本文专栏:Linux网络编程
目录
一,状态码
重定向状态码
1,永久重定向(301 Moved Permanently)
2,临时重定向(302 Found)
二,常见请求方法
1,HTTP常见Header
2,GET方法
3,POST方法
4,总结
3,session
4,总结
源码
一,状态码
HTTP状态码:是服务器响应客户端请求时返回的三位数字代码,用于表示请求的处理结果。
以下列举几种常见状态码的表格:
| 状态码 | 含义 | 应用样例 |
| 100 | Continue | 表示请求已接受,需要继续处理。例如,上传大文件时,服务器告诉客户端可以继续上传。 |
| 200 | OK | 表示请求已被成功处理 |
| 201 | Create | 资源创建成功。例如,发布新文章,服务器返回文章创建成功的信息 |
| 204 | Not Content | 删除文章后,服务器返回“无内容”表示操作成功 |
| 301 | Moved Permanently | 网站更换域名后,自动跳转到新的域名。搜索引擎更换网站链接时使用 |
| 302 | Found或 See Other | 用户登录成功后,自动跳转到用户首页 |
| 304 | Not Midified | 浏览器缓存机制 |
| 400 | Bad Request | 填写表单时,格式不正确导致的错误 |
| 401 | Unauthorized | 访问需要登陆的页面时,未登录或者认证失败 |
