Qwen2.5-Omni-3B是阿里云推出的全能AI模型。它能同时处理视频、音频、图像和文本。只有3B参数,却能在本地运行强大的多模态功能。
近日,已经在Hugging Face上发布。它是小型多模态AI系统的重要突破。
特点

Qwen2.5-Omni-3B与普通语言模型不同。它是真正的多模态系统,可以同时理解四种内容类型。
-
Qwen2.5-Omni-3B处理文本,能理解和生成全面的语言内容。
-
Qwen2.5-Omni-3B分析图像,能识别物体和场景,回答关于视觉内容的问题。
-
Qwen2.5-Omni-3B理解音频,能进行语音识别和转录,分析声音内容。
-
Qwen2.5-Omni-3B处理视频,能描述动作和场景变化,进行时间推理。
这个模型最大的特点是在仅有3B参数的情况下实现了这些功能。这使它可以在计算资源有限的环境中使用。
技术架构
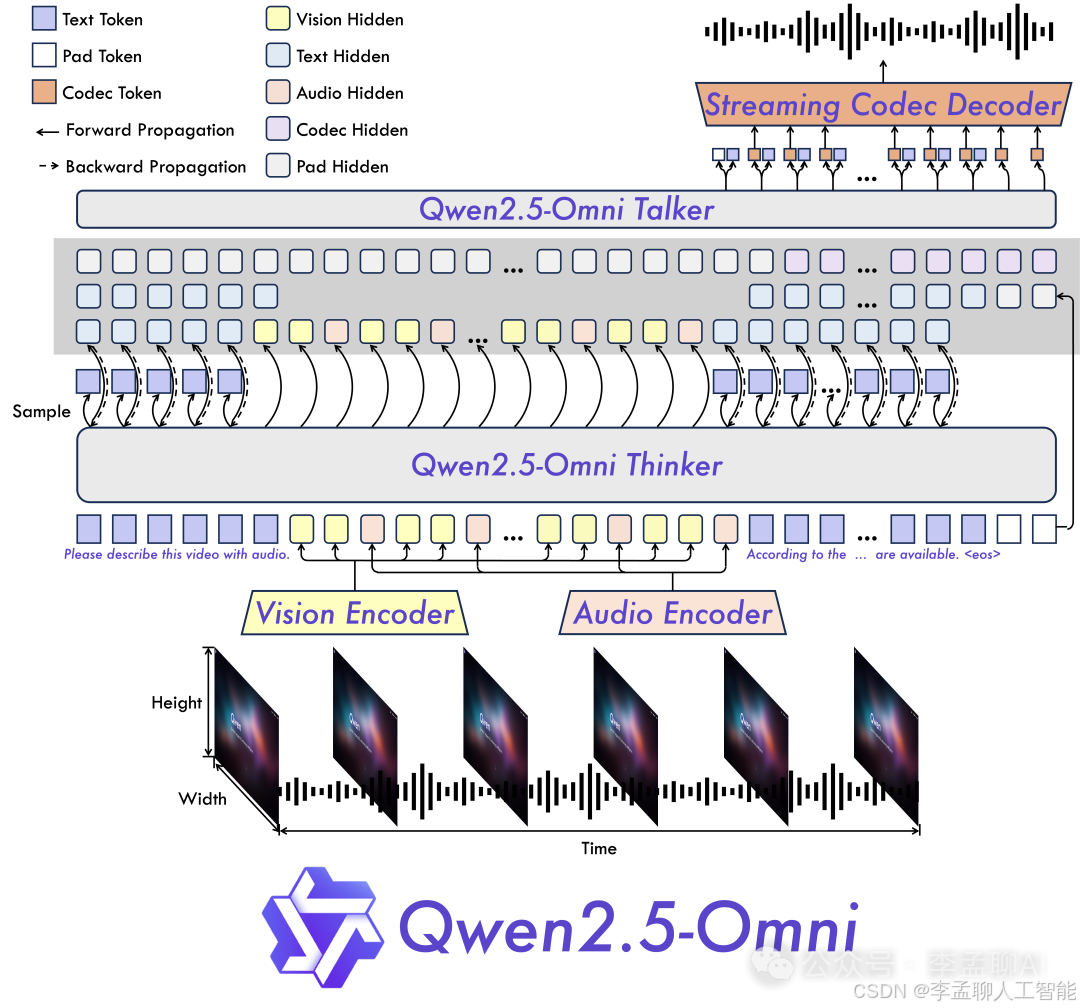
技术架构上,它基于Qwen 2.5模型系列,增加了专门的多模态处理组件。
-
Qwen2.5-Omni-3B有统一的Transformer骨干网络,作为基础文本处理管道。
-
Qwen2.5-Omni-3B有视觉处理模块,用于提取和理解图像与视频帧的特征。
-
Qwen2.5-Omni-3B有音频处理管道,将声波转换为可处理的嵌入向量。
-
Qwen2.5-Omni-3B有跨模态注意力机制,建立不同模态之间的连接。
