目录
案例1:GRUB引导故障
案例2:文件系统只读故障
案例3:OOM Killer触发
案例4:系统启动卡住(initramfs损坏)
案例5:磁盘空间耗尽
案例6:SSH登录缓慢
案例7:逻辑卷无法扩展
案例8:内核模块冲突
案例9:NTP时间不同步
案例10:SELinux导致服务异常
案例11、root密码遗忘
前言:
此篇是故障排查,想要模拟的话,先把虚拟机用快照或OVF保存下来
案例1:GRUB引导故障
故障现象: 系统启动卡在"GRUB>"提示符,无法进入系统 原因分析:
-
GRUB配置文件损坏(/boot/grub/grub.cfg)
-
引导文件被误删或磁盘损坏 解决步骤:
-
在GRUB命令行依次执行:
insmod xfs set root=‘hd0,msdos1’linux16 /vmlinuz-3.10.0-1160.el7.x86_64 root=/dev/mapper/centos-root ro rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb initrd16 /initramfs-3.10.0-1160.el7.x86_64.img boot -
进入系统后执行:
grub2-mkconfig -o /boot/grub2/grub.cfg
实操:
具体解决思路:进入grub操作界面手动引导,加载xfs文件驱动,设置从哪个地方找它的系统文件,加载内核和加载内存文件系统
做之前先备份
[root@bogon ~]# df -Th
文件系统 类型 容量 已用 可用 已用% 挂载点
devtmpfs devtmpfs 894M 0 894M 0% /dev
tmpfs tmpfs 910M 0 910M 0% /dev/shm
tmpfs tmpfs 910M 11M 900M 2% /run
tmpfs tmpfs 910M 0 910M 0% /sys/fs/cgroup
/dev/mapper/centos-root xfs 50G 4.2G 46G 9% /
/dev/mapper/centos-home xfs 147G 33M 147G 1% /home
/dev/sda1 xfs 1014M 185M 830M 19% /boot
tmpfs tmpfs 182M 24K 182M 1% /run/user/0
[root@bogon ~]# dd if=/dev/mapper/centos-root of=/opt/root.bak bs=512 count=1
记录了1+0 的读入
记录了1+0 的写出
512字节(512 B)已复制,0.00100117 秒,511 kB/秒
[root@bogon ~]# dd if=/dev/mapper/centos-home of=/opt/root.bak bs=512 count=1
记录了1+0 的读入
记录了1+0 的写出
512字节(512 B)已复制,0.00217275 秒,236 kB/秒
[root@bogon ~]# dd if=/dev/sda1 of=/opt/root.bak bs=512 count=1
记录了1+0 的读入
记录了1+0 的写出
512字节(512 B)已复制,0.00227063 秒,225 kB/秒
当然也可以用xfs_dum做备份或者用tar打包
tar zcvf gurb.cfg.bak.tar.gz grub.cfg
进入实战:
1.前往boot/grub里删掉grub.cfg 然后重启
[root@bogon ~]# cd /boot/grub2
[root@bogon grub2]# ls
device.map fonts grub.cfg grubenv i386-pc locale
[root@bogon grub2]# rm -rf grub.cfg
[root@bogon grub2]# reboot
2.进入grub页面操作,输入命令
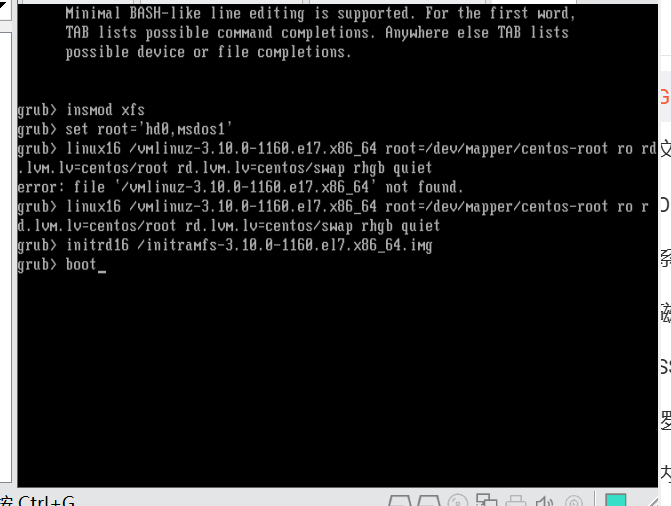
注意:只能手输,所以一定要仔细,不要输错了
3.boot回车后回到系统cd /boot/grub2下使用grub2-mkconfig -o /boot/grub2/grub.cfg重新生成grub.cfg文件
[root@bogon ~]# cd /boot/grub2
[root@bogon grub2]# ls
device.map fonts grubenv i386-pc locale
[root@bogon grub2]# grub2-mkconfig -o /boot/grub2/grub.cfg
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-3.10.0-1160.el7.x86_64
Found initrd image: /boot/initramfs-3.10.0-1160.el7.x86_64.img
Found linux image: /boot/vmlinuz-0-rescue-a44733bca4fb4567bebe8f80d6c9583b
Found initrd image: /boot/initramfs-0-rescue-a44733bca4fb4567bebe8f80d6c9583b.img
done
[root@bogon grub2]# ls
device.map fonts grub.cfg grubenv i386-pc locale
4.重启验证,完成
案例2:文件系统只读故障
故障现象: 无法创建文件,提示"Read-only file system" 排查过程:
-
dmesg | grep -i error发现磁盘I/O错误 -
smartctl -a /dev/sda检查磁盘健康状态 解决方案: -
卸载分区:
umount /dev/sda1 -
强制修复:
fsck -y /dev/sda1或 xfs文件系统: xfs_repair/dev/sda1 -
重新挂载:
mount -a实战:
1.分析,只读故障有最常见有两种情况
1.挂载选项写错 2.文件系统损坏
哦,当然还有一种可能,写入的是光盘,光盘是无法写入的
2.第一次挂载上光盘就会出现Read-only file system
[root@bogon ~]# mount /dev/sr0 /mnt/ mount: /mnt: WARNING: device write-protected, mounted read-only.3.光盘的挂载一定是只读的,光盘默认是不可写的(只读文件系统)
[root@bogon ~]# cd /mnt/ [root@bogon mnt]# mkdir aaa mkdir: 无法创建目录 “aaa”: 只读文件系统注:操作之前要先挂载光盘镜像
4.检查
(1)dmesg 查看当前文件系统的启动时挂载情况
[root@bogon ~]# dmesg [ 0.000000] Initializing cgroup subsys cpuset [ 0.000000] Initializing cgroup subsys cpu [ 0.000000] Initializing cgroup subsys cpuacct [ 0.000000] Linux version 3.10.0-1160.el7.x86_64 (mockbuild@kbuilder.bsys.centos.org) (gcc version 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC) ) #1 SMP Mon Oct 19 16:18:59 UTC 2020(2)grep -i 查看有没有错误(因为有的系统不同大小写不一样),整个系统加载都会显示出来,都是内存地址
[root@bogon ~]# dmesg | grep -i error [ 12.771582] BERT: Boot Error Record Table support is disabled. Enable it by using bert_enable as kernel parameter.
