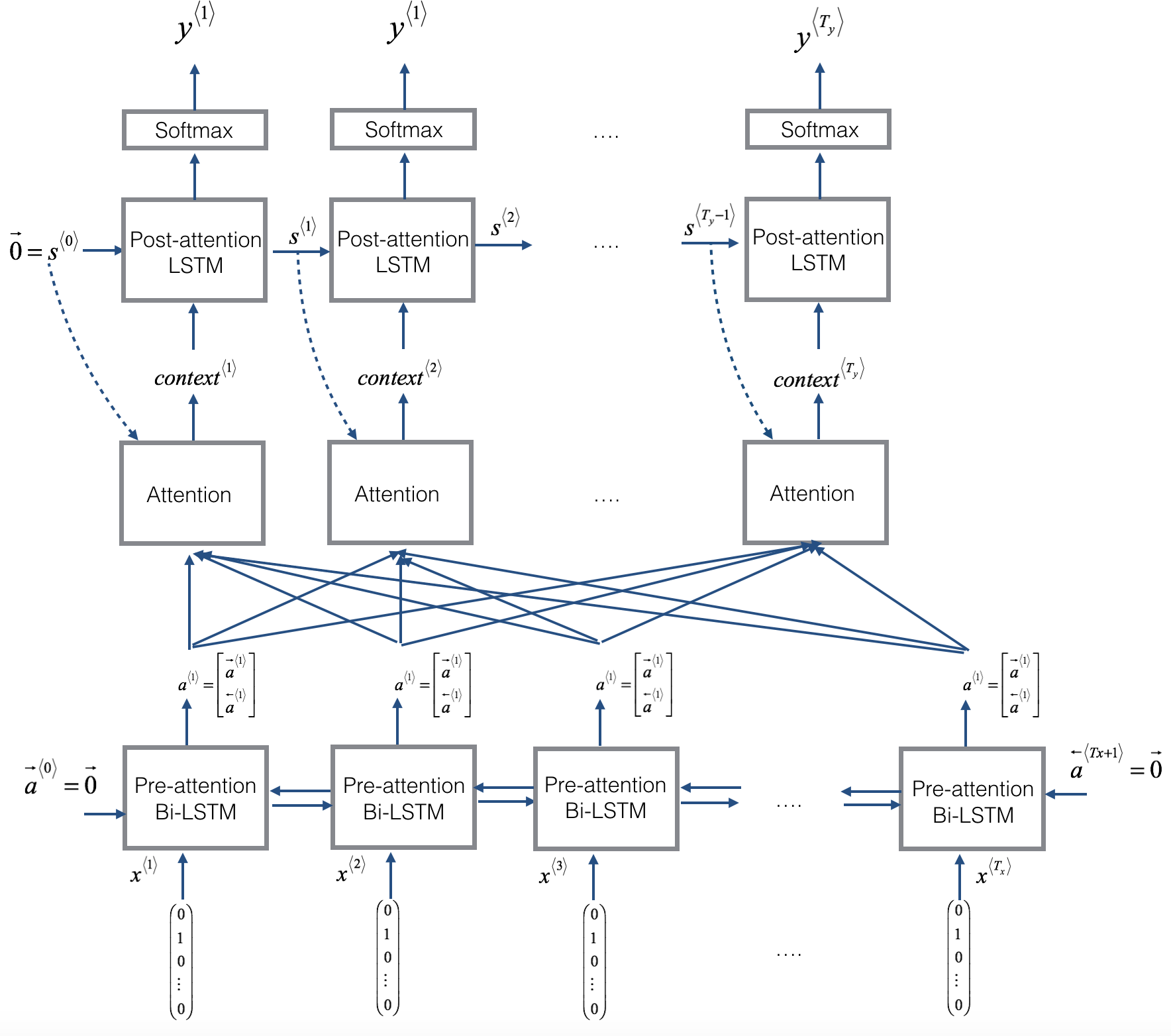
- 注意力模型:机器翻译中,如果输入序列过长,编码器输出的状态向量不能很好的代表输入序列的信息,而很多序列模型在输出某个时间步时,并不需要先将整个输入序列都记住再输出。
- 注意力模型网络由多个网络连接而成,双向LSTM+注意力权重计算网络+单向LSTM
- 将输入序列输入双向LSTM,得到每一步的隐藏状态,因为是双向LSTM,每一步隐藏状态矩阵由2个隐藏状态向量合并得到
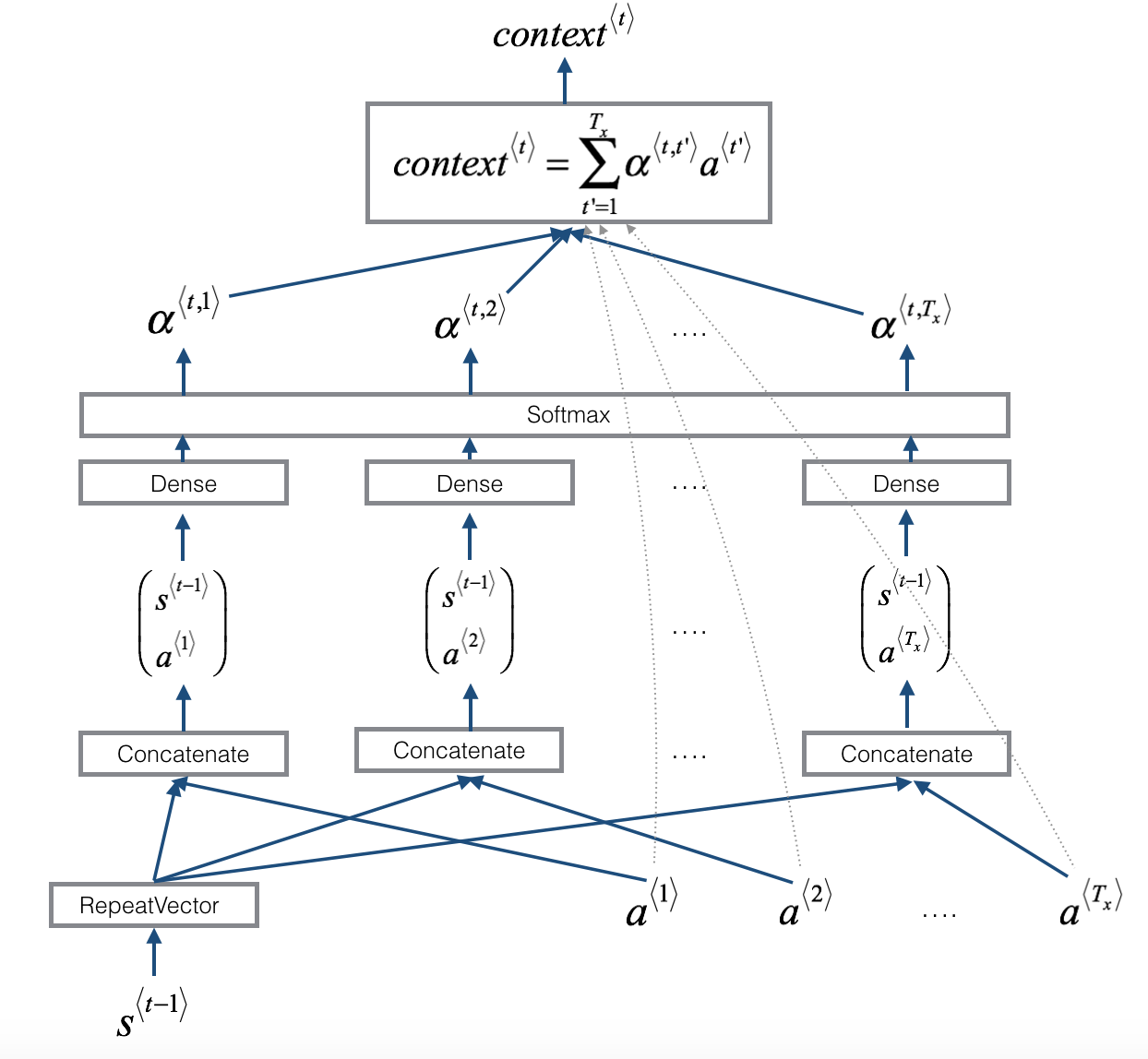
- 将隐藏状态矩阵和单向LSTM的前一步状态矩阵合并成1个大矩阵,输入注意力权重网络,得到注意力权重,注意力权重由softmax层得到,所以每个权重值0~1,总和为1
- 权重alpha的维度是(batch, Tx, 1),隐藏状态矩阵a维度是(batch, Tx, 2n_a),将alpha和a在axis=1的维度求向量点积(对应元素相乘,再求和),得到上下文矩阵(batch, 1, 2n_a)。a的每个时间步对应1个权重值,乘以对应权重值,再求和。
- 将上下文矩阵输入单向LSTM,得到单步输出
# UNQ_C1 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)
# GRADED FUNCTION: one_step_attentiondef one_step_attention(a, s_prev):"""Performs one step of attention: Outputs