目录
数据类型
字符串:
List:
HASH:
Set:
Zset:
BitMap:(这个及以下是后来新增的数据结构)
HyperLogLog:
GEO:
Stream:
主要数据结构
SDS
压缩列表
HASH
整数结合
跳表
quickList
listpack编辑
持久化
AOF(Append only FIle)
AOF写回策略
AOF重写
aof后台重写
rdb快照
混合持久化
过期删除和内存淘汰
过期删除:
内存淘汰
主从复制
具体应用:
布隆过滤器
分布式锁
数据类型
五种常用数据类型:字符串,List,HASH,Set,Zset(也叫sorted Set)
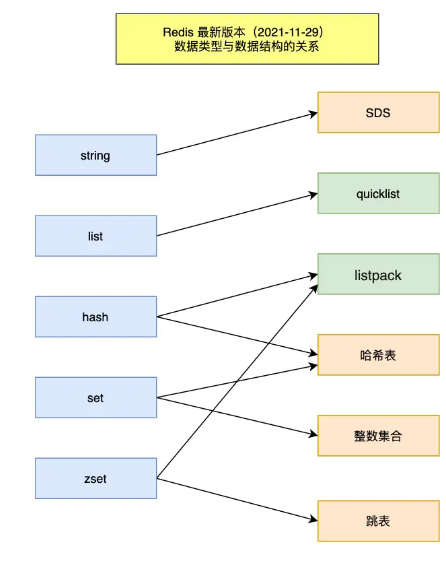
字符串:
key-Value形式储存,key可以理解为字符串的名字,Value是实际字符串的内容
底层有SDS实现(SDS:简单动态字符串),个人理解是基本字符串的扩展。短的时候是embstr,长了是raw。简单理解就是,Redis额外开辟了一或二个额外空间来储存字符串相关的内容,比如字符串的长度,字符串的实际地址等。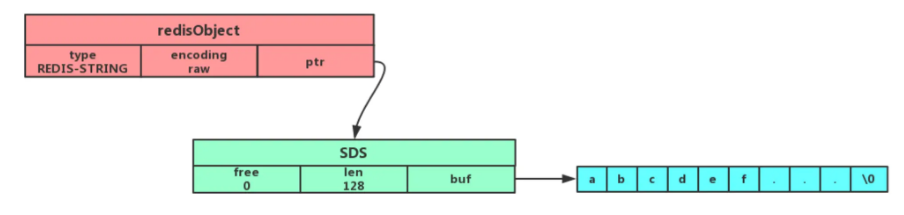
基本的使用语句是set,get,setNX等。
字符串可以用来当做分布式锁:很多个客户端共同使用一个Redis,在进行一个操作的时候,设置一个字符串:set lock_key unique_value NX PX 10000 后面的PX 10000 是超过这个时间自动释放锁(防止死锁)NX是not exit 不存在这个字符串时才会加锁。
字符串也可以用作缓存:储存数据就是了;也可以用作计数器:字符串有自增指令INCR和INCRBY,可以使字符串的值加1或加多,并且由于是单线程实现的,不需要考虑竞态问题
List:
Key-value储存形式,是一个双端队列
内部结构listPack
基本语法LPUSH,LPOP,RPUSH,RPOP等,并且有阻塞获取的语法BRPOP:阻塞,右边,取
可以用作简单的消息队列,但有些问题:List实现的消息队列不能实现持久化;不能多个消费者处理同一个消息;需要手动维护每个消息的唯一id
HASH:
Key-field-value储存形式, key是HASH的名称,filed可以类比哈希表的key,Value可以类比哈希表的Value
内部储存结构是listPack和哈希表
基本语法是HSET、HMSET等(M指的是Multi,一次处理多个)
Set:
Key-filed储存形式
内部实现时整数集合和哈希表
和普通的set一样,每个元素唯一,但是是无序存储。