案例3:OOM Killer触发
故障现象: 关键进程突然被终止,系统日志出现"Killed process" 分析工具:
-
grep -i 'killed process' /var/log/messages -
free -h查看内存使用情况 -
vmstat 1监控内存交换如果free在减小,那就是内存问题 -
进入top查看
-
优化方案:
-
调整oom_score_adj:
echo -100 > /proc/[PID]/oom_score_adj -
修改sysctl.conf:
vm.overcommit_memory = 2 vm.overcommit_ratio = 80
实战:
1.查看对应日志,系统触发,一定出现在系统日志中 /var/log/messages
[root@bogon ~]# grep -i 'killed process' /var/log/messages
2.查看内存使用情况,是否是满的,很少是按照G为单位显示大小,都是以KB为单位,有些内存比较小,整个地方剩的不够就成0了。查看free剩没有剩下,是否为0,是0则表示占满内存故内存不足,一定是OOM Killer触发
[root@bogon ~]# free -htotal used free shared buff/cache available
Mem: 1.9G 820M 534M 12M 624M 998M
Swap: 2.0G 0B 2.0G
[root@bogon ~]# free -mtotal used free shared buff/cache available
Mem: 1980 820 534 12 624 998
Swap: 2047 0 2047
3.使用vmstat 1 作内存交换监控,如果发现free这边的数一直在减小,有一个进程一定占内存比较高
[root@bogon ~]# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st2 0 0 547380 16828 623180 0 0 192 5 146 208 3 4 93 0 00 0 0 547008 16828 623212 0 0 0 0 166 219 3 4 93 0 00 0 0 547008 16828 623216 0 0 0 0 77 118 1 0 99 0 00 0 0 547008 16828 623216 0 0 0 0 63 105 0 0 100 0 00 0 0 546984 16828 623216 0 0 0 8 233 210 5 7 88 0 00 0 0 547008 16828 623216 0 0 0 0 59 100 0 0 100 0 00 0 0 547008 16828 623216 0 0 0 0 72 121 1 0 99 0 00 0 0 547008 16828 623216 0 0 0 0 69 117 0 0 100 0 00 0 0 547008 16828 623216 0 0 0 0 65 108 1 0 99 0 0
当占用内存高怎么办? top命令 按P键或者M键 内存显示 查看%MEM那个占用的最高并且是不是当前系统运行的bl进程或应用程序运行的bl进程
top - 23:22:38 up 57 min, 3 users, load average: 0.01, 0.05, 0.07