a context vector computed as a dot product of the attention weights"alphas" and the hidden states "a" of the Bi-LSTM.Arguments:a -- hidden state output of the Bi-LSTM, numpy-array of shape (m, Tx, 2*n_a),双向RRU的输出隐藏状态,一共有Tx步,因为是双向的,每一步输出2个状态向量,所以是2*n_a,n_a是每一步的隐藏状态的维度数s_prev -- previous hidden state of the (post-attention) LSTM, numpy-array of shape (m, n_s),s是用来计算y^hat的隐藏状态,s_prev是上一步计算y^hat的隐藏状态Returns:context -- context vector, input of the next (post-attention) LSTM cell"""### START CODE HERE #### Use repeator to repeat s_prev to be of shape (m, Tx, n_s) so that you can concatenate it with all hidden states "a" (≈ 1 line)# s_prev.shape=(m, Tx, n_s)s_prev = repeator(s_prev)# Use concatenator to concatenate a and s_prev on the last axis (≈ 1 line)# For grading purposes, please list 'a' first and 's_prev' second, in this order.# a是(m, Tx, 2*n_a),s_prev是(m, Tx, n_s),concat是(m, Tx, 2*n_a+n_s)concat = concatenator([a,s_prev])# Use densor1 to propagate concat through a small fully-connected neural network to compute the "intermediate energies" variable e. (≈1 lines)e = densor1(concat)# Use densor2 to propagate e through a small fully-connected neural network to compute the "energies" variable energies. (≈1 lines)# energies.shape=(m, Tx, 1),经过2个全连接层后,每个时间步输出1个能量值energies = densor2(e)# Use "activator" on "energies" to compute the attention weights "alphas" (≈ 1 line)# 