一、设置随机种子
设置随机种子有助于结果的可复现性。
import numpy as np # 导入NumPy库
import random # 导入随机数生成库
import os # 导入操作系统相关功能
import torch # 导入PyTorch库 def setup_seed(seed=0): # 设置NumPy的随机种子 np.random.seed(seed) # 设置Python内置的随机数生成器的种子 random.seed(seed) # 设置环境变量,确保Python的哈希种子固定 os.environ['PYTHONHASHSEED'] = str(seed) # 设置PyTorch随机种子 torch.manual_seed(seed) # 如果CUDA可用,设置CUDA的随机种子 if torch.cuda.is_available(): torch.cuda.manual_seed(seed) # 设置当前GPU的随机种子 torch.cuda.manual_seed_all(seed) # 设置所有GPU的随机种子 torch.backends.cudnn.benchmark = False # 禁用cuDNN的基准特性,以确保结果可复现 torch.backends.cudnn.deterministic = True # 设置cuDNN为确定性模式,以确保可复现性 # 调用setup_seed函数并设置种子为0
setup_seed(0) 代码说明:
-
np.random.seed(seed):设置NumPy库的随机种子,以确保使用NumPy生成的随机数可复现。 -
random.seed(seed):设置Python内置随机数生成器的种子,以保证随机数生成的一致性。 -
os.environ['PYTHONHASHSEED'] = str(seed):设置Python的哈希种子,防止在同一字符串上产生不同的哈希值,增强结果的可复现性。 -
torch.manual_seed(seed):设置PyTorch的随机种子,以确保使用PyTorch进行的随机操作可复现。 -
torch.cuda.manual_seed(seed):设置当前GPU的随机种子,以确保在使用CUDA时的可复现性。 -
torch.cuda.manual_seed_all(seed):如果有多个GPU,这一行确保在所有GPU上设置相同的随机种子。 -
torch.backends.cudnn.benchmark = False和torch.backends.cudnn.deterministic = True:这两行确保cuDNN在运行时采用确定性算法,这对于模型的可复现性是非常重要的。 -
setup_seed(0):调用函数,设置随机种子为0。
二、检查gpu是否可用
确保在可用的情况下使用GPU加速。
import torch # 导入PyTorch库 # 检查CUDA是否可用
if torch.cuda.is_available(): # 如果CUDA可用,使用GPU device = torch.device('cuda') print('CUDA is available, USE GPU') # 输出信息,表示使用GPU进行计算
else: # 如果CUDA不可用,使用CPU device = torch.device('cpu') print('CUDA is not available, USE CPU') # 输出信息,表示使用CPU进行计算 代码说明:
-
torch.cuda.is_available():检查系统是否安装了CUDA并且可以使用GPU进行计算。如果返回True,表示CUDA可用;如果返回False,则表示CUDA不可用。 -
torch.device('cuda'):创建一个表示GPU的device对象,后续可以使用这个对象将模型和数据移动到GPU上进行加速计算。 -
print('CUDA is available, USE GPU'):如果CUDA可用,则输出此信息,确认程序将使用GPU。 -
torch.device('cpu'):创建一个表示CPU的device对象,用于在CUDA不可用的情况下进行计算。 -
print('CUDA is not available, USE CPU'):如果CUDA不可用,输出此信息,确认程序将使用CPU。
三、数据读取
使用torchvision来读取MNIST数据集。
from torchvision import datasets, transforms
from torch.utils.data import DataLoader # 加载MNIST训练数据集
# root参数指定数据集存储的根目录,train=True表示加载训练集
# transform=transforms.ToTensor()将图像转换为张量格式
# download=True表示如果数据集不存在则自动下载
train = datasets.MNIST(root='./dataset', train=True, transform=transforms.ToTensor(), download=True) # 加载MNIST测试数据集
# root参数指定数据集存储的根目录,train=False表示加载测试集
# transform=transforms.ToTensor()同样将图像转换为张量格式
# download=True表示如果数据集不存在则自动下载
test = datasets.MNIST(root='./dataset', train=False, transform=transforms.ToTensor(), download=True) # 创建训练数据加载器
