https://github.com/NVIDIA/Megatron-LM![]() https://github.com/NVIDIA/Megatron-LM
https://github.com/NVIDIA/Megatron-LM
目录
- Megatron-LM & Megatron-Core
- 最新消息
- 目录
- 威震天 概述
- 威震天-LM
- 威震天核心
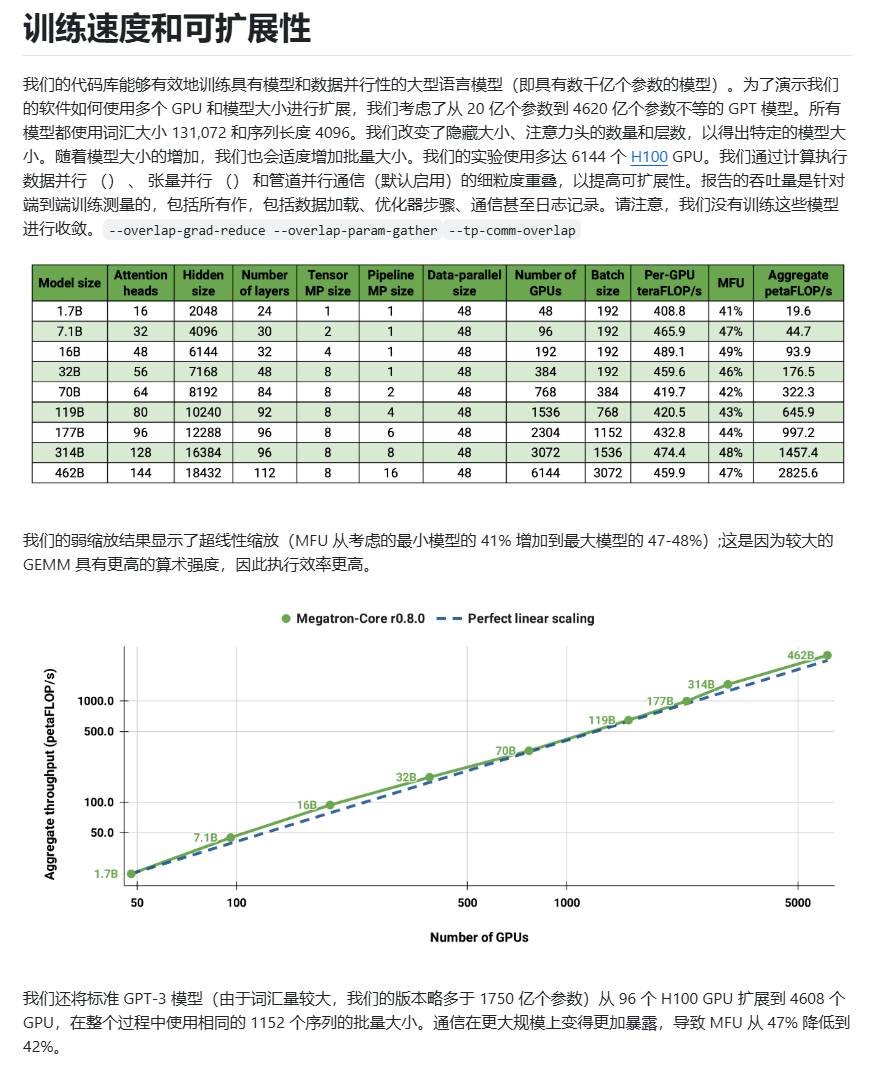
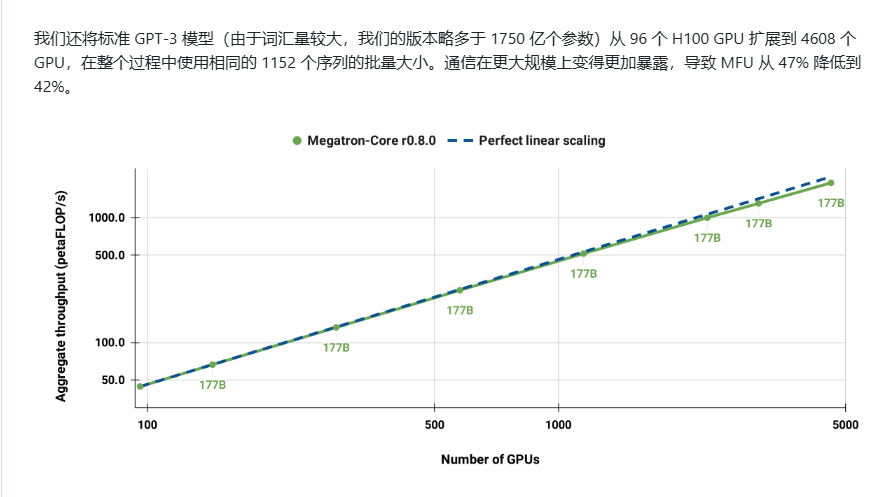
- 训练速度和可扩展性
- 设置
- 下载 Checkpoints
- 用法
- 训练
- 数据预处理
- BERT 预训练
- GPT 预训练
- T5 预训练
- 分布式预训练
- 激活检查点和重新计算
- 分布式优化器
- FlashAttention 的
- GPT-3 示例
- Retro 和 InstructRetro
- 基于 Manba 的语言模型
- 专家混合
- 评估和任务
- GPT 文本生成
- 通过自我生成排毒 GPT
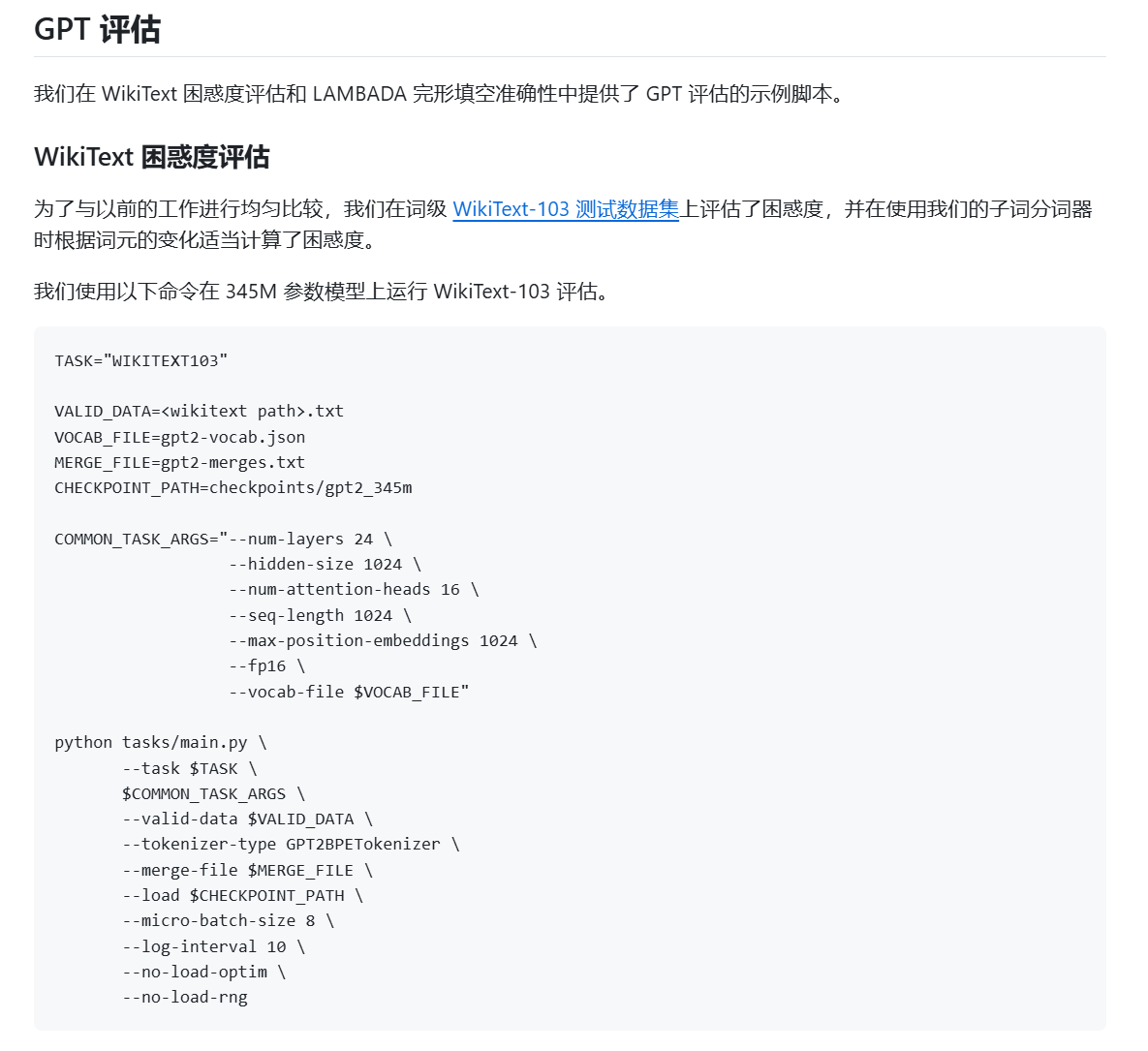
- GPT 评估
- WikiText 困惑度评估
- LAMBADA 完形填空精度
- BERT 任务评估
- RACE 评估
- MNLI 评估
- Llama-2 推理和微调
- GPT 文本生成