注意:这里只有激活层,没有全连接层,所以不改变维度数,alphas.shape仍是(m, Tx, 1),但是计算了softmax值,所有时间步的权重和为1alphas = activator(energies)# Use dotor together with "alphas" and "a", in this order, to compute the context vector to be given to the next (post-attention) LSTM-cell (≈ 1 line)# alphas.shape是(m, Tx, 1),a是(m, Tx, 2*n_a),context是(m, 1, 2*n_a),对于时间步i,将第i个注意力权重*第i步的隐藏状态向量,最后将所有加权后的状态向量相加context = dotor([alphas,a])### END CODE HERE ###return context
Transformer模型
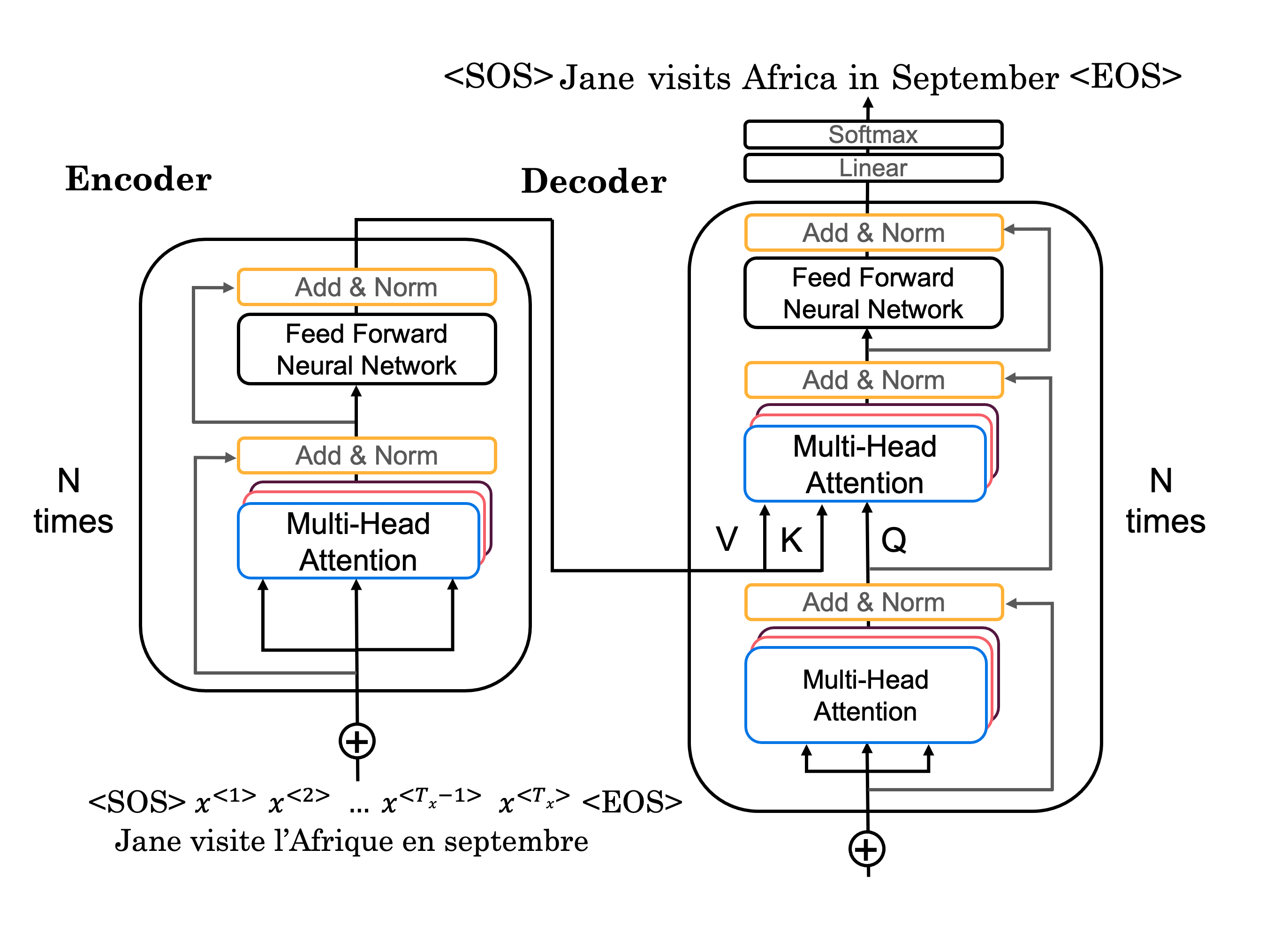
- RNN+注意力模型的问题:计算注意力权重依赖上一次输出序列的隐藏状态,只能串行计算注意力值,对于长序列输出训练和预测效率差,而Transformer模型可以并行计算注意力值
- 也是编码器-解码器结构,编码器由N个(通常6个)编码器单元串联,编码器单元由1个多头注意力层和1个前馈神经网络(2个全连接层)串联组成,解码器也是由N个(通常6个)解码器单元串联,解码器单元由2个多头注意力层和1个前馈神经网络串联组成。