基本语法是SADD,SREM,SCARD(cardinality,集合的势),SMEMBERS(获取集合中的全部元素)。并且SET支持SUNION,SINTER,SDIFF(并,交,差)集合运算
Zset:
key-score-value储存形式,集合中的元素按照score的顺序排序。
内部实现时listPack和跳表
基本语法是ZADD,ZREM等。支持交、并操作(不支持差了)
BitMap:(这个及以下是后来新增的数据结构)
每个元素都是二进制的(相当于维护了一个二进制的数组,但不需要实现设定大小)
基本语法SETBIT,GETBIT等,支持二进制运算:与&,或|,异或^,反~
主要用于制作布隆过滤器或记录一些二进制的状态(比如签到等)
HyperLogLog:
用处就是可以用一个相当小(12k)的内存来统计具体有多少个元素(能用,但是有误差0.81%)
常用指令PFADD(添加),PFCOUNT(计数),PFMERGE(合并)
比如向这个结构中PFADD100w个数据,可以用PFCOUNT快速得到大致的数量
GEO:
地图存储,底层用的是ZSET
Stream:
主要解决list实现消息队列时不能持久化,不能多个消费者处理的问题
基本语法XADD,XREAD等。可以定义XGROUP(消费者组),用消费者组读取内容(一组可以有多个消费者)。组内消费者不能读取同一条数据,但不同组的消费者可以处理同一条内容。
处理完成后向Stream返回XACK确认消息已经处理完毕。没处理完的数据可以用SPENDING获取,这样当Redis意外关闭时未处理的消息也不会丢失。
但是Stream存储的消息中间件可能会丢失,并且大小受内存大小的限制。如果有高要求的话还是用kafka等专业消息队列比较好
主要数据结构
我们之前说的,上面的数据类型都有一个key,以及对应的value。(key是数据的名称,value就是对应的数据)。而Redi是用一个哈希表来保存这些全部的数据的。在下图中可以看到,Redi维护了一个dictEntry,就是哈希表中储存的键值对。每个对有一个key指针和value指针,key指针指向一个String,value指针指向对应的具体数据类型。
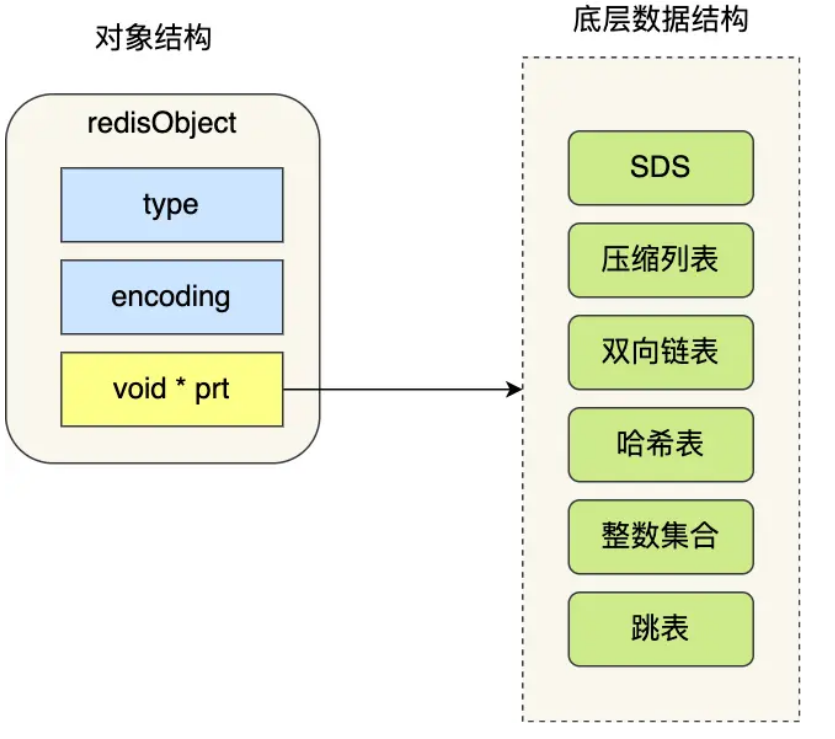
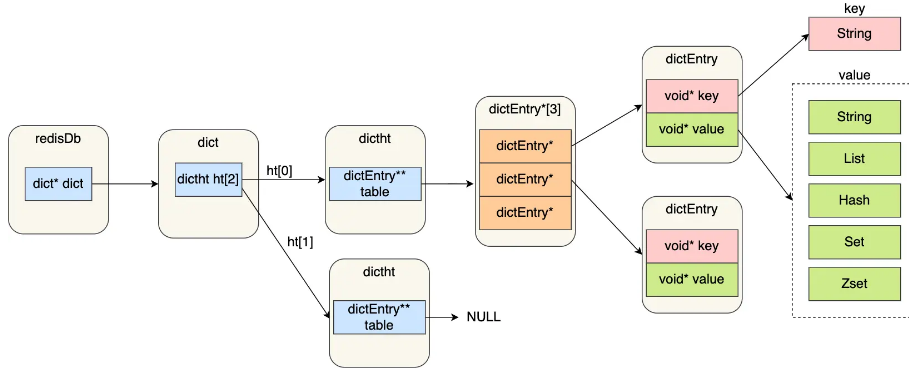 Redis中存储的都是Redis对象。有一个type标志这个对象是哪一种数据类型(比如Zset),encoding表示底层数据结构。比如SDS会有embstr和raw两种选择。最后的就是一个指针,指向真正的数据