# batch_size=64指定每个批次包含的样本数量,shuffle=True表示在每个epoch时打乱数据顺序
train_data = DataLoader(train, batch_size=64, shuffle=True) # 创建测试数据加载器
# batch_size=64指定每个批次包含的样本数量,shuffle=False表示不打乱数据顺序
test_data = DataLoader(test, batch_size=64, shuffle=False) 代码说明:
-
datasets.MNIST(...):从torchvision库加载MNIST数据集。MNIST是一个经典的手写数字识别数据集,包含60,000个训练样本和10,000个测试样本。 -
root='./dataset':指定下载的数据集存储在./dataset目录中。 -
train=True和train=False:分别表示加载训练集和测试集。 -
transform=transforms.ToTensor():将图像转换为PyTorch张量格式,这对后续的训练和模型输入至关重要。 -
download=True:如果指定的目录中没有数据集,程序将自动从互联网上下载数据集。 -
DataLoader(...):用于创建数据加载器,以便批量加载数据。 -
batch_size=64:指定每个批次包含的样本数为64,这有助于在训练过程中提高计算效率。 -
shuffle=True:在每个epoch中打乱训练数据的顺序,以增加模型的泛化能力。 -
shuffle=False:在测试数据加载器中不打乱数据的顺序,因为一般测试数据的顺序不需要进行打乱。
四、构建模型
使用LeNet-5架构构建卷积神经网络。
import torch.nn as nn # 导入PyTorch的神经网络模块
import torch.nn.functional as F # 导入PyTorch的功能性操作模块 # 定义LeNet-5模型类
class LeNet5(nn.Module): def __init__(self): super(LeNet5, self).__init__() # 调用父类的构造函数 # 第一个卷积层 # 输入通道数为1(灰度图像),输出通道数为6,卷积核大小为5x5,步幅为1,填充为2 self.conv1 = nn.Conv2d(1, 6, 5, 1, 2) # 第一个平均池化层:池化窗口大小为2x2,步幅为2 self.pool1 = nn.AvgPool2d(2, 2) # 第二个卷积层 # 输入通道数为6,输出通道数为16,卷积核大小为5x5,步幅为1 self.conv2 = nn.Conv2d(6, 16, 5, 1) # 第二个平均池化层:池化窗口大小为2x2,步幅为2 self.pool2 = nn.AvgPool2d(2, 2) # 第一个全连接层:输入特征数为5*5*16,输出特征数为120 self.liner1 = nn.Linear(5 * 5 * 16, 120) # 第二个全连接层:输入特征数为120,输出特征数为84 self.liner2 = nn.Linear(120, 84) # 第三个全连接层:输入特征数为84,输出特征数为10(对应10个数字类别) self.liner3 = nn.Linear(84, 10) # 定义正向传播函数 def forward(self, x): # 输入数据经过第一个卷积层,应用ReLU激活函数,随后经过第一个池化层 x = self.pool1(F.relu(self.conv1(x))) # 输入数据经过第二个卷积层,应用ReLU激活函数,随后经过第二个池化层 x = self.pool2(F.relu(self.conv2(x))) # 将多维张量展平为一维张量,以便输入到全连接层 x = x.view(-1, 16 * 5 * 5) # 输入数据经过第一个全连接层,应用ReLU激活函数 x = F.relu(self.liner1(x)) # 输入数据经过第二个全连接层,应用ReLU激活函数 x = F.relu(self.liner2(x)) # 输入数据经过第三个全连接层,输出10个类别的评分 x = self.liner3(x) return x # 返回每个类别的预测值 # 实例化LeNet-5模型
model = LeNet5() 代码说明:
-
class LeNet5(nn.Module):定义一个继承自nn.Module的卷积神经网络类。 -
super(LeNet5, self).__init__():调用父类的构造函数以初始化模型。 -
卷积层 (
self.conv1和self.conv2):用于提取特征,卷积运算可以捕捉图像中的局部特征。 -
平均池化层 (
self.pool1和self.pool2):减少特征图的尺寸,降低计算复杂度并增强模型的泛化能力。 -
全连接层 (
self.liner1、self.liner2和self.liner3):将卷积层提取的特征映射到输出类别,进行分类。 -
forward函数:定义了数据通过网络的流动方式,包括应用卷积、池化和激活函数等操作。 -
x.view(-1, 16 * 5 * 5):将输出的特征图展平,为全连接层准备输入。-1表示自动计算维度。 -