Tasks: 280 total, 2 running, 277 sleeping, 1 stopped, 0 zombie
%Cpu(s): 0.7 us, 0.3 sy, 0.0 ni, 98.7 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
KiB Mem : 2027868 total, 545992 free, 841816 used, 640060 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 1021412 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 870 root 20 0 295564 5284 4036 S 0.3 0.3 0:13.00 vmtoolsd 1340 root 20 0 574288 17488 6144 S 0.3 0.9 0:01.62 tuned 6212 root 20 0 0 0 0 S 0.3 0.0 0:00.43 kworker/0+ 6570 root 20 0 162232 2396 1580 R 0.3 0.1 0:00.08 top 1 root 20 0 128384 7004 4184 S 0.0 0.3 0:10.03 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.05 kthreadd 4 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0+ 6 root 20 0 0 0 0 S 0.0 0.0 0:00.74 ksoftirqd+ 7 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration+ 8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh 9 root 20 0 0 0 0 R 0.0 0.0 0:04.14 rcu_sched 10 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 lru-add-d+ 11 root rt 0 0 0 0 S 0.0 0.0 0:00.18 watchdog/0 13 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kdevtmpfs
优化:
1.每个启动进程都在/proc下,都有PID对应的 数字 都是PID,找到指定PID找该进程 -100把优先级调低 让OOM Killer不杀它,oom_score_adj里默认都是0,不杀本身进程,但里面每个都有不同的机制,调整优先级,调低
[root@bogon proc]# ls
1 2018 2371 2534 30 355 386 60 783 914 locks
10 2056 2373 2539 31 356 387 605 785 96 mdstat
11 2059 2382 2542 32 357 388 620 787 acpi meminfo
1276 2072 2383 2545 322 358 389 6212 798 asound misc
