摘要:小型语言模型(SLM)的推理能力有限,这使得人们对其是否适合需要深度、多步骤逻辑推理的任务产生了怀疑。本文介绍了一种名为“小理由,大提示”(SMART)的框架,该框架通过从大型语言模型(LLM)中选择性地提供针对性指导来增强SLM的推理能力。SMART受到认知脚手架概念的启发,通过基于评分的评估来识别不确定的推理步骤,并且只在必要时注入由LLM生成的纠正性推理内容。通过将结构化推理视为一种最优策略搜索,我们的方法能够在不进行穷尽采样的情况下,引导推理轨迹走向正确答案。我们在数学推理数据集上的实验表明,针对性的外部辅助显著提高了性能,为SLM和LLM的协作使用铺平了道路,使其能够共同解决目前SLM单独无法解决的复杂推理任务。
本文目录
一、背景动机
二、核心贡献
三、实现方法
3.1 SLM生成推理草稿
3.2 基于分数的步骤评估
3.3 LLM基于步骤修正
3. 4 终止条件
3.5 测试时间计算扩展
四、实验结果
4.1 实验设置
4.2 性能提升
4.3 LLM辅助的效益
4.4 成本效益分析
五、未来研究
一、背景动机
论文题目:Guiding Reasoning in Small Language Models with LLM Assistance