实例化模型
model = LeNet5():创建LeNet-5模型的实例,后续可以使用该模型进行训练和推理。
五、损失函数和优化器和训练模型
import torch # 导入PyTorch库 # 定义交叉熵损失函数
# CrossEntropyLoss通常用于多分类问题,是一个常用的损失函数
cri = torch.nn.CrossEntropyLoss() # 定义Adam优化器,使用模型参数和学习率
# Adam优化器结合了动量和自适应学习率的优点,通常能更快收敛
optim = torch.optim.Adam(model.parameters(), lr=0.01) # 训练模型,训练10个epoch
for epoch in range(1, 11): model.train() # 设置模型为训练模式 total_loss = 0 # 初始化总损失 # 迭代训练数据,enumerate会返回每个批次的索引和数据 for i, (images, labels) in enumerate(train_data): # 前向传播:通过模型获取输出 outputs = model(images) # 计算损失:比较模型输出与真实标签 loss = cri(outputs, labels) # 清零梯度:优化器在每次迭代前需清除上次迭代的梯度信息 optim.zero_grad() # 反向传播:计算梯度 loss.backward() # 更新模型参数 optim.step() # 累加总损失 total_loss += loss.item() # 使用loss.item()获取标量值并加到总损失中 # 计算每个epoch的平均损失 avg = total_loss / len(train_data) # 总损失除以批次数 print(epoch, avg) # 打印当前epoch和平均损失 代码说明:
-
torch.nn.CrossEntropyLoss():定义交叉熵损失函数,用于多类分类任务,期望模型输出的概率分布与真实标签一致。 -
torch.optim.Adam(...):定义Adam优化器,自动调整学习率以加速模型收敛。 -
for epoch in range(1, 11):进行10次训练,range(1, 11)表示从1到10。 -
model.train():设置模型为训练模式,启用Dropout和BatchNorm等特性,以便在训练过程中正确运行。 -
total_loss = 0:初始化总损失为0,用于记录当前epoch的损失。 -
enumerate(train_data):通过迭代器获取批次索引i和数据(images, labels)。train_data是装载训练数据的DataLoader对象。 -
outputs = model(images):通过调用模型的__call__方法来进行前向传播,传入当前批次的图像数据,获取模型的输出。 -
loss = cri(outputs, labels):计算损失,比较模型预测输出outputs与真实标签labels。 -
optim.zero_grad():在进行梯度计算之前,清零之前的梯度,以避免累加。 -
loss.backward():执行反向传播,计算各参数对损失的梯度。 -
optim.step():根据计算得到的梯度更新模型的参数。 -
total_loss += loss.item():将当前批次的损失值累加到total_loss中,使用loss.item()以得到标量值。 -
avg = total_loss / len(train_data):计算当前epoch的平均损失,len(train_data)为批次数。 -
print(epoch, avg):在控制台中打印当前训练的epoch和对应的平均损失值。
六、模型评估
# 设置模型为评估模式
model.eval() # 初始化总样本数和正确预测数量
total = 0
corret = 0 # 注意:此处变量名应该是`correct`
a = [] # 用于存储预测的结果
b = [] # 用于存储真实标签 # 禁用自动梯度计算
# 1. 节省内存
# 2. 加速计算
# 3. 防止梯度累加
with torch.no_grad(): # 遍历测试数据集 for images, labels in test_data: outputs = model(images) # 通过模型进行前向传播,获取预测输出 # 通过torch.max获取每个样本的预测类别 # `outputs.data`是模型预测的输出,[64, 10],其中64是批次大小,10是类别数 _, predicted = torch.max(outputs.data, 1) total += labels.size(0) # 累加测试样本总数 corret += (predicted == labels).sum().item() # 累加正确预测的数量 # 将预测和真实标签添加到列表中 a.extend(predicted.cpu().numpy()) # 将预测的类别转换为NumPy数组并添加到列表a b.extend(labels.cpu().numpy()) # 将真实标签转换为NumPy数组并添加到列表b # 计算并打印模型在测试集上的准确率
print(f"Accuracy of the model on the test images: {100 * corret / total} %") # 导入用于评估的库
