TL;DR
- 2024 年莱斯大学提出的无需微调的 2bit KV 缓存量化算法 KIVI,可以使 Llama、Falcon 和 Mistral 模型在使用 2.6 倍更少的峰值内存(包括模型权重)的情况下保持几乎相同的质量。
Paper name
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Paper Reading Note
Paper URL:
- https://arxiv.org/pdf/2402.02750
Introduction
背景
- KV 缓存带来的挑战
- 随着批处理大小的增加和上下文长度的延长,存储注意力键和值以避免重复计算的键值(KV)缓存显著增加了内存需求,并成为速度和内存使用的新瓶颈
- 例如:在 540B PaLM中,批处理大小为 512,上下文长度为 2048 时,仅 KV 缓存就可能占用 3TB。这是模型参数大小的 3 倍
- 另外 KV 缓存的加载导致计算核心处于空闲状态,从而限制了推理速度
- 随着批处理大小的增加和上下文长度的延长,存储注意力键和值以避免重复计算的键值(KV)缓存显著增加了内存需求,并成为速度和内存使用的新瓶颈
- 目前缺乏深入研究来探索KV缓存的元素分布,以了解KV缓存量化的难度和限制
本文方案
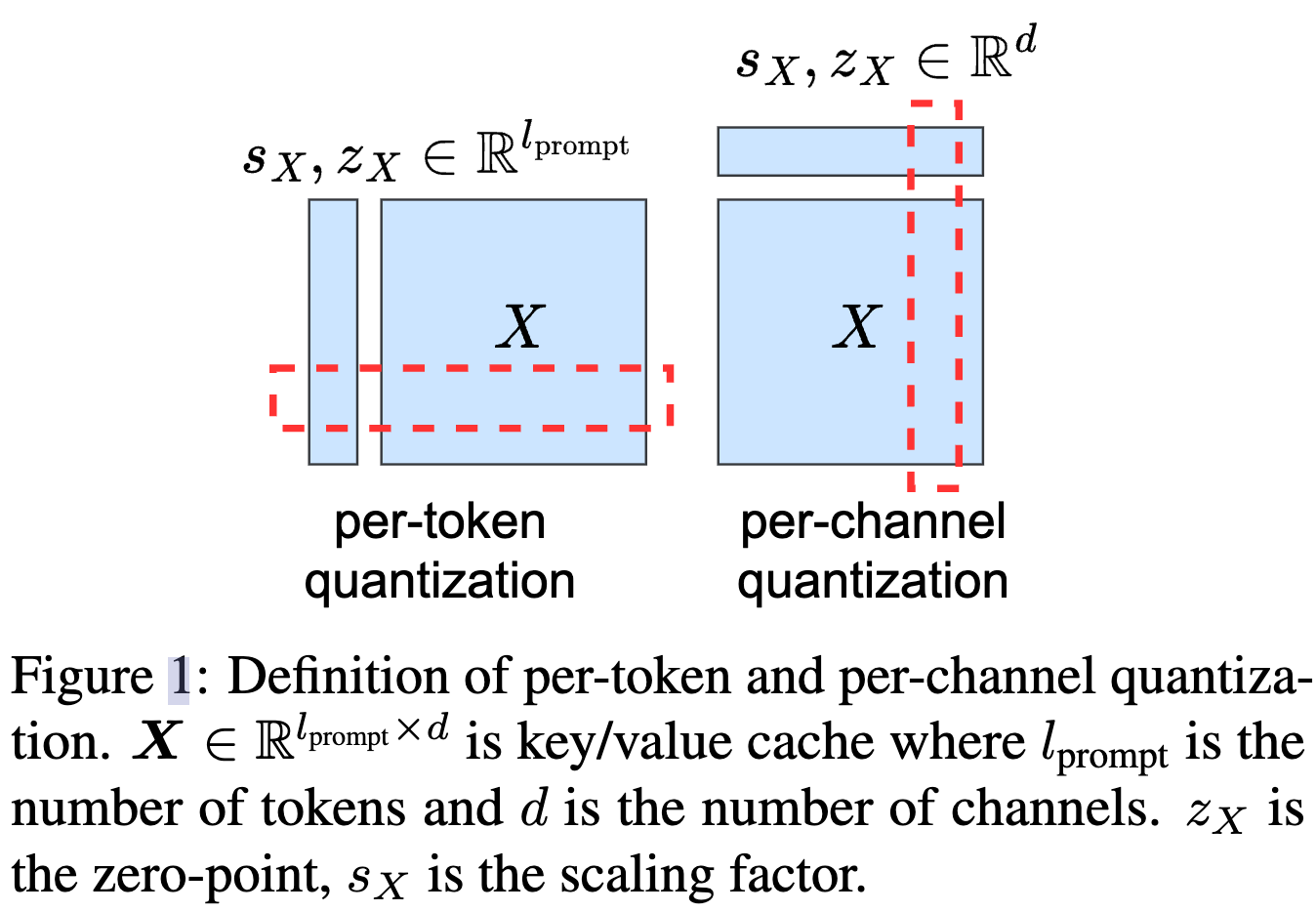
开发了一种无需微调的 2bit KV 缓存量化算法,名为 KIVI