论文地址:https://arxiv.org/pdf/2504.09923v1
当前大模型在需要多步逻辑推理的任务中表现出色,然而小模型SLMs(Small Language Models)由于参数容量有限,虽然推理效率高,但通常难以处理复杂的推理任务,这限制了它们在需要深度逻辑推导的场景中的应用。
该文章提出SMART(Small Reasons, Large Hints)框架,通过在关键决策点提供LLM的辅助,来提升SLMs的推理能力,使其能够处理原本无法解决的复杂推理任务。
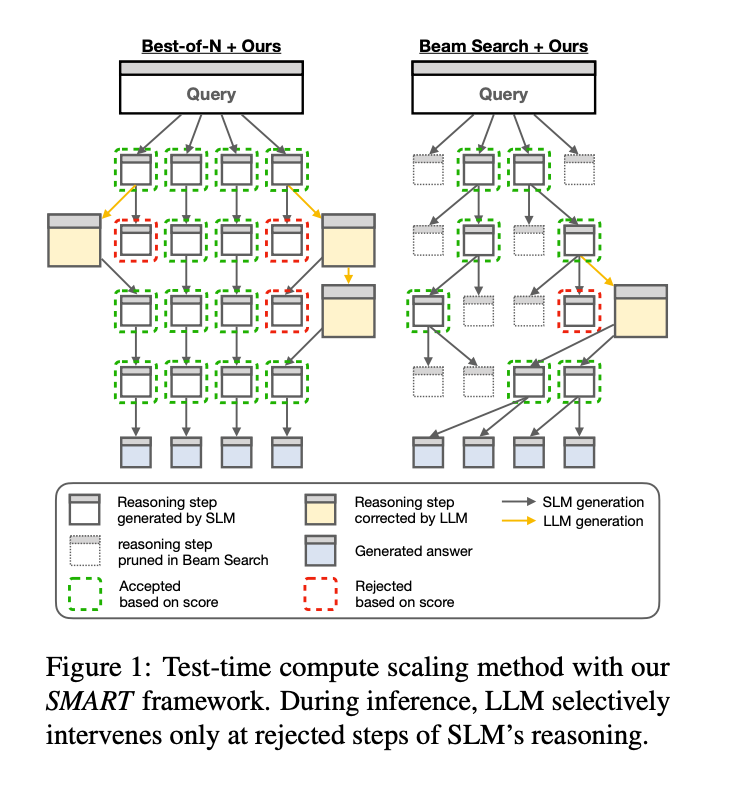
二、核心贡献
1、提出了SMART框架,其通过选择性地将LLM生成的推理步骤整合到SLM的推理过程中,以提升SLM的推理能力。
2、在数学推理数据集上进行的实验表明,SMART能够显著提升SLM的性能,使其能够解决原本无法解决的复杂推理问题。
3、文章详细分析了在何种情况下LLM辅助最为有益,为混合推理系统提供了思路。
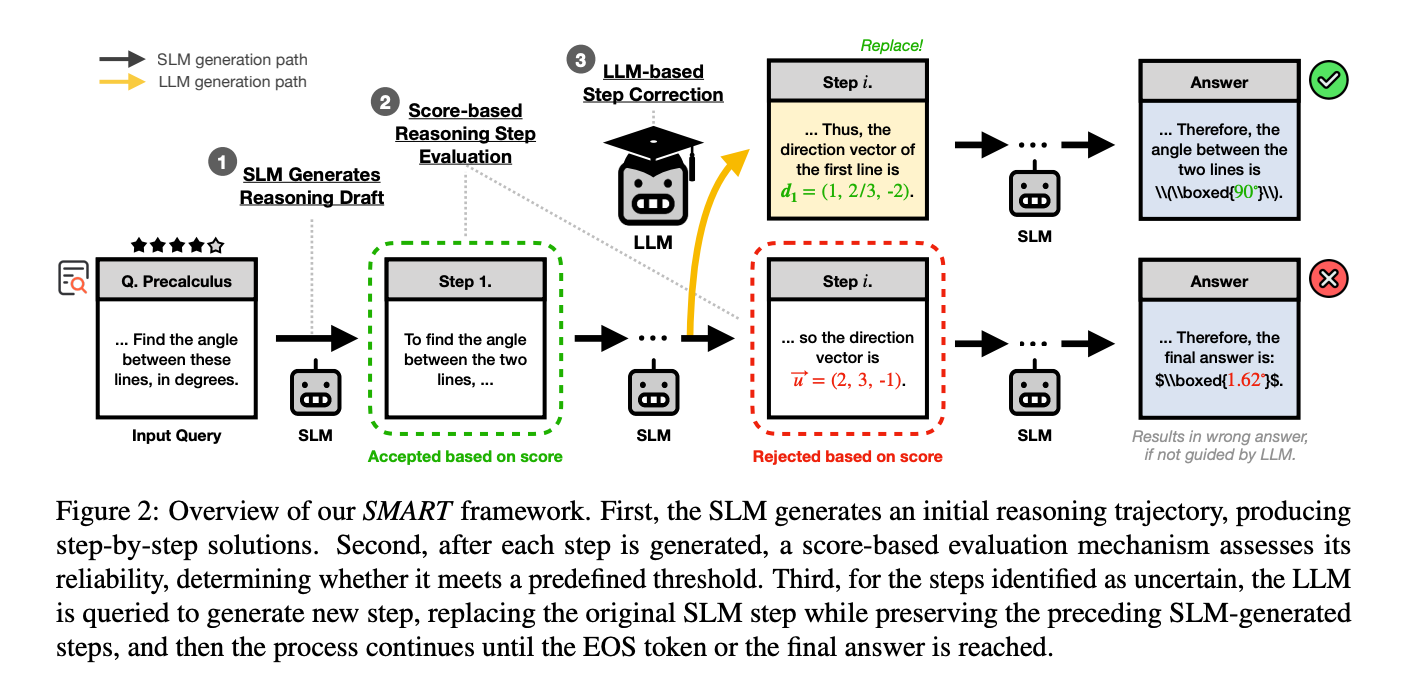
三、实现方法
3.1 SLM生成推理草稿
-
输入:给定一个查询 Q。
-