13 2078 2386 2548 323 359 390 6496 799 buddyinfo modules
1340 2087 2388 2556 325 360 391 6570 8 bus mounts
1343 2088 2390 2571 33 361 4 662 814 cgroups mpt
1345 21 2391 2600 3319 362 41 6625 815 cmdline mtrr
1347 2115 2396 2614 332 363 43 663 817 consoles net
1349 2119 2398 2616 333 364 44 664 818 cpuinfo pagetypeinfo
1364 2124 2399 2628 334 365 45 665 821 crypto partitions
..
2.优化加固 优化是指优化方面的,加固是指安全方面的
3.集群模式,想要整个服务提供的可用性更高,一定要部署集群模式而且对集群的相关组件再次进行优化和加固,整体大系统更稳定。
如何屏蔽OOM Killer:不建议屏蔽太多,不禁止,禁止该机制会造成系统崩溃。
案例4:系统启动卡住(initramfs损坏)
故障现象: 启动时卡在"Loading initial ramdisk" 紧急处理:
-
进入救援模式(trouble shooting)使用rescue a centos system
-
选择第一项
-
重建initramfs:
chroot /mnt/sysimage dracut -f /boot/initramfs-$(uname -r).img $(uname -r) exit reboot
4.假如之前调整了bios启动顺序,需要还原成Hard Drive
实战:
(1)先模拟故障,cd /boot/下 ,里面有内存文件系统加载的映像文件:initramfs-3.10.0-1160.el7.x86_64.img 移走到 /opt/中,重启,就读取不到,硬盘就找不到。
[root@localhost ~]# cd /boot/
[root@localhost boot]# ls
config-3.10.0-1160.el7.x86_64
efi
grub
grub2
initramfs-0-rescue-a44733bca4fb4567bebe8f80d6c9583b.img
initramfs-3.10.0-1160.el7.x86_64.img
initramfs-3.10.0-1160.el7.x86_64kdump.img
symvers-3.10.0-1160.el7.x86_64.gz
System.map-3.10.0-1160.el7.x86_64
vmlinuz-0-rescue-a44733bca4fb4567bebe8f80d6c9583b
vmlinuz-3.10.0-1160.el7.x86_64
(2)重启后发现直接报error:file '/initramfs-4.18.0-553.el8_10.x86_64.img' not found,找不到对应信息,就会卡住,不接收任何软件指令,退不出去。
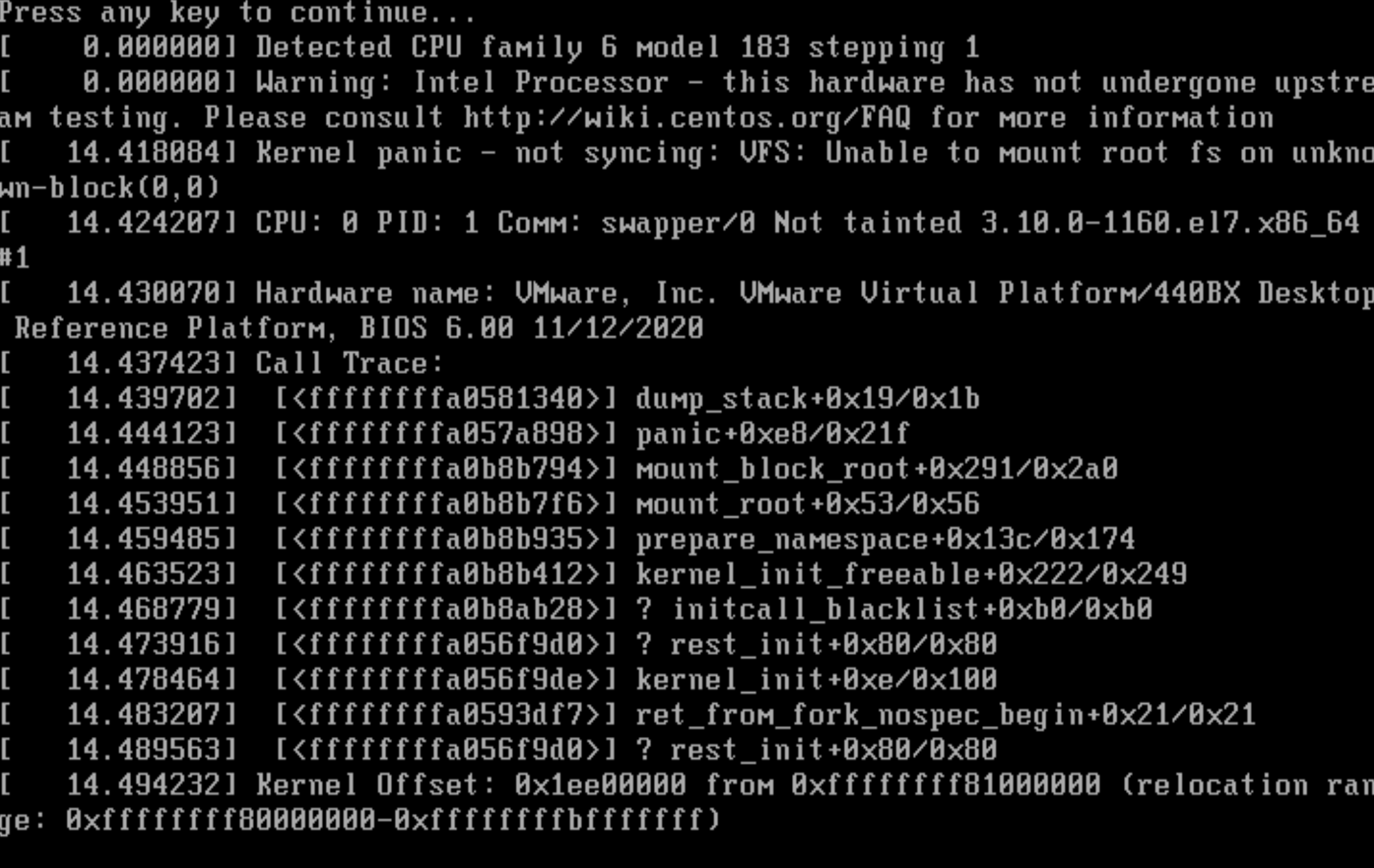
(3)开始解决,进入救援模式虚拟机:使用镜像,因当前本地文件系统肯定进不去;
