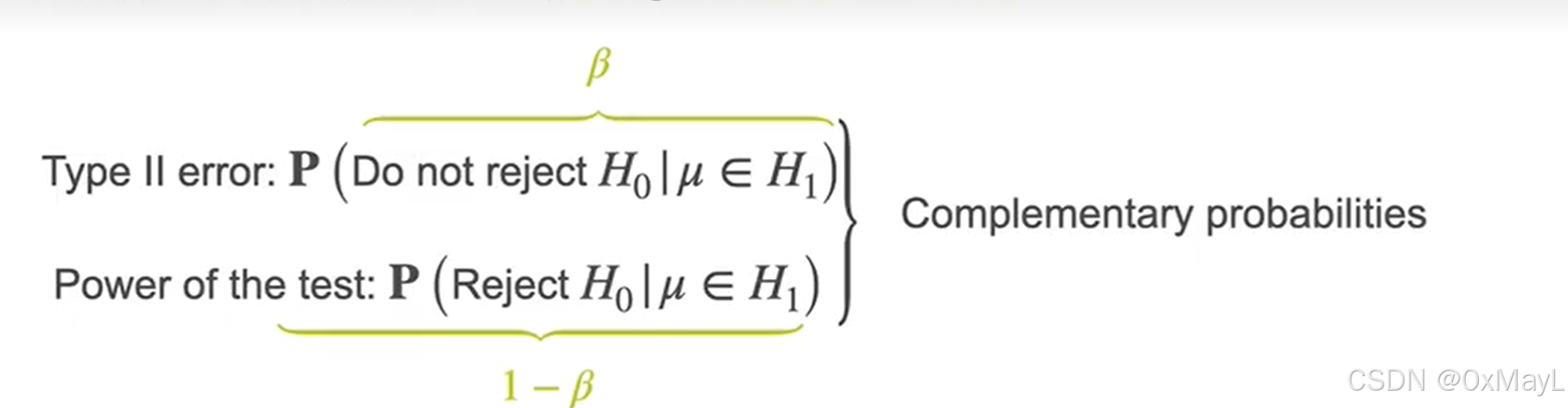概率论
概率基础
这部分太简单,直接略过
条件概率
独立性
独立事件A和B的交集如下

非独立事件
非独立事件A和B的交集如下

贝叶斯定理
先验 事件 后验
在概率论和统计学中,先验概率和后验概率是贝叶斯统计的核心概念
简单来说后验概率就是结合了先验概率的前提和新事件的信息

自然贝叶斯
自然贝叶斯就是在有多个先验的前提下,假设它们相互独立,利用公式算出来的近似概率

贝叶斯与机器学习
-
条件概率生成像素

-
条件概率识别图像

概率分布
随机变量
随机变量分为离散型随机变量和连续型随机变量
区别如下

两个分布函数
适用离散型随机变量

适用连续性随机变量
概率分布
纵坐标都是概率密度函数,面积才是概率,且总面积为1
伯努利分布和二项分布的区别在于二项分布中事件发生的概率带有二项式系数
概率密度函数在一个范围[a,b]为定值