过程:SLM自回归地生成一个初始推理轨迹 R=(r1,r2,…,rm),其中每个 ri 是一个中间推理步骤。
-
输出:生成的推理过程 R。
3.2 基于分数的步骤评估
-
评分函数:为每个生成的推理步骤
分配一个分数
,用于评估其可靠性。
-
PRM分数:使用预训练的奖励模型(Process Reward Model, PRM)评估每个步骤的正确性。
-
Token级置信度(TLC):计算每个步骤中每个token的平均置信度。
-
-
阈值判断:如果分数 s 低于预设阈值 τ,则认为该步骤不可靠,需要LLM的辅助。
3.3 LLM基于步骤修正
-
LLM干预:如果步骤
替换它
-
保留SLM步骤:如果步骤的分数高于阈值,则保留SLM生成的步骤。
3. 4 终止条件
-
EOS标记:如果生成了结束标记(EOS),则停止推理。
-
最大token长度:如果累积的token数量超过预设的最大值 Lmax,则停止推理。
3.5 测试时间计算扩展
-
Best-of-N:生成多个推理路径,并独立应用SMART框架。每个路径中的低分节点被LLM生成的替代步骤替换。
-
Beam Search:在每个推理步骤中保留前 M 个候选序列。如果任何候选节点的分数低于阈值 τ,则用LLM生成的替代步骤替换。
