在大模型参数爆炸、训练推理并重的趋势下,「超节点」成为下一代 AI 基础设施的重要方向。
不同于传统标准 AI 服务器的算力交付形式,超节点具备更强的算力集成与数据传输能力,其内部通常采用高性能协议,将 AI 加速卡间互连高带宽域(HBD,High-Bandwidth Domain)提升,突破 8 卡和 16 卡规模的限制,在极致延时条件下实现算力无损的扩展。
1. 百度在 AI 服务器领域设计和部署的历程
百度拥有着十多年的服务器设计和部署经验。在 OCP 计算项目中,百度将自身在 AI 技术领域的优势与 OCP 项目成员共享,和其他成员一起推动构建开放的 AI 硬件生态系统。同时,与 Facebook、微软展开合作,联合制定 OAM(OCP Accelerator Module)标准。在 2011 年,百度就设计推出了第一代北极整机柜(也被称为「天蝎」整机柜)。
在 AI 和大模型时代,百度专门为 GPU 计算场景设计的服务器 —— 超级 AI 计算机 X-MAN,支持了百度集群各项 AI 业务落地。2022 年百度基于 X-MAN 4.0 建设了国内首个全 IB 网络的千卡级 GPU 集群,支撑了 2023 年初百度文心一言的发布,2025 年 X-MAN 5.0 助力昆仑芯 P800 3 万卡集群的落地。
在今年的 Create 2025 百度 AI 开发者大会中,百度智能云发布昆仑芯超节点。相比传统的 8 卡服务器算力交付方式,昆仑芯超节点将 64 张昆仑芯 XPU 放到同一个机柜,卡间互联带宽提升 8 倍,单整机柜训练性能提升了 10 倍,单卡推理性能提升了 13 倍。从性能上讲,一个机柜就能顶过去上百台机器。
为了支撑好昆仑芯超节点这种新算力形态的落地,百度天池 AI 高密液冷整机柜从机柜、计算节点、网络互联、供电散热、设备管理等方面进行了创新设计,使得昆仑芯超节点成为了一套具备高算力密度、高可靠、简单运维、容易部署等特性的 32/64 卡最小算力交付单元,并可支撑万卡级别集群网络互联。
在百度天池 AI 高密液冷整机柜的支撑下,昆仑芯超节点支持 1U 4 卡的超高密度算力交付形式,单节点一个人即可轻松维护。计算节点的核心芯片的温度可以降低 20℃ 以上,为 XPU 提供稳定的运行环境。能够适应各种机房的供电环境,并支持在风冷机房部署交付。

2. 昆仑芯超节点分模块介绍
2.1. 机柜
昆仑芯超节点基于百度天池系列 AI 高密液冷整机柜,支持整柜一体化的交付模式。同时采用水、电、网 3 盲插设计,在无需精准对准的条件下实现组件快速可靠对接的技术。普通一线运维人员,首次接触产品即可轻松上架运维。相比传统风冷标准服务器的交付方式,能够大幅度缩短业务上线时间。
昆仑芯超节点机柜在空间利用上发挥了极致,实现了超高密度的算力水平。以典型 64 卡场景为例,通常需要 8 台 8U 的风冷 AI 服务器,占用 64U 空间,而昆仑芯超节点通过整机柜方案仅需 28U ,即 16 个 1U Compute Tray + 8 个 1U Switch Tray + 2 个 2U Power shelf,机柜空间利用效率提升一倍以上,极大优化了数据中心的部署密度和能效比。
2.2. 计算节点(Compute Tray)
高算力、大带宽、强互连是昆仑芯超节点的核心设计目标。在有限空间与功耗约束下实现极致的算力密度提升,是我们在设计时反复打磨的重点方向。
依托百度多年在整机柜架构设计上的技术积累与工程经验,我们采用 1U 单节点 4 卡液冷方案,相较传统 AI 服务器的 8U 8 卡设计,算力密度提升了 4 倍。
AI 算力被誉为「重资产」,不仅体现在其成本上,更体现在物理重量。传统 8 卡 GPU 服务器整机重量高达 120 kg,上架需 4 人协作。而昆仑芯超节点得益于 1U 轻量化设计,单节点由一个人即可轻松维护,极大优化了数据中心的运维效率。
计算节点基于 21 寸标准 1U 计算节点架构,前窗 I/O 高度集成,可灵活支持百度太行 DPU、4 张网卡、4 块 NVMe、2 个 M.2、HBA 卡或 RAID 卡等多种配置,满足复杂多样的算力场景需求。
计算节点采用模块化设计,CPU 板、PCIe Switch 板与 GPU 板相互解耦,支持国产化 CPU 平台,具备极高的灵活性与可扩展性。
每个节点配备双 PCIe Switch 芯片,通过双上行链路与 CPU 高速互联,构建 1:1 无阻塞互联结构,实现了高效调度与低延迟通信,彻底消除数据瓶颈。
2.3. 交换节点(Switch Tray)
