2022年5月,谷歌DeepMind发布了可应用于多领域的通用智能体Gato;2023年6月,其又推出应用于机器人领域的多具身形态、多任务通用智能体RoboCat;
从命名逻辑来看,Gato 在西班牙语中意为 “猫”,这一命名暗含双关隐喻 —— 比如,猫通常被认为是灵活、适应性强的动物,这可能与 Gato 作为通用智能体的特性相关。而 RoboCat 可直译 “机器猫” ,从命名方式上可以看出,RoboCat不仅延续了 “猫” 的意象符号,更直接暗示了Gato 与RoboCat在技术上的传承脉络。事实上,RoboCat 确实继承了 Gato 的通用 Transformer 架构,但在任务侧重、数据使用以及模型优化方面又存在着明显的差异化。
-
任务侧重:Gato 是面向跨领域的多模态、多任务、多具身的通用智能体,涉及到的任务领域广泛,包括图像注释、聊天、玩游戏、控制机械臂等;而RoboCat 则专注于机器人操控场景,通过 “目标条件学习” 和 “自我改进闭环”,专注解决抓取、装配等精细任务,其泛化能力专为机器人平台迁移设计。
-
数据使用:Gato 的训练数据来源多样,涵盖游戏、图像、文本等多种领域。RoboCat 的训练数据更侧重于机器人操作相关的数据,涵盖400万个机器人操作片段,数据直接来源于真实机器人实验和模拟环境,覆盖抓取、放置、装配等基础操作。同时,它还能够通过“自我完善” 的方式来进一步丰富训练数据,通过不断收集和利用新的数据来优化模型。
-
模型优化:Gato作为通用模型,虽在多模态处理上表现出色,但缺乏针对机器人控制的专门设计,导致其在少样本泛化和跨平台适应上存在显著短板。RoboCat 在得到预训练模型后,针对新任务或新机器人平台,只需采集少量示教数据对预训练模型做微调,就能展示出对新任务和不同构型机器人的泛化能力。
通用智能体Gato
2022年5月,DeepMind发布通用具身智能体 Gato。它是一个集多模态、多任务、多具身特性于一体的通用智能体,其核心架构采用了包含 11.8 亿参数的Transformer序列模型。
核心设计:
-
继承LLM的Transformer序列建模范式,通过将跨模态数据序列化(图像分块、动作离散化)扩展至物理交互领域;基于广泛的多模态数据训练(涵盖图像、文本、本体状态感知、关节扭矩、按钮操作等),赋予模型对离散/连续观测与动作的泛化处理能力。
-
通过使用一组具有相同权重的单一神经网络,可处理不同具身形态(如机械臂、仿生机器人)的多源传感数据,实现跨场景感知与动作生成。

通用智能体Gato可适配不同具身形态
1. 基础模型训练数据
1)控制任务数据(占比 85.3%):包含游戏交互(如Atari游戏按键序列)、机器人操作(真实机械臂关节力矩、本体状态感知数据)以及导航与规划任务(如Meta-World中的机械臂操控、BabyAI中的3D导航)。这些数据主要来自模拟环境(如MuJoCo、DM Control Suite)和真实机器人平台(如Sawyer机械臂)的轨迹记录,总计覆盖596项任务,占训练数据总量的85.3%。
2)视觉与语言数据(占比 14.7%):整合了纯文本语料(对话、网页文本)、图像数据(如ImageNet)及图文配对信息(图像描述任务)。此类数据用于支持图像字幕生成、文本对话等能力,但占比显著低于控制任务。
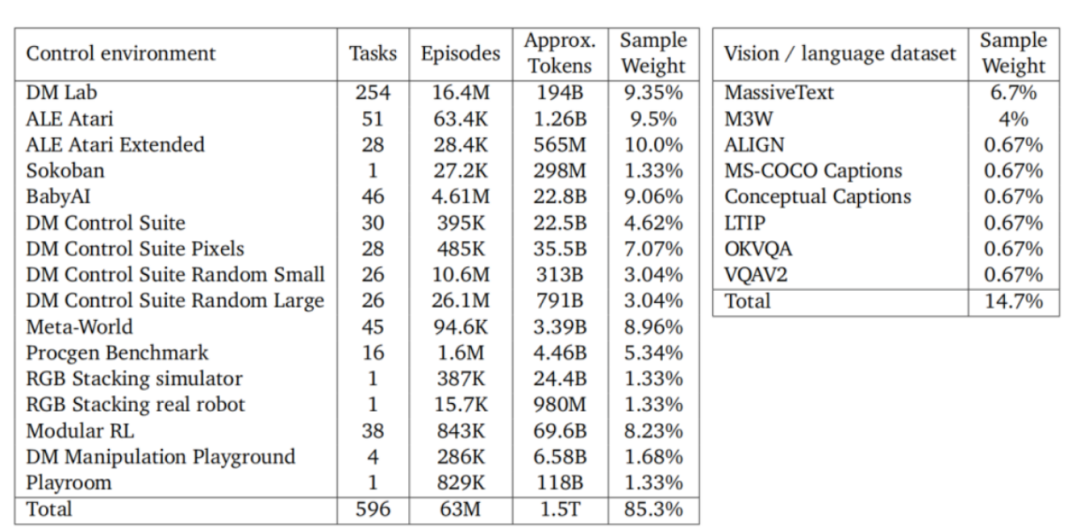
Gato模型训练所使用数据集
2. 模型的训练与部署
1)训练阶段
来自不同任务和模态的数据被序列化为一个扁平的 Token 序列,分批处理后由 Transformer 神经网络处理。通过掩码机制,损失函数仅应用于目标输出(即文本和各种动作)。

Gato训练阶段示意图
2)部署阶段
采样的 Tokens 会根据上下文组合成对话回复、图像字幕、按钮操作或其他动作。Gato 使用自回归生成控制策略,预测 t+1 的编码并反解码为动作,与环境交互。