Redis中存储的都是Redis对象。有一个type标志这个对象是哪一种数据类型(比如Zset),encoding表示底层数据结构。比如SDS会有embstr和raw两种选择。最后的就是一个指针,指向真正的数据
SDS
就是设计了一个头结构,记录了字符串的长度和已经分配的内存空间大小。这样获取长度的复杂度为O(1),并且执行字符串拼接的时候不用再考虑内存分配(C的问题),最后,由于已经标明了字符串的长度,因此不需要再为字符串添加‘/0’的终止符,使得字符串现在不止可以储存文本,也可以储存二进制数据了
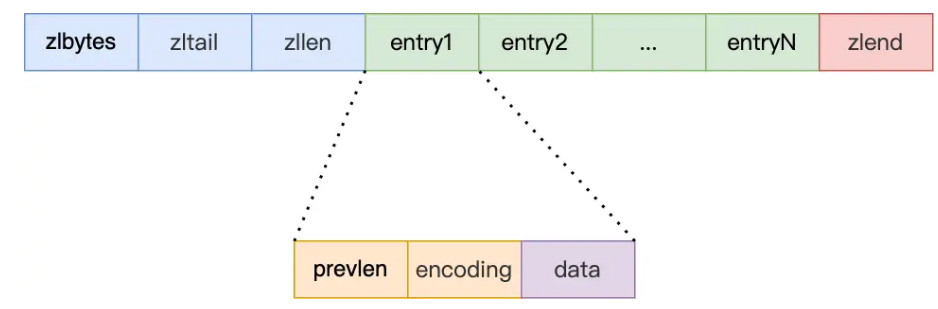
压缩列表
结构的会储存结构整体占用的字节数,列表尾的偏移量,节点数和结束点。(不再是普通链表的分块存储,这样提高了CPU缓存的命中率)
每个节点会储存上一个节点的长度,本节点的数据类型和长度,实际数据内容。
压缩列表的两个问题就是:查询中间节点需要的复杂度是O(n);连锁更新问题(主要是在改变节点内容的时候需要改变下一个节点的prevlen值,可能会出现改一个之后后面的很多个都要改的情况。)
HASH
和java7及以前的逻辑是基本上一样的。不过是扩容的时候不是一次性复制,而是用到哪个bin,就把哪个bin的内容复制过来
整数结合
就是一块连续的内存空间,三个量:编码方式,元素个数和保存元素的数组。通过二分查找实现有序数组进而实现唯一。不过每个数字占的大小有限制(比如都要小于16位),如果有一个数超过这个限制,那么所有的数都要大小升级,数组整体扩容
跳表
很多层,每层维护一个链表。目的是为了实现链表的更快查询,大致结构长这个样子。链表的层数要事先设计好。节点按照一定的概率向上升(这个概率要人为给定)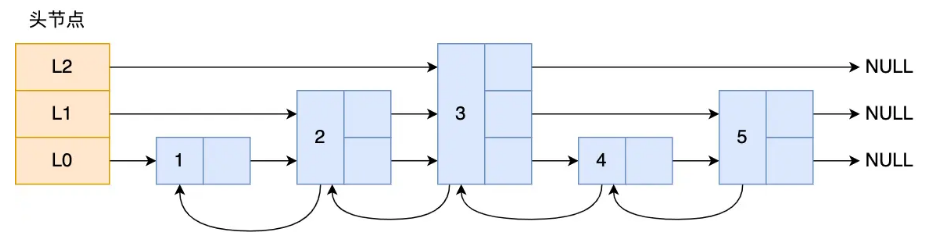
跳表的主要优势是他结构简单易于实现,范围查询更快,插入删除需要的操作更少,每个节点储存的指针更少(跳表平均1/(1-p),平衡树两个)
quickList
添加元素的时候,不再直接新建一个节点,而是先看这个节点对应的压缩链表能否容纳这个节点(就是看列表中是否还有足够的空闲内存和可容纳节点个数),如果可以的话就放进去,不能的话才新建一个节点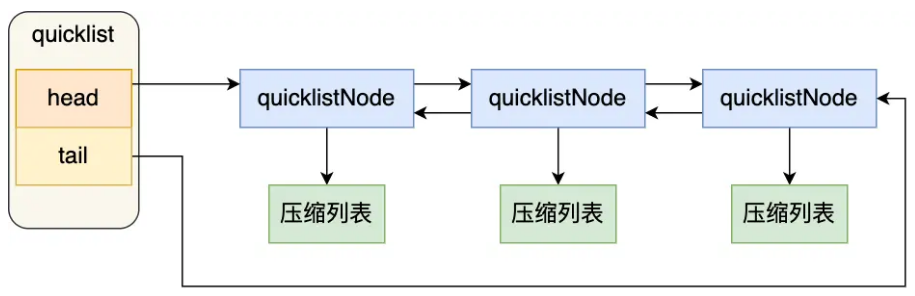
listpack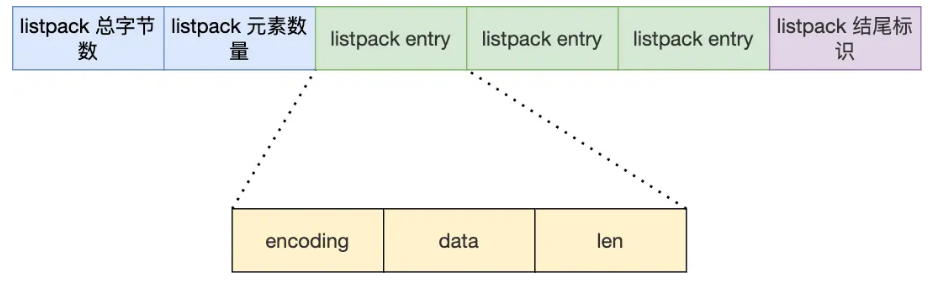
和压缩链表相比,实际上就是把pre(上一个节点的长度)删掉,换成了当前节点的长度。相当于压缩链表的改进版。
持久化
Redis的持久化(其实就是将内容写入到磁盘)有AOF和RDB两种策略