- 键缓存应按通道进行量化,即沿通道维度对元素进行分组并一起量化。相反,值缓存应按 token 进行量化
- 对于键缓存,有一些固定通道的幅度非常大
- 尽管值缓存没有明显的异常模式,但本文通过实验表明,它只能按 token 进行量化,因为它用于计算注意力输出,本质上是一个值缓存混合器
- 可以使 Llama、Falcon 和 Mistral 模型在使用 2.6 倍更少的峰值内存(包括模型权重)的情况下保持几乎相同的质量
- 内存使用的减少使得批处理大小可以增加至 4 倍,在实际 LLM 推理工作负载中带来 2.35 倍至 3.47 倍的吞吐量
Methods
背景:注意力机制在推理阶段的工作流程
大语言模型(LLM)的注意力机制在推理阶段的工作流程分为两个阶段:
i) 预填充阶段(Prefill Phase):使用输入提示(prompt)为每个 Transformer 层生成键值缓存(KV Cache);
ii) 解码阶段(Decoding Phase):模型利用并更新 KV 缓存,逐个生成下一个 token。
预填充阶段
设输入张量 X ∈ R b × l prompt × d X \in \mathbb{R}^{b \times l_{\text{prompt}} \times d} X∈Rb×lprompt×d,其中:
- b b b 为 batch size(批量大小),
- l prompt l_{\text{prompt}} lprompt 为输入提示的长度,
- d d d 为模型的隐藏层维度。