将Gato部署为策略的过程示意图
3. Gato —— 迈向AGI的关键一步
Gato 首次提出 “通才智能体(Generalist Agent)”概念,将 AI研究从“任务特定优化”转向“跨多任务统一建模”。
1)方法论革新:扩展LLM的“预训练+微调”范式至物理交互场景,通过数据序列化(图像分块、动作离散化等)实现多模态统一处理,首次验证Transformer在低维连续控制任务(如机械臂操作)中的潜力,但未突破其短期记忆瓶颈。例如,Gato在物理任务中依赖专家演示数据,且未解决长期记忆问题(上下文窗口仅1024 tokens)。
2)AGI路径探索:通过参数缩放实验(79M→364M→1.18B)验证模型规模、数据多样性与多任务泛化能力的正相关性,为通用模型研发提供实证依据;但后续研究表明,单纯扩大规模难以提升专业化能力,需结合“通专融合”架构解决任务可持续性问题。
Gato验证并实现了跨模态统一建模,将计算机视觉(CV)、自然语言处理(NLP)和机器人控制等不同模态数据(如图像、文本、传感器信号、关节力矩)通过统一的Transformer 序列模型进行处理。
-
数据序列化:所有模态数据被转化为Token序列(如文本通过SentencePiece编码,图像分割为 16x16 图块,连续状态和动作通过标量离散化),形成统一输入空间;
-
模型参数共享:同一套11.8 亿参数的模型可同时处理视觉识别、语言对话、机器人操作等任务,避免了传统方法为每个任务单独设计模型的冗余;
-
动态决策:模型基于输入序列的上下文自回归地预测下一个Token,该Token可以自动对应到不同的输出模态(如生成文本回复、游戏按键或机械臂控制指令),实现跨模态无缝交互。
总而言之,Gato在跨模态整合、任务通用性上的突破,被学界视为迈向通用人工智能的关键一步。
4. Gato的局限性
有业内相关专家指出,Gato模型的最大价值之一是将强化学习、计算机视觉与自然语言处理三大领域深度融合。尽管技术路径上借鉴了既有框架,但能将图像、文本与机器控制等不同模态数据映射至同一表征空间,并用同一套模型参数实现统一表达,已实属难得。
但是,Gato总体上依然是数据驱动的方式,且并没有在训练分布外的任务上获得较好效果。同时,训练数据总体上偏向游戏和机器人控制任务,采用有监督的离线训练方式,依赖专家数据,未充分利用强化学习的核心机制——奖励信号和在线交互。例如,其机器人控制任务的成功依赖预训练的专家轨迹,而非通过实时奖励优化策略。
这一局限性在后续模型RoboCat中通过自我改进循环(Self-Improvement Loop)得到部分解决。
通用智能体RoboCat
2023年6月,谷歌Deep Mind推出多具身形态、多任务通用智能体RoboCat——一种基于视觉目标条件的决策Transformer,可处理动作标注的视觉经验数据,能够通过自身生成的数据进行训练迭代实现自我改进。
1. 对Gato 的继承和创新
RoboCat直接沿用了Gato的多模态Transformer架构作为基础,将视觉、语言、动作数据统一处理为离散token序列。这一设计被认为是DeepMind在通用智能体Gato的技术路线上的延续。
另外,在Gato基础上,RoboCat针对机器人任务强化了以下能力:
1)动作输出适配:RoboCat 针对机器人任务的动作头扩展并非简单的维度调整,而是通过动态动作空间映射实现的深度优化。
-
多自由度兼容设计:动作头支持混合动作表示,可同时处理离散动作(如按键)和连续动作(如关节力矩);引入动作头参数共享机制,即不同机械臂的动作头共享底层Transformer 参数,但通过任务特定的适配器(Adapter)实现自由度差异的动态适配。
-
硬件无关的控制接口:通过统一动作语义空间实现跨机械臂迁移。例如,抓取动作在不同机械臂中被抽象为"闭合夹具" 的语义指令,动作头根据当前机械臂的自由度自动生成具体的关节角度序列。另外,引入动作空间正则化技术:在训练阶段,通过对抗训练使动作头输出分布与机械臂物理约束对齐,避免生成超出关节极限的动作。