在 AI 基础设施中,网络互连不仅仅是连接,而是性能的延续和扩展。随着大模型训练、推理任务对多卡协同和跨节点通信的依赖不断增强,互连带宽和拓扑结构的优劣,直接决定了系统整体算力的天花板。
昆仑芯超节点在设计上突破了传统单机 8 卡互联的架构限制,创新性地引入多 Switch 通信结构。以 32 卡为例,可以通过 4 台 Switch Tray 模块实现算力全互联,构建出一个 Scale-Up 域规模为 32 卡的统一算力池。
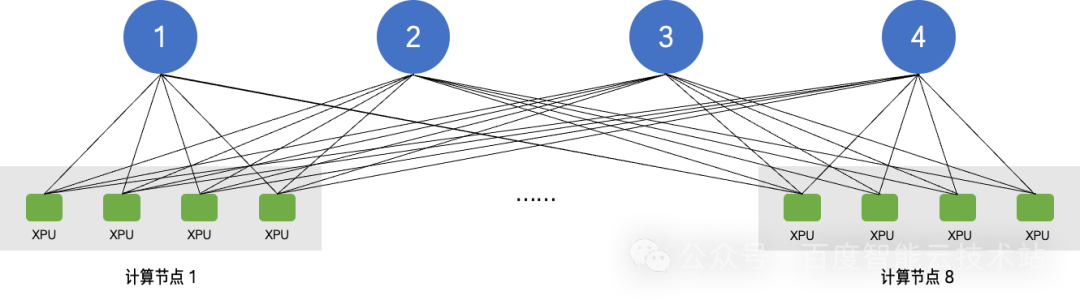
该架构确保任意两张 XPU 之间通信仅需 1 跳路径,显著降低通信延迟,提升带宽利用效率。相比传统的树状或分层式拓扑结构,昆仑芯超节点的全互联方案在 AllReduce、Alltoall 等通信场景中,展现出更优的通信效率与系统扩展性。
在 Scale-Out 网络设计上,昆仑芯超节点同样考虑到大规模集群部署需求。每个计算节点预留 4 张 PCIe 网卡扩展位,实现 XPU 与 NIC 的 1:1 绑定设计,单节点最高支持 4 张 400G 网卡。结合百度智能云自研的基于导轨优化的 HPN(High Performance Network)架构,昆仑芯超节点可支撑从数百卡到上万卡的 XPU 集群构建,为 AI 大模型训练提供坚实的网络底座和横向扩展能力。
2.4. 供电单元(Power shelf)
电源是整机柜的心脏。不同与传统 AI 服务器电源模块 PSU 的布置方法,昆仑芯超节点将电源模块 PSU 与计算节点解耦,所有电源集中放置于 Power shelf 中,为整机进行集中供电,以便实现昆仑芯超节点的高密部署。
昆仑芯超节点的单个 Power shelf 高度 2U,内置 12 个 PSU 电源单元,支持 10+2 电源冗余,采用双输入 ATS 技术,相比传统单输入电源 PSU ,电源数量节省 40%。
Power shelf 支持 3300W 和 5500W 两种电源功率规格,通过并联的方式,可实现单柜 33kW ~ 120kW 的供电能力,可支持 500W ~ 1000W XPU/GPU 供电,满足业界主流 AI 机柜功耗需求。同时,供电模块支持 AC + AC、AC + DC、DC + DC 三种机房冗余供电模式,能够适应传统、新建等各种机房的供电环境。
2.5. 散热模块
昆仑芯超节点采用液冷和风冷相结合的混合散热架构,解决高功耗、高密度散热挑战。CPU 及 XPU 采用液冷散热,网卡、内存、SSD 等采用风冷散热。
在液冷系统中,我们采取了微通道冷板液冷技术及并联水路设计,通过精准调控冷却液流量与流速,最大化 XPU 和 CPU 的散热效率。实验结果表明,该液冷设计可使 XPU 温度下降 20℃ 以上,相较传统风冷系统,减少因为高温导致的 XPU 故障,显著提升系统的热稳定性与能效比。
在风冷系统中,我们做了进一步优化设计。从主流的 GPU 服务器布局来看,RDMA 网卡(如 Mellanox CX7)一般部署在热通道,而 400G 网卡使用的光模块又是一个对温度敏感的器件,温度过高会引起 CRC 报错,造成网口抖动甚至网络失联等问题。在 Meta 发布 Llama 3.1 训练技术报告中披露,由于网卡和网络引起的任务中断占比高达 12%。鉴于此,昆仑芯超节点将计算节点的 RDMA 网卡、VPC 网卡等均部署在冷通道,减少网卡和光模块由于散热问题导致的故障频率,使得集群整体更加稳定可靠。
通常情况下,液冷服务器无法部署在风冷机房。昆仑芯超节点的液冷机柜集成了百度智能云自主研发的冷却分配单元(CDU)—— 天玑 1.0,只需要在每台机柜旁边部署一套天玑 1.0,即可将昆仑芯超节点部署于传统风冷数据中心。
2.6. 管理模块
昆仑芯超节点采用业界领先的双层带外管理架构,由机柜级 RMC(Rack Management Controller)与节点级 BMC(Baseboard Management Controller)协同组成,覆盖计算节点、互连模块、电源模块与散热模块,实现全链路智能运维。
RMC 具备智能电源管理、液冷系统守护、资产管理和预测性运维等核心能力,为整机柜系统提供稳定可靠的运行保障。
BMC 支持核心组件故障监控和告警,包括 CPU、内存、XPU、网卡/DPU、磁盘、风扇、主板等,支持节点漏液检测,支持一键日志精准故障定位,能够提前发现潜在风险,降低宕机时间,提升维护效率。
3. 结语
昆仑芯超节点的推出,意味着百度智能云在 AI 基础设施领域的创新再次迈出了坚实的一步。这一全新的整机柜设计不仅在算力密度、能效比和部署灵活性上实现了质的飞跃,还为 AI 大模型训练、推理等复杂任务提供了强大的支持。

)



