一、背景
编写C程序时有一类看似简单实则经常暗藏漏洞的问题就是字符串的处理。对于字符串的处理,常用的函数如strcpy,sprintf,strcat等,这些函数的区别无外乎就是处理'\0'结尾相关的逻辑。字符串的长度有时候并不能很好确定,尤其字符串的最大长度,所以,C程序里,定义多大数组给到一个字符串一直是一个令人头疼的事情。当然,我们可以用C++的string来做字符串的处理,但是,有时候我们考虑到内存的不必要的浪费以及更好的性能,我们在一些逻辑里还是会用C的char数组方式,为了更加直观和性能更优。而使用C的char数组的方式来进行字符串处理就不可避免的要考虑一些corner case,其中最主要的就两种:
1)src的字符串某一个较长导致dst的字符串容量放不下;
2)src的字符串在某些逻辑下可能因为没有赋值导致在拷贝时一直不断地进行拷贝,导致地址越界触发用户态的segment fault或内核态的panic;
这篇博客里,我们针对常用的内核态里的容易产生误判的字符串处理函数和用户态字符串处理函数进行一定的实验,来避免未来潜在字符串处理相关的“阴沟里翻船”。
二、内核态函数strlcpy及strscpy
内核态函数里有两个与字符串处理相关的功能接近的函数,一个是strlcpy还有一个是strscpy。
2.1 内核态strlcpy函数
下图是strlcpy的内核文档关于它的注释:
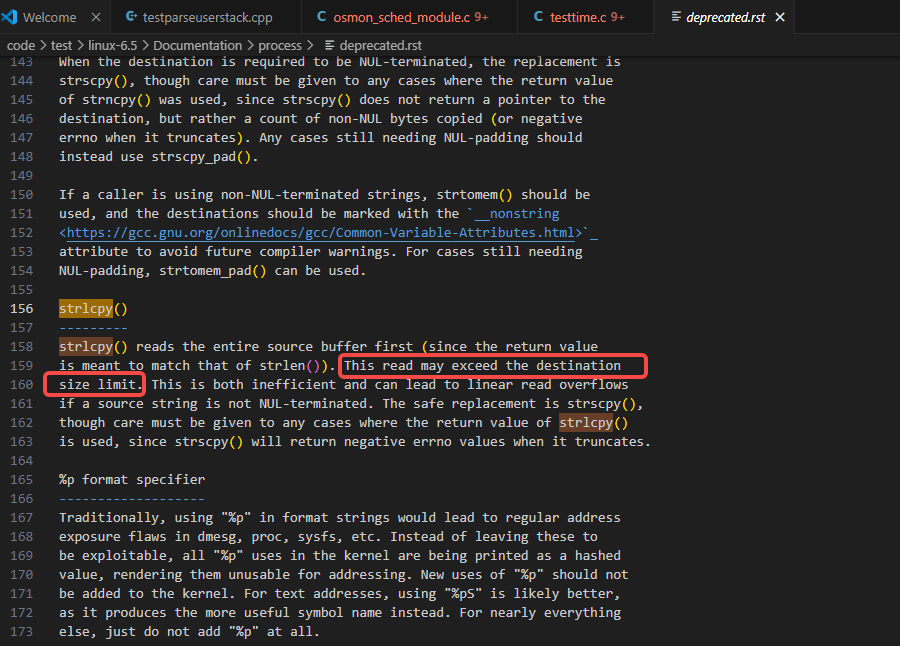