- 模型优化和部署
- 量化和 TensorRT-LLM 部署
- 数据
- 收集 Wikipedia 训练数据
- 收集 GPT Webtext 数据
- 再现性
- 检查点转换
- 模型类转换
- 检查点格式转换
- 使用 Megatron 的项目
Megatron Overview
此存储库包含两个基本组件:Megatron-LM 和 Megatron-Core。Megatron-LM 是一个以研究为导向的框架,利用 Megatron-Core 进行大型语言模型 (LLM) 训练。另一方面,Megatron-Core 是一个 GPU 优化训练技术库,附带正式的产品支持,包括版本控制的 API 和常规版本。您可以将 Megatron-Core 与 Megatron-LM 或 Nvidia NeMo 框架一起使用,以实现端到端和云原生解决方案。或者,您可以将 Megatron-Core 的构建块集成到您首选的训练框架中。
Megatron-LM
Megatron(1、2 和 3)于 2019 年首次推出,在 AI 社区引发了一波创新浪潮,使研究人员和开发人员能够利用该库的基础来进一步推动 LLM 的进步。如今,许多最流行的 LLM 开发人员框架都受到开源 Megatron-LM 库的启发并直接利用开源 Megatron-LM 库构建,从而刺激了一波基础模型和 AI 初创公司。基于 Megatron-LM 构建的一些最流行的 LLM 框架包括 Colossal-AI、HuggingFace Accelerate 和 NVIDIA NeMo 框架。可以直接使用 Megatron 的项目列表可以在这里找到。
Megatron-Core
Megatron-Core 是一个基于 PyTorch 的开源库,其中包含 GPU 优化技术和尖端的系统级优化。它将它们抽象为可组合的模块化 API,为开发人员和模型研究人员提供了充分的灵活性,可以在 NVIDIA 加速计算基础设施上大规模训练自定义转换器。此库与所有 NVIDIA Tensor Core GPU 兼容,包括对 NVIDIA Hopper 架构的 FP8 加速支持。
Megatron-Core 提供核心构建块,例如注意力机制、transformer 块和层、归一化层和嵌入技术。激活重新计算、分布式检查点等其他功能也内置于库中。构建块和功能都经过 GPU 优化,可以使用高级并行化策略构建,以实现 NVIDIA 加速计算基础设施上的最佳训练速度和稳定性。Megatron-Core 库的另一个关键组件包括高级模型并行技术(张量、序列、管道、上下文和 MoE 专家并行)。
Megatron-Core 可与企业级 AI 平台 NVIDIA NeMo 一起使用。或者,您可以在此处使用本机 PyTorch 训练循环探索 Megatron-Core。访问 Megatron-Core 文档以了解更多信息。
Training Speed and Scalability
Setup