为了便于说明,这里省略了层数索引。键(Key)和值(Value)张量可通过以下方式计算:
X K = X W K , X V = X W V X_K = X W_K, \quad X_V = X W_V XK=XWK,XV=XWV
其中 W K , W V ∈ R d × d W_K, W_V \in \mathbb{R}^{d \times d} WK,WV∈Rd×d 分别是键和值对应的权重矩阵。获得 X K X_K XK 和 X V X_V XV 后,它们会被缓存在内存中,供后续解码阶段使用。
解码阶段
令 t ∈ R b × 1 × d t \in \mathbb{R}^{b \times 1 \times d} t∈Rb×1×d 表示当前输入 token 的嵌入向量。定义:
t K = t W K , t V = t W V t_K = t W_K, \quad t_V = t W_V tK=tWK,tV=tWV
分别为键和值层的输出。我们首先更新 KV 缓存:
X K ← Concat ( X K , t K ) , X V ← Concat ( X V , t V ) X_K \leftarrow \text{Concat}(X_K, t_K), \quad X_V \leftarrow \text{Concat}(X_V, t_V) XK←Concat(XK,tK),XV←Concat(XV,tV)
然后计算注意力输出:
t Q = t W Q A = Softmax ( t Q X K ⊤ ) t O = A X V (1) t_Q = t W_Q \\ A = \text{Softmax}(t_Q X_K^\top) \\ t_O = A X_V \tag{1} tQ=tWQA=Softmax(tQXK⊤)tO=AXV(1)
其中 W Q ∈ R d × d W_Q \in \mathbb{R}^{d \times d} WQ∈Rd×d 是查询层的权重矩阵。为便于说明,忽略了注意力输出层及其他推理流程中的组件。
内存与速度分析
上述过程会持续进行,直到遇到表示句子结束的特殊 token。假设共生成 l gen l_{\text{gen}} lgen 个 token。
根据上述分析,KV 缓存的形状为:
b × ( l prompt + l gen ) × d b \times (l_{\text{prompt}} + l_{\text{gen}}) \times d b×(lprompt+lgen)×d
以 OPT-175B 模型为例,当 batch size b = 512 b = 512 b=512、prompt 长度 l prompt = 512 l_{\text{prompt}} = 512 lprompt=512、输出长度 l gen = 32 l_{\text{gen}} = 32 lgen=32 时,KV 缓存需要 1.2TB 的内存空间,是模型权重大小的 3.8 倍。
