
智谱AI引领技术前沿,推出了新一代预训练模型GLM-4系列,其中的GLM-4-9B作为开源版本,展现了其在人工智能领域的深厚实力。在语义理解、数学运算、逻辑推理、代码编写以及广泛知识领域的数据集测评中,GLM-4-9B及其人类偏好对齐的版本GLM-4-9B-Chat均以超越Llama-3-8B的优异表现,证明了其卓越的性能。
GLM-4-9B-Chat不仅擅长进行流畅的多轮对话,还集成了网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大128K上下文)等高级功能,极大地扩展了其应用场景。此外,本代模型在语言支持上迈出了重要一步,现已支持包括日语、韩语、德语在内的26种语言,进一步促进了全球范围内的语言交流与技术融合。
为了满足不同用户的需求,智谱AI还推出了支持1M上下文长度(约200万中文字符)的GLM-4-9B-Chat-1M模型,以及基于GLM-4-9B的多模态模型GLM-4V-9B。GLM-4V-9B在1120 * 1120的高分辨率下,展现了其中英双语多轮对话的强大能力。在中英文综合能力、感知推理、文字识别、图表理解等多模态评测中,GLM-4V-9B的表现超越了GPT-4-turbo-2024-04-09、Gemini 1.0 Pro、Qwen-VL-Max和Claude 3 Opus等同类模型。
GLM结构
GLM(General Language Modeling)是一种自然语言处理模型,用于理解和生成人类语言。GLM的架构包括多个层次,每个层次都扮演着重要的角色。下面是GLM框架和模型的详细解释:
- 输入层:输入层负责将文本数据转换为模型可以理解的格式。首先,使用Tokenizer将输入的文本序列转换为字或词标记的序列。然后,将这些词标记转换为对应的ID,即Input_ids。
- Embedding层:Embedding层将每个ID映射到一个固定维度的向量。这样,每个文本序列都被转换为一个向量序列,作为模型的初始输入表示。
- GLMBlock28(或GLM4-9B-Chat的GLMBlock40):这是GLM模型的核心部分,由多个GLMBlock组成。每个GLMBlock包含两个主要部分:Self-Attention和Feed-Forward Network (MLP)。
-
Self-Attention:在Self-Attention部分,输入首先通过Q、K、V矩阵映射。然后,引入Rotary Position Embedding(RoPE)以更好地学习词之间的位置信息。接着,进行注意力计算,并将输出线性变换为与输入相同的维度。最后,使用残差连接网络(Residual Connection)、Dropout和RMSNorm等方法来防止过拟合。
-
Feed-Forward Network (MLP):在MLP部分,输入通过两层全连接变换,最多扩展到13696维度。使用Swiglu激活函数代替传统的Relu激活函数。与Self-Attention的输出类似,MLP的输出也引入了Dropout和RMSNorm方法。
-
- RMSNorm层:在GLM模型中,使用RMSNorm(均方根标准化)代替传统的LayerNorm(层标准化)。RMSNorm具有加速训练和改善模型泛化能力的效果。
- 输出层:输出层负责将模型的最终输出转换回文本格式。首先,将embedding转换回字词编码。然后,使用解码器将这些编码转换为人类可读的文本。
- 残差连接网络(Residual Connection):残差连接网络是一种在深度学习中常用的技巧。它在神经网络的层与层之间添加一个直接的连接,允许输入信号无损地传递到较深的层。这样设计的目的是为了缓解梯度消失和梯度爆炸问题,同时促进梯度在深层网络中的流畅传播,使得训练更高效,模型更容易学习复杂的特征。
- 旋转位置编码(Rotary Position Embedding,RoPE):RoPE是一种位置编码方法,用于更好地学习词之间的位置信息。它被广泛应用于各种NLP模型中,如Qwen、LLaMA等。
GLM-4V模型
ChatGLMForConditionalGeneration((transformer): ChatGLMModel((embedding): Embedding((word_embeddings): Embedding(151552, 4096))(rotary_pos_emb): RotaryEmbedding()(encoder): GLMTransformer((layers): ModuleList((0-39): 40 x GLMBlock((input_layernorm): RMSNorm()(self_attention): SelfAttention((query_key_value): Linear(in_features=4096, out_features=4608, bias=True)(core_attention): CoreAttention((attention_dropout): Dropout(p=0.0, inplace=False))(dense): Linear(in_features=4096, out_features=4096, bias=False))(post_attention_layernorm): RMSNorm()(mlp): MLP((dense_h_to_4h): Linear(in_features=4096, out_features=27392, bias=False)(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False))))(final_layernorm): RMSNorm())(output_layer): Linear(in_features=4096, out_features=151552, bias=False)(vision): EVA2CLIPModel((patch_embedding): PatchEmbedding((proj): Conv2d(3, 1792, kernel_size=(14, 14), stride=(14, 14))(position_embedding): Embedding(6401, 1792))(transformer): Transformer((layers): ModuleList((0-62): 63 x