ROPE位置编码:从理论到LLaMA的实践
一、前言
ROPE(Rotary Positional Embedding,旋转位置编码)是一种通过旋转矩阵将位置信息融入Token Embedding的编码方法。相比传统Transformer的绝对位置编码,ROPE能更灵活地建模相对位置关系,被广泛应用于GPT-3.5/4、LLaMA等大模型。本文将介绍ROPE的必要性,公式以及推理过程。如果觉得有用,麻烦点个小小的赞,十分感谢~
📌 核心思想:通过旋转操作让模型直接"感知"Token之间的相对位置,而非依赖绝对位置编号。
二、位置编码的必要性
传统transformer概述
在理解ROPE之前,我们需要先回顾传统Transformer的运作机制:
首先,输入是一个长度为N的序列,表示为:
S N = w i i = 1 N S_N = {w_i}^N_{i=1} SN=wii=1N
意为i从1到N的字符,比如“欢迎点赞关注!”就是一个输入序列。之后需要对该序列进行转换,转换为embedding向量,这是因为神经网络不能直接处理文字,只能处理数字。
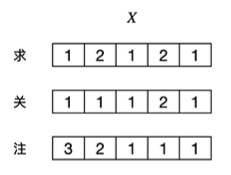
这里我们取“求关注”这三个字,假设这三个字的embedding分别为:
我们就可以针对这三个字计算注意力分数,attention score,也就是 α \alpha α,这里的计算公式为 A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V s o f t m a x ( z i ) = e z i ∑ K = 1 N e Z K Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\\ softmax(z_i) = \frac{e^{z_i}}{\sum^N_{K=1}e^{Z_K}} Attention(Q,K,V)=softmax(dkQKT)Vsoftmax(zi)=∑K=1NeZKezi
第一个公式是ransformer 模型 中最核心的机制之一 —— “注意力机制(Attention Mechanism)” 的公式,用来计算token之间的关系。这里 d k d_k dk代表向量的维度,用来做缩放(避免过大数值造成梯度不稳定)。Q(Query),即查询向量,表示当前正在处理的词(或位置)的表示,K(Key),即键向量:表示输入中所有词(或位置)的特征。V(Value),即值向量:表示每个词携带的实际信息。接下来我们来逐步解释公式的含义:
- Q K T QK^T QKT :对每个查询(Query)向量和所有键(Key)向量计算相似度(点积),得到一个“注意力分数矩阵”。
- Q K T d k \frac{QK^T}{\sqrt{d_k}} dkQKT:将注意力分数进行缩放(缩放点积注意力),使得随着向量维度增大,分数不过大。
- softmax(…):将分数归一化为概率,决定 Query 对输入中每个位置应该“注意”多少。
- 乘以 V:将注意力权重应用于 Value 向量,加权求和,得到最终的注意力输出。
到这里,你可能会觉得非常抽象,难以理解,我们来做个类比就好懂很多了:
你是一个学生(Query),在考试前要复习(获取信息)。你采取的步骤是:
- 你根据每本书的标题(Key)判断它对考试的帮助程度(打分)。
- 然后你根据这些打分(softmax)决定分配多少时间复习每本书(Value)。
- 最后你将从每本书中获得的信息按分数加权合成自己的知识(输出)。
现在有没有好懂很多?这里Q, K, V的计算公式分别是:
Q = W q X K = W K X V = W V X Q = W_qX\\ K = W_KX\\ V = W_VX Q=WqXK=WKXV=WVX其中 W q W_q Wq, W K W_K WK和 W V W_V WV都是可学习的参数。但是在接下来的示范中,为了方便引入ROPE,我们暂时先省略这几个参数。