技术创新点包括高效的参数共享,将所有输入作为序列处理,以及使用投影层将不同模态特征映射到共享的嵌入空间。
功能
-
在视频理解方面,它可以描述视频内容,识别动作,检测场景变化,进行时间推理,并回答关于视频的问题。
-
在音频处理方面,它可以进行语音识别和转录,识别说话者,理解音频场景,检测声音事件,回答基于音频的问题。
-
在图像理解方面,它提供详细的图像描述,物体检测和识别,场景理解,视觉问答和基于图像的推理。
-
在文本处理方面,它保持了强大的语言理解能力,可以生成内容,做摘要,回答问题,进行翻译。
Qwen2.5-Omni-3B的真正力量在于整合多模态信息的能力。它可以回答关于带音频的视频的问题,描述文本与图像的关系,基于多模态输入生成文本,从混合媒体内容创建连贯的叙述。
测试
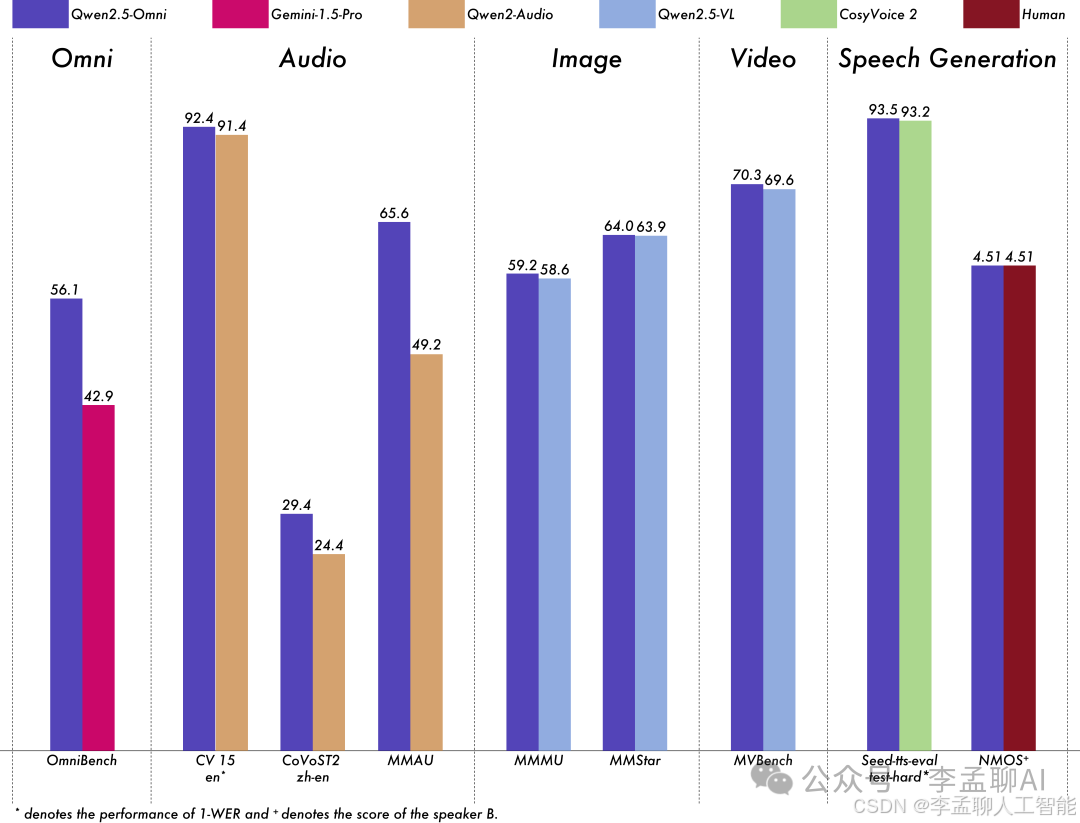
性能测试显示,它在多个基准测试中表现出色,效率高,有时甚至超过了参数量更大的模型。
本地部署
以下是如何使用Python在本地运行模型的方法,不需要任何云端GPU!
第一步:安装必要依赖
运行以下命令设置环境:
pip install torch torchvision torchaudio einops timm pillow
pip install git+https://github.com/huggingface/transformers@v4.