- 填充:编码器的为定长输入,如果输入序列长度超过定长,则分成多个批次;如果不足定长,用1个很小的负数(近似负无穷)填充,因为softmax是e的指数次幂,e的负无穷是0,转成负无穷后,它的softmax值是0,与v求点积,不影响最终的注意力值
- 位置编码:对于RNN模型,注意力权重是按照序列的顺序计算的,顺序信息隐含在计算中,而transformer模型并行计算注意力值,计算本身不包含顺序信息,所以计算注意力前,需要在序列的词嵌入(词向量)中添加词语的位置信息。使用正弦余弦位置编码函数根据词语的位置(1~Tx)计算位置编码,词语的位置编码也是向量,形状和词向量相同,加上词向量得到词语的最终编码,位置编码的值足够小[-1,1],不过于影响词向量的值
P E ( p o s , 2 i ) = s i n ( p o s 10000 2 i d ) P E ( p o s , 2 i + 1 ) = c o s ( p o s 10000 2 i d ) 其中 2 i 是 0 , 2 , 4... ,对应单个词语位置编码向量的第偶数个值, 2 i + 1 对应奇数 p o s 是词语的位置, 1 , 2 , 3... T x PE_{(pos, 2i)}= sin\left(\frac{pos}{{10000}^{\frac{2i}{d}}}\right) \\ PE_{(pos, 2i+1)}= cos\left(\frac{pos}{{10000}^{\frac{2i}{d}}}\right) \\ 其中2i是0,2,4...,对应单个词语位置编码向量的第偶数个值,2i+1对应奇数 \\ pos是词语的位置,1,2,3...Tx