除了内存开销之外,KV 缓存的大小也直接影响推理速度。GPU 在每次生成 token 时都需要将 KV 缓存从主显存加载到 SRAM 中,在此期间芯片的计算核心基本处于空闲状态。
KV 缓存量化的初步研究
在表 1 中,展示了在 Llama-2-13B 模型上对 CoQA 和 TruthfulQA 任务进行不同配置的伪 KV 缓存逐组量化的结果。伪量化意味着我们通过先将KV缓存量化为较低精度,然后在注意力层中去量化来模拟量化过程
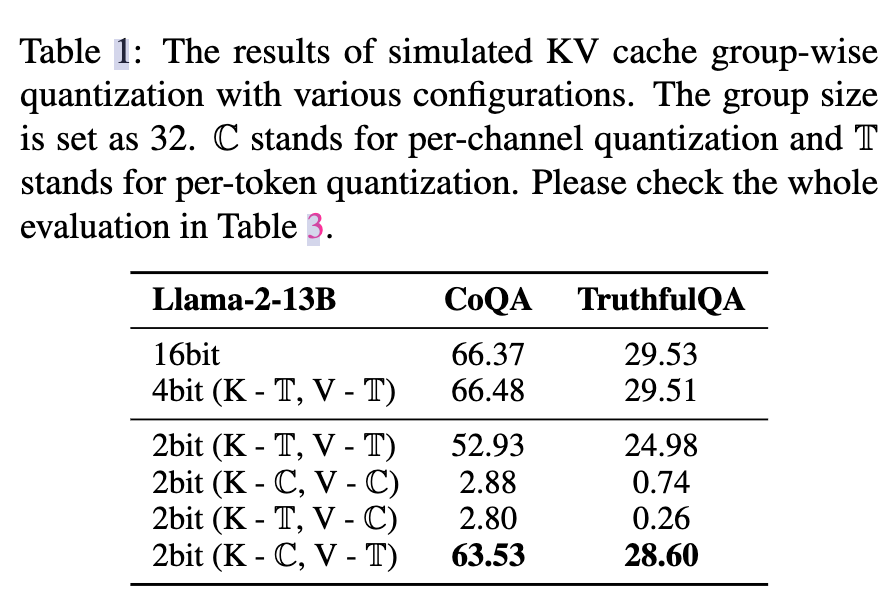
观察1:当对键缓存和值缓存均使用常用的逐 token 量化时,INT4 精度可以保持准确性。然而,将其降低到 INT2 会导致明显的准确性下降。
观察2:当值缓存按通道量化时,无论键缓存如何量化,准确性都会显著下降。
观察3:当使用较低的数值精度(如 INT2)时,最准确的方法是按通道量化键(K)缓存,按 token 量化值(V)缓存。
为什么键缓存和值缓存应沿不同维度量化?
K 缓存量化分析
可视化了不同层中原始KV缓存的分布:在键缓存中,某些固定通道表现出非常大的幅度,而在值缓存中,没有明显的异常值模式。
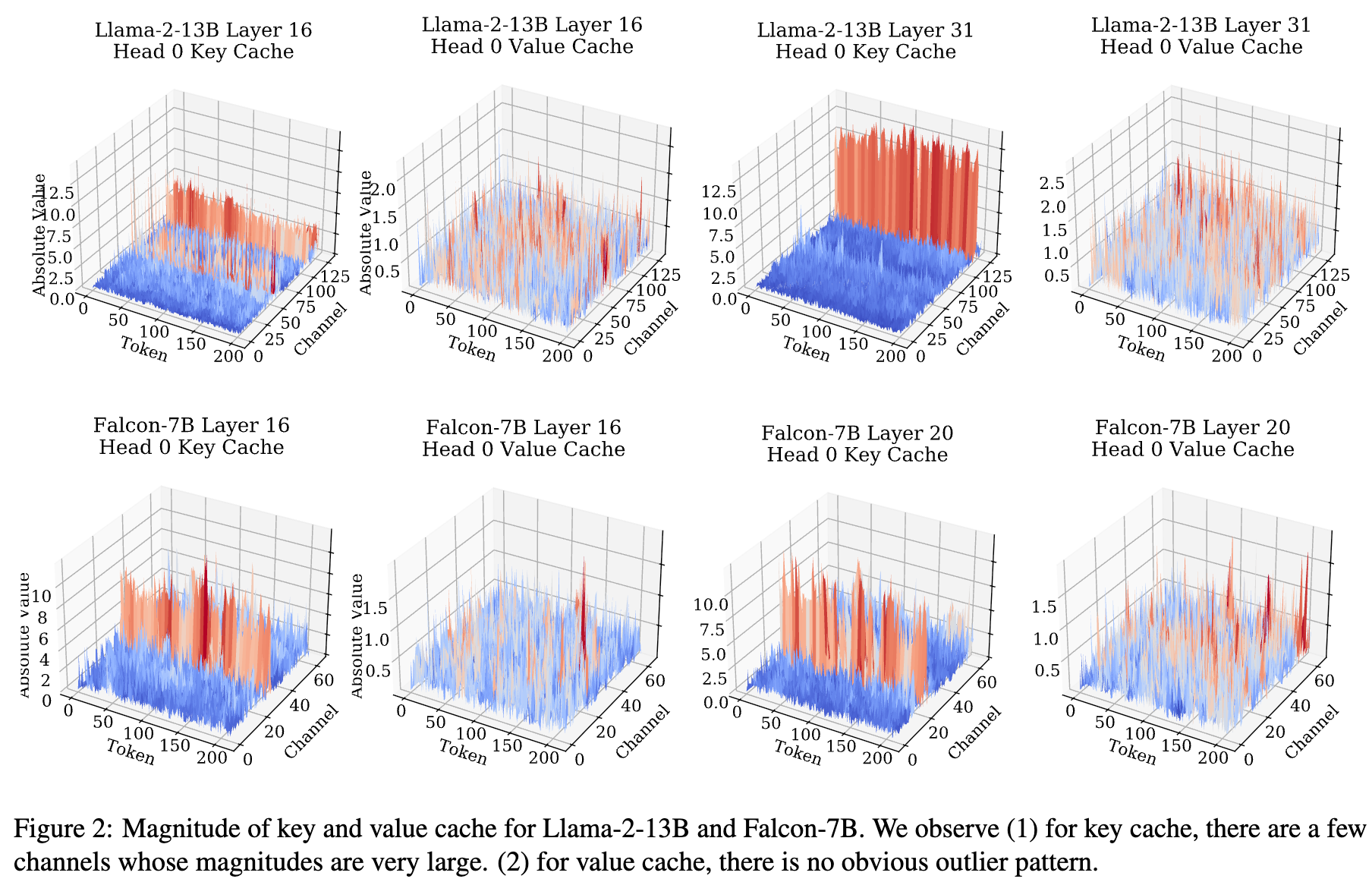
- K 按 token 量化会导致注意力得分误差比按通道量化大近5倍
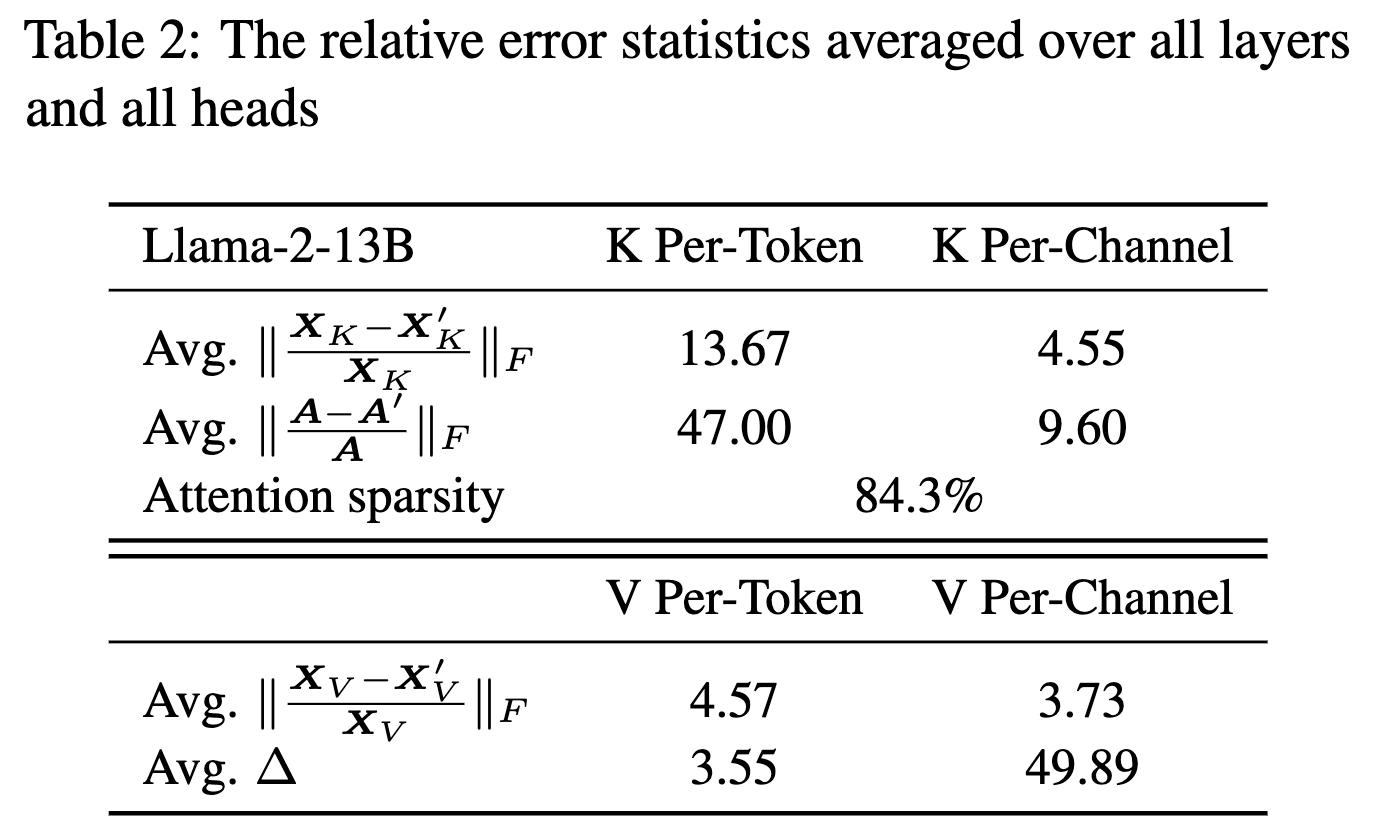
V 缓存量化分析
值缓存没有显示出按通道的异常值模式。但是基于表 2 结果来看,V 按 token 量化的误差比按通道量化小近 15 倍。
