Introduction
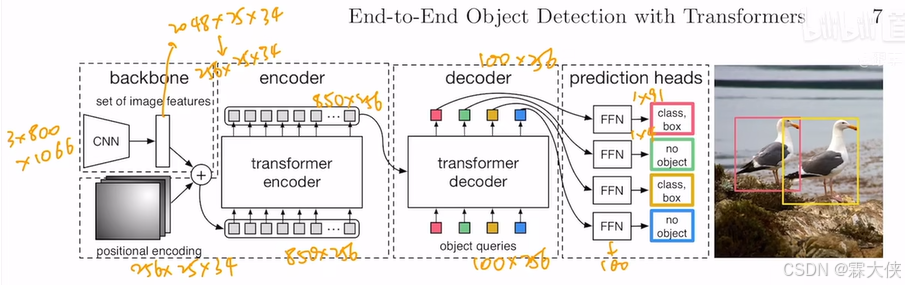
(1)CNN提取视觉特征,拉直
(2)transformer encoder的作用:进一步学习全局信息,为decoder出预测框做铺垫,也就是说图片上每一个像素点(特征)都会和其他点特征有交互,对于同一个物体,就应该只出一个框,而不是出很多框,全局特征有利于移除冗余的框。
(3)Transformer decoder出预测框,结合object query,限定要出多少个框,query和特征不做自主一操作,得出最终的框。
(4)匹配GT,集合预测的问题,用二分图匹配的方法算loss,将出来的100个预测框与GT算loss,没有匹配到GT的框就会被标记成背景类。
推理的时候前三步抑制,第四步的时候不需要loss,设置一个置信度,大的被留下啦,小的被丢弃。
对于大物体效果比较好,小物体效果不太好。取得了与Fast R-CNN comparable的结果,在大物体上预测结果好,小物体上预测结果差,也为后续工作留下改进空间。
半年之后Deformable DETR就出来了,大大提升了效果。
Related Work
集合预测:不需要NMS,直接生成目标预测的集合
DETR主要的两个特点
- Set-based loss:基于集合的预测方法
- Recurrent detectors
Method
Object detection set prediction loss
DETR首先根据object query生成一个固定数量(文中N = 100)的bounding box,到这里其实和之前proposal或anchors似乎差不多,但有一个很重要的方法:DETR中认为一个object只会出现在一个bounding box中,因此使用一对一的匹配方式,所以直接使用匈牙利算法(scipy包里的linear_sum_assignment函数计算)就可以得到最佳匹配,而避免了nms过程。
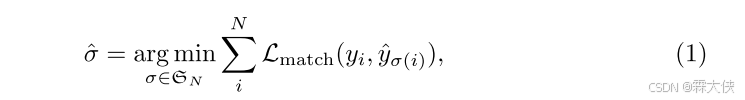
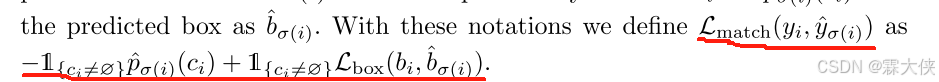
- 别预测错误:预测类别与真实类别不匹配的惩罚。
- 边界框误差:预测框与真实框之间的重叠度(通过0种损失函数计算)
代码:

Experiments
Encoder:可以把实例很清楚的分开

Decoder:
可以看出Encoder的作用主要是将object尽量分开,而Decoder则负责将每个object边缘较难部分进行处理,Object query看出每一个query都负责图片中的一部分检测,同时也学习到COCO数据集的一个pattern。
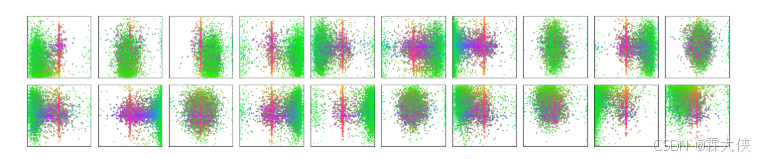
Object query:绿色的点代表小的bounding box,红色的点代表大的横向的bounding box,蓝色的点代表竖向的大的bounding box,跟anchor有些像,anchor是提前定义好了bounding box,最后把预测跟提前定好的bounding box做对比,而object query是一个可以学习的东西,每一次给他一个图片,都会问左下角有没有比较小的物体呀,有没有看到中间大的横向的物体呀之类的问题,这100个query就像100个问问题的人一样,每个人都有自己问问题的方式,