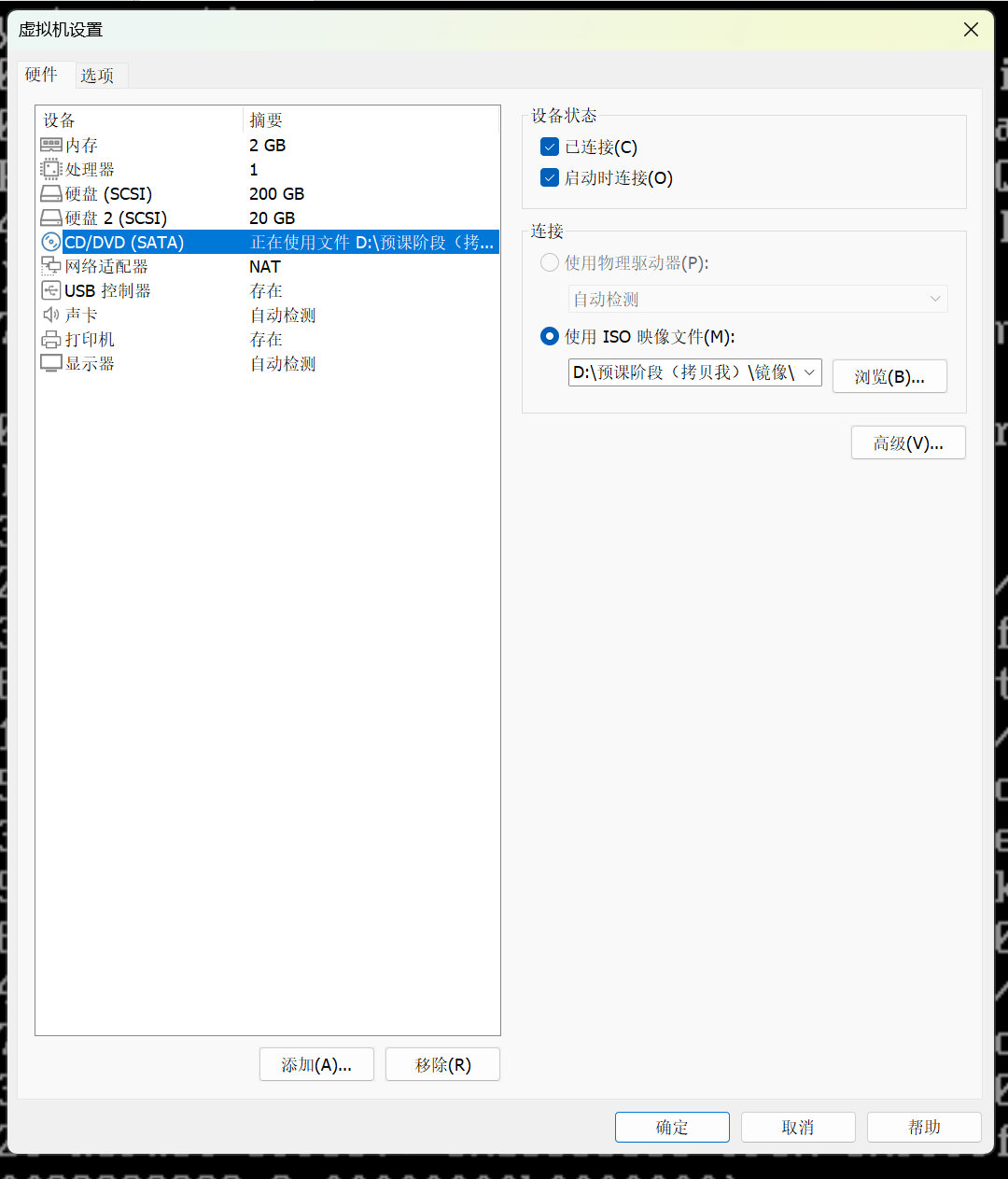
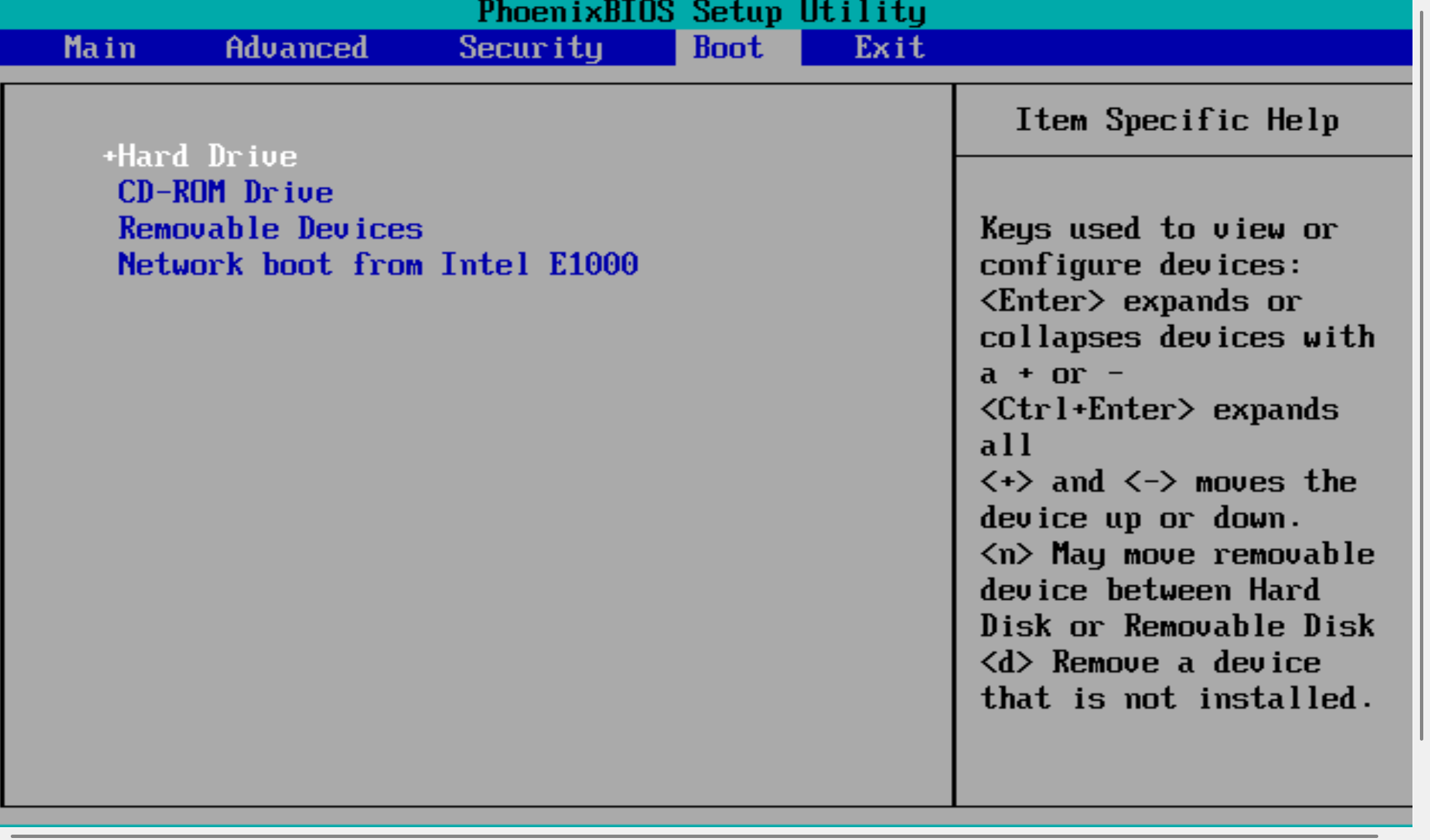
(2) 导完镜像后重启,按F2键进入bios界面,切换到Boot将 CD-ROM Drive 调整到第一启动项 进入到光盘,F10保存退出,重启
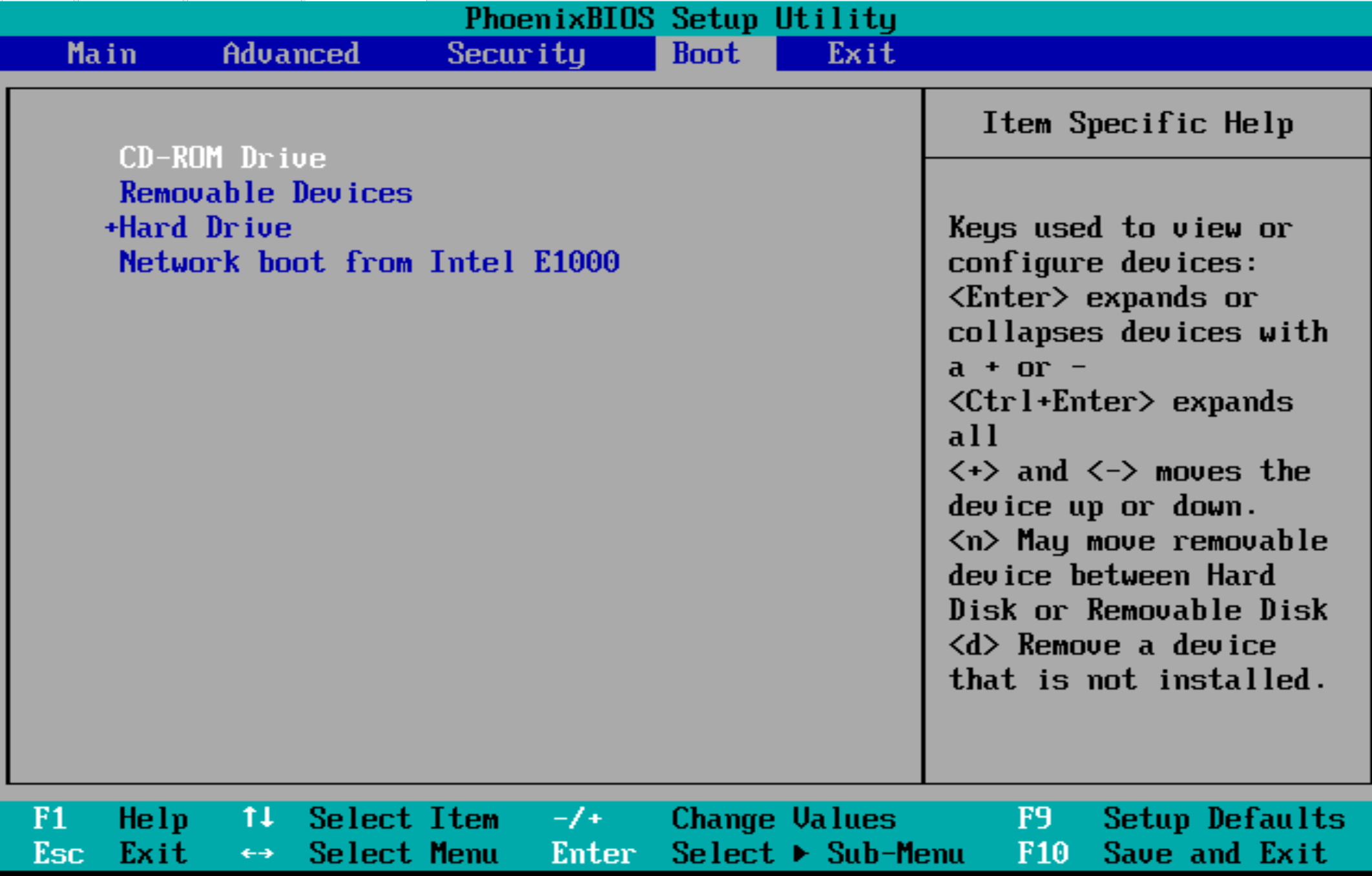
(3) 进入Troubleshooting,选择第二项 进入Rescue a Centos system 修复一个centos系统
(4)进入修复模式之后,有四个选项 选择1)continue 继续 其实就是进入live CD 模式,会进入一个特殊的shell模式下,进入的就是加载到内存中的一个操作系统,回车进入到:sh-4.2#内存里的新操作系统。
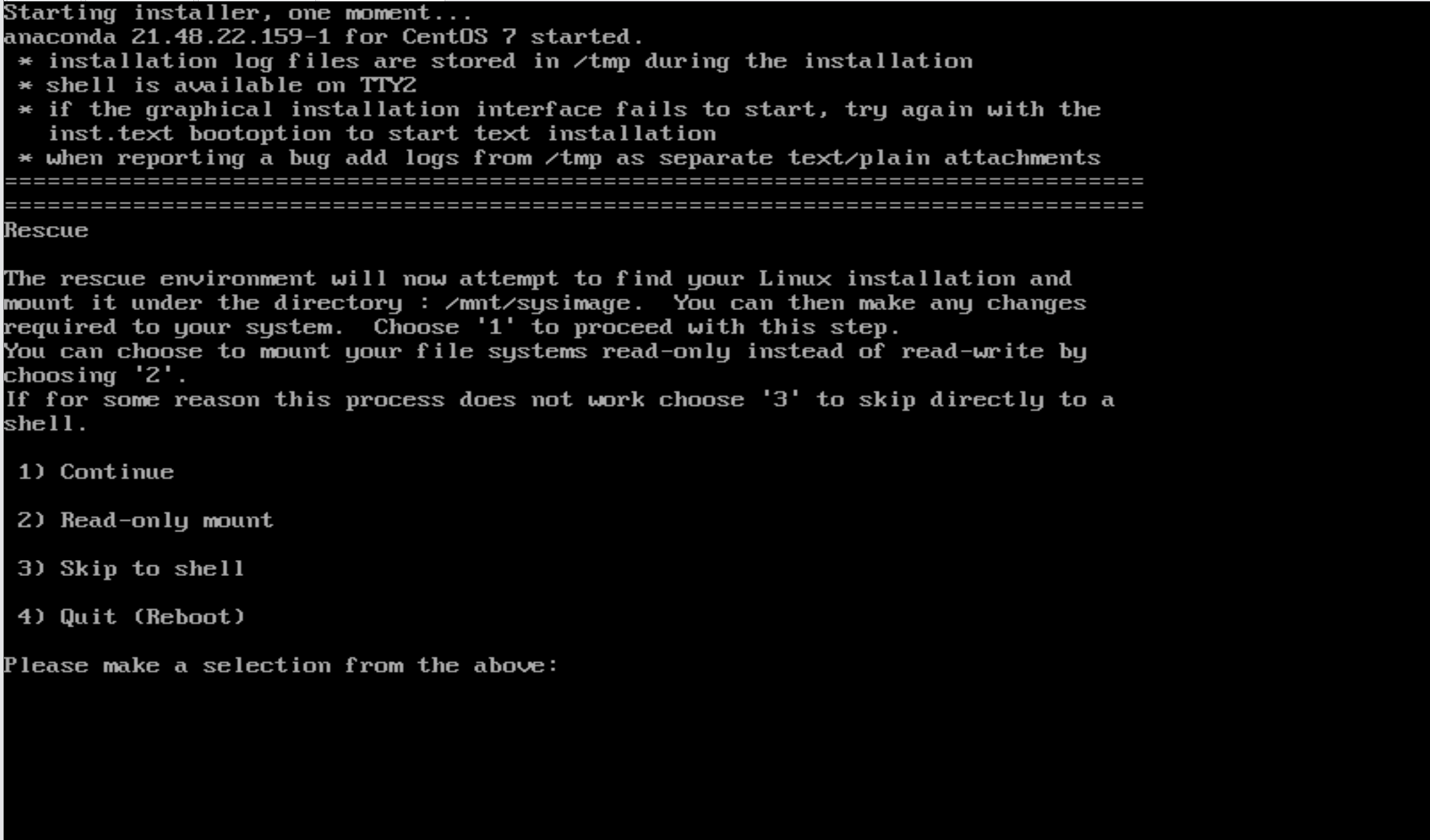
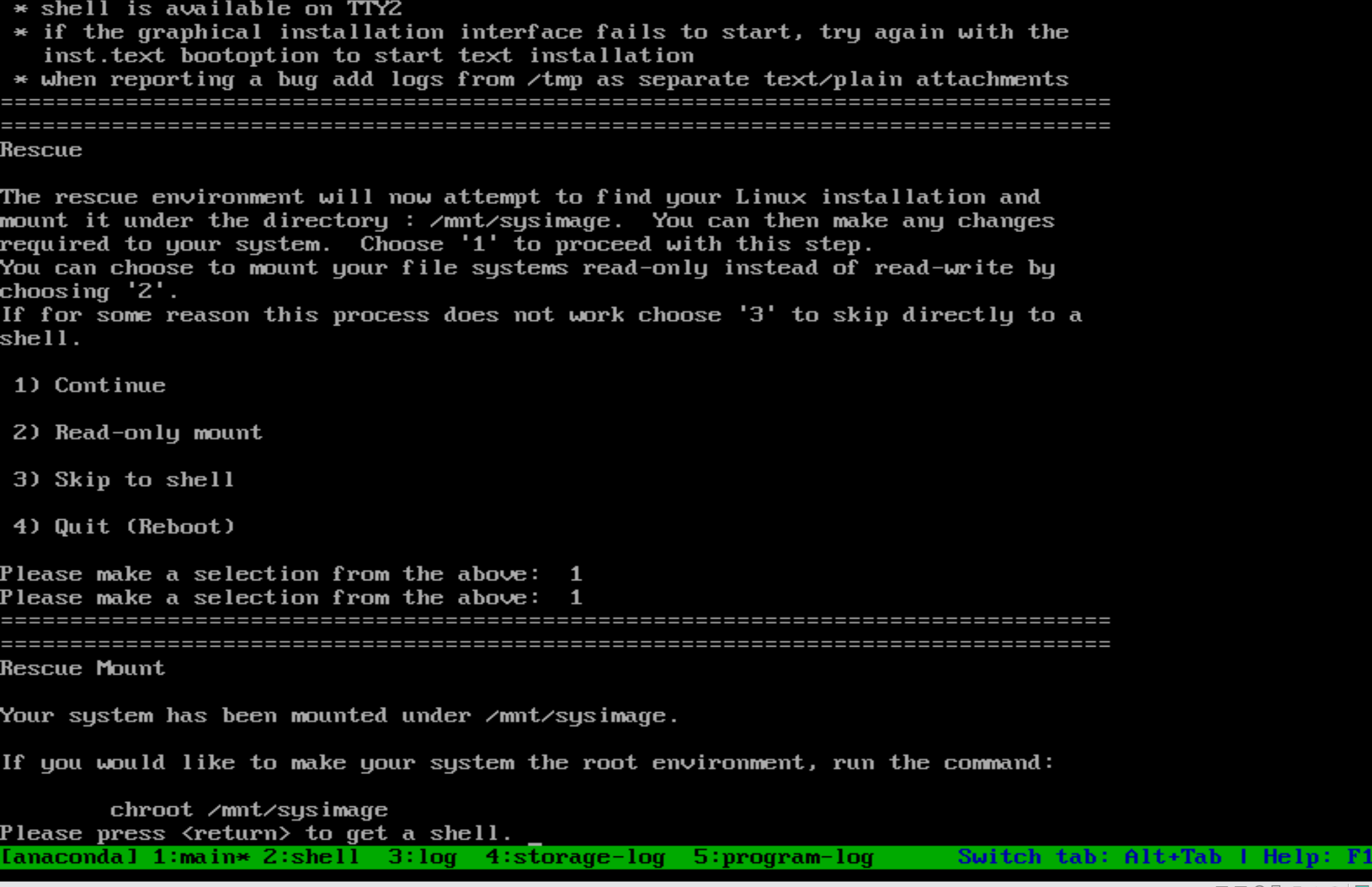
5) cd /boot/ 查看到对应的映像文件没有,如果是移走 要么移回来,要么使用dracut -f /boot/initramfs-$(uname -r).img $(uname -r) 进行生成对应的文件系统,生成完毕后 ls 查看确认生成有这个文件后initramfs-4.18.0-553.el8_10.x86_64.img,然后exit退出bash环境,进行重启。
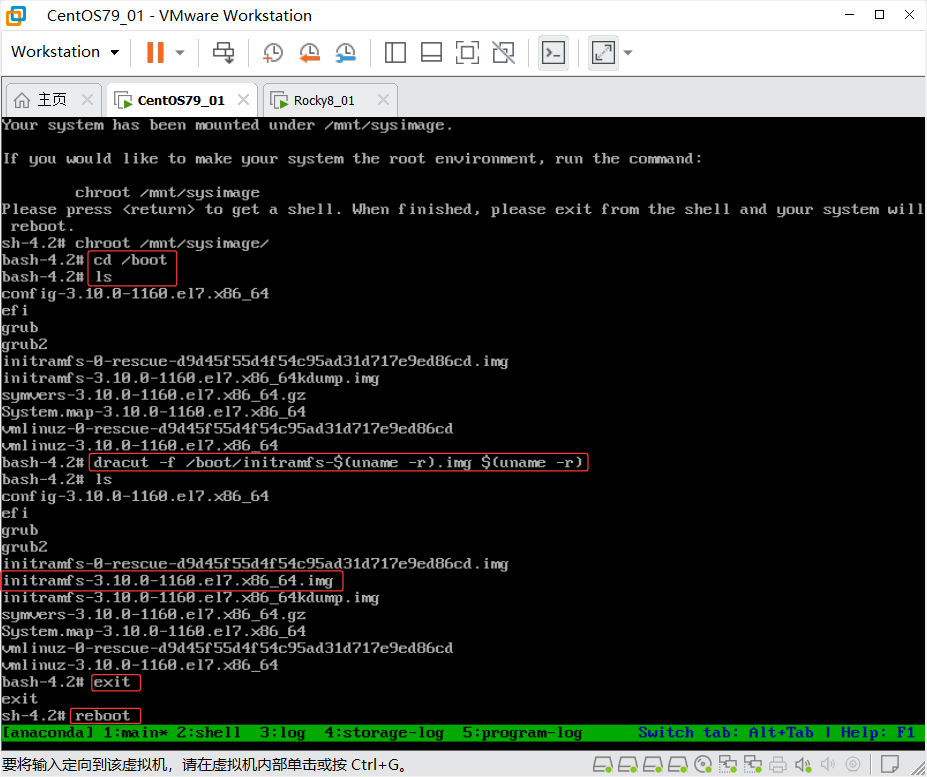
6)最后进bios,切换到 Boot 把前面调整的第一启动项调整回Hard Drive,F10保存退出后查看启动正常
案例5:磁盘空间耗尽
故障现象: 服务异常,df显示使用率100% 快速定位:
-
lsof -n | grep deleted查找未释放空间的进程 -
du -xh --max-depth=1 / | sort -hr定位大文件 典型场景:
-
/var/log/journal 日志膨胀:
journalctl --vacuum-size=100M -
/tmp目录堆积:
rm -rf /tmp/*.tmp实战:
1.首先故障模拟,将磁盘根塞满
[root@bogon ~]# for i in {2..5};do dd if=/dev/zero of=/f$i bs=1024M count=10;done 记录了10+0 的读入 记录了10+0 的写出 10737418240字节(11 GB)已复制,64.6785 秒,166 MB/秒 记录了10+0 的读入 记录了10+0 的写出 10737418240字节(11 GB)已复制,98.4921 秒,109 MB/秒 记录了10+0 的读入 记录了10+0 的写出 10737418240字节(11 GB)已复制,111.612 秒,96.2 MB/秒 dd: 写入"/f5" 出错: 设备上没有空间 记录了6+0 的读入 记录了5+0 的写出 6284574720字节(6.3 GB)已复制,115.466 秒,54.4 MB/秒 [root@bogon ~]# df -h 文件系统 容量 已用 可用 已用% 挂载点 devtmpfs 974M 0 974M 0% /dev tmpfs 991M 0 991M 0% /dev/shm tmpfs 991M 11M 