如上图可以看到,strlcpy在做字符串拷贝时,可能会因为src的字符串一直没读到\0而导致访问到了越界的内存,这在内核逻辑里是非常危险的,会导致panic及其他异常(之前遇到过因为某处赋值写到了不该写的范围时尤其是栈上的范围时,把栈上的一些link类的pc地址给写掉导致代码乱执行出现一些非panic类的异常,后来查下来都是因为越界写导致)。
2.2 strlcpy函数的实验
我们编写一个测试代码来进行strlcpy的使用测试,看其返回值及运行效果。
代码如下:
char testa[20];char testb[20] = "helloworld";ssize_t ret;for (int i = 0; i < 20; i++) testa[i] = 1;printk("%d", strlcpy(testa, testb, 5)); // strlcpy 会把source读完,可能导致问题,用strscpy更好//strncpy(testa, testb, 5);for (int i = 0; i < 7; i++) printk("testa[%d]=%d\n", i, (int)testa[i]);测试打印如下:
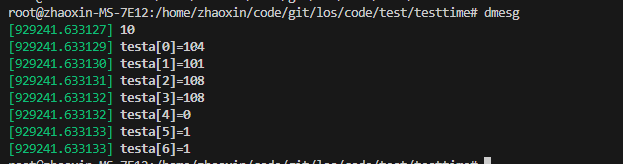
可以如上图看到,strlcpy的返回值是src字符串的有效字符个数,所以,就算如上面代码设置了strlcpy的第三个参数为5,它仍然遇到\0才会停止,才有的返回是10的结果。这其实是很危险的。
2.3 strscpy函数及其实现
而strscpy函数就可以避免上面介绍的strlcpy函数在访问时的越界情况,如下面的注释里的内容:
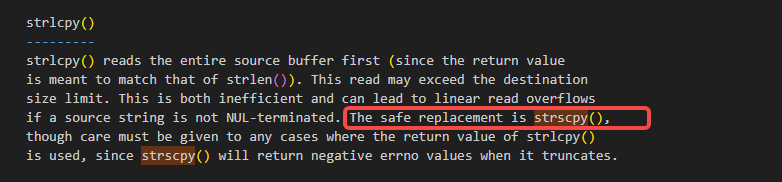
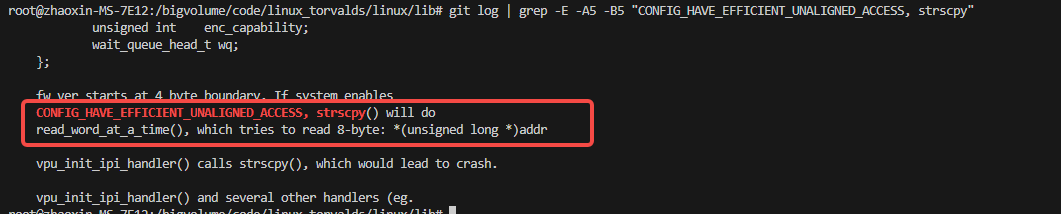
我们看一下strscpy的内核里的实现:
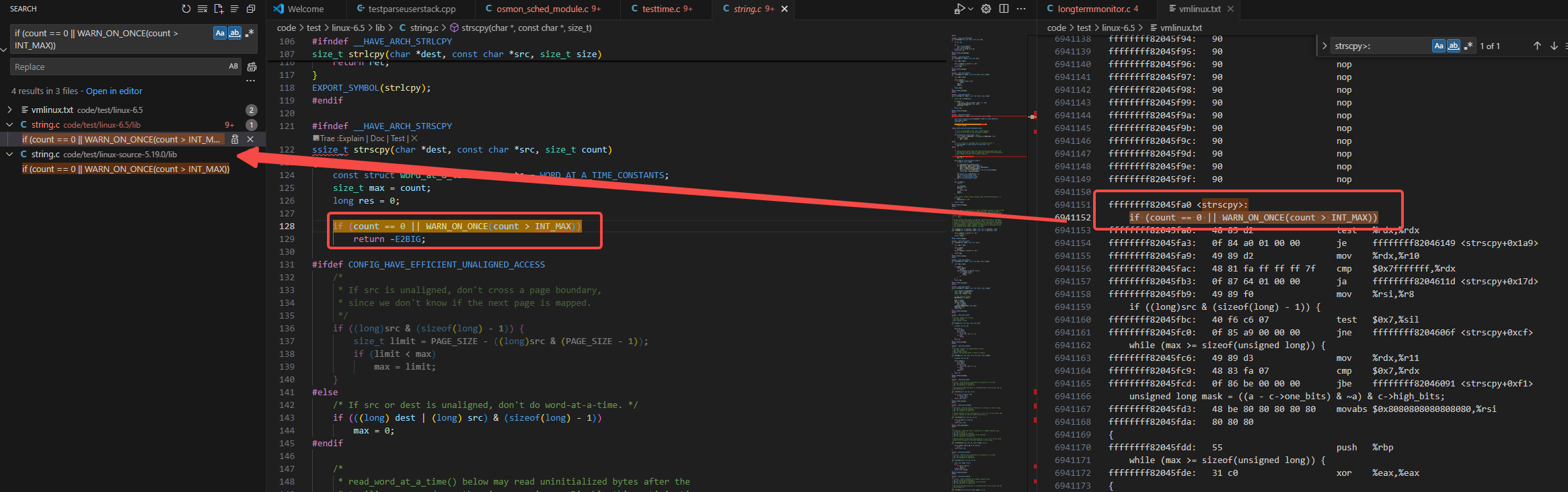
是在lib/string.c里定义的实现。
如下图里可以看到在当前的x86环境下,CONFIG_HAVE_EFFICIENT_UNALIGNED_ACCESS宏是打开的:
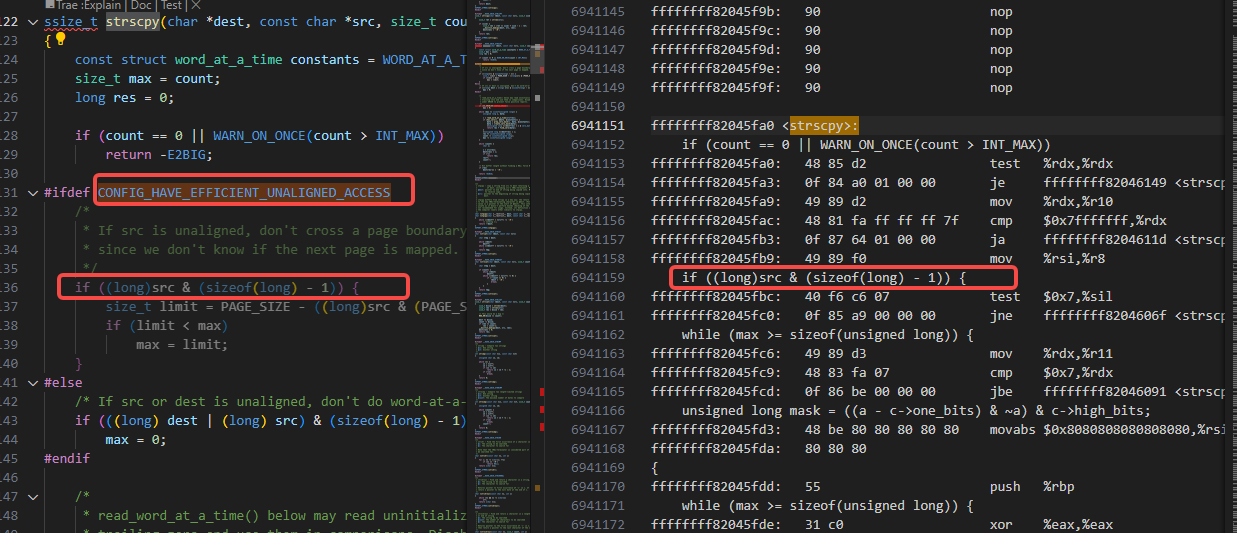
而CONFIG_HAVE_EFFICIENT_UNALIGNED_ACCESS宏是为了加速性能,可以在dest并没有按照8字节对齐的情况下也能一个个word进行拷贝:
如果没有使能这个CONFIG_HAVE_EFFICIENT_UNALIGNED_ACCESS功能,得是dest和src都得是8字节对齐:

另外,CONFIG_HAVE_EFFICIENT_UNALIGNED_ACCESS功能开启后,还需要确保没有page越界,这是因为最后的一些字节可能会因为写时考虑到8字节对齐而多写入一些内容(这是违反函数执行的一般性预期的),而这些多写入的部分是否已经映射在执行strscpy时无法快速进行判断,所以把超过当前page的这部分内容就不用该加速功能了。
2.4 strscpy函数的实验
同样是差不多的实验代码,只是把strlcpy改成strscpy,如下:
char testa[20];char testb[20] = "helloworld";ssize_t ret;for (int i = 0; i < 20; i++) testa[i] = 1;printk("%d", strscpy(testa, testb, 5)); // strlcpy 会把source读完,可能导致问题,用strscpy更好//strncpy(testa, testb, 5);for (int i = 0; i < 7; i++) printk("testa[%d]=%d\n", i, (int)testa[i]);运行后的日志如下:
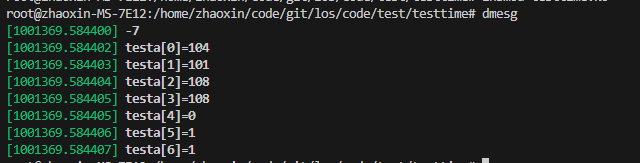
可以看到,strscpy和strlcpy一样都会自动补齐最后的一个\0,不一样的是strscpy并不会读取超过传入第三个参数的数值,如果发现还未读到\0但是超过了传入strscpy的count的话就会直接报错-E2BIG:
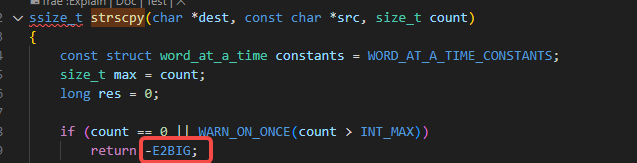
也就是-7:
![]()
我们再看一下,如果不发生截断时的情况,改写后的测试代码:
char testa[20];char testb[20] = "helloworld";ssize_t ret;for (int i = 0; i < 20; i++) testa[i] = 1;printk("%d", strscpy(testa, testb, 15)); // strlcpy 