- 【分析】注意力输出是值缓存在不同令 token 的加权求和,权重为注意力得分。由于注意力得分高度稀疏,输出仅是少数重要 token 的值缓存的组合。按 token 量化可以将误差限制在每个单独 token 上。因此,量化其他 token 不会影响重要 token 的准确性。因此,按 token 量化导致相对误差 Δ 显著减小。
提出的 KIVI 方案
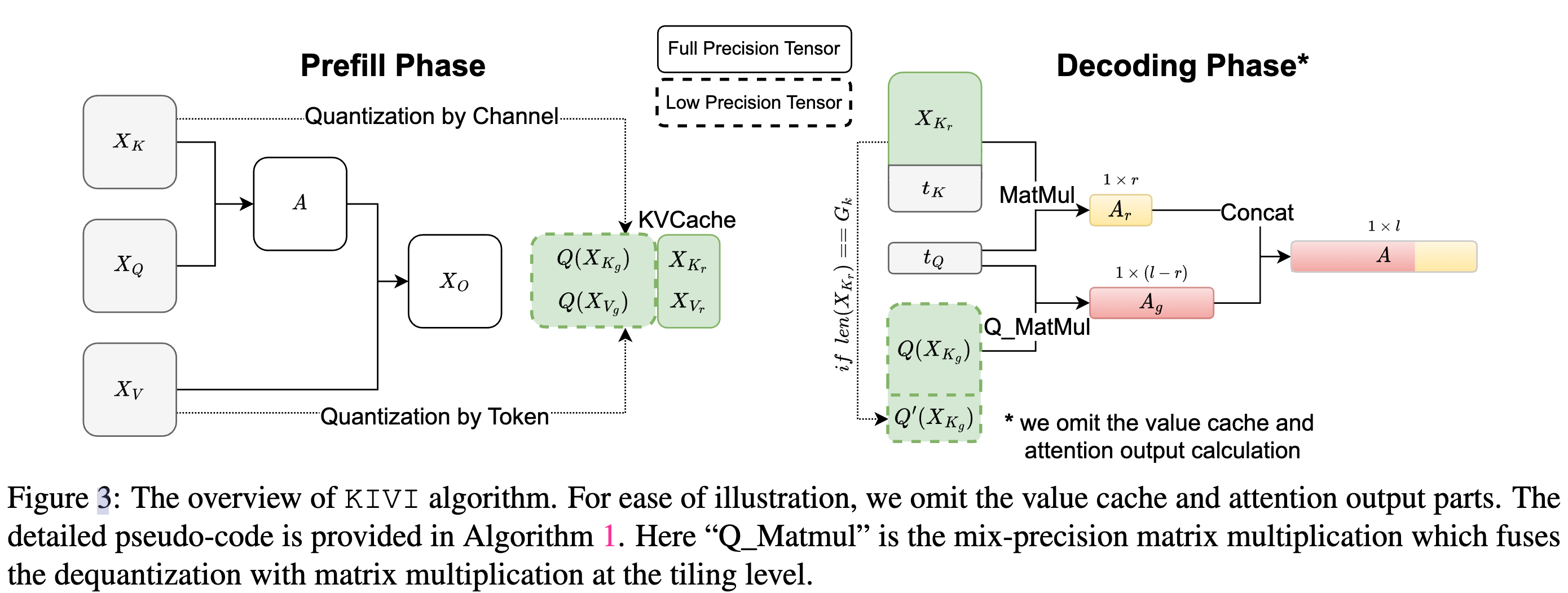
- KIVI 按通道量化键缓存,并按 token 量化值缓存。
- 按 token 的值缓存量化与自回归推理的流式特性很好地对齐,允许新量化的张量按token维度直接附加到现有的量化值缓存中。
- 然而,对于按通道的键缓存量化,量化过程跨越不同的 token,无法在这种流式设置中直接实现。由于键缓存中的 token 数量可以是任意的,本文的关键想法是将键缓存分为两部分。第一部分是分组键缓存,包含若干组 token,每组有一定数量的 token。第二部分是残余键缓存,没有足够的 token 形成完整的组。类似地,本文将值缓存分为分组和残余部分以保持准确性。仅对分组键缓存和值缓存应用分组量化,而残余键缓存和值缓存保持全精度。在计算注意力分数时,可以使用平铺矩阵乘法将分组和残余部分结合起来。
Experiments
实验配置