980M 2% /run tmpfs 991M 0 991M 0% /sys/fs/cgroup /dev/mapper/centos-root 50G 50G 2.5M 100% / /dev/sda1 1014M 185M 830M 19% /boot /dev/mapper/centos-home 147G 33M 147G 1% /home tmpfs 199M 20K 199M 1% /run/user/0 [root@bogon ~]# df -h | grep -n "/dev/mapper/centos-root" 6:/dev/mapper/centos-root 50G 50G 2.5M 100% /2.进入到根目录,查找大文件f1,f2,f3,f4,f5
[root@bogon ~]# cd .. [root@bogon /]# du -ah --max-depth 1 153M ./boot 0 ./dev 12K ./home du: 无法访问"./proc/8130/task/8130/fd/3": 没有那个文件或目录 du: 无法访问"./proc/8130/task/8130/fdinfo/3": 没有那个文件或目录 du: 无法访问"./proc/8130/fd/4": 没有那个文件或目录 du: 无法访问"./proc/8130/fdinfo/4": 没有那个文件或目录 0 ./proc 11M ./run 0 ./sys 43M ./etc 5.8M ./root 169M ./var 8.0K ./tmp 3.9G ./usr 0 ./bin 0 ./sbin 0 ./lib 0 ./lib64 0 ./media 0 ./mnt 4.0K ./opt 0 ./srv 0 ./sdb1 10G ./f1 10G ./f2 10G ./f3 10G ./f4 5.9G ./f5 51G .3.删除,解决问题
[root@bogon /]# find ./ -type f -size +5G -exec rm -rf {} \; rm: 无法删除"./proc/kcore": 不允许的操作 find: ‘./proc/8520/task/8520/fdinfo/5’: 没有那个文件或目录 find: ‘./proc/8520/fdinfo/6’: 没有那个文件或目录 [root@bogon /]# ls bin dev home lib64 mnt proc run sdb1 sys usr boot etc lib media opt root sbin srv tmp var [root@bogon /]# cd [root@bogon ~]# df -th df: 未处理文件系统 [root@bogon ~]# df -h 文件系统 容量 已用 可用 已用% 挂载点 devtmpfs 974M 0 974M 0% /dev tmpfs 991M 0 991M 0% /dev/shm tmpfs 991M 11M 980M 2% /run tmpfs 991M 0 991M 0% /sys/fs/cgroup /dev/mapper/centos-root 50G 4.2G 46G 9% / /dev/sda1 1014M 185M 830M 19% /boot /dev/mapper/centos-home 147G 33M 147G 1% /home tmpfs 199M 20K 199M 1% /run/user/0