| 404 | Not Found | 访问的链接不存在 |
| 500 | Internal Server Error | 服务器崩溃或数据库错误导致页面无法加载 |
| 502 | Bad Gateway | 使用代理服务器时,收到无效响应 |
| 503 | Service Unavaliable | 服务不可用(维护中或过载) |
重定向状态码
- 关于重定向相关的状态码,可以大概分为两类,永久重定向和临时重定向。
- 在本文中以301永久重定向和302临时重定向为例,进行讨论。
- 简单的理解重定向,就是当我们想访问一个网址时,会跳转到其他的网址。
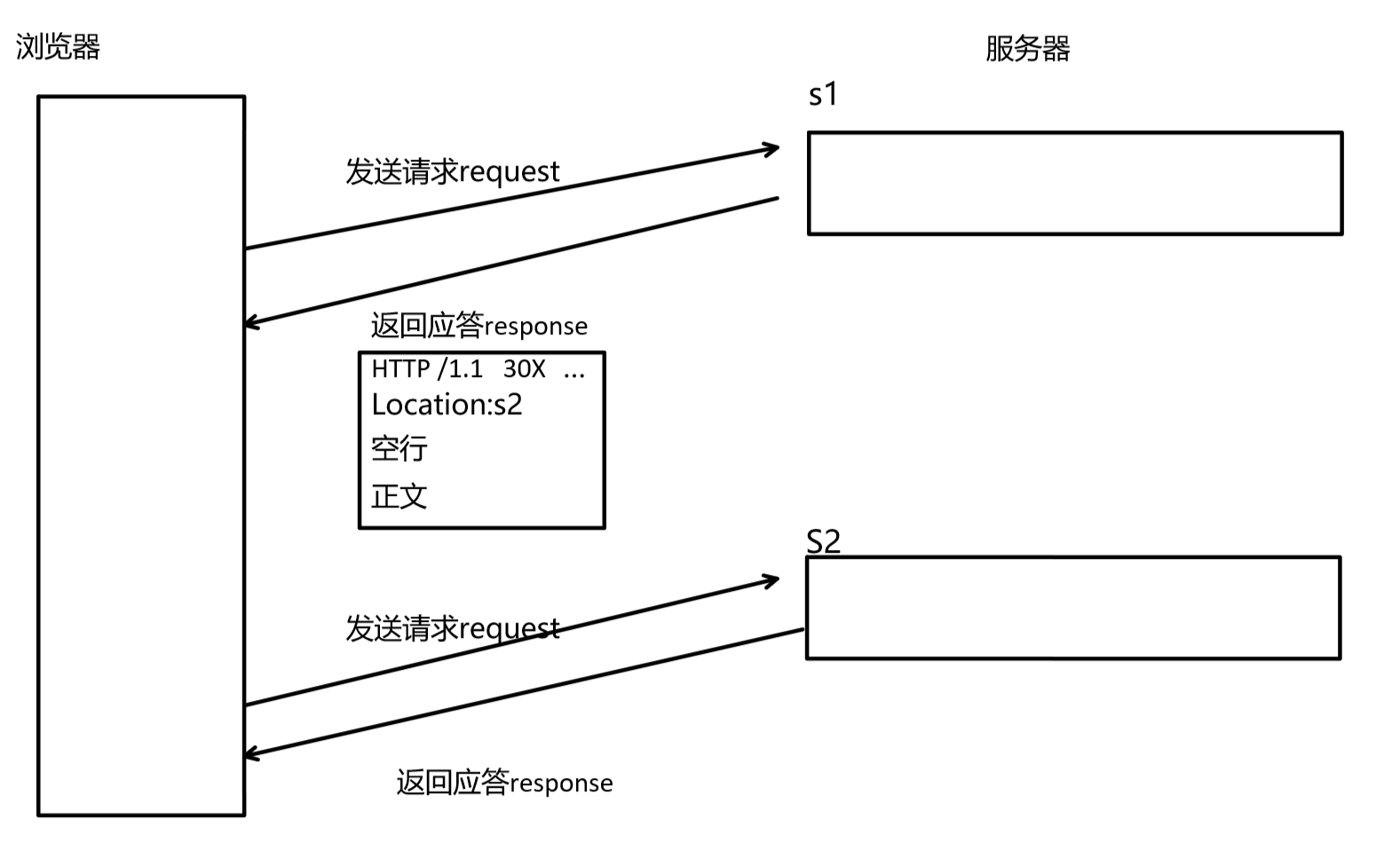
具体看下图:
当使用浏览器访问s1时,接收到s1发送的应答报文,发现它的状态码是30x(301或者302),就知道是需要重定向到新的网址,新的网址是报文中Location后面的内容。提取到到新的网址后,浏览器会发送二次请求访问新的网址。这就是重定向的大致过程。
1,永久重定向(301 Moved Permanently)
- 所谓永久重定向,就是我们想访问的资源的域名发生更改,当我们使用原网址进行访问的时候,会直接跳转到新的网址下。并且浏览器会更改内部的数据,用新的网址覆盖掉原来的网址,下次访问的时候就直接使用新的网址了。
- 永久重定向(301)的价值是用来给搜索引擎更新网站链接的。
