#利用线性回归模型california房价预测
#调用API
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.metrics import mean_squared_error
#利用正规方程的优化方法进行预测:
def linear1():#获取数据california = fetch_california_housing()#划分数据集x_test,x_train,y_test,y_train = train_test_split(california.data,california.target,random_state = 22)#标准化transfer = StandardScaler()# fit_transform 方法首先计算训练集的均值和标准差,然后使用这些统计量对训练集进行标准化x_train = transfer.fit_transform(x_train)# transform 方法使用训练集的均值和标准差对测试集进行标准化。这确保了训练集和测试集使用相同的缩放参数。x_test = transfer.transform(x_test)#预估器# 创建 LinearRegression 预估器对象estimator = LinearRegression()# fit 方法用于将线性回归模型拟合到训练数据上。它会计算模型的系数和截距,使得模型能够最好地描述训练数据。estimator.fit(x_train,y_train)#得出模型print("正规方程——权重系数:\n",estimator.coef_)print("正规方程——偏置为:\n",estimator.intercept_)#模型评估y_predict = estimator.predict(x_test)mse = mean_squared_error(y_test,y_predict)print("MSE:\n",mse)return None#利用梯度下降优化方法进行预测
def linear2():#获取数据california = fetch_california_housing()#划分数据集x_train,x_test,y_train,y_test = train_test_split(california.data,california.target,random_state = 22)#标准化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)#预估器#(对于一个常数数值学习率)learning_rate = "constant"#eta0 = n -->指定一个学习率;max_iter -->迭代次数estimator = SGDRegressor(eta0=0.001,max_iter=10000)estimator.fit(x_train,y_train)#得出模型print("梯度下降——权重系数:\n",estimator.coef_)print("梯度下降——偏置:\n",estimator.intercept_)#模型评估y_predict = estimator.predict(x_test)mse = mean_squared_error(y_test,y_predict)print("MSE:\n",mse)return None
if __name__ == "__main__":linear1()linear2()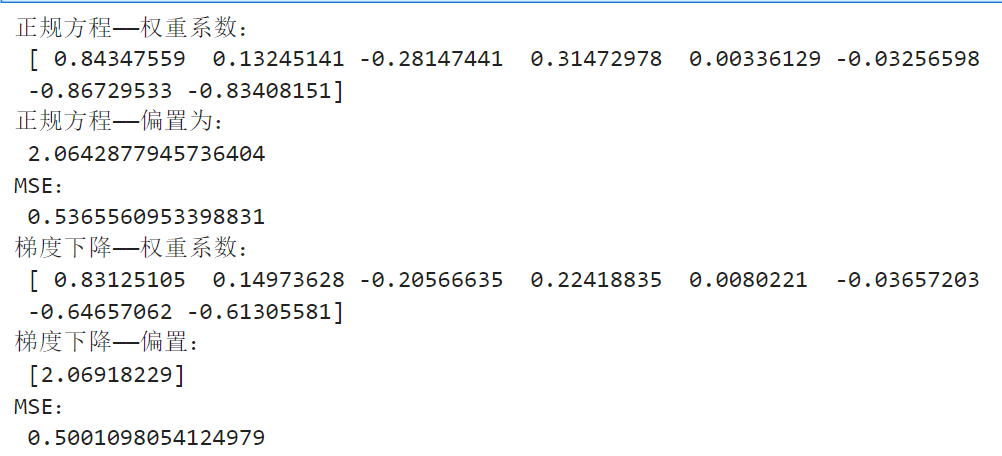
)

)