- 使用三种流行的模型族来评估 KIVI:Llama/Llama-2,Falcon 和 Mistral。Llama 和 Mistral 模型基于多头注意力机制,而 Falcon 基于多查询注意力机制
- 使用 Hugging Face Transformers 代码库并在其基础上实现了 KIVI 算法
- 量化算法中的组大小 G 设为 32,键值缓存的残差长度 R 设为 128
- 采用 LM-Eval 中的生成任务进行正常上下文长度评估,使用 LongBench 进行长上下文评估
不同量化配置之间的比较
- 首先使用假量化(fake quantization)来展示我们非对称量化的有效性
- “2bit (K per-channel, V per-token)” 配置始终优于所有其他配置,即对键缓存按通道量化,值缓存按 token 量化有效
- 假 “2bit (K per-channel, V per-token)” 量化与 KIVI 的区别在于,KIVI 保留了一个局部相关 token 的滑动窗口的全精度键值缓存,所以 GSM8K 上的准确率 KIVI 比假 “2bit (K per-channel, V per-token)” 量化好
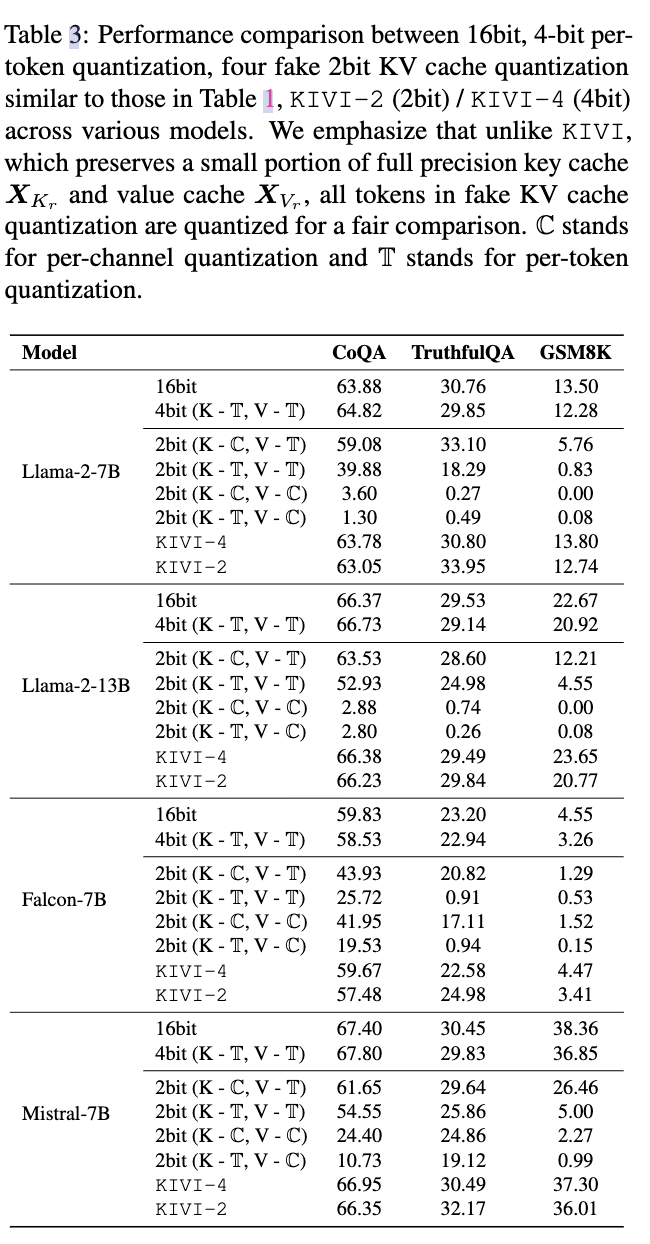
- MQA 的压缩最好就到 4bit,MHA 可以压缩到 2bit
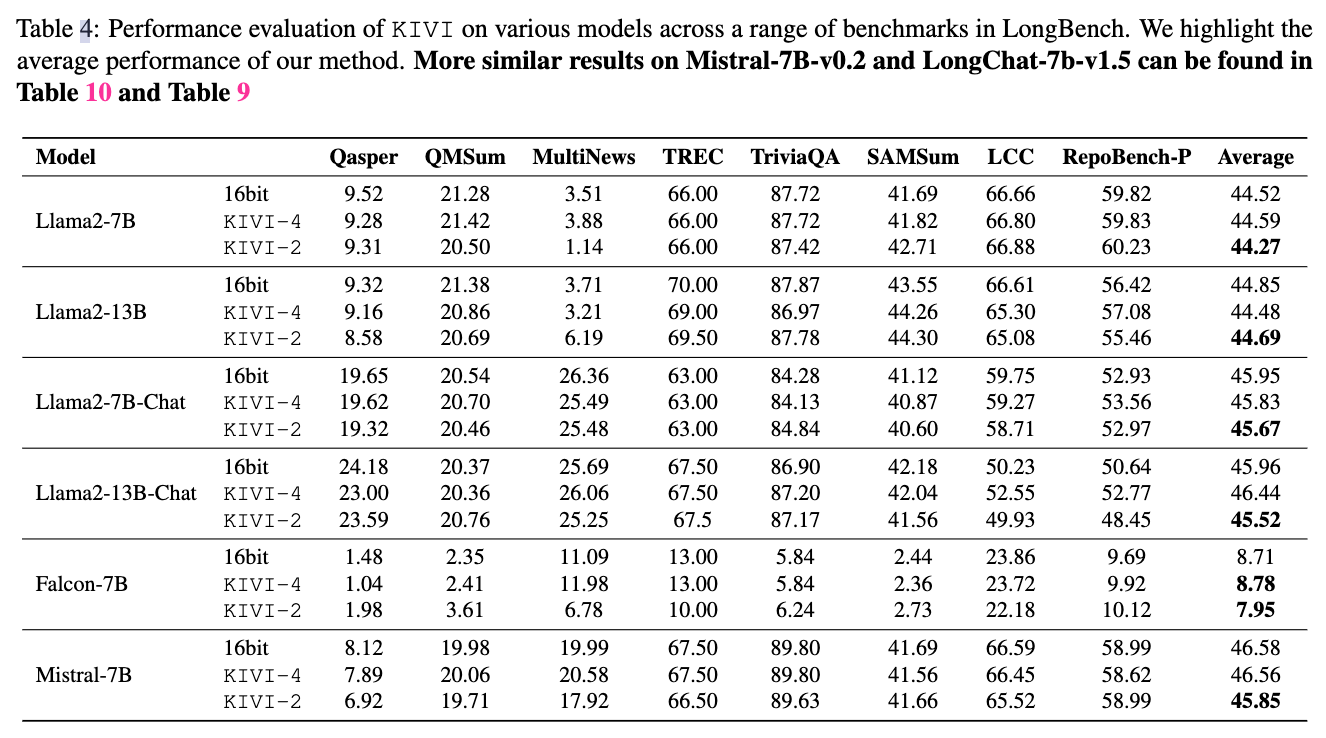
生成任务上的准确性对比
KIVI 是一种有效的 KV 缓存压缩方法,在各种模型和任务上对准确率的影响最小