- 在我们使用搜索引擎访问资源的时候,其实就是获取到目标资源的域名。但是如果有些域名发生改变,就可能会导致访问失败。
- 所以,对于搜索引擎,会不定时的向目标资源发送请求,当收到目标的应答时,如果发现报文中状态码是301,并且报文中包含Location: XXX选项。搜索引擎就会将自己内部保保存原来的域名用新的XXX域名替换掉,所以下次访问的时候,直接使用新的域名。
2,临时重定向(302 Found)
有了对永久重定向的理解,临时重定向就很简单。当我们访问一个网址时,会跳转到新的网址,最常见的就是我们用户的登录操作,当我们登录完成后,就会跳转到用户首页。而下次访问时,还是需要先访问登录页面。
二,常见请求方法
最常见的两种方法:GET和POST
- POST:上传资源,比如登录操作,需要上传我们的用户名和密码。
- GET:获取资源,获取网页,图片,视频等等各种资源。同时也可以上传资源。
1,HTTP常见Header
Content-Type:数据类型,就是正文部分的内容是什么类型的,html,css或者是纯文本等等类型
Content-Length:正文部分的长度
Host:客户端告诉服务器,所请求的资源在哪个主机的哪个端口上。
User-Agent:声明用户的操作系统的浏览器版本信息
refer:当前页面是从哪个页面跳转过来的
Location:在上面状态码部分提到过。告诉客户端接下来要去哪里访问。
Cookie:这个 内容在本文下面讲解。