四、实验结果
4.1 实验设置
-
数据集:MATH500数据集,包含500个数学问题,涵盖不同难度级别。
-
模型:Qwen2.5-1.5B和Qwen2.5-7B,以及Llama3.2-1B和Llama3.2-8B。
-
评分方法:PRM分数和TLC分数。
-
评估指标:Weighted@N,选择最高总奖励的答案。
4.2 性能提升
-
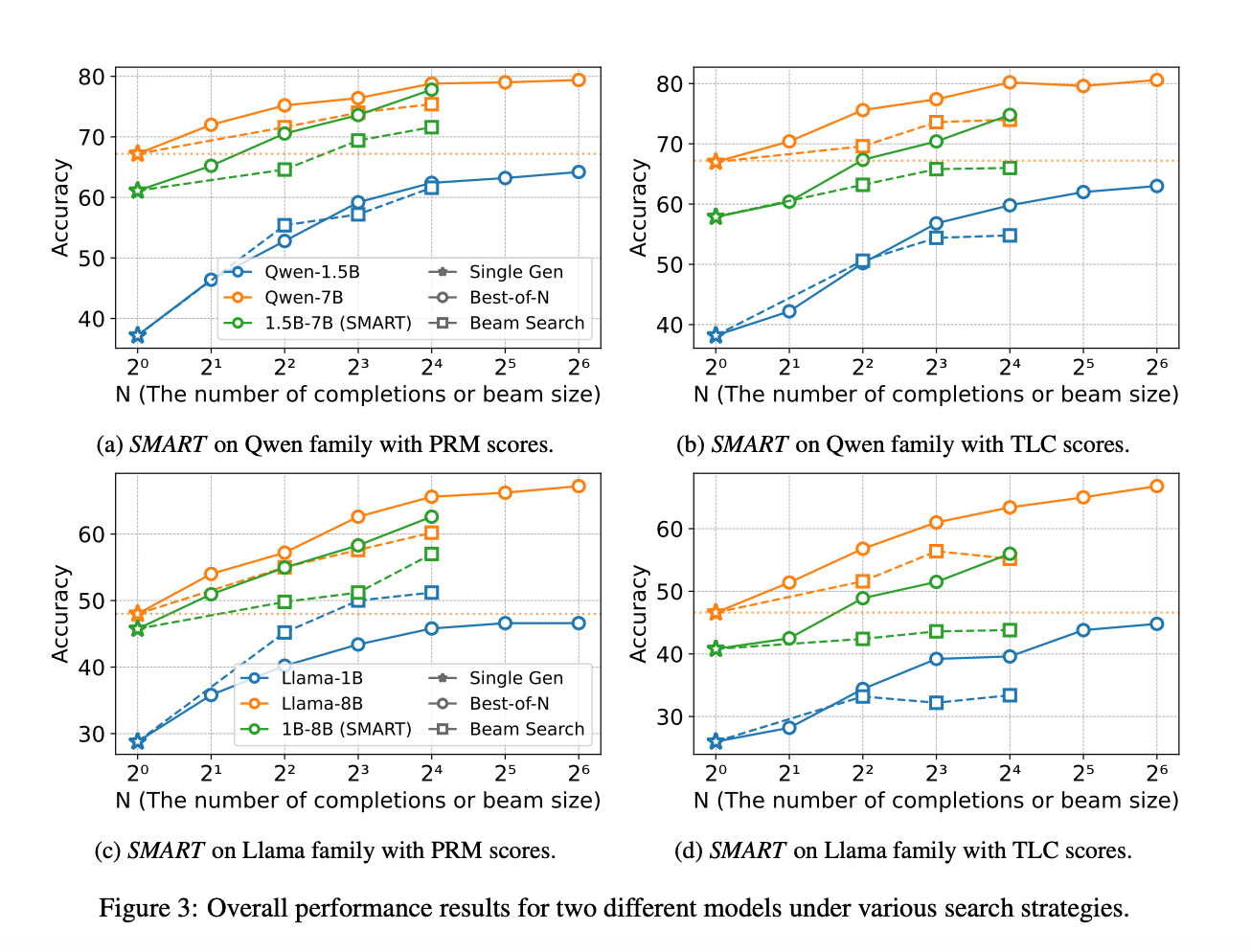
SMART在所有设置中均优于SLM基线,并且随着测试时间计算的增加,SMART的性能迅速接近LLM水平。
-
在单步生成(N=1)的情况下,SMART已经提供了明显的准确性提升。如在N=1时,SMART将Qwen2.5-1.5B的准确率从66.85%提升到79.79%。
-
随着N的增加,SMART的性能进一步提升,尤其是在更复杂的任务中。如在N=16时,SMART将Qwen2.5-1.5B的准确率提升到91.85%,接近Qwen2.5-7B的94.85%。
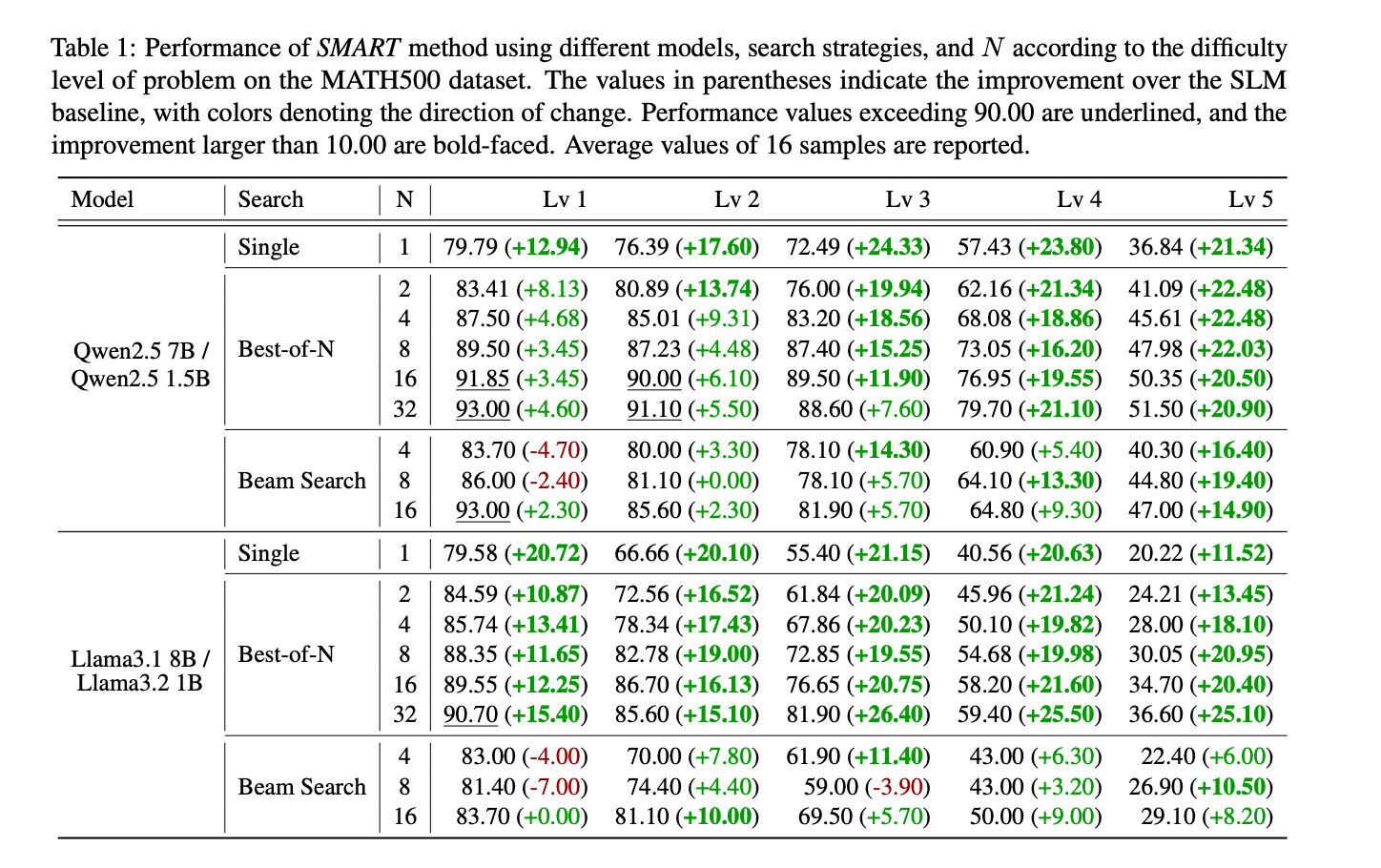
4.3 LLM辅助的效益
-
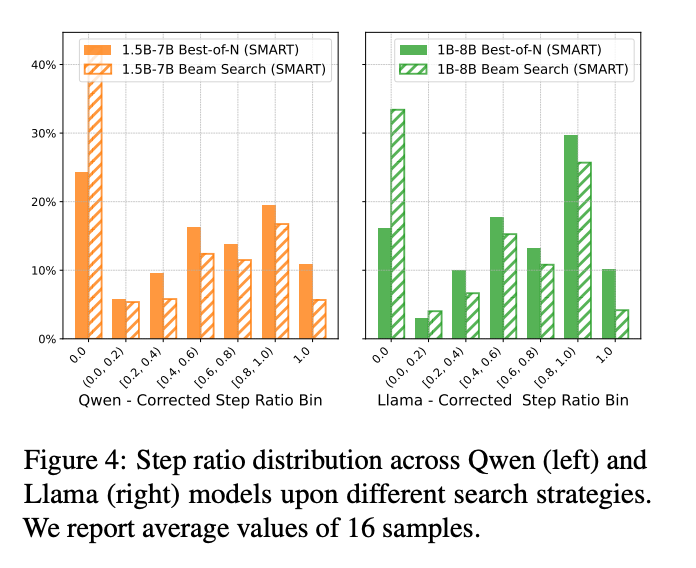