AOF(Append only FIle)
就是写一个aof文件,这个文件保存在磁盘中。具体来说有以下处理过程:
Redis接受到写命令之后,先在内存中修改对应的数据,然后把这个修改数据的命令储存在aof缓冲区中,等待合适的时机把缓冲区中的内容写入到aof文件中。
AOF写回策略
所谓的合适的时机就是aof的刷盘策略,总共有三种:always、everysec和no。第一种就是每次有修改命令,都把内容写入到内核空间的page cache中同时写入到磁盘中。everysec是每一秒写一次,no是交给操作系统决定什么时候写入磁盘。(其实就是aof的三种刷盘策略,主要是标明主进程什么时候调用操作系统的fsync方法进行刷盘,aof缓冲区中的内容都是写完之后直接调用i/o系统的Write方法写入到page cache中)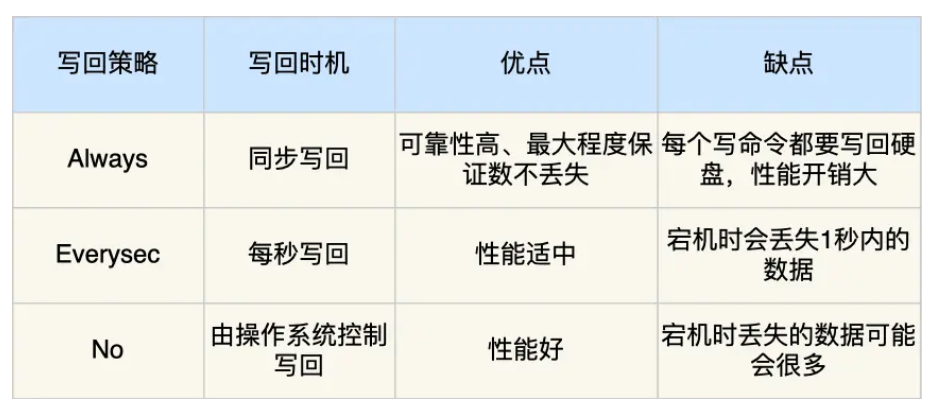
AOF重写
如果aof文件太大,那么就会触发aof文件的重写。主进程先fork一个子进程(就是复制了一份页面给子进程),子进程根据页表内容读取内存并写入到新的aof文件中(实际上是生成一个写这条内容的指令,并将这条指令保存下来)。这期间父进程和子进程是共享物理内存的,当父进程对某一块内存进行修改的时候,才会将这块内存原有的内容复制给子进程,父进程修改内存(所谓的写时复制)。这样就保证了子进程写的内容都是父进程fork时内存的样子。
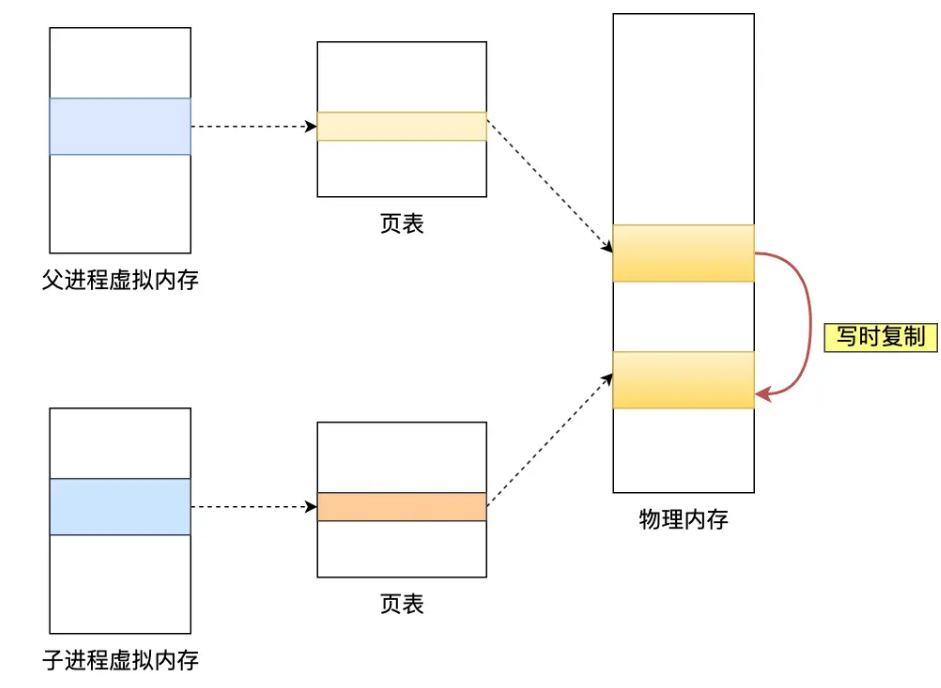
aof后台重写
当子进程生成新的aof文件时,主线程会正常执行内容(并不会阻塞),这些正常执行的操作将不止被缓存在aof缓冲区中,还会被写在aof重写缓冲区中。子进程将页表中的内容写好后,会告诉主进程已经重写好(发送一条信号)。主进程将aof重写缓冲区中的内容追加到新的aof文件中,然后将老aof文件覆盖。
rdb快照
有两种策略:save和bgsave。save是主进程完成快照生成工作,此时Redis会被阻塞,bgsave是fork一个子进程生成对应的快照。
其实逻辑跟aof重写差不多,只不过aof重写的时候是生成语句并保存,rdb重写是记录对应的数据内容,用的时候直接读取就可以了。并且rdb快照生成由于是全量复制,所以会很慢,需要平衡生成快照的时机和丢失内容多少的关系。(aof也是全量扫描,但有的内容可能在写的时候可以由一个可重复指令完成,因此某些情况下会比rdb快)
混合持久化
在aof重写时,不再生成读取内容生成指令,而是直接按照rdb的模式复制,在处理aof重写缓存的时候才是aof的记录语句的形式。
过期删除和内存淘汰