TransformerLayer((input_layernorm): LayerNorm((1792,), eps=1e-06, elementwise_affine=True)(attention): Attention((query_key_value): Linear(in_features=1792, out_features=5376, bias=True)(dense): Linear(in_features=1792, out_features=1792, bias=True)(output_dropout): Dropout(p=0.0, inplace=False))(mlp): MLP((activation_fn): GELUActivation()(fc1): Linear(in_features=1792, out_features=15360, bias=True)(fc2): Linear(in_features=15360, out_features=1792, bias=True))(post_attention_layernorm): LayerNorm((1792,), eps=1e-06, elementwise_affine=True))))(linear_proj): GLU((linear_proj): Linear(in_features=4096, out_features=4096, bias=False)(norm1): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(act1): GELU(approximate='none')(dense_h_to_4h): Linear(in_features=4096, out_features=13696, bias=False)(gate_proj): Linear(in_features=4096, out_features=13696, bias=False)(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False))(conv): Conv2d(1792, 4096, kernel_size=(2, 2), stride=(2, 2))))
)
GLM-4V-9B硬件要求
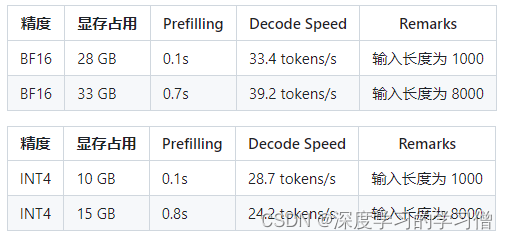
最低硬件要求
如果您希望运行官方提供的最基础代码 (transformers 后端) 您需要:
- Python >= 3.10
- 内存不少于 32 GB
如果您希望运行官方提供的本文件夹的所有代码,您还需要:
- Linux 操作系统 (Debian 系列最佳)
- 大于 8GB 显存的,支持 CUDA 或者 ROCM 并且支持 BF16 推理的 GPU 设备。(FP16 精度无法训练,推理有小概率出现问题)
多模态能力
GLM-4V-9B 是一个多模态语言模型,具备视觉理解能力,其相关经典任务的评测结果如下:
| MMBench-EN-Test | MMBench-CN-Test | SEEDBench_IMG | MMStar | MMMU | MME | HallusionBench | AI2D | OCRBench | |
|---|---|---|---|---|---|---|---|---|---|
| gpt-4o-2024-05-13 | 83.4 | 82.1 | 77.1 | 63.9 | 69.2 | 2310.3 | 55.0 | 84.6 | 736 |
| gpt-4-turbo-2024-04-09 | 81.0 | 80.2 | 73.0 | 56.0 | 61.7 | 2070.2 | 43.9 | 78.6 | 656 |
| gpt-4-1106-preview | 77.0 | 74.4 | 72.3 | 49.7 | 53.8 | 1771.5 | 46.5 | 75.9 | 516 |
| InternVL-Chat-V1.5 | 82.3 | 80.7 | 75.2 | 57.1 | 46.8 | 2189.6 | 47.4 | 80.6 | 720 |
| LLaVA-Next-Yi-34B | 81.1 | 79.0 | 75.7 | 51.6 | 48.8 | 2050.2 | 34.8 | 78.9 | 574 |
| Step-1V | 80.7 | 79.9 | 70.3 | 50.0 | 49.9 | 2206.4 | 48.4 | 79.2 | 625 |
| MiniCPM-Llama3-V2.5 | 77.6 | 73.8 | 72.3 | 51.8 | 45.8 | 2024.6 | 42.4 | 78.4 | 725 |
| Qwen-VL-Max | 77.6 | 75.7 | 72.7 | 49.5 | 52.0 | 2281.7 | 41.2 | 75.7 | 684 |
| Gemini 1.0 Pro | 73.6 | 74.3 | 70.7 | 38.6 | 49.0 | 2148.9 | 45.7 | 72.9 | 680 |
| Claude 3 Opus | 63.3 | 59.2 | 64.0 | 45.7 | 54.9 | 1586.8 | 37.8 | 70.6 | 694 |
| GLM-4V-9B | 81.1 | 79.4 | 76.8 | 58.7 | 47.2 | 2163.8 | 46.6 | 81.1 | 786 |
import torch
from PIL import Image
from transformers import AutoModelForCausalLM, AutoTokenizerdevice = "cuda"tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4v-9b", trust_remote_code=True)query = '描述这张图片'
image = Image.open("your image").convert('RGB')
inputs = tokenizer.apply_chat_template([{"role": "user", "image": image, "content": query}],add_generation_prompt=True, tokenize=True, return_tensors="pt",return_dict=True) # chat modeinputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained("THUDM/glm-4v-9b",torch_dtype=torch.bfloat16,low_cpu_mem_usage=True,trust_remote_code=True
).to(device).eval()gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():outputs = model.generate(**inputs, **gen_kwargs)outputs = outputs[:, inputs['input_ids'].shape[1]:]print(tokenizer.decode(outputs[0]))
未完待续
感谢LDG_AGI分享的《【机器学习】GLM-4V:图片识别多模态大模型(MLLs)初探》博客





