大家好,这里是架构资源栈!点击上方关注,添加“星标”,一起学习大厂前沿架构!
引言
在分布式系统中,服务注册、配置管理、分布式锁、选举等场景都需要一个高可用、一致性强的协调服务。Apache ZooKeeper 凭借其轻量级、易用性和强一致性,成为业界主要选择之一。本文将从原理层面剖析 ZooKeeper,给出 Java 快速上手示例,并与同类产品(etcd、Consul、Eureka)进行对比,为架构选型提供参考。
一、ZooKeeper 简介
-
定位:分布式协调服务,提供命名(Naming)、同步(Synchronization)、配置管理(Configuration)、组管理(Group Management)等基本原语。
-
优势:
- 读性能优越:针对读多写少场景优化
- 强一致性:采用 Zab(ZooKeeper Atomic Broadcast)协议保障写操作原子广播
- Watch 机制:基于事件通知的异步设计
二、ZooKeeper 核心原理
1. 数据模型 —— ZNode 树
- 以类文件系统的树状结构存储数据,称为 ZNode
- 每个 ZNode 可以存储少量的元数据和数据(默认 1MB 以内)
- 支持持久节点(Persistent)和临时节点(Ephemeral),及顺序变体
/
├── /app
│ ├── /app/config (持久节点)
│ └── /app/lock_0001 (临时顺序)
└── /services├── /services/svcA (临时节点)└── /services/svcB (临时节点)
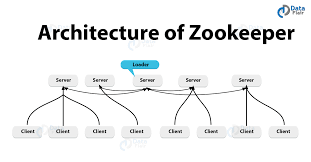
2. 集群架构与选举
-
角色:每个节点启动时会在集群中选举产生一个 Leader,其余为 Follower;也可配置 Observer(只读,不参与选举)
-
读写分离:
- 读请求:可由任意节点(Follower/Observer)处理
- 写请求:必须先提交给 Leader,由 Leader 通知 Follower 过半达成一致后应用并回复客户端
3. Zab 协议(Atomic Broadcast)
- Proposal:Leader 接收写请求并生成提案(Proposal)
- Sync:Leader 将 Proposal 发送给所有 Follower
- Ack:Follower 收到 Proposal 后返回确认
- Commit:Leader 收到多数 Ack 后发送 Commit,所有节点应用并完成事务
4. 会话与 Watch
- Session:客户端与集群建立会话,ZK 用心跳维持,有超时机制
- Watch:客户端可在 ZNode 上注册 Watch,节点数据/子节点变化时触发一次性事件通知
三、ZooKeeper 快速入门示例(Java)
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;import java.util.concurrent.CountDownLatch;public class ZkDemo {private static final String CONNECT_ADDR = "zk1:2181,zk2:2181,zk3:2181";private static final int SESSION_TIMEOUT = 5000;private ZooKeeper zk;private CountDownLatch connectedSignal = new CountDownLatch(1);public void connect() throws Exception {zk = new ZooKeeper(CONNECT_ADDR, SESSION_TIMEOUT, event -> {if (event.getState() == Watcher.Event.KeeperState.SyncConnected) {connectedSignal.countDown();}});connectedSignal.await();}// 创建持久节点public String createPersistent(String path, byte[] data) throws KeeperException, InterruptedException {return zk.create(path, data, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);}// 读取数据并注册 Watchpublic byte[] getData(String path, Watcher watcher) throws KeeperException, InterruptedException {Stat stat = zk.exists(path, true);if (stat != null) {return zk.getData(path, watcher, stat);}return null;}// 更新数据public void updateData(String path, byte[] data) throws KeeperException, InterruptedException {Stat stat = zk.exists(path, false);if (stat != null) {zk.setData(path, data, stat.getVersion());}}// 关闭连接public void close() throws InterruptedException {zk.close();}public static void main(String[] args) throws Exception {ZkDemo demo = new ZkDemo();demo.connect();String path = demo.createPersistent("/app/config", "v1".getBytes());System.out.println("节点创建: " + path);byte[] data = demo.getData("/app/config", event ->System.out.println("节点变更: " + event));System.out.println("读取数据: " + new String(data));demo.updateData("/app/config", "v2".getBytes());demo.close();}
}
四、与同类产品对比
| 特性 | ZooKeeper | etcd | Consul | Eureka |
|---|---|---|---|---|
| 一致性 | 强一致性(CP) | 强一致性(CP,基于 Raft) | 可配(默认 CP) | 弱一致性(AP,基于自选复制) |
| 读写性能 | 读快、写次之 | 写优、读优 | 性能均衡 | 适中 |
| Watch机制 | 一次性 Watch,需重置 | 支持 Watch/WatchStream,可持续监听 | 支持 KV Watch | 不支持,需客户端轮询 |
| 数据模型 | 树形层级(类文件系统) | 键值对(扁平) | KV + 服务健康检查 | 服务注册中心 |
| 客户端生态 | 原生 Java/C、众多三方 | Go/Kotlin/Java/C# 等,多语种支持 | Go/Java/Python/Node.js 等 | Java 生态为主 |
| 高可用方案 | 集群模式,Observer 可扩展读 | 集群模式,普通节点+Learner | Cluster + WAN Federation | 集群模式,PeerAwareInstance |
| 典型场景 | 分布式锁、配置管理、选举、Naming | 配置管理、服务发现、Leader 选举 | 服务发现、健康检查、Multi-Datacenter | 服务发现、负载均衡 |
对比总结
- 一致性与性能:若追求强一致性、读多写少场景,首选 ZooKeeper;写密集场景可考虑 etcd。
- 生态与易用性:Consul 提供内置健康检查、Multi-DC 支持,适合作为全栈服务发现与健康监控;Eureka 更偏向 Java 微服务生态(Spring Cloud)。
- Watch 能力:持续监听场景下,etcd 和 Consul 更灵活;ZooKeeper 则需客户端自行重置 Watch。
结语
Apache ZooKeeper 以其成熟的协调原语、强一致性和稳定的社区,仍是分布式系统核心组件的首选。但在选型时,应结合业务场景、性能特点和运维成本,综合权衡。希望本文能够帮助你快速理解 ZooKeeper 原理,并在架构设计中做出更明智的决策。
转自:https://mp.weixin.qq.com/s/cSTNX6jaOYnkHhSEjz9ILw