自注意力机制的局限性
省略以上参数后,attention score的计算公式就变成了 A t t e n t i o n ( Q , K , V ) = s o f t m a x ( X X T d k ) X Attention(Q,K,V) = softmax(\frac{XX^T}{\sqrt{d_k}})X Attention(Q,K,V)=softmax(dkXXT)X根据该计算公式,我们一步步进行计算,如下图所示:
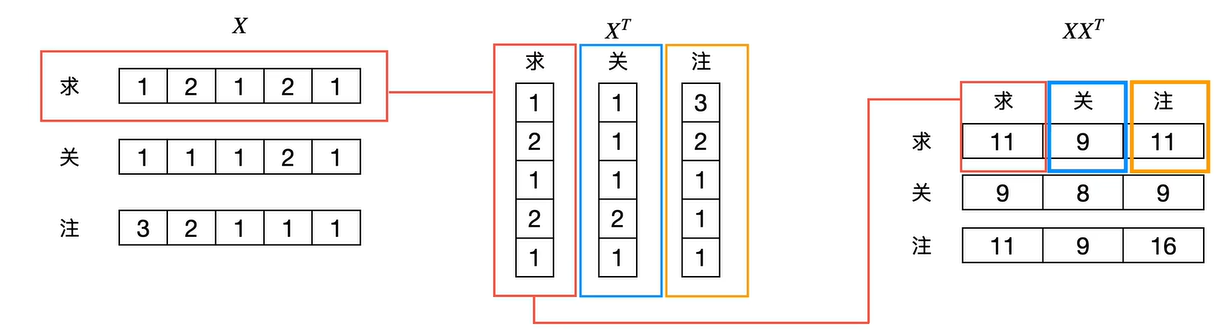
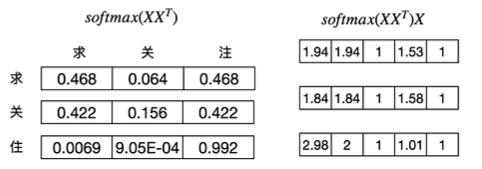
到 s o f t m a x ( X X T X ) softmax({XX^T}X) softmax(XXTX)这一步的时候,大家有没有发现什么问题?
当我们变化一下“求关注” 这三个字的顺序。从“求关注”到“求注关”,,那么注意力矩阵就会变成:
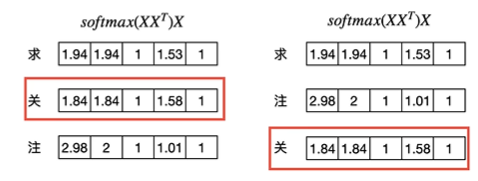
在人类语言中,一句话的含义会随着每个字的出现顺序而改变,但是在传统的注意力机制中,并没有考虑位置顺序这一点。从计算结果我们能看出,即使顺序进行了改变,经过Attention计算后,每一个字的embedding依旧是不变的,也就是Transformer 的注意力机制没有考虑过顺序对embedding的影响,仅靠 Attention(Q, K, V) 是看不出“谁在前谁在后”的,计算结果只依赖于 token embedding 的内容。
因此我们需要找到一个函数,入参是当前序列值x和其所在的位置i,返回结果会因为x和i不同而不同。这就是位置编码技术出现的初衷,及讲位置信息融入计算之中。
三、ROPE的数学原理
公式介绍
这一章节我们开始介绍ROPE的公式推导。为了方便理解,我们假设输入是二维向量,即 x m x_m xm和 x n x_n xn。那么公式为:
x m ′ = W q x m e i m θ = ( W q x m ) e i m θ = q m e i m θ x n ′ = W k x n e i n θ = ( W k x n ) e i n θ = k n e i n θ x m T x n ′ = ( q m 1 q m 2 ) ( c o s ( ( m − n ) θ ) − s i n ( ( m − n ) θ ) s i n ( ( m − n ) θ ) c o s ( ( m − n ) θ ) ) ( k n 1 k n 2 ) {x_m}^{\prime} = W_qx_me^{im\theta} = (W_qx_m)e^{im\theta} = q_me^{im\theta} \\ {x_n}^{\prime} = W_kx_ne^{in\theta} = (W_kx_n)e^{in\theta} = k_ne^{in\theta}\\ {x_m}^T{x_n}^{\prime} = (q_m^1\ q_m^2)\begin{pmatrix} cos((m-n)\theta) & -sin((m-n)\theta) \\ sin((m-n)\theta) & cos((m-n)\theta) \end{pmatrix}\begin{pmatrix} k_n^1 \\ k_n^2 \end{pmatrix} xm′=Wqxmeimθ=(Wqxm)eimθ=qmeimθxn′=Wkxneinθ=(Wkxn)einθ=kneinθxmTxn′=(qm1 qm2)(cos((m−n)θ)sin((m−n)θ)−sin((m−n)θ)cos((m−n)θ))(kn1kn2)
证明过程
接下来我们看这三个公式的证明,过程会比较繁琐,需要一点耐心走一遍:
- 首先我们之前设定了输入向量是二维的,那么初始计算公式为:
q m = ( W q 11 W q 12 W q 21 W q 22 ) ( x m 1 x m 2 ) = ( q m 1 q m 2 ) q_m= \begin{pmatrix} W_q^{11} & W_q^{12} \\ W_q^{21} & W_q^{22} \\ \end{pmatrix}\begin{pmatrix} x_m^1 \\ x_m^2\\ \end{pmatrix} = \begin{pmatrix} q_m^1 \\ q_m^2\\ \end{pmatrix} qm=(Wq11Wq21Wq12Wq22)(xm1xm2)=(qm1qm2) - 二维向量可以表示为复数形式,因为向量的一个维度可以表示为一个坐标,类比到实数坐标和虚数坐标。那么可得:
q m = q m 1 + i q m 2 q_m=q_m^1 + iq_m^2 qm=qm1+iqm2 - 运用欧拉公式可以得到:
e i m θ = c o s ( m θ ) + i s i n ( m θ ) e^{im\theta} = cos(m\theta) + isin(m\theta) eimθ=cos(mθ)+isin(mθ) - 进行复数计算。考虑到 i 2 = − 1 i^2=-1 i2=−1,可得:
q m e i m θ = ( q m 1 + i q m 2 ) ( c o s ( m θ ) + i s i n ( m θ ) ) = ( q m 1 c o s ( m θ ) − q m 2 s i n ( m θ ) + i ( q m 2 c o s ( m θ ) + q m 1 s i n ( m θ ) ) \begin{align*} q_me^{im\theta} & = (q_m^1+iq_m^2)(cos(m\theta)+isin(m\theta) )\\ & = (q_m^1cos(m\theta)-q_m^2sin(m\theta) + i(q_m^2cos(m\theta) + q_m^1sin(m\theta)) \\ \end{align*} qmeimθ=(qm1+iqm2)(cos(mθ)+isin(mθ))=(qm1cos(mθ)−qm2sin(mθ)+i(qm2cos(mθ)+qm1sin(mθ)) - 针对最后这个公式,我们再次将其转换为二维向量:
x m ′ = q m e i m θ = ( q m 1 c o s ( m θ ) − q m 2 s i n ( m θ ) , q m 2 c o s ( m θ ) + q m 1 s i n ( m θ ) ) = ( c o s ( m θ ) − s i n ( m θ ) s i n ( m θ ) c o s ( m θ ) ) ( q m 1 q m 2 ) \begin{align*} {x_m}^{\prime} & = q_me^{im\theta} \\ & = (q_m^1cos(m\theta)-q_m^2sin(m\theta), \ q_m^2cos(m\theta) + q_m^1sin(m\theta))\\ &=\begin{pmatrix} cos(m\theta) & -sin(m\theta) \\ sin(m\theta) & cos(m\theta) \\ \end{pmatrix}\begin{pmatrix} q_m^1 \\ q_m^2 \end{pmatrix} \end{align*} xm′=qmeimθ=(qm1cos(mθ)−qm2sin(mθ), qm2cos(mθ)+qm1sin(mθ))=(cos(mθ)sin(mθ)−sin(mθ)cos(mθ))(qm1qm2) - 类比到另一个输入 x n x_n xn,我们也可以同样有
