Prompt-Free Diffusion: Taking “Text” out of Text-to-Image Diffusion Models
2026/4/26 0:52:37
来源:https://blog.csdn.net/weixin_44994838/article/details/140172470
浏览:
次
关键词:Prompt-Free Diffusion: Taking “Text” out of Text-to-Image Diffusion Models
- CVPR2024 SHI Labs
- https://arxiv.org/pdf/2305.16223
- https://github.com/SHI-Labs/Prompt-Free-Diffusion
- 问题引入
- 在SD模型的基础之上,去掉text prompt,使用reference image作为生成图片语义的指导,optional structure image作为生成图片structure的指导来进行生成;
- 使用SeeCoder来提取参考图片的embedding作为生成条件,且SeeCoder是可以重复使用的,可以直接集成到另外的T2I模型中;
- methods
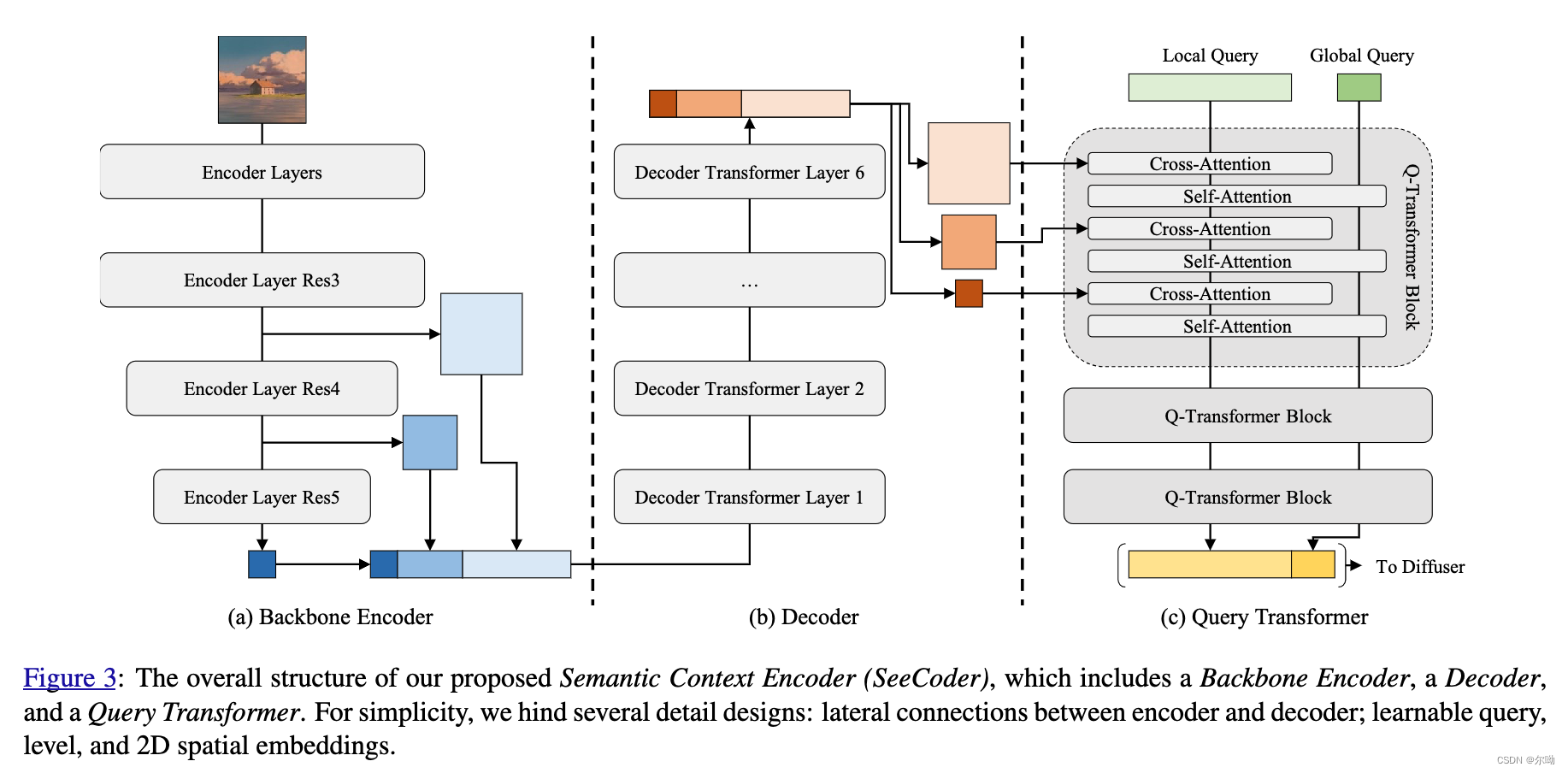
- 使用SeeCoder代替CLIP text embedding;
- SeeCoder包含三个部分,Backbone Encoder, Decoder, and Query Transformer,其中Backbone Encoder使用SWIN-L提取多尺度特征,该部分参数是冻结的;之后decoder使用卷积来使得多尺度特征通道数相同,然后进行flatten+concat,得到的结果通过self attn + ffn;之后Query Transformer输出视觉embedding;