PE(pos,2i)=sin(10000d2ipos)PE(pos,2i+1)=cos(10000d2ipos)其中2i是0,2,4...,对应单个词语位置编码向量的第偶数个值,2i+1对应奇数pos是词语的位置,1,2,3...Tx
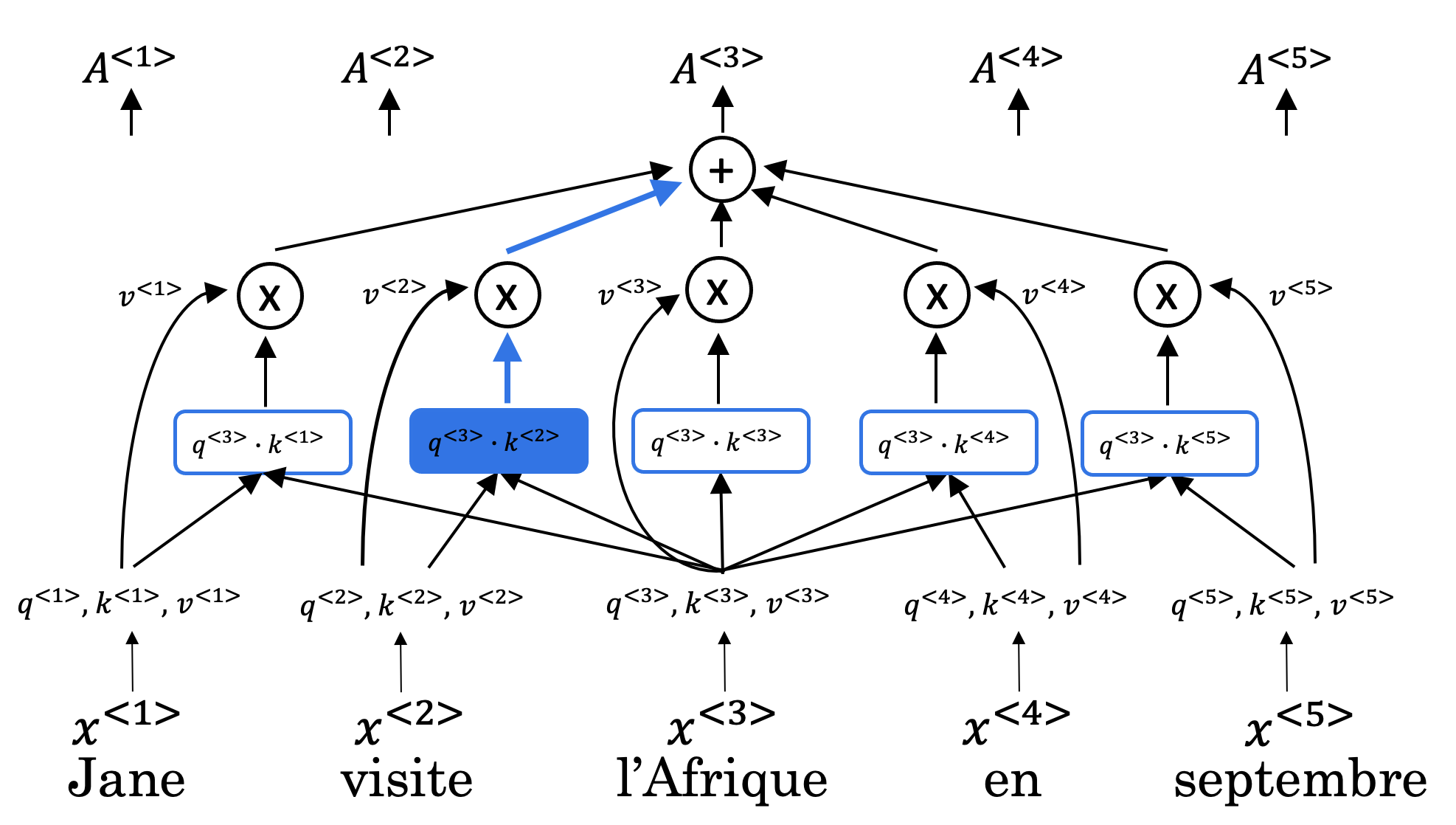
- 自注意力(self-attention):输入序列的词向量分别乘以权重,得到Q,K,V,q3表示对词语x3的问题,q3*K’是该问题和每个词语的关系大小(向量内积表示相似度),softmax是为了获取与该问题相似度的比例,该比值乘V求和,得到词语x3在q3问题的答案
自注意力计算公式: Attention ( Q , K , V ) = softmax ( Q K T d k ) V 向量化运算,一步完成输入序列的每个词语的注意力值,是先求 s o f t m a x 再乘 V Q = W Q ⋅ X K = W K ⋅ X V = W V ⋅ X 自注意力计算公式:\text { Attention }(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V \\ 向量化运算,一步完成输入序列的每个词语的注意力值,是先求softmax再乘V \\ Q=W^Q \cdot X \\ K=W^K \cdot X \\ V=W^V \cdot X \\ 自注意力计算公式: Attention (Q,K,V)=softmax(dkQKT)V向量化运算,一步完成输入序列的每个词语的注意力值,是先求softmax再乘VQ=WQ⋅XK=WK⋅XV=WV⋅X