这两个操作并不相同:过期删除指的是我们可以对一个Redis对象设定存活时间,超出这个时间后删除对象时过期删除,内存淘汰则是当Redis的储存空间不足时,需要对一些对象进行删除
过期删除:
我们知道在设定一个Redis对象的时候,可以设置他的过期时间,那么如何对过期对象进行删除就有三种策略:
- 定时删除。这种策略指的是在设定一个可以过期的Redis对象时,同时也启动一个定时事件,事件到期后由一个专门的线程来对他进行删除。这种方法思路很简单,但实际使用会消耗太多资源,比如CPU时间等,并且也可能会导致一些热点数据同时大量被删除,因此这种删除策略并没有被采用
- 定期删除。这种策略说的是每过一段时间检查一部分的对象(一般是20个),删除过期的对象,如果说过期对象大于五个,就继续随机抽取然后删除,直到超时或者过期对象少于五个
- 惰性删除。这种指的是完全不检查,等到用的时候再看有没有过期,过期的话删除。这种策略的问题也十分明显:会有大量的过期对象没有被删除,占用空间
Redis使用的是定期和惰性结合,一方面会定期检查,另一方面使用对象的时候如果过期就删除
Redis实现了一个HashMap来储存每个可过期对象的对象地址和对应的创建时间,使用的时候比较这个创建时间。需要指明的是,这个HashMap和我们可使用的hash并不一样:我们使用的hash数据结构要求key是字符串,这个HashMap存的是地址,并且这个HashMap是Redis底层自己实现的,我们用不了
内存淘汰
当内存不够用的时候,就需要淘汰一些不常用的对象。淘汰手段一般是LRU和LFU。LRU指的是找到最久没有使用的,LFU指的是使用次数最少的。Redis对这两个都做了优化
- LRU:每个对象储存最近被使用的时间,删除的时候随机采样五个,删除最久没用的内个
- LFU:这个相对复杂一点,Redis给每个对象增加了一个LFU字段,这个字段记录了上次使用的时间和一个标志使用频次的数,这个频次的数初始为5,对象每次被使用时会先减1,然后根据上次使用时间和现在的时间算一个权重出来,频次再加上这个权重作为最终的结果
具体使用哪个Redis提供了一些参数,修改这些参数就行了
主从复制
Redis的主从复制主要是为了多备份几个数据库保证数据的高可用(其实就是数据备份)主要需要考虑两个问题:一个是数据如何同步,或者说是叫主从复制;令一个是主服务器掉了怎么办,采取的措施是哨兵模式
主从复制
主从复制主要考虑:新服务器来了如何复制;复制完之后后续如何维持