其中需要注意的是Content-Type数据类型,当服务器端给客户端返回数据时,需要带上这个属性,告诉浏览器该怎么解释(其实也可以不用带了,因为现在的浏览器已经很强大了,可以解析出来)。关于Content-Type,有一张对照表:
链接:HTTP Content-type 对照表 | content type
比如如果正问部分为html格式,那么报头中应该包含 Content-Type:text/html
2,GET方法
- 方法部分需要配合代码才好理解。这里我写了一个简单的http服务器(源码在文章末尾),以该http服务器为例子来理解GET方法。
- 在服务器中设置了4个html网页:首页,登录页面,注册页面,404页面。
- 其中首页可以跳转到登录页面和注册页面。
当我们想要进入登录页面,进行登陆时会出现如下问题:
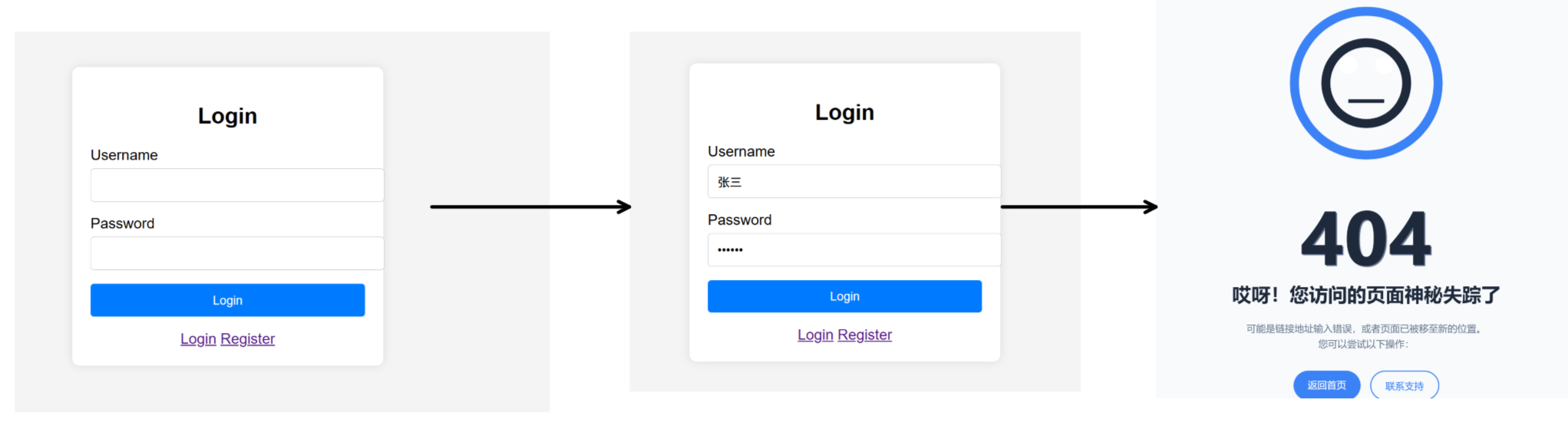
此时的uri内容是:

同时登录页面的html内容是:
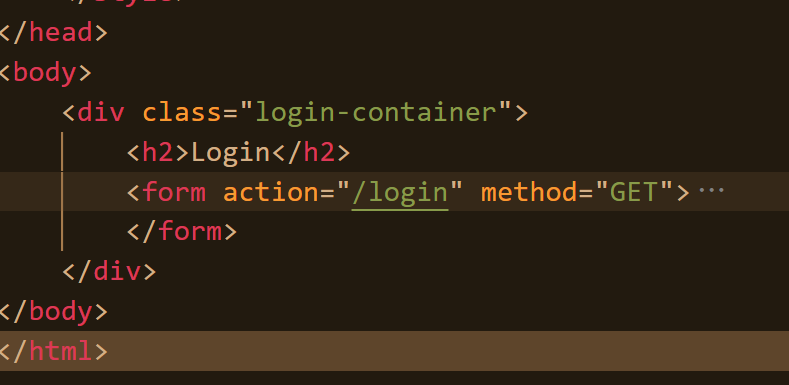
可以得出结论:uri中?之前的部分表示http提供的服务,?之后的内容表示用户输入的参数。只不过现在我们的http服务器还没有实现这个服务,所以最后会进入404页面。
- 之前我们访问网页都是在访问呢静态资源,图片视频什么的。而现在需要实现login服务,也就是让我们的服务器实现动他交互的功能。