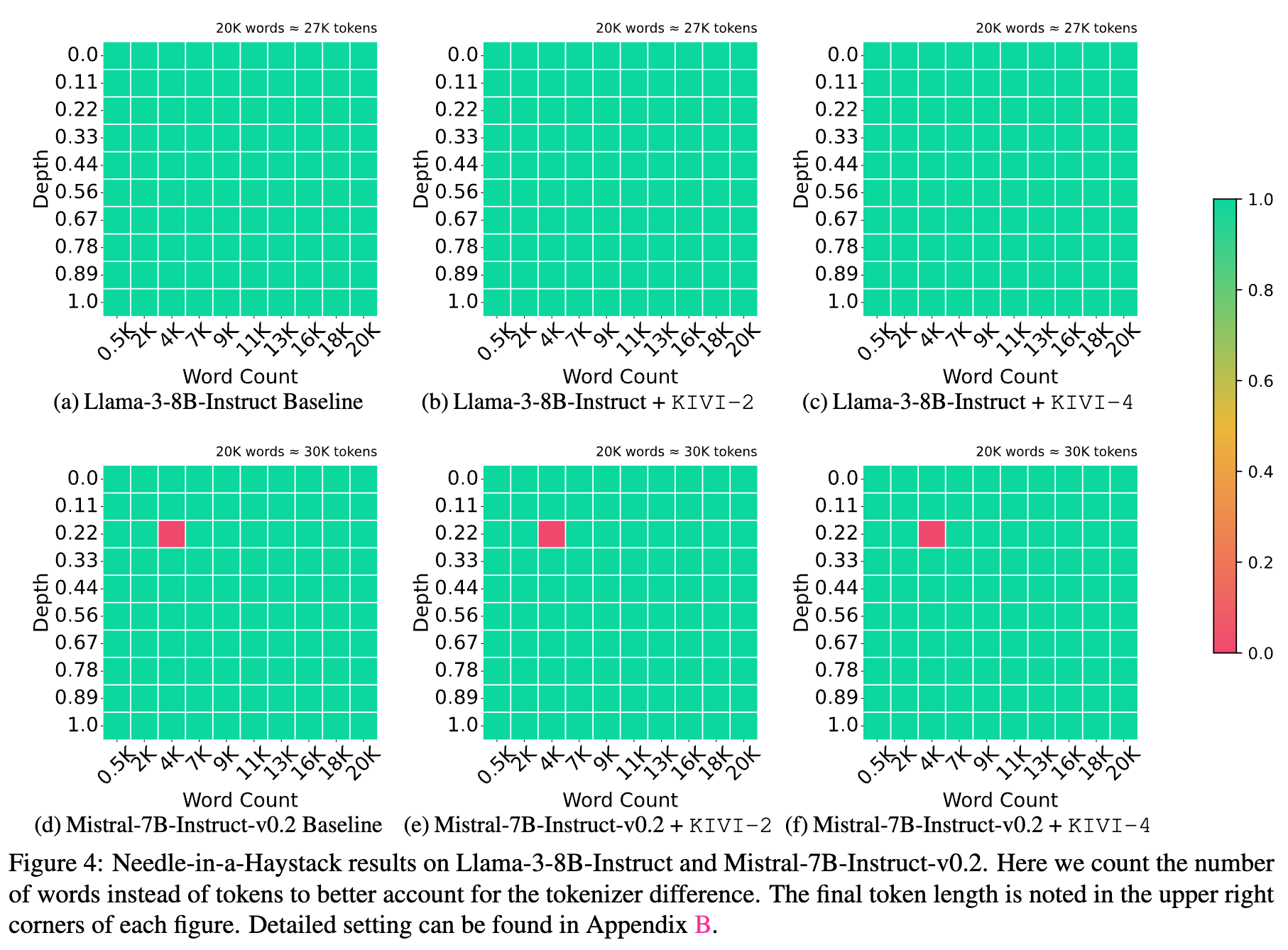
长上下文检索能力
- “大海捞针”(NIAH)任务来评估 KV 缓存量化后模型的长上下文检索能力,量化后没有区别
效率对比(Efficiency Comparison)
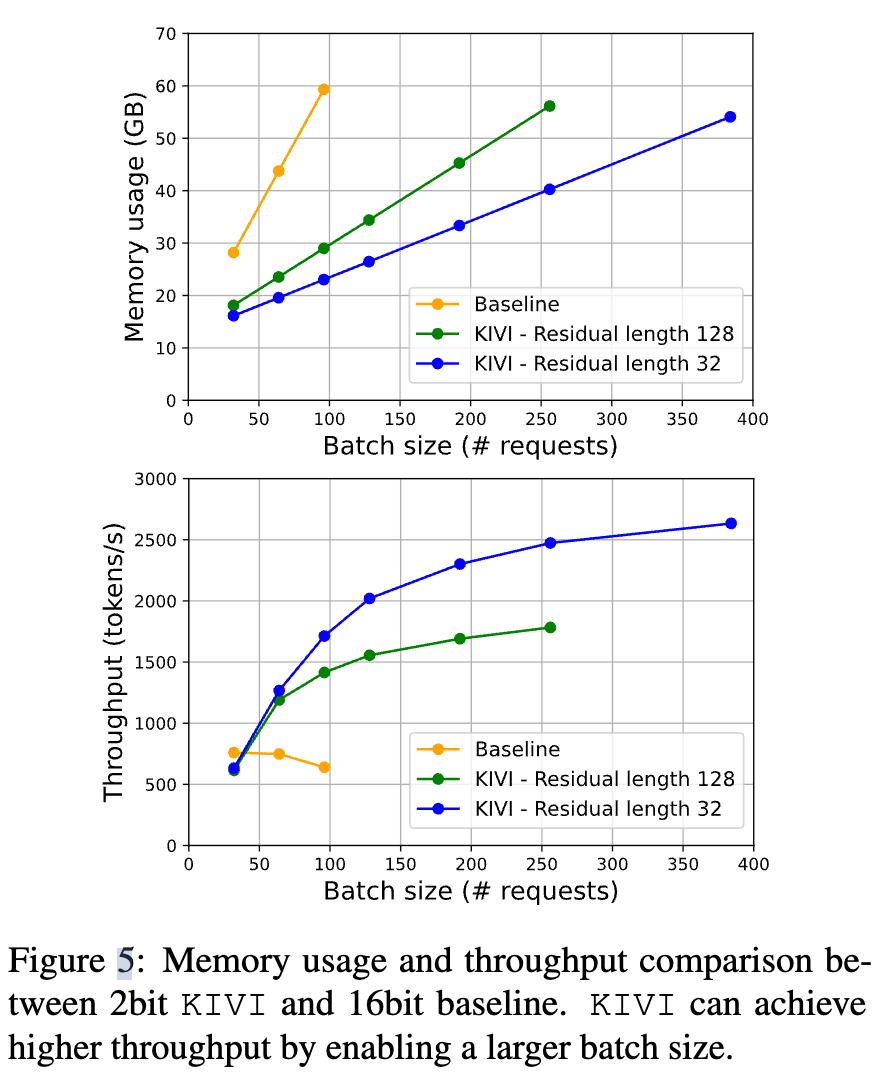
- 参考 vLLM(Kwon 等,2023),基于 ShareGPT(sha,2023)合成工作负载,这些数据集包含真实 LLM 服务中的输入和输出文本。平均而言,该数据集的输入提示长度(l_prompt)为 161,输出长度(l_gen)为 338(Kwon 等,2023)。我们不断增加批处理大小直到内存溢出,并报告了 KIVI(残差长度分别为 32 和 128)与 FP16 基线方法在 Llama-2-7B 模型上的峰值内存使用量和吞吐量。实验硬件为单块 NVIDIA A100 GPU(80GB)。
- 在最大内存使用量相近的情况下,KIVI 支持高达 4 倍的批处理大小,并带来 2.35× 至 3.47× 的更高吞吐量
Conclusion
- 当时第一个能把 kv cache 量化到 2 bit 同时还能保持性能的方案,KIVI 保留了一个局部相关 token 的滑动窗口的全精度键值缓存应该是比较有效的
- 从 KIVI 的 代码实现 来看,量化是在作用 ROPE 位置编码后进行的,这里位置编码对于量化的影响可能值得进一步分析和研究