- 第一次同步(从服务器来了,全量复制):从服务器和主服务器建立链接,从服务器请求进行全量复制。主服务器收到之后fork一个子进程来生成一个rdb文件,将这个rdb文件发给从服务器。从服务器收到这个rdb文件之后清空之前的数据,将rdb文件中的内容写入。注意这里有个问题,从主服务器fork子进程开始写到最后从服务器加载完rdb文件,这中间主服务器依然在写入新数据,这部分新数据储存在一个缓冲区中。当从服务器加载完数据返回一个ack给主服务器后,主服务器把这些内容再发给从服务器
- 命令传播(后续维持):主从服务器之间维持一个TCP连接,主服务器将写入的操作命令不断发给从服务器。这里要考虑一个小情况:如果出现短暂的断网怎么办。如果短暂断网,会有一分部数据丢失,但是丢失的又不多,没必要进行全量复制。为了处理这种情况,主服务器维持了一个已复制偏移量和一个增量复制缓冲区。这个缓冲区是环形的,如果说偏移量还在这个缓冲区中,那么就从这个位置开始复制,如果不在的话就认为断开太久了,进行全量复制
哨兵模式
考虑:如果主服务器因为某种原因断开连接了怎么办(分为三部分,如何判断下线和如何找到新的主服务器,以及如何通知所有的节点和客户端有新节点了)
- 判断下线:有不止一个的哨兵节点来监控主服务器,定期发送ping消息。如果收不到pong的话就认为他主观下线。这时候他会询问其他的哨兵是否认为主节点主观下线,如果超过半数的话,就认为主服务器客观下线。判断客观下线之后,曾经判断主观下线的哨兵成为leader,通过投票选举出一个leader。这个leader选择一个从服务器作为新的主服务器
- 从三个标准寻找新的主服务器:先看从服务器直接的优先级,优先级一样的话看谁的复制偏移量靠后,如果还一样的话看从服务器节点编号
- 选到新的主服务器之后通知主服务器下线,通知所有的从服务器新主节点已经选出,通知所有的客户端新节点
cluster集群
前面说的是为了维持Redis的高可用(数据备份),cluster集群则是为了实现负载均衡
具体实现是定义一个名为哈希槽的东西,总共16384(2的14次方)个。客户端每次尝试存key的时候,会先根据key算一个哈希值,根据这个哈希值和看他属于哪个槽,再看这个槽属于哪个切片。最后把这个数据发给对应的切片。
那么在发送的时候可能会出现两种异常情况:1、集群中新增或减少了切片,导致槽到切片的真实定向发生了改变,但客户端不知道,这就导致定向错误。这个时候会触发moved重定向。切片向客户端返回key对应的正确节点的地址。2、切片收到key的时候正处于新增或减少切片的时间,那么这个时候就会发生ask重定向。客户端向新节点再发送一次asking然后再发送key内容
具体应用:
布隆过滤器
可以把他理解成一个只能添加和查找元素是否存在的数据结构(某种意义上的Hashmap?)