案例6:SSH登录缓慢
故障现象: SSH连接延迟超过10秒 排查步骤:
-
ssh -vvv user@host查看详细日志 -
检查DNS配置:
UseDNS noin sshd_config -
关闭GSSAPI认证:
GSSAPIAuthentication no -
strace -p [sshd_PID]跟踪系统调用
案例7:逻辑卷无法扩展
故障现象: lvextend后文件系统未扩容 正确操作流程:
lvextend -L +10G /dev/vg01/lv_data
resize2fs /dev/vg01/lv_data # 对ext4文件系统
xfs_growfs /data # 对XFS文件系统
注意事项:
-
确保物理卷有足够空间:
vgs查看Free PE -
在线扩容无需卸载
注意事项:
1.确保物理卷有足够空间:
vgs查看Free PE或vgdisplay[root@bogon ~]# vgdisplay--- Volume group ---VG Name centosSystem ID Format lvm2Metadata Areas 1Metadata Sequence No 4VG Access read/writeVG Status resizableMAX LV 0Cur LV 3Open LV 3Max PV 0Cur PV 1Act PV 1VG Size <199.00 GiBPE Size 4.00 MiBTotal PE 50943Alloc PE / Size 50942 / 198.99 GiBFree PE / Size 1 / 4.00 MiBVG UUID M7NHK2-4BiE-8qfQ-vwWM-dOA2-LjWK-PfpbI1
2.在线扩容无需卸载
案例8:内核模块冲突
故障现象: 系统更新后网卡失效 解决方案:(先用lsmod看网卡模块的名字是什么,我这里是e1000)
-
lsmod | grep e1000查看加载模块 -
modinfo e1000检查模块信息filename: /lib/modules/3.10.0-1160.el7.x86_64/kernel/drivers/net/ethernet
-
rmmod e1000 && modprobe e1000重载驱动 -
回滚驱动:
dnf reinstall kmod-e1000-3.10.0
案例9:NTP时间不同步
故障现象: 日志出现"Clock skew detected"警告 排错流程:
-
ntpq -pn查看时间源状态 -
chronyc sources -v检查chrony同步状态 -
systemctl restart chronyd -
硬件时钟同步:
hwclock --systohc
案例10:SELinux导致服务异常
故障现象: Apache无法访问自定义目录 诊断方法:
-
tail -f /var/log/audit/audit.log | grep httpd -
sealert -a /var/log/audit/audit.log解决方案:
# 临时解决
setenforce 0
# 永久方案
semanage fcontext -a -t httpd_sys_content_t "/webroot(/.*)?"