μ和σ的几何意义:μ是对称中心,σ是标准差,直接决定曲线的高度和形状

箱型图
箱线图也称箱须图、箱形图、盒图,用于反映数据的离散程度,倾斜程度
主要由Q1,Q2,Q3百分位数组成,

QQ图
定义
分位数-分位数图是通过比较两个概率分布的分位数对这两个概率分布进行比较的概率图方法
横坐标是理论正态概率分布的百分数,纵坐标是数据概率分布的百分数

具体定义如下

统计意义
- 比较数据是否符合正态分布
- 越接近直线越可能是正态分布
边缘分布
将高维度密度分布降低至低纬度密度分布
离散型随机变量
*唯一公式

体现在联合分布的散点图上

连续性随机变量
本质是散点图+概率密度绘制成三维图像上的一个横截面,公式与离散型完全一致

条件分布
两个随机变量的条件分布
公式:本质上是条件概率
- 离散型随机变量


- 连续型随机变量

几何意义:横截面只是上式的分母

协方差
公式
对于数据集来收,概率分布为恒定值;对于随机变量来说,公式要变成加权的形式


统计意义
协方差为正或负说明数据集之间有正相关或负相关的关系,接近0说明数据集几乎没有关系
协方差矩阵
对角线上都是变量的方差,其他都是两个变量之间的协方差

相关系数
就是把协方差标准化的结果

数理统计
总体和样本的统计属性
样本的方差
这种结果更接近总体真实的方差

大数定理
大数定律揭示了随着样本量 𝑛 的增加,样本均值将越来越接近总体的期望值
中心极限定理
中心极限定理(Central Limit Theorem,CLT)是概率论和统计学中的一个重要定理,它描述了在一定条件下,独立同分布随机变量的和(或均值)趋近于正态分布的性质。具体来说,中心极限定理表明,当样本量足够大时,任何分布的独立同分布随机变量的均值的分布都将接近于正态分布,不论这些变量的原始分布是什么。
直接应用
因为中心极限定理告诉我们当n->∞+,二者的均值是一致的,
也可以用来估计方差随着样本的变化趋势

中心极限定理表明,当 n 足够大时,均值的标准化形式将收敛于标准正态分布
可以用于假设检验等这些要求正态分布的情况

点估计-最大似然估计MLE
最大似然估计(Maximum Likelihood Estimation,MLE)是一种用于估计统计模型参数的方法。最大似然估计通过找到使得观测数据出现的概率最大的参数值,来估计模型参数。
说人话就是已知某个数据集,想要计算某个模型的参数,只需要令各个数据在这个模型(概率密度/分布函数)中的概率乘积(等价于出现可能性)最大,就可以通过求导找出零点解出参数值
伯努利估计
- 随机变量只有两个取值
取对数求极值
最终大概率:实际出现值的平均值


高斯函数估计
记得提前将数据标准化
基本同理:也是最大化点在正态分布曲线上的概率

线性回归
你的模型就是一条直线,现在讨论的时让数据集尽可能接近你的直线,利用垂直的高斯函数,最大化概率计算直线的参数

假设都是用的标准高斯函数进行概率模拟
等价于最小化这些平方误差

正则化
正则化(Regularization)是一种用于防止机器学习模型过拟合的技术。过拟合是指模型在训练数据上表现良好,但在新数据(测试集)上表现不佳,即模型过于复杂,以至于捕捉了训练数据中的噪音和细节,无法很好地推广到新的数据。正则化通过在损失函数中增加一个惩罚项,限制模型的复杂度,从而提高模型的泛化能力。
常见正则化方法:L2-正则化
多项式拟合中,多项式系数的平方之和组成惩罚项

正则项
L2-正则化误差乘以正则化参数

贝叶斯统计
贝叶斯公式:信念,先验和后验
贝叶斯统计将概率解释为对不确定事件的主观信念或信念程度。它通过更新这种信念来进行统计推断。
- 贝叶斯公式的进一步解释

- 离散和连续分布的贝叶斯公式

最大化后验概率 MAP
其实就是更新后的后验概率分布中取一个最大值,最大化你的信念

贝叶斯统计的特点
先验很大程度上影响着后验
没有任何信息的先验,均匀分布的PDF函数的最大后验就是MLE
如果有充分数据,MLE和MAP估计是一样的

三者的关系
模型的总损失=模型本身的损失·MLE估计的损失+正则化损失
模型损失
多项式模型的系数分布在正太分布曲线上之积最小化

条件概率:MLE估计
就是模型生成的点与目标函数的差在正态分布曲线上的概率最大值

正则项损失

置信区间
显著性水平α
样本落在置信区间外的概率
z-score
Z-score是一种标准化的数据度量,仅仅适用于正态分布中
Z-score表示一个数据点距离其所在数据集均值的标准差倍数。
Z 分数用于衡量一个观测值在其分布中的相对位置,能够帮助识别数据点的异常程度以及进行不同数据集之间的比较。
计算公式

- Z分数与显著性水平的关系
z相关于显著性水平α的的值通过查表获得


置信区间的计算公式
怎么来的:将均值标准化后根据置信水平确定Z值,然后还原为随机变量X-bar即可
在标准差准确的情况下,均值的分布一定是正态分布,根据中心极限定理

