写CUDA,追求的就是加速比,想要得到准确的时间,计时函数就是必不可少
计时通常分为两种情况:
1)直接得到接口函数的时间,一般用于得到加速比;
2)获得接口函数内核函数、内存拷贝函数等所耗时间,一般用于优化代码时。
情况(1)方法有两种,CPU计时函数和GPU计时函数。
情况(2)有三种工具nsight,nvvp,nvprof
本博客会详细介绍情况(1)的两种方法;情况(2)nsight不会用,简单介绍一下nvvp和nvprof的用法。
1 CPU计时函数
在利用CPU计时函数时,要考虑的一个问题是:核函数的执行是异步执行的,所以必须加上核函数同步函数,才能得到准确的时间。但是实际上CPU记时的时间是超过核函数实际调用时间的,下文会具体分析。
CPU示例代码如下:
#include <sys/time.h>
double cpuSecond()
{struct timeval tp;gettimeofday(&tp,NULL);return((double)tp.tv_sec+(double)tp.tv_usec*1e-6);
}
gettimeofday是linux下的一个库函数,创建一个cpu计时器,从1970年1月1日0点以来到现在的秒数,需要头文件sys/time.h
那么我们使用这个函数测试核函数运行时间,示例代码如下:
#include <cuda_runtime.h>
#include <stdio.h>
#include "freshman.h"__global__ void sumArraysGPU(float*a,float*b,float*res,int N)
{int i=blockIdx.x*blockDim.x+threadIdx.x;if(i < N)res[i]=a[i]+b[i];
}
int main(int argc,char **argv)
{// set up device.....// init data ......//timerdouble iStart,iElaps;iStart=cpuSecond();sumArraysGPU<<<grid,block>>>(a_d,b_d,res_d,nElem);cudaDeviceSynchronize();iElaps=cpuSecond()-iStart;// ......
}
主要分析计时这段,首先iStart是cpuSecond返回一个秒数,接着执行核函数,核函数开始执行后马上返回主机线程,所以我们必须要加一个同步函数等待核函数执行完毕,如果不加这个同步函数,那么测试的时间是从调用核函数,到核函数返回给主机线程的时间段,而不是核函数的执行时间,加上了cudaDeviceSynchronize();,函数后,计时是从调用核函数开始,到核函数执行完并返回给主机的时间段,下面图大致描述了执行过程的不同时间节点:
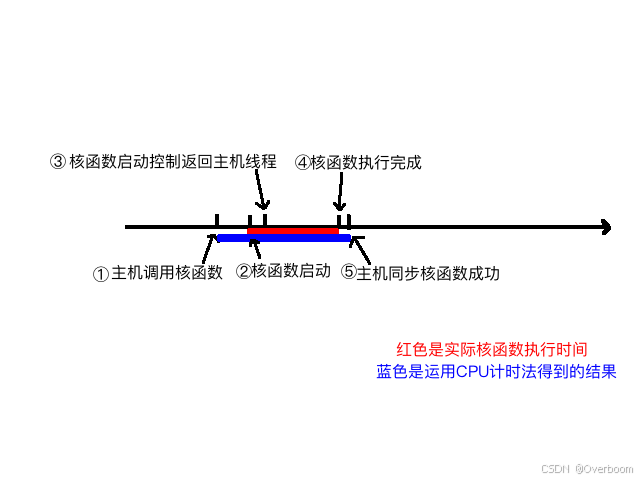
我们可以大概分析下核函数启动到结束的过程:
1 主机线程启动核函数
2 核函数启动成功
3 控制返回主机线程
4 核函数执行完成
5 主机同步函数侦测到核函数执行完
我们要测试的是2-4的时间,但是用CPU计时方法,只能测试1~5的时间,所以测试得到的时间偏长。
2 GPU记时函数
GPU计时函数就不需要考虑同步问题,直接用计时事件函数就可以了,示例代码如下:
cudaEvent_t start, stop;
float elapsedTime = 0.0;cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);function(argument list);;cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);cudaEventElapsedTime(&elapsedTime, start, stop);cout << elapsedTime << endl;cudaEventDestroy(start);
cudaEventDestroy(stop);
如何获得精确的计时
正常情况下,第一次执行核函数的时间会比第二次慢一些。这是因为GPU在第一次计算时需要warmup。所以想要第一次核函数的执行时间是不精确的。获得精确的计时我总结为三种,如下:
1 循环执行一百次所需要计时的部分,求平均值,将第一次的误差缩小100倍。这种方法的优点是简单粗暴。但缺点也很明显:(1)程序的执行时间大大增长,特别是比较大的程序(2)要考虑内存溢出问题,C++的内存需要程序猿自己手动管理。写出执行一次不出内存溢出问题的程序很容易,但是写出循环执行一百次而不出内存溢出问题的代码就有一定难度了(3)计时不是特别准确,虽然误差已经被缩小了100倍。
2 在计时之前先执行一个warmup函数,warmup函数随便写,比如我从cuda sample里的vectoradd作为warmup函数。这种方法的优点是程序执行时间缩短;缺点是需要在程序中添加一个函数,而且因为GPU乱序并行的执行方式,核函数的两次执行时间并不能完全保持一样。所以推荐使用方法3.
3 先执行warmup函数,在循环10遍计时部分。
3 用nvprog记时
CUDA 5.0后有一个工具叫做nvprof的命令行分析工具,后面还要介绍一个图形化的工具,现在我们来学习一下nvprof,学习工具主要技巧是学习工具的功能,当你掌握了一个工具的全部功能,那就是学习成功了。
nvprof的用法如下:
$ nvprof [nvprof_args] <application>[application_args]

工具不仅给出了kernel执行的时间,比例,还有其他cuda函数的执行时间,可以看出核函数执行时间只有4%左右,其他内存分配,内存拷贝占了大部分事件,nvprof给出的核函数执行时间2.1011ms,上面cpuSecond计时结果是2.282ms
可见,nvprof可能更接近真实值。
nvprof这个强大的工具给了我们优化的目标,分析数据可以得出我们重点工作要集中在哪部分。