- 实现方法:在对浏览器发送过来的uri进行解析时,判断是否带有问号,如果带有问号,表示需要进行动态交互,然后提取服务名(也就是问号之前的参数),再提取用户上传的参数(?之后的内容)
当我们实现好后,添加一个登录的操作,这里只是简单的将用户输入的数据以纯文本的形式发送回去,将来我们继续登陆后,不会访问404页面,而是收到同样的数据,以文本的形式展示出来。
//实现login一个服务
void Login(HttpRequest& req,HttpResponse& resp)
{//构建resp的内容//这里直接将req的内容以纯文本的形式发送回去std::string text="hello :"+req.Args();resp.setCode(200);resp.setHeader("Content-Type","text/plain");resp.setHeader("Content-Length",std::to_string(text.size()));resp.setText(text);
}
在http协议基础之上,我们新增了一个Login服务,我们将来就可以使用域名+服务名来访问对应的服务,这就相当于http给我们提供了一种微服务的接口。这种风格的网络接口称为RESTful风格的网络接口。所以未来我们还可以新增各种服务接口。比如注册接口,统计在线人数接口等等。
最后,其实我们早就知道了,GET方法的提参是通过uri提交的。
3,POST方法
POST方法,我们看一段正文就可以知道了。
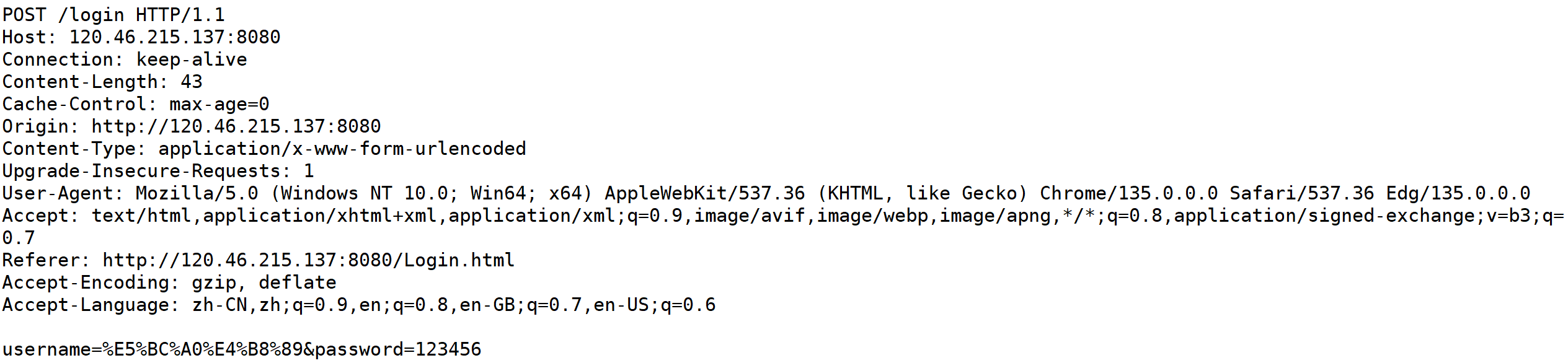
上面的报文是通过POST方法进行登录,可以发现再提交参数的时候,是将参数增加到正文部分的
4,总结
GET方法:
- 获取静态资源或者网页
- 提交参数,以uri形式提交
- GET提交参数一般不建议太长,因为uri长度是有限的
- GET传参,参数是会显示出来的。
POST方法:
- 提交参数,以正文部分参数
- 参数不会回显,相对私密
不管是GET还是POST,都是明文传送,可以抓取,是不安全的。
要做到真正的安全,必须要把报文进行加密,就要用到https协议。
三,cookie-session
1,cookie
HTTP协议是无连接,无状态的协议,即每次请求都需要建立新的连接,且服务器不会保存客户端的状态信息。
- HTTP底层是基于tcp的,所谓无连接,是指HTTP不管通信部分,只负责接受请求和发送应答的事情,连接是底层tcp管理的。所以说HTTP是无连接的。
- 无状态,是指当我们访问服务器时,服务器不会记录我们状态的信息。比如我们访问某个网页一次,就给我返回该网页一次。所以说是无状态的。(但实际上,为了提高效率,当我们访问一次后,浏览器会记录数据,下次访问时直接找浏览器拿即可)
有了上面的理解,看下面的一个例子:
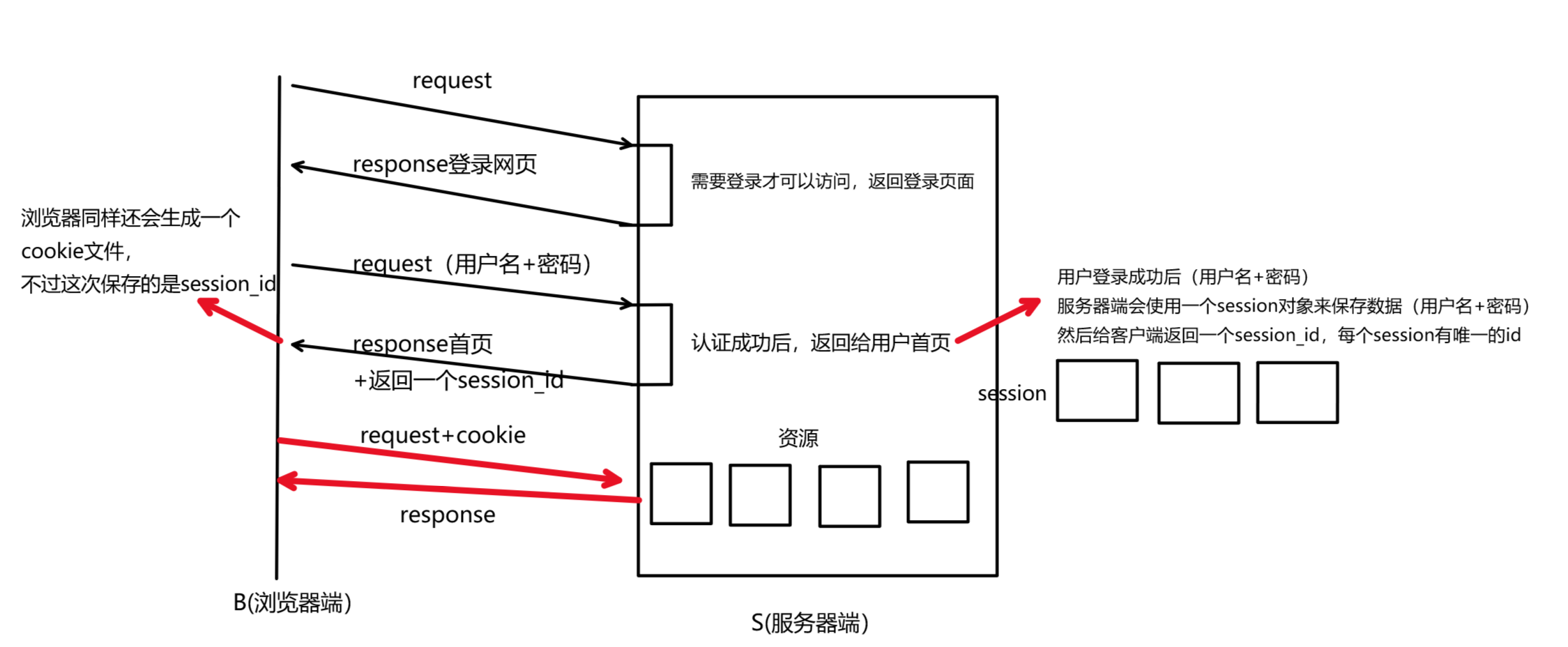
如下图所示,当我们项访问某个网站资源时,需要登录认证 。