from sklearn.metrics import confusion_matrix, f1_score, precision_score, recall_score
import seaborn as sns
import matplotlib.pyplot as plt # 用于绘制图表 # 计算混淆矩阵
conf_matrix = confusion_matrix(a, b)
print(conf_matrix) # 打印混淆矩阵 # 使用热图可视化混淆矩阵
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues')
plt.show() # 显示热图 # 计算并打印F1分数、精确率和召回率
print(f1_score(a, b, average='weighted')) # 打印F1分数
print(precision_score(a, b, average='weighted')) # 打印精确率
print(recall_score(a, b, average='weighted')) # 打印召回率 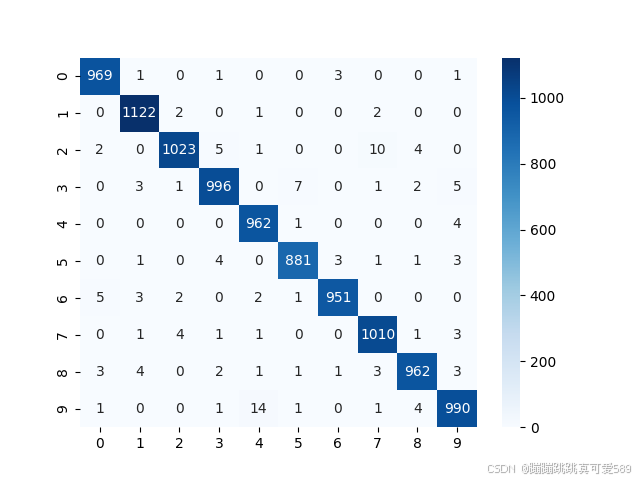
代码说明:
-
model.eval():将模型设置为评估模式,关闭Dropout和Batch Normalization的训练模式,以使模型在推理时的行为保持一致。 -
total和corret:初始化统计变量,total用来记录测试样本的总数,corret(应为correct)用于记录预测正确的样本数。 -
a和b:用于存储模型预测的结果和真实的标签,以便进行后续的评估。 -
with torch.no_grad():在这个上下文中禁用自动梯度计算,以节省内存,加速计算,并避免对计算图的构建,这在评估模型时是非常常见的做法。 -
for images, labels in test_data:遍历测试数据集,获取每个批次的图像和标签。 -
outputs = model(images):通过模型获取当前批次的预测输出。 -
_, predicted = torch.max(outputs.data, 1):获取每个样本预测的类别。torch.max返回最大值及其索引,这里只需要索引,即预测类别。 -
total += labels.size(0):记录当前批次的样本数,累加到总样本数。 -
corret += (predicted == labels).sum().item():计算当前批次中正确预测的样本数,并累加到corret。 -
a.extend(predicted.cpu().numpy()):将预测类别从张量转换为NumPy数组,并在列表a中存储。使用.cpu()确保数据在CPU上,以避免在GPU上直接进行操作。 -
b.extend(labels.cpu().numpy()):同样将真实标签转换为NumPy数组,并在列表b中存储。 -
print(f"Accuracy of the model on the test images: {100 * corret / total} %")
计算并打印模型在测试集上的准确率。准确率的计算公式为正确预测的数量 / 总样本数量 * 100。通过格式化字符串(f-string)来整齐输出结果。 -
from sklearn.metrics import confusion_matrix, f1_score, precision_score, recall_score
从scikit-learn库中导入评估指标计算所需的函数。这里使用的评估指标有混淆矩阵、F1分数、精确率和召回率。 -
import seaborn as sns
导入seaborn库,用于数据可视化,它提供了更美观的绘图接口。 -
import matplotlib.pyplot as plt
导入matplotlib.pyplot库,用于绘制图表。plt是常用的别名。 -
conf_matrix = confusion_matrix(a, b)
计算混淆矩阵,混淆矩阵用于评估分类模型的性能,其结构为:行表示真实类别,列表示预测类别。通过传入预测的类别a和真实的标签b来计算。 -
print(conf_matrix)
打印混淆矩阵,以便查看模型在不同分类上的表现。 -
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues')
使用seaborn绘制混淆矩阵的热图。参数说明:-
annot=True:在每个单元格中显示数值。 -
fmt='d':数值格式为整数。 -
cmap='Blues':颜色映射为蓝色调。
-
-
plt.show()
显示绘制的热图,便于观察和分析模型的分类效果。 -
print(f1_score(a, b, average='weighted'))
计算并打印F1分数。F1分数是精确率和召回率的调和平均数,适用于不平衡的数据集。average='weighted'表示根据每个类别的支持(样本数)计算加权平均。 -
print(precision_score(a, b, average='weighted'))
计算并打印精确率,精确率是指正确分类的积极样本占所有被分类为积极的样本的比例,反映模型的准确性。 -
print(recall_score(a, b, average='weighted'))
计算并打印召回率,召回率是指正确分类的积极样本占所有实际积极样本的比例,反映模型的完整性。

)