restorecon -Rv /webroot
案例11、root密码遗忘
在RHEL/CentOS 7及更新版本中,如果忘记root密码,可以通过以下步骤重置(需物理/虚拟控制台访问权限):
方法原理
通过修改GRUB2启动参数进入单用户模式,绕过身份验证直接获取root权限
详细操作步骤
-
重启系统并中断引导
# 当系统启动到GRUB菜单时,快速按下方向键阻止自动引导
# 选择默认内核条目(通常第一条)按 `e` 键进入编辑模式
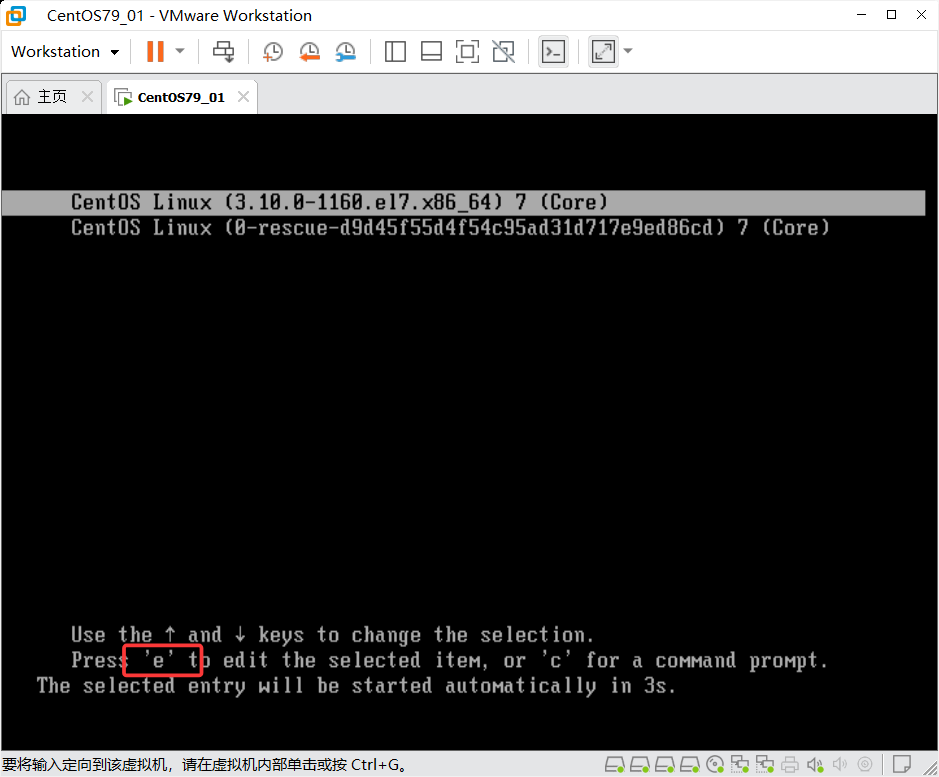
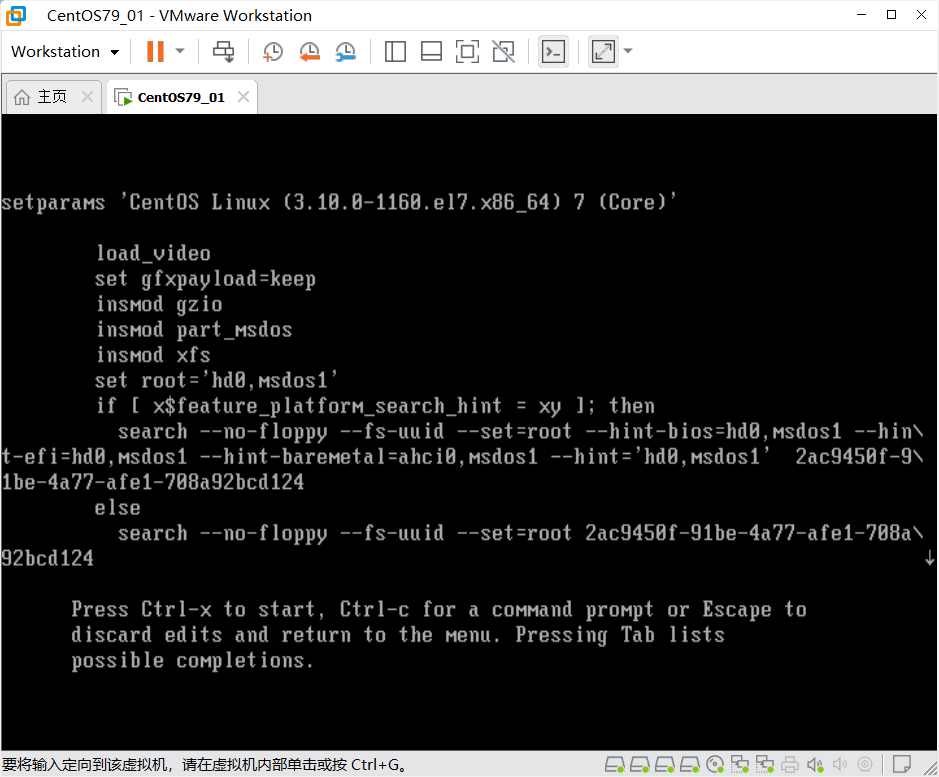
-
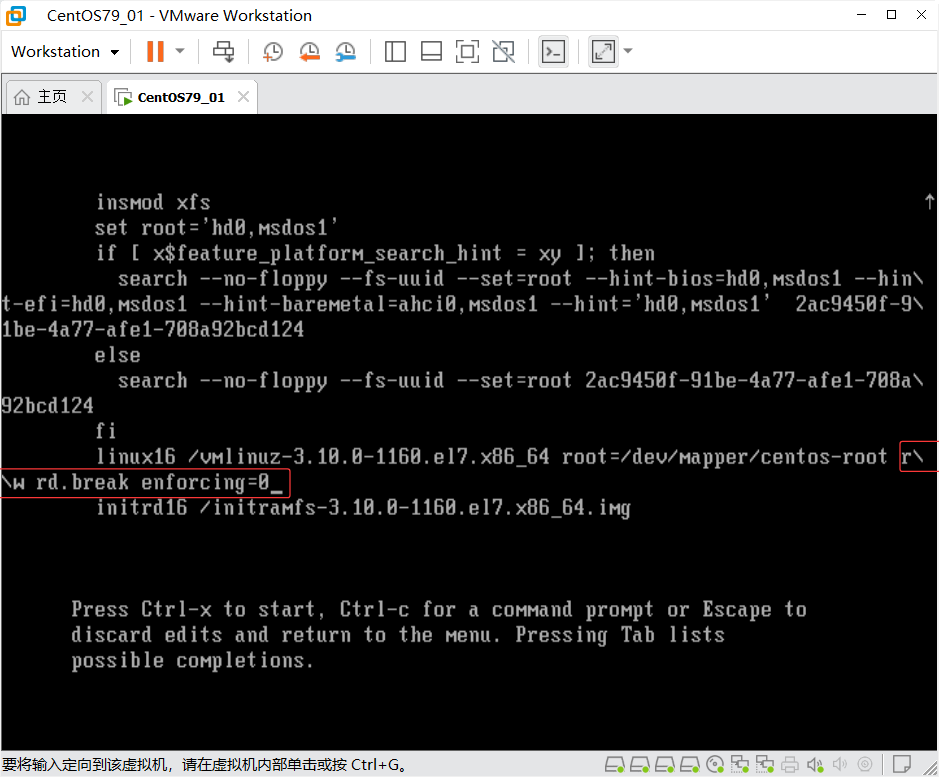
修改内核参数
# 在linux16行(或linux行)末尾追加:
rd.break enforcing=0
# 修改后的完整行示例:
linux16 /vmlinuz-3.10.0-1160.el7.x86_64 root=/dev/mapper/rhel-root rw rd.break enforcing=0
-
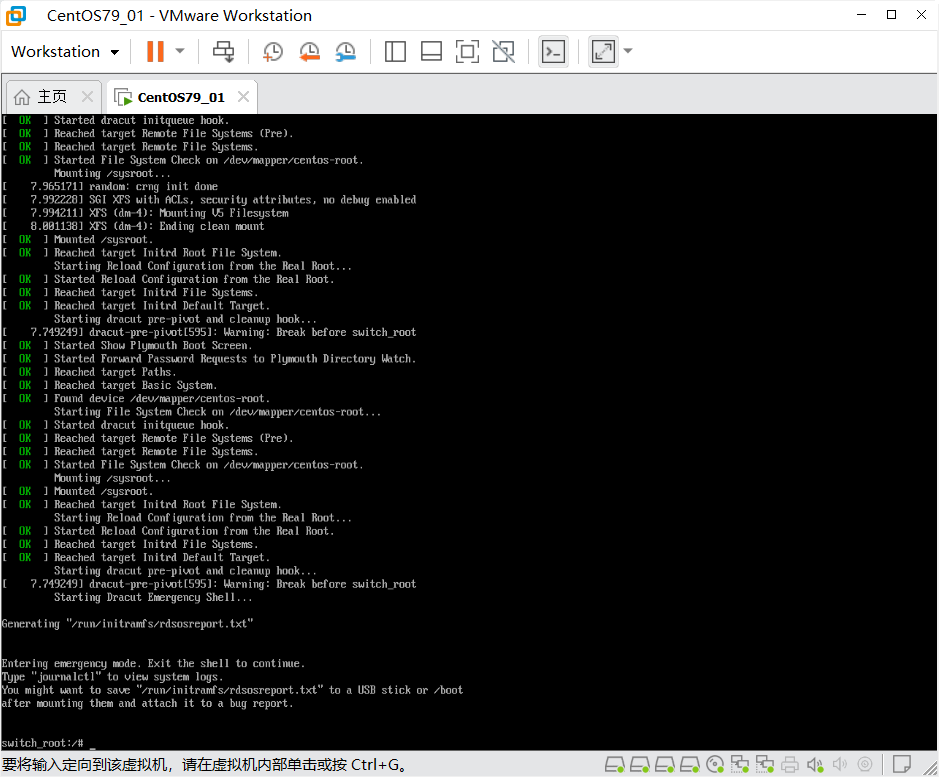
进入紧急模式
# 按 Ctrl+X 启动系统,进入紧急救援模式的shell环境
# 此时文件系统挂载在/sysroot(只读模式)
-
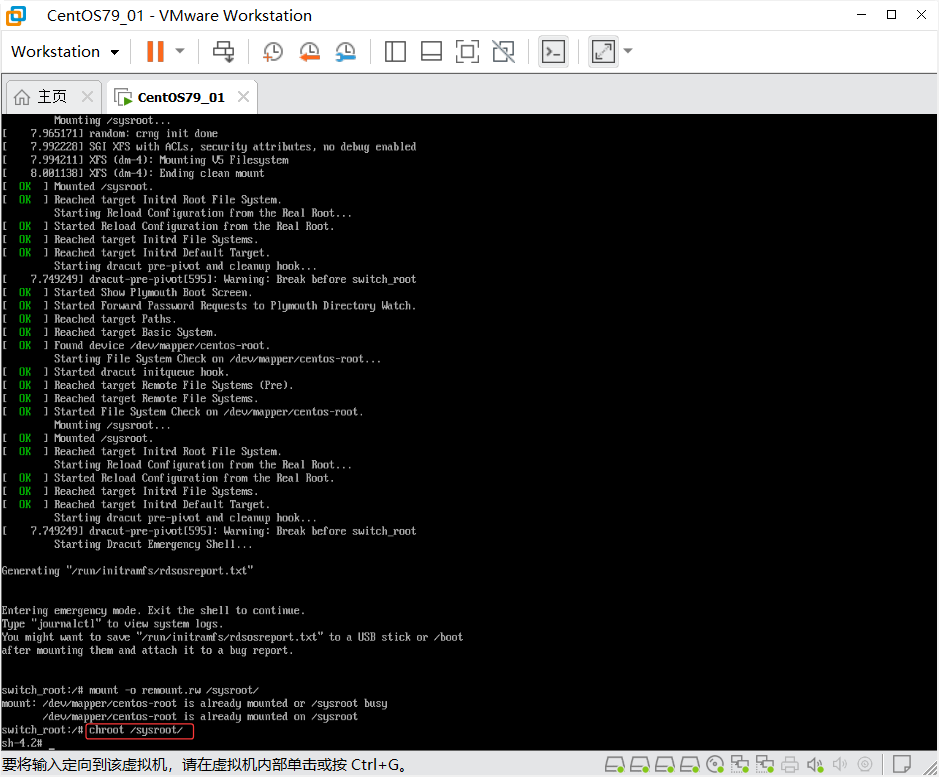
重新挂载文件系统(如果是centos系统,修改内核参数那边改成了rw不是ro,那么这一步不用)
# 重新挂载为读写模式:
mount -o remount,rw /sysroot
-
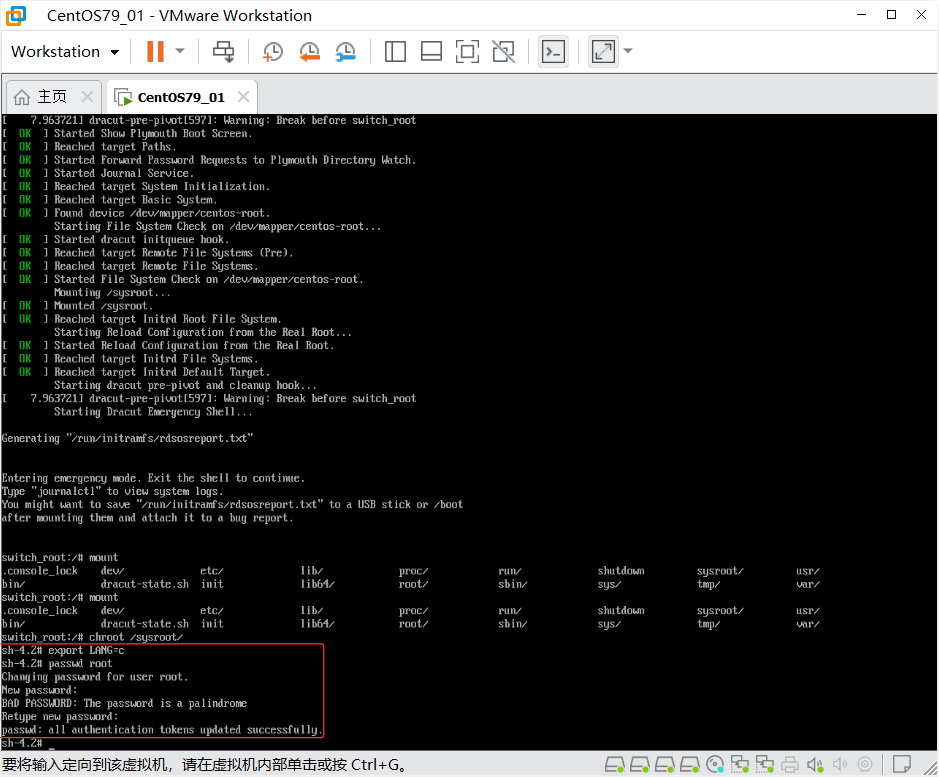
切换根目录
chroot /sysroot
-
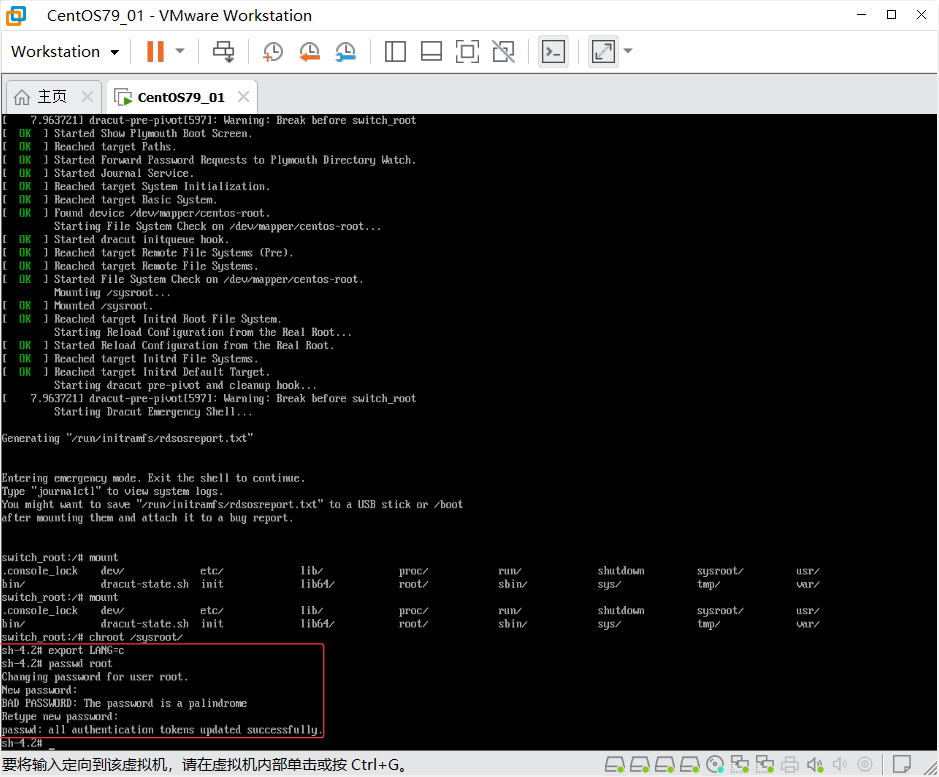
修改root密码
# 此时已获得完整root权限:
passwd root
# 输入新密码两次(不会显示输入内容)
-
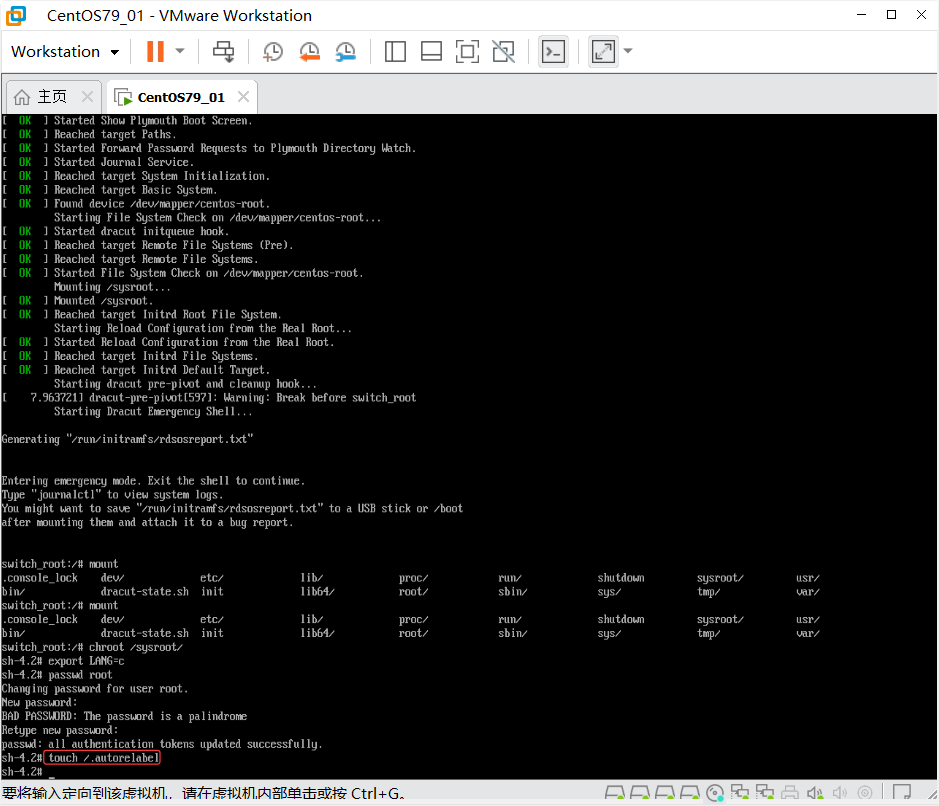
修复SELinux上下文
# 强制重新标记文件系统(重要!):
touch /.autorelabel
-
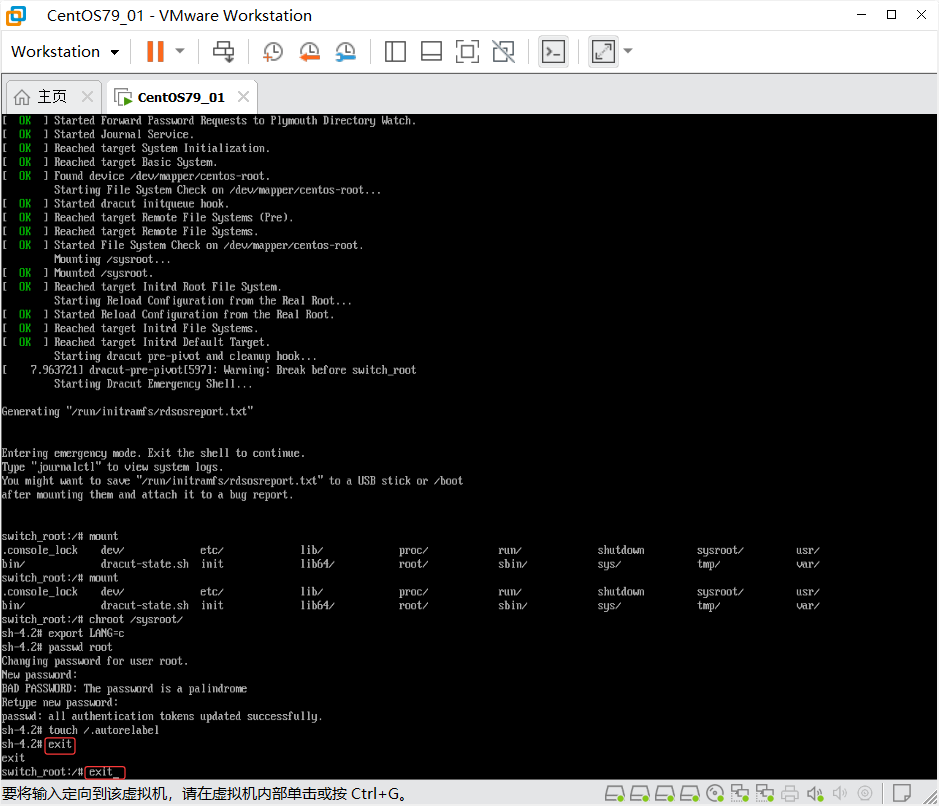
退出并重启
exit
exit
reboot
关键参数说明
| 参数 | 作用 |
|---|---|
rd.break | 在内核加载初期中断启动流程 |
enforcing=0 | 临时禁用SELinux强制模式 |
注意事项
-
磁盘加密系统:若启用了LUKS加密,需先解密再操作
-
云服务器:部分云平台需通过VNC或救援模式操作
-
时间控制:
.autorelabel会导致首次重启时间较长(约5-15分钟) -
UEFI系统:可能需要关闭Secure Boot功能
-
审计日志:系统日志会记录密码修改操作(/var/log/audit/audit.log)
替代方案(适用于不同场景)
-
init方法:
# 在GRUB的linux行后追加: init=/bin/bash
-
systemd方法:
systemctl edit --force --full rescue.target