x n ′ = k n e i n θ = ( k n 1 c o s ( n θ ) − k n 2 s i n ( n θ ) , k n 2 c o s ( n θ ) + k n 1 s i n ( n θ ) ) = ( c o s ( n θ ) − s i n ( n θ ) s i n ( n θ ) c o s ( n θ ) ) ( k n 1 k n 2 ) \begin{align*} {x_n}^{\prime} & = k_ne^{in\theta} \\ & = (k_n^1cos(n\theta)-k_n^2sin(n\theta), \ k_n^2cos(n\theta) + k_n^1sin(n\theta))\\ &=\begin{pmatrix} cos(n\theta) & -sin(n\theta) \\ sin(n\theta) & cos(n\theta) \\ \end{pmatrix}\begin{pmatrix} k_n^1 \\ k_n^2 \end{pmatrix} \end{align*} xn′=kneinθ=(kn1cos(nθ)−kn2sin(nθ), kn2cos(nθ)+kn1sin(nθ))=(cos(nθ)sin(nθ)−sin(nθ)cos(nθ))(kn1kn2) - 带入到内积中: x m T x n ′ = ( ( cos ( m θ ) − sin ( m θ ) sin ( m θ ) cos ( m θ ) ) ( q m 1 q m 2 ) ) T ( ( cos ( n θ ) − sin ( n θ ) sin ( n θ ) cos ( n θ ) ) ( k n 1 k n 2 ) ) = ( q m 1 q m 2 ) ( cos ( m θ ) sin ( m θ ) − sin ( m θ ) cos ( m θ ) ) ( cos ( n θ ) − sin ( n θ ) sin ( n θ ) cos ( n θ ) ) ( k n 1 k n 2 ) = ( q m 1 q m 2 ) ( cos ( m θ ) cos ( n θ ) + sin ( m θ ) sin ( n θ ) − cos ( m θ ) sin ( n θ ) + sin ( m θ ) cos ( n θ ) − sin ( m θ ) cos ( n θ ) + cos ( m θ ) sin ( n θ ) sin ( m θ ) sin ( n θ ) + cos ( m θ ) cos ( n θ ) ) ( k n 1 k n 2 ) = ( q m 1 q m 2 ) ( cos ( ( m − n ) θ ) sin ( ( m − n ) θ ) ) − sin ( ( m − n ) θ ) cos ( ( m − n ) θ ) ) ( k n 1 k n 2 ) \begin{align*} {x_m}^T{x_n}^{\prime} & = \left( \begin{pmatrix} \cos(m\theta) & -\sin(m\theta) \\ \sin(m\theta) & \cos(m\theta) \\ \end{pmatrix} \begin{pmatrix} q_m^1 \\ q_m^2 \end{pmatrix} \right)^T \left( \begin{pmatrix} \cos(n\theta) & -\sin(n\theta) \\ \sin(n\theta) & \cos(n\theta) \\ \end{pmatrix} \begin{pmatrix} k_n^1 \\ k_n^2 \end{pmatrix} \right) \\ & = (q_m^1\ q_m^2) \begin{pmatrix} \cos(m\theta) & \sin(m\theta) \\ -\sin(m\theta) & \cos(m\theta) \\ \end{pmatrix} \begin{pmatrix} \cos(n\theta) & -\sin(n\theta) \\ \sin(n\theta) & \cos(n\theta) \\ \end{pmatrix} \begin{pmatrix} k_n^1 \\ k_n^2 \end{pmatrix}\\ & = (q_m^1\ q_m^2) \begin{pmatrix} \cos(m\theta)\cos(n\theta)+\sin(m\theta)\sin(n\theta) & -\cos(m\theta)\sin(n\theta)+\sin(m\theta)\cos(n\theta)\\ -\sin(m\theta)\cos(n\theta)+\cos(m\theta)\sin(n\theta) & \sin(m\theta)\sin(n\theta)+\cos(m\theta)\cos(n\theta)\\ \end{pmatrix} \begin{pmatrix} k_n^1 \\ k_n^2 \end{pmatrix}\\ & = (q_m^1\ q_m^2) \begin{pmatrix} \cos((m-n)\theta) & \sin((m-n)\theta))\\ -\sin((m-n)\theta) & \cos((m-n)\theta)\\ \end{pmatrix} \begin{pmatrix} k_n^1 \\ k_n^2 \end{pmatrix} \end{align*} xmTxn′=((cos(mθ)sin(mθ)−sin(mθ)cos(mθ))(qm1qm2))T((cos(nθ)sin(nθ)−sin(nθ)cos(nθ))(kn1kn2))=(qm1 qm2)(cos(mθ)−sin(mθ)sin(mθ)cos(mθ))(cos(nθ)sin(nθ)−sin(nθ)cos(nθ))(kn1kn2)=(qm1 qm2)(cos(mθ)cos(nθ)+sin(mθ)sin(nθ)−sin(mθ)cos(nθ)+cos(mθ)sin(nθ)−cos(mθ)sin(nθ)+sin(mθ)cos(nθ)sin(mθ)sin(nθ)+cos(mθ)cos(nθ))(kn1kn2)=(qm1 qm2)(cos((m−n)θ)−sin((m−n)θ)sin((m−n)θ))cos((m−n)θ))(kn1kn2)
恭喜!完成证明啦!另外证明方式不止这一种,你也可以去试试其他的方法~
多维度泛化
最后就是将这个公式从二维推向多维,听起来很复杂,其实很简单,只需要将多维数据两两拿出来用以上公示计算即可,如下图所示。
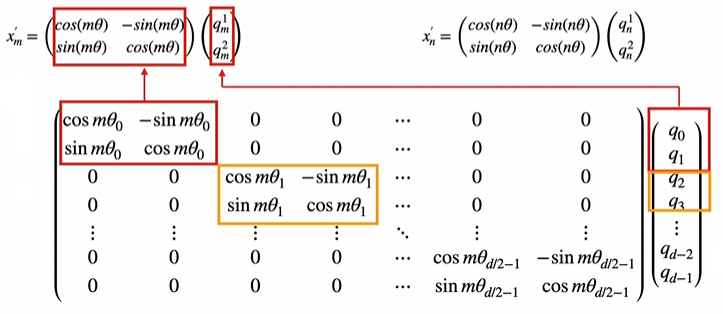
但是通过这种方式因为矩阵中大部分数字是0会导致多余的计算量,所以这个公式也可修改为等值的:
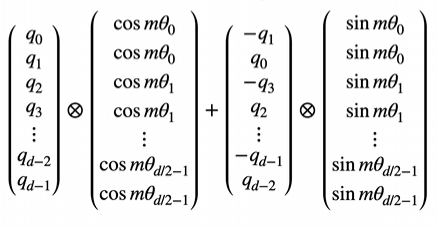
以下是优化后的表述建议,既保持了专业性又增强了可读性:
关于θ参数的说明
ROPE中的关键参数θ按照以下公式计算:
θ i = 1000 0 − 2 i / d ( 其中 d 必须为偶数 ) \theta_i = 10000^{-2i/d} \quad (\text{其中}d\text{必须为偶数}) θi=10000−2i/d(其中d必须为偶数)
设计原理:
- 维度分组:将d维嵌入向量划分为d/2个二维子空间
- 独立旋转:在每个二维子空间分别应用旋转矩阵
- 衰减设计:指数项的负号确保随着维度i增加,旋转角度逐渐减小
- 基数选择:10000作为经验值,平衡长短期依赖的捕捉能力
技术总结
ROPE通过优雅的数学设计,在保持计算效率的同时,完美解决了Transformer的位置感知难题,成为大模型位置编码的事实标准。