在低难度任务中,SLM需要较少的LLM干预。在高难度任务中,LLM干预频率显著增加,表明SMART能够有效检测并仅在SLM遇到困难时提供支持。
-
SMART在Best-of-N策略下更频繁地进行干预,并且在必要时进行更激进的修正。在Beam Search策略下,LLM干预较少,因为Beam Search的树状结构允许单个修正自动传播到多个子路径。
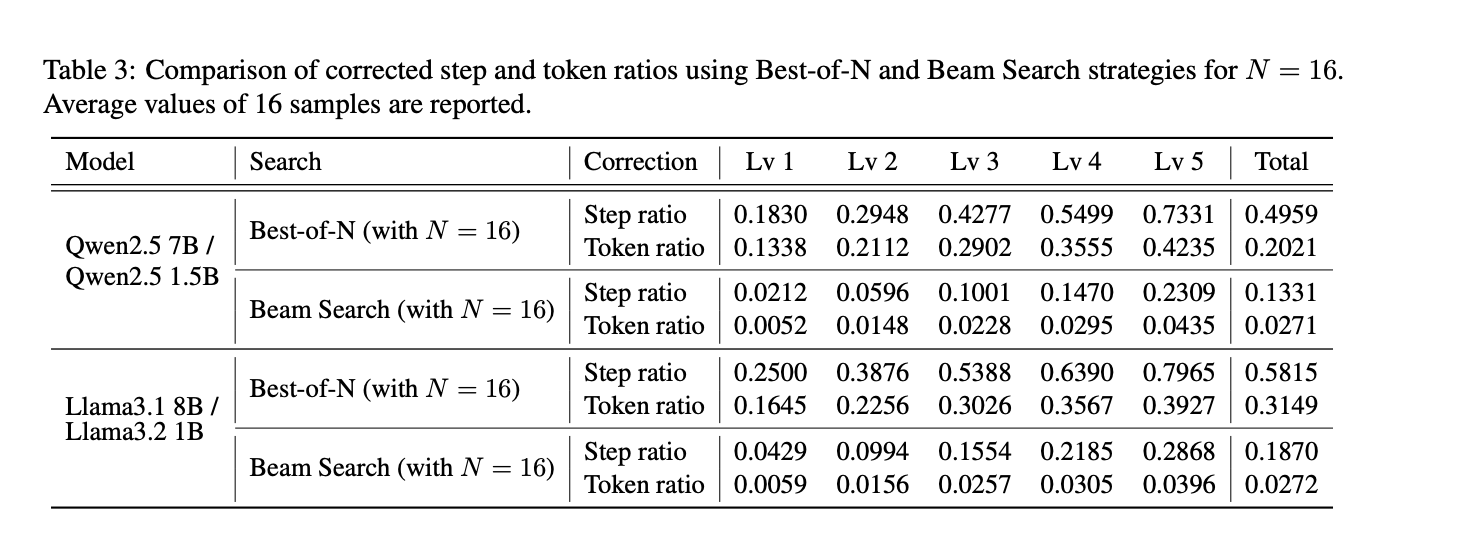
4.4 成本效益分析
-
SMART在Beam Search策略下显著减少了LLM token的使用量,最高可达90%。在Best-of-N策略下,SMART的LLM token使用量与直接使用LLM相当。
-
SMART在减少LLM token使用量的同时保持了与LLM相当的准确性,尤其是在Beam Search策略下。
五、未来研究
1、LLM辅助的控制:SMART通过PRM和TLC分数间接控制LLM辅助的程度,缺乏更精细的控制,未来可以探索基于任务复杂度或计算约束的更适应性策略。
2、触发LLM辅助的策略:当前的触发策略可能不是最优的,未来可以探索更优的策略以进一步减少计算开销。
)

)