Usage
安装后,有几种可能的工作流程。最全面的是:
- 数据预处理
- 预训练
- 微调(对于零镜头任务可选)
- 下游任务评估或文本生成
但是,步骤 1 和 2 可以用上面提到的预训练模型之一来代替。
我们在 examples 目录中提供了几个用于预训练 BERT 和 GPT 的脚本,以及用于零样本和微调下游任务的脚本,包括 MNLI、RACE、WikiText103 和 LAMBADA 评估。还有一个用于 GPT 交互式文本生成的脚本。
Training

BERT Pretraining

GPT Pretraining

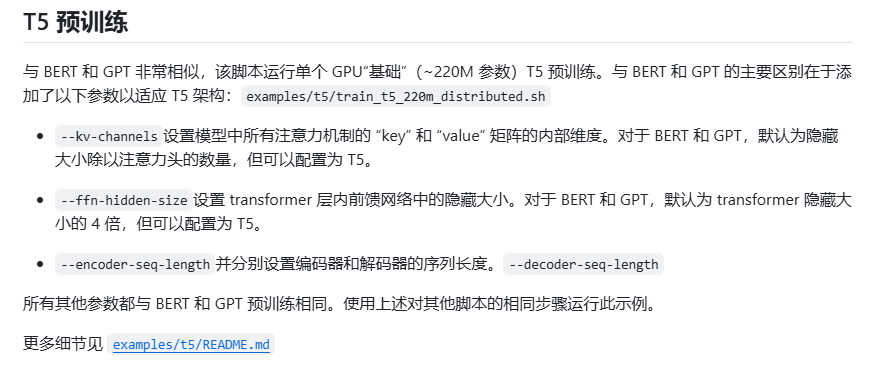
T5 Pretraining
Distributed Pretraining

Activation Checkpointing and Recomputation

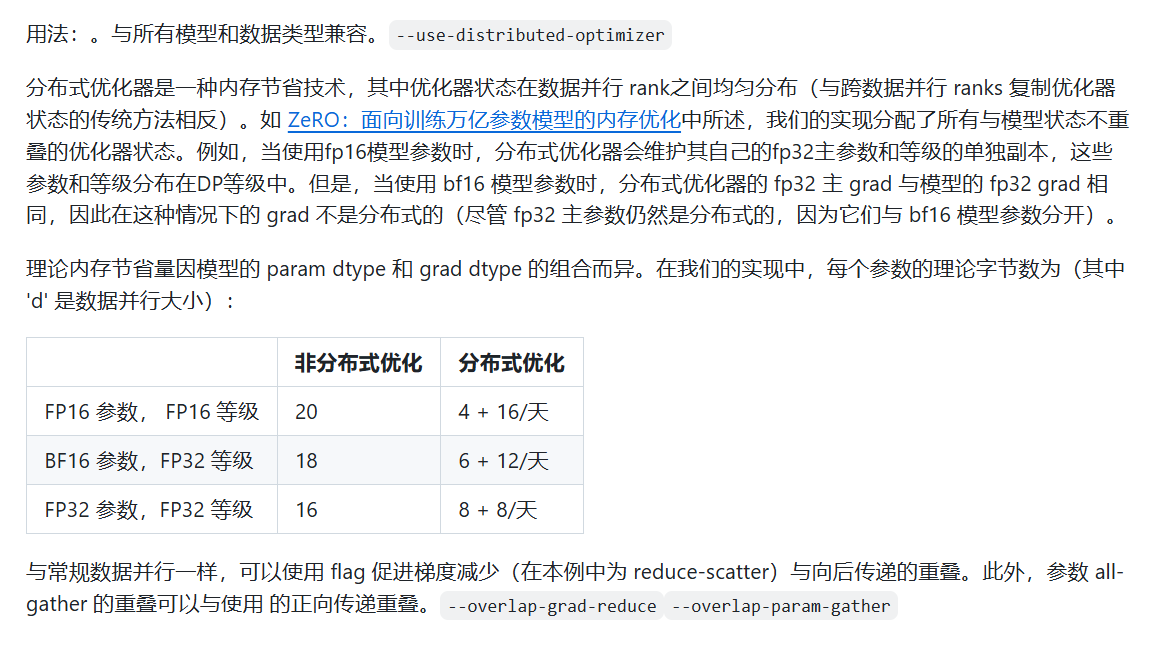
Distributed Optimizer
FlashAttention

GPT-3 Example

Retro and InstructRetro

Mamba-based Language Models
Mixture of Experts

Evaluation and Tasks

GPT Text Generation
GPT Evaluation
LAMBADA Cloze Accuracy

BERT Task Evaluation (BERT模型评估)
RACE Evaluation

MNLI Evaluation

Llama-2 Inference and Finetuning
Model Optimization and Deployment

Quantization and TensorRT-LLM Deployment

Datasets


Reproducibility

Checkpoint conversion

Model class conversion

Checkpoint format conversion

Projects Using Megatron
Below are some of the projects where we have directly used Megatron:
- BERT and GPT Studies Using Megatron
- BioMegatron: Larger Biomedical Domain Language Model
- End-to-End Training of Neural Retrievers for Open-Domain Question Answering
- Large Scale Multi-Actor Generative Dialog Modeling
- Local Knowledge Powered Conversational Agents
- MEGATRON-CNTRL: Controllable Story Generation with External Knowledge Using Large-Scale Language Models
- RACE Reading Comprehension Dataset Leaderboard
- Training Question Answering Models From Synthetic Data
- Few-shot Instruction Prompts for Pretrained Language Models to Detect Social Biases
- Exploring the Limits of Domain-Adaptive Training for Detoxifying Large-Scale Language Models
- Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model
- Multi-Stage Prompting for Knowledgeable Dialogue Generation
- Evaluating Parameter Efficient Learning for Generation
- Exploring the Limits of Domain-Adaptive Training for Detoxifying Large-Scale Language Models
- Shall We Pretrain Autoregressive Language Models with Retrieval? A Comprehensive Study
- InstructRetro: Instruction Tuning post Retrieval-Augmented Pretraining
- An Empirical Study of Mamba-based Language Models