他的特点是可以实现快速查找,但查找只能保证他认为不在的不在,他认为在的也不一定在
布隆过滤器底层数据结构是一个长二值数组。同时设置了几个hash函数。
每次插入元素时,就计算这个元素对应的hash值,并将关于数组长度取模后的对应位置的值设为1。
在查询的时候,计算这个元素在数组中对应的几个位置(也是根据hash值取模得到的),如果全为1,那么认为他存在(当然也可能不在)。
应用场景:解决redis缓存穿透
实际使用:Redis其实并没有实现所谓的BitMap数据结构,他是依赖字符串实现的。在我的项目中,布隆过滤器是这样设计的:
首先根据公式计算出需要的哈希函数数量和数组长度:n是预估的数量个数,p是误判率
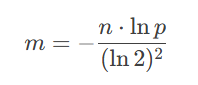
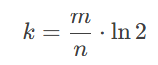
计算得到的m就是需要的布隆过滤器长度(指定的字符串所占的比特数),k是需要的哈希函数个数,取整。
选择一个哈希函数(我选的是一个,不是k个!)比如md5,计算当前元素的哈希值。将计算的到的哈希值拆成k分,每份再计算一个hashCode(),对长度取模就得到一个数组,长度为k。加入的时候将这个数组每一位上的值设置为true。查找的时候就看对应位有没有false,只要有一个就说明当前元素没有被加入过。
分布式锁
分布式锁的实现也是字符串。具体来说,每个进程(或者线程)公用一个Redis的时候就可以设计分布式锁,使得只有一个线程可以使用资源。
分布式锁主要依赖字符串的setIfAbsent和get方法。当一个线程尝试获取锁的时候,就会在Redis中尝试设置一个字符串,设置成功的话就相当于成功获取了锁,否则就是获取锁失败,任务结束之后删除字符串就相当于释放了锁。
单一Redis节点需要考虑这几个问题:
- 某个线程在删除字符串时,要确保这个字符串是他自己设置的
- 要保证删除操作是原子的
- 释放锁之前锁不能自动过期
对于第一个问题,我们考虑这个场景:两个线程都想要获取锁,线程A获得锁,但超时了,锁自动释放,线程B新建了锁,线程A执行完任务删除了锁,但这时他删除的是线程B新建的锁。解决思路就是用字符串的key当做锁名,value当做线程对锁的持有证
第二个问题,要先检查锁存在才能释放,这中间存在时间,这段时间里可能会出现锁过期然后另外一个线程新建锁的问题,因此要让Redis一次性检查并且释放。具体实现思路就是使用lua脚本。Spring中,用字符串写好脚本然后提交execute。
第三个问题,采用看门狗机制,对所有的任务线程设计一个定时任务线程池,新建任务线程的时候就把自己线程的信息传递给看门狗,看门狗定期用收到的信息执行锁延时任务:只要线程还在运行,就延长锁。任务线程结束之后再中断这个定期任务。(注意这里要用到线程的ThreadLocal来记录每个线程独立的信息,比如他的锁名,锁持续时间等等)
如果多Redis节点的话需要考虑redLock,但我这里是单节点就没有实现

)