- 第一次登录认证成功后,会给我们返回网站首页。
- 拿到网站首页后,当我们想要访问某个资源时,就需要再次进行登录认证,因为HTTP是无状态的,他不会记录当前你这个用户是否登录过,所以需要再次登录认证。
- 那么从今往后,你每访问一个资源,就需要登录认证一次,这对用户的肯定不友好。
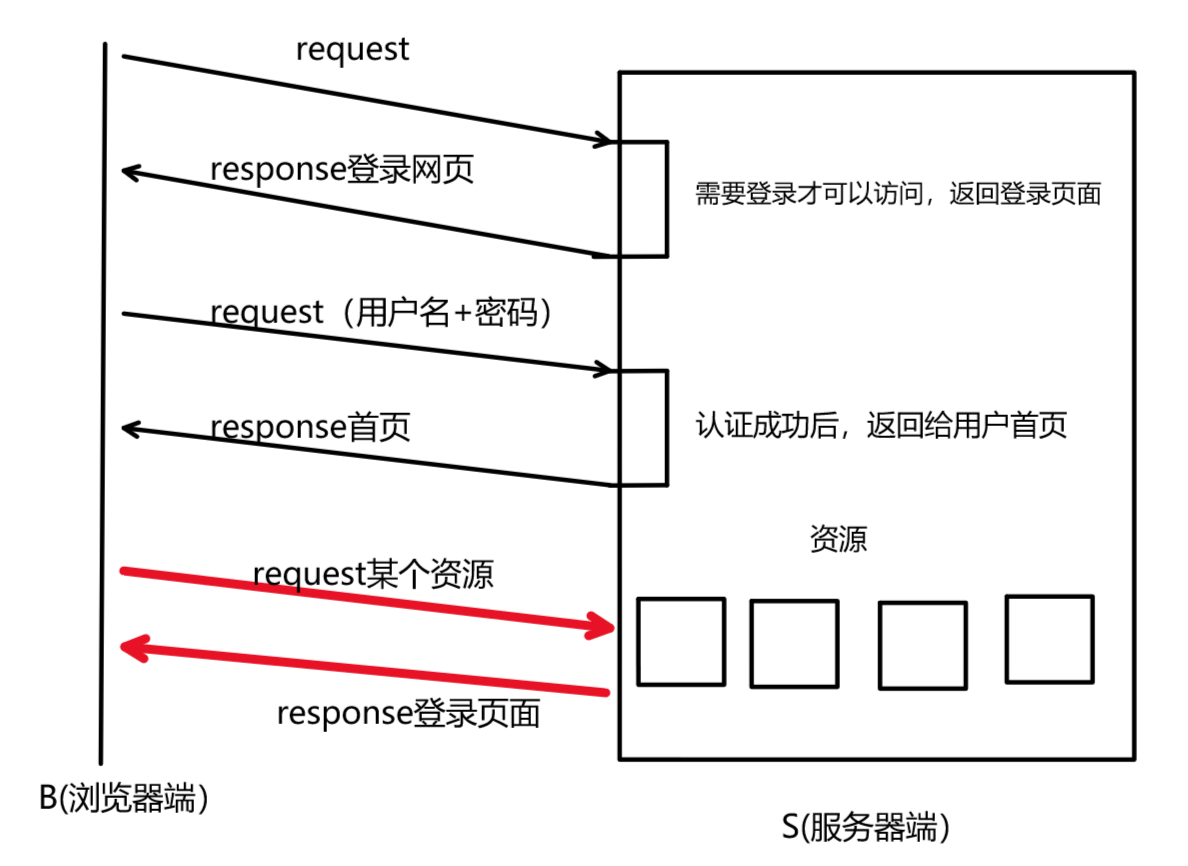
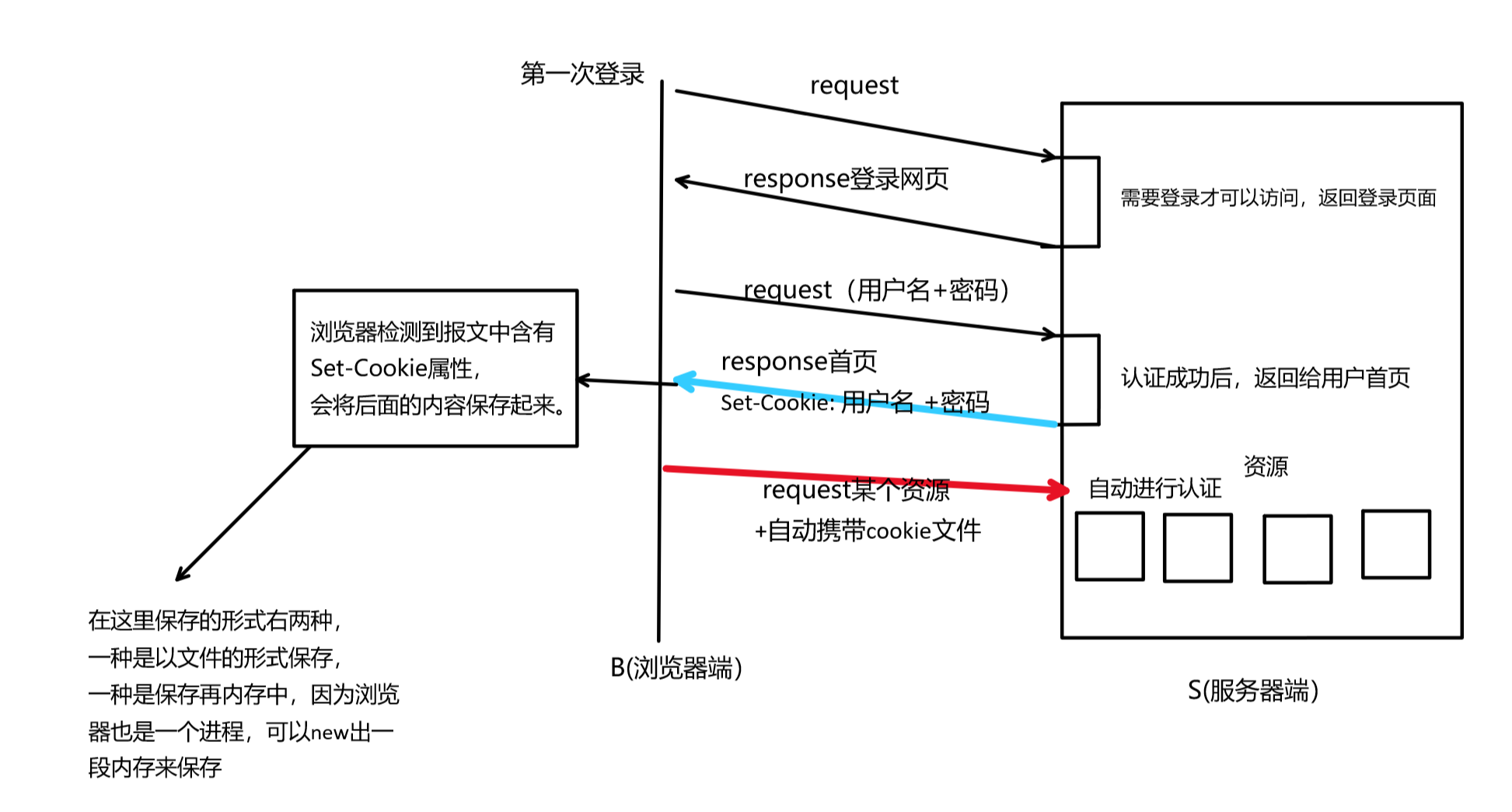
所以,为了解决上述问题,就引入了cookie功能。
在进行完一次认证操作后,服务器返回应答,应答报文中会包含Set-Cookie属性,记录用户输入的内容。浏览器检测到Set-Cookie属性,会将该部分内容保存下来,形成一个cookie文件,下次访问的时候直接携带该cookie文件,不需要再次认证了。
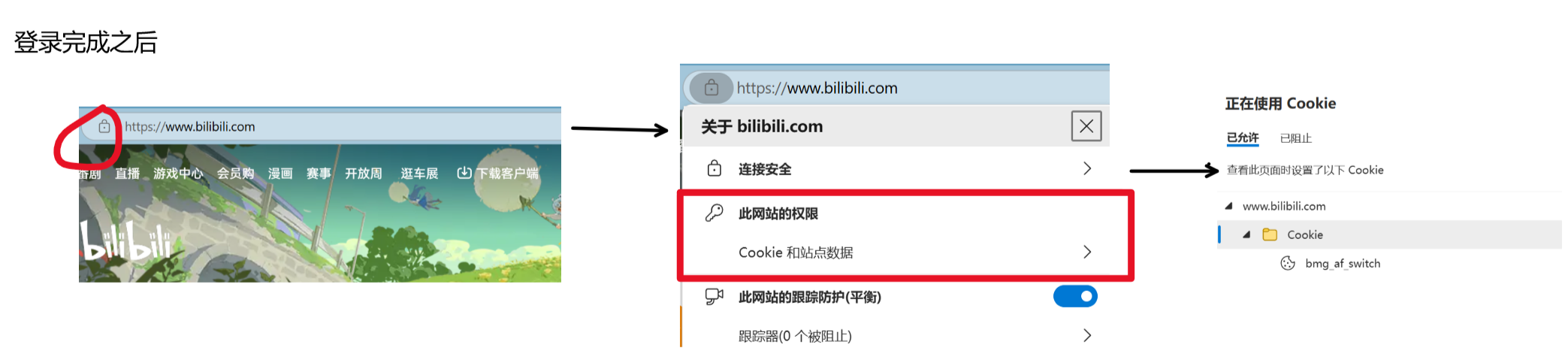
验证cookie的存在,以登录bilibili为例:
2,cookie问题
如果我们的电脑被植入了木马程序,那么黑客就可以获取到我们浏览器内的cookie文件。此时在他自己的电脑上访问同样的网站,使用我们的cookie,那么黑客就可以以我们的身份登录,访问服务器了。这样我们的账号就会被盗取,同时cookie中记录的私密数据(用户名,用户密码等等)也会泄漏。所以说,单纯使用cookie是不安全的。
总结一下,会存在两个问题:用户的账号丢失,用户的私密信息泄漏。
为了一定程度的解决该问题,就引入了session。
3,session
为了一定程度的解决上述问题,就引入了session
- 当我们登录认证成功后,我们输入的数据(用户名+密码),服务器端会生成一个session对象,来保存我们的密码和数据。然后给浏览器端返回一个session_id。下次访问时,直接携带cookie,cookie中保存了session_id,服务器端检查session_id是否存在即可。这样将用户的信息保存在服务器端,不保存在客户端,就解决了用户私密信息泄漏的问题。
- 而对于账号丢失的问题,不能完全解决,只能采取一定的辅助方案,比如溯源ip,地址的变更等等。比如,上次登录是在北京,5秒后再次登录,ip变为云南了,此时服务器就会检测到异常,将保存的session对象释放掉,要求用户重新登录,重新输入用户名和密码。就在一定程度上解决了这些问题。
4,总结
cookie和session:是用来负责会话管理与会话保持的。是HTTP的附加功能,不严格属于HTTP。
源码
myhttp2 · 小鬼/linux学习 - 码云 - 开源中国![]() https://gitee.com/wang-junyanxx/linux-learning/tree/master/myhttp2
https://gitee.com/wang-junyanxx/linux-learning/tree/master/myhttp2

)