- 边际误差的计算

t分布-当标准差未知的情况
当使用样本的标准差时,均值的分布不是一个正态分布,而是一个t分布
t分布有一个自由度=样本数N-1,自由度越大,均值分布越接近于正态分布,
当自由度趋于30时,t分布与正态分布基本一致

t-统计量
与z-score定义类似,就是标准化后与均值的偏差
计算方式也是查表:需要哪个显著性水平α就差对应的t

概率的置信区间计算
P-hat是抽样的概率,概率的置信区间与样本均值的置信区间计算公式一致,都是±边际误差

假设检验
零假设和备择假设
零假设一般是否定你想要验证的结论:例如P不成立
备择假设一般选为你想要验证的结论:例如P成立
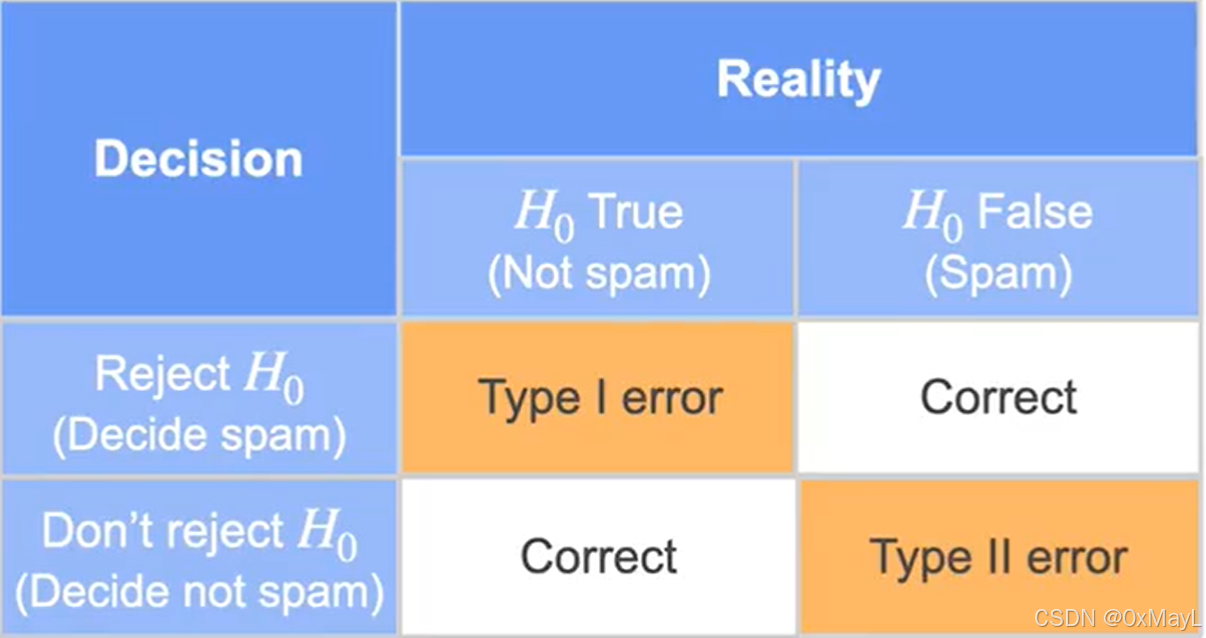
第一类错误和第二类错误
第一类错误:我是对的,但是被拒绝了
第二类错误:我是错的,但是被接受了
第一类错误明显严重于第二类错误
第一类错误和第二类错误是互补的关系:

显著性水平α的定义
第一类错误发生的最大概率
α直接决定你是否应该拒绝你的假设

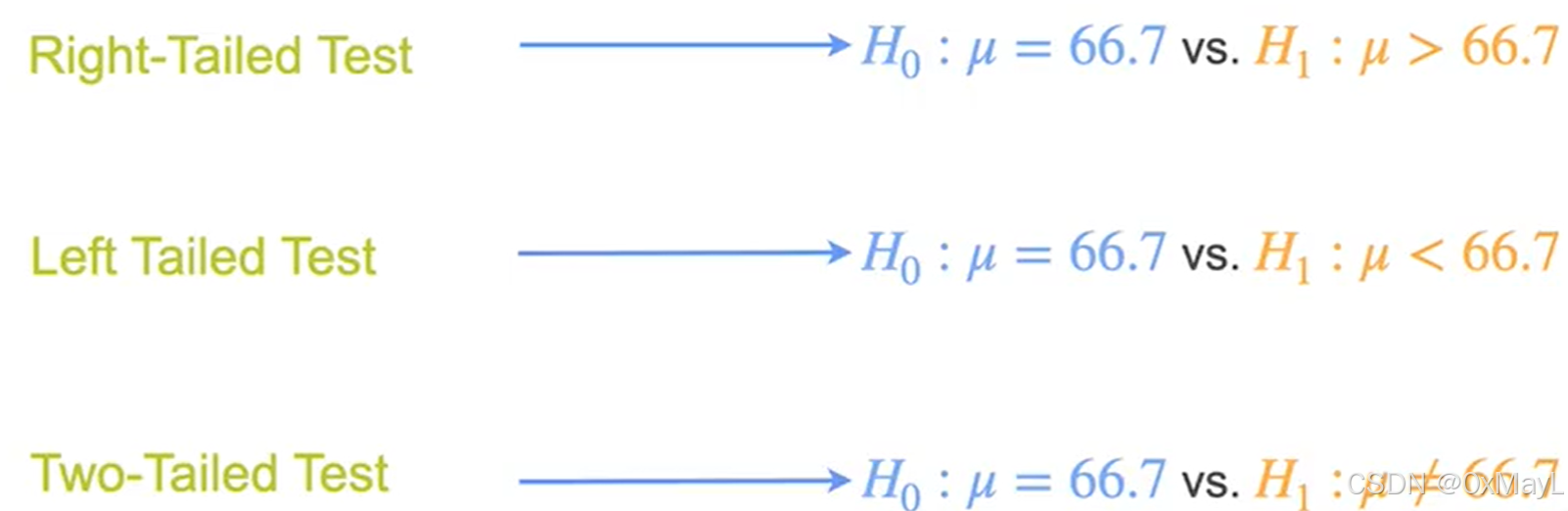
三种假设的形式
双尾和单尾假设
你的备择假设与零假设的大小关系,确定了假设的形式
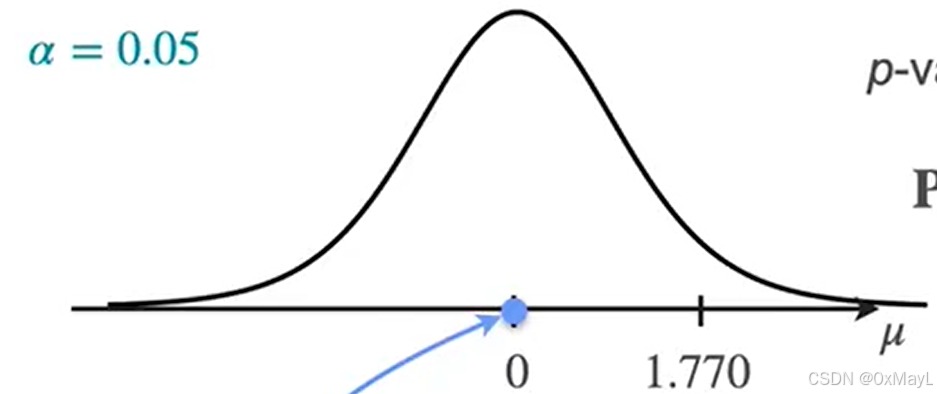
p值
p值的定义
其实就是第一类错误发生的概率,结合了三种基本的假设
决定规则
α作为第一类错误最大发生的概率,是一个阈值,如果大于α是不可以容忍的,也就是不能拒绝零假设,否则可以拒绝零假设
p值作为实际第一类错误发生的概率,与α作比较,就可以判定是否应该拒绝零假设


临界值k
k是一个百分数
k对应三种检验形式,图像上可以拒绝零假设的临界值
注意双尾检验,k=α/2 or k=1-α/2;

β和检验功效
β就是第二类错误发生的概率
检验功效与β互补,是拒绝零假设且备择假设成立的概率