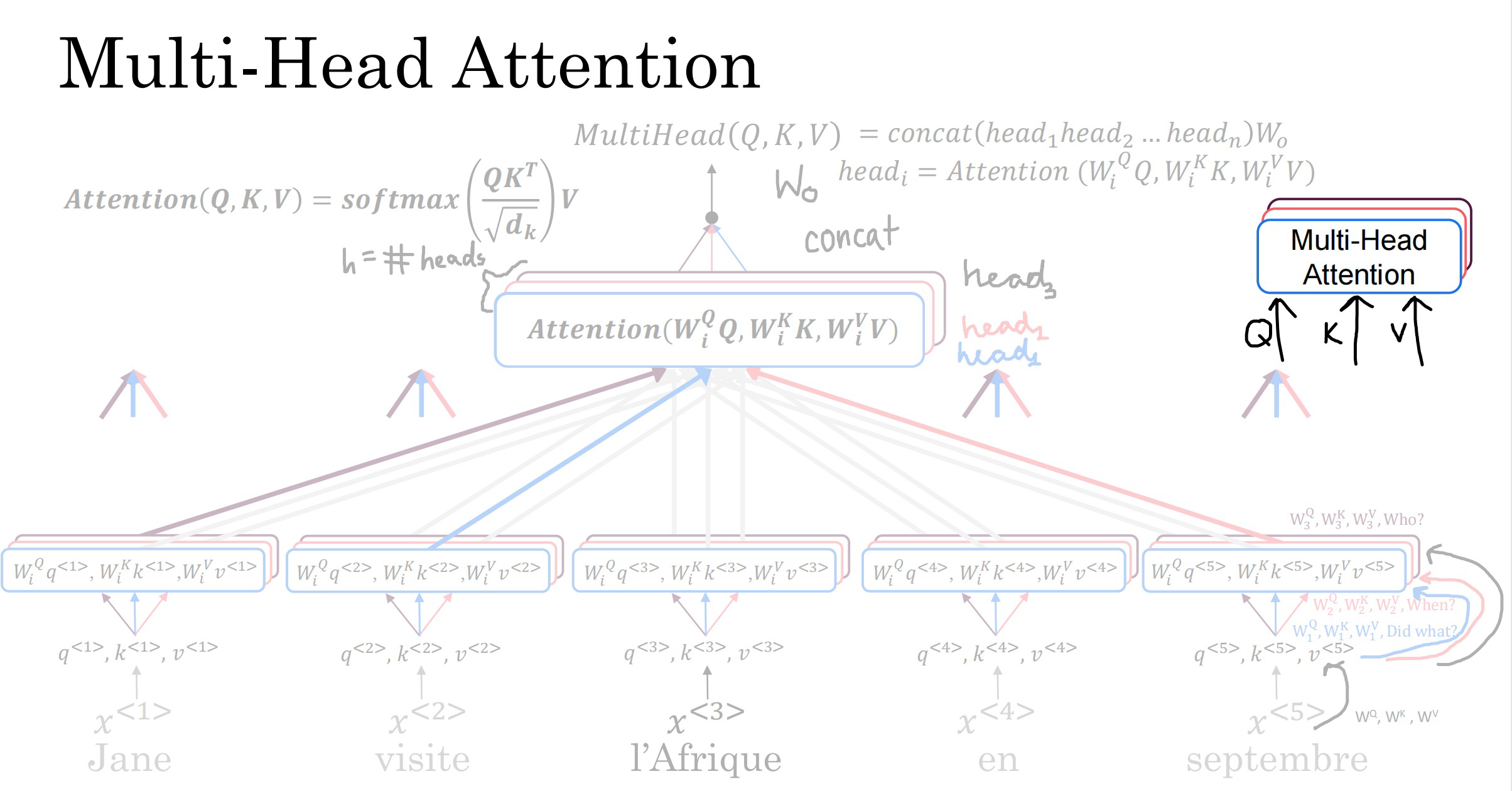
- 多头注意力(multi-head):计算单个自注意力n次,就是n头注意力,一般8头。每一个头的使用不同的权重,得到不同Q、K、V,分别计算这些头的注意力值,将结果合并成一个大的矩阵,乘以权重,得到最终结果
多头注意力: M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) W O 的作用是将合并后的大矩阵转成形状和 h e a d i 相同的小矩阵,从而继续作为下一个编码器单元的输入 多头注意力:MultiHead(Q, K, V ) = Concat(head_1, ..., head_h)W^O \\ head_i = Attention(QW_i^Q, KW_i^K, V W_i^V) \\ W^O的作用是将合并后的大矩阵转成形状和head_i相同的小矩阵,从而继续作为下一个编码器单元的输入 \\ 多头注意力:MultiHead(Q,K,V)=Concat(head1,...,headh)WOheadi=Attention(QWiQ,KWiK,VWiV)WO的作用是将合并后的大矩阵转成形状和headi相同的小矩阵,从而继续作为下一个编码器单元的输入
- 解码器有2个输入,1个是输出序列,初始为起始字符,经过多头注意力层后,取其中的Q向量,1个是编码器的输出,也就是V的softmax加权值,作为K和V(K和V相同),经过N个解码器单元后,由softmax得到输出序列的下一个预测值