会把source读完,可能导致问题,用strscpy更好//strncpy(testa, testb, 5);for (int i = 0; i < 15; i++) printk("testa[%d]=%d\n", i, (int)testa[i]);测试运行日志:
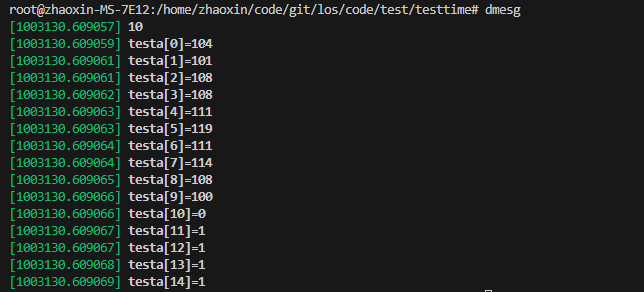
返回值10就是在不发生截断时src里的遇到\0前的字符个数。
三、用户态函数strncpy
我们来运行测试程序来看一下用户态strncpy的执行情况,测试程序如下:
char testa[20] = { 0 };for (int i = 0; i < 20; i++) testa[i] = 1;char testb[20] = "helloworld";ssize_t a1;for (int c = 0; c <= 15; c++) {a1 = (ssize_t)strncpy(testa, testb, c);printf("[%d]ret=%ld,%s\n", c, a1, testa);}运行后的日志如下:
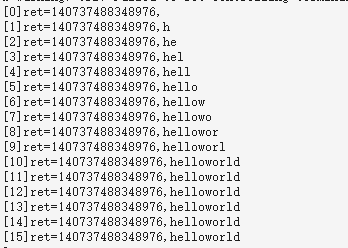
strncpy的返回值是dst的char*这个指针的数值:
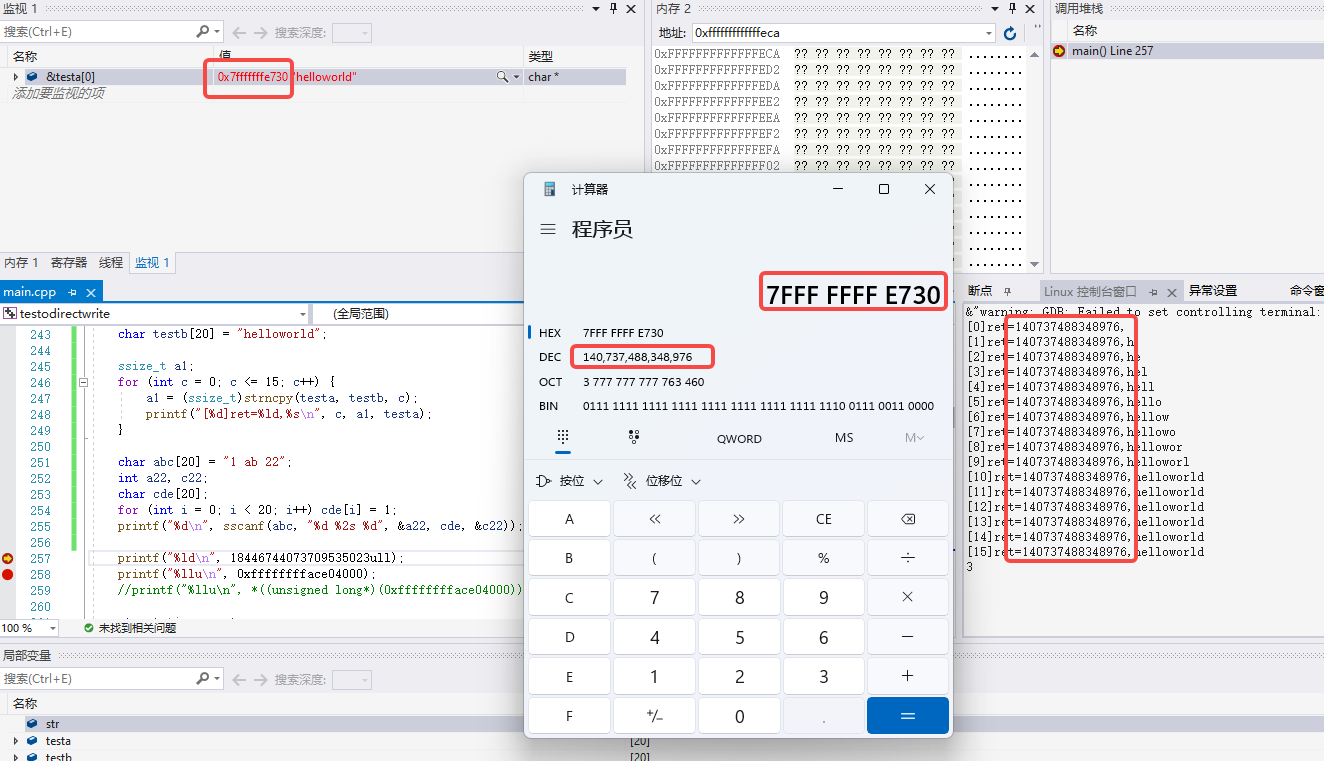
虽然上面的截图表面上看,strncpy操作后的dest字符串是能显示正常的,但是实际上,它并没有\0结尾,显示正常是恰好后面有\0,且\0前的非\0的那些内容是显示不出字符的。如下图,strncpy操作后的testa的内容虽然c是2,但是并没有如预期一样把testa的第二个字符写成\0,而是第二个字符写了src的内容:

所以,要特别注意,strncpy虽然设置了count,但是并不会自行补\0的。
四、自己编写一个与内核态函数strscpy相同效果的用户态函数strscpy
为了在用户态也能达到和内核态的strscpy函数一样的效果,也就是能根据count自行进行截断并补\0在最后一个count上(如果src的count个字符里并没有\0的话),编写了一个用户态的strscpy函数,虽然还没做优化,但是功能上是可以工作的,测试程序代码:
char testa[20] = { 0 };for (int i = 0; i < 20; i++) testa[i] = 1;char testb[20] = "helloworld";ssize_t a1;for (int c = 0; c <= 15; c++) {a1 = (ssize_t)strscpy(testa, testb, c);printf("[%d]ret=%ld,%s\n", c, a1, testa);}测试情况如下:
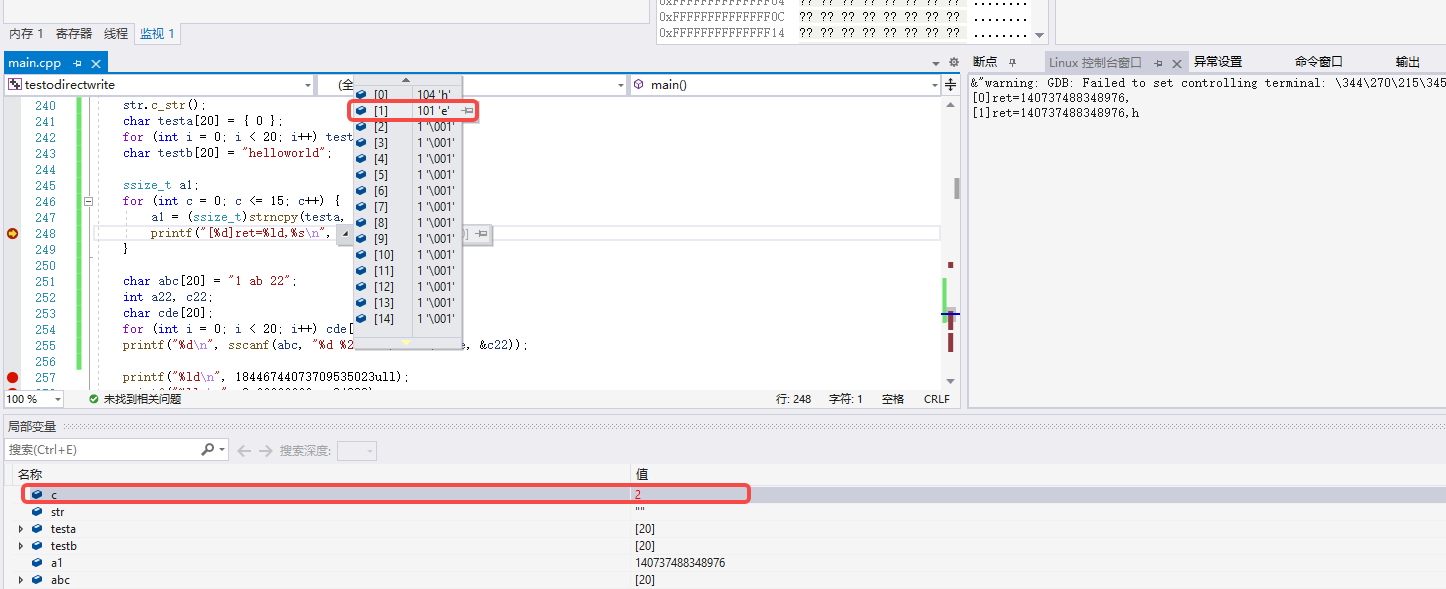
如下图看到c等于2时,第二个字符被写成了\0:
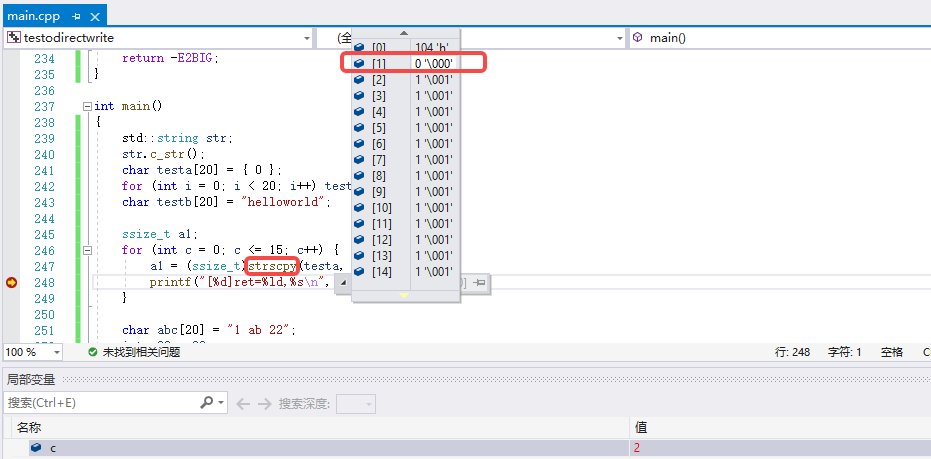
继续运行测试程序,跑完c=0到c=15的情况:

可以如上图看到,如果发生了截断,就会返回-E2BIG,如果不发生截断,就会返回不包含\0的字符个数。