2)目标条件策略:RoboCat 的目标图像输入通道并非简单的输入扩展,而是构建了端到端的视觉 - 动作闭环。
-
目标图像的多模态融合:目标图像通过预训练的VQ-GAN 编码器转化为 token 序列,并与当前观测图像 token、动作 token、任务描述 token 共同输入 Transformer;引入目标-观测注意力机制:Transformer 在处理序列时,会动态计算目标图像 token 与当前观测 token 的相关性,优先关注需要调整的区域。
-
闭环控制的实时性优化:采用时序目标对齐技术,将目标图像分解为时间序列token,并与当前动作序列token 进行时序对齐训练;引入失败补偿机制 —— 当动作执行未达到目标时,模型会自动生成补偿动作。
2. 自我改进闭环学习机制
研究实验表明,RoboCat既能零样本泛化到新任务与新形态机器人,也可仅通过100-1000个目标任务样本的微调,快速适配到不同的新任务,包括新机器人具身、未见过的行为、物体和感知变体(光照/视角等感知条件变化),以及从仿真模拟到真实的迁移。
此外,训练后的模型自身可生成数据用于后续训练迭代,从而构建自我改进闭环学习机制 —— 研究人员使用多样化的训练数据集来训练该通用智能体的初始版本,该版本可通过100-1000 次演示数据微调至适配新任务,随后部署到真实机器人上,为这些任务生成更多数据。生成的新数据将被添加到训练数据集中,用于RoboCat的下一迭代版本训练,这种机制在一定程度上突破了传统机器人依赖真机数据的局限,使模型能持续进化变成可能。
如下图所示,RoboCat通过自我改进闭环流程持续提升智能体能力——增强其跨任务迁移性、通过微调扩展适配任务范围,并在现有任务中实现性能突破。

RoboCat自我改进闭环流程机制
3. 基础模型训练数据
RoboCat 的训练数据集聚焦于视觉目标条件下的机器人操作任务,且针对性覆盖了多形态硬件和复杂场景,包含400 万次机器人操作片段,涵盖物体分拣、工具使用、导航等多样化场景。
-
多具身形态适配:数据来自4 种不同类型的真实机器人(如 Sawyer、Panda 机械臂)及模拟环境,包含不同自由度、观察空间和动作规范的操作序列。
-
任务多样性覆盖:训练数据覆盖253 项基础任务及 141 项变体,涉及精密装配(如齿轮插入、积木堆叠等)、基础操作类(如抓取指定物体、分拣水果等)等场景。
4. RoboCat的局限性
在具身智能领域,机器人面临的最大挑战是如何像人类一样快速适应新任务与环境。RoboCat首次在通用机器人领域实现了“学习-实践-进化”的完整闭环,为破解这一难题提供了全新路径。
这一突破性技术通过在模拟与真实环境中融合跨机器人经验,结合生成式人工智能的自我数据增强能力,显著降低了新技能学习所需的人类演示数据量。然而,在动态环境适应性、跨本体泛化效率等方面仍存在明显局限。
1)动态环境应对不足:物理建模深度的不够
RoboCat在静态桌面操作(如抓取固定物体、堆叠积木)中表现出色,但面对动态交互场景时性能急剧下降。例如在抓取滚动球体任务中,其成功率不足30%,远低于工业场景要求的95%+的可靠性标准。这本质上是世界模型缺失的体现。与人类基于物理直觉预判行为后果不同,RoboCat仅建立“图像-动作”的统计关联,缺乏对“力-运动-形变”因果链的内在表征。当环境变量超出训练集分布时(如地面材质由木质变为金属),模型无法通过物理推理调整策略,导致跨场景泛化崩溃。
2)硬件适配的柔性瓶颈:本体特化与通用性的两难
虽然RoboCat支持跨机械臂迁移,但其适配效率仍受限于本体动力学特性差异。当新硬件与训练集机械臂存在显著动力学差异时,微调成本剧增。这些问题暴露了跨本体适配的“表面泛化”特性:模型可适应外形相似、自由度相近的机械臂,但对动力学特性迥异的系统,仍需近乎重训级的深度调整。





