【AI大模型学习路线】第一阶段之大模型开发基础——第二章(大模型的训练与应用)大模型发展趋势中的RAG、智能体 Agent与小模型(Small Models)
【AI大模型学习路线】第一阶段之大模型开发基础——第二章(大模型的训练与应用)大模型发展趋势中的RAG、智能体 Agent与小模型(Small Models)
文章目录
- 【AI大模型学习路线】第一阶段之大模型开发基础——第二章(大模型的训练与应用)大模型发展趋势中的RAG、智能体 Agent与小模型(Small Models)
- 🔍 一、RAG(检索增强生成)详解
- ✅ 什么是RAG?
- 🧠 核心流程:
- 🛠 Python代码示例(简化版)
- 🤖 二、Agent(大模型智能体)
- ✅ 什么是LLM Agent?
- 🧠 基本结构:
- 🛠 示例代码(LangChain工具型Agent):
- 🧩 三、小模型(Small Model)与大模型的协同
- ✅ 为什么需要小模型?
- 🎯 小模型常用方案:
- 🛠 Python代码:使用DistilBERT情感分析
- 🔄 四、三者的融合前景:RAG × Agent × 小模型
- ✅ 总结图示
- 📌 你可以进一步探索的方向:
欢迎宝子们点赞、关注、收藏!欢迎宝子们批评指正!
祝所有的硕博生都能遇到好的导师!好的审稿人!好的同门!顺利毕业!
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://fighting.blog.csdn.net/article/details/146691809
🔍 一、RAG(检索增强生成)详解
✅ 什么是RAG?
- RAG(Retrieval-Augmented Generation)是将外部知识库检索系统与生成模型结合的方法,解决大模型“遗忘”和“幻觉”问题。
- 简单说:大模型不背书,而是“去查再答”。
🧠 核心流程:
用户提问 → 检索相关文档(如向量数据库) → 文档作为上下文 + 提问一起输入大模型 → 生成答案🛠 Python代码示例(简化版)
from transformers import pipeline
from langchain.vectorstores import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.chains import RetrievalQA
from langchain.llms import HuggingFaceHub# 假设你有一个 FAISS 向量数据库
vector_store = FAISS.load_local("my_faiss_index", HuggingFaceEmbeddings())
retriever = vector_store.as_retriever()# 使用开源模型作为后端生成器
llm = HuggingFaceHub(repo_id="tiiuae/falcon-7b-instruct", model_kwargs={"temperature": 0.5})# 构建RAG QA链
rag_chain = RetrievalQA.from_chain_type(llm=llm, retriever=retriever, chain_type="stuff")# 提问并回答
query = "什么是冻土滑坡?"
answer = rag_chain.run(query)
print(answer)- ✅ 现实场景:ChatGPT + Docs、Notion AI、法/医领域搜索问答等。
🤖 二、Agent(大模型智能体)
✅ 什么是LLM Agent?
- Agent = 大模型 + 工具调用能力 + 记忆 + 多轮决策。
- 它让大模型不只是“回答问题”,而是能完成任务(如写代码、查网页、操作API、执行步骤)。
类似“给它一个目标,它能自己想怎么做,然后一步步做出来”。
🧠 基本结构:
用户目标 → LLM分析任务 → 调用工具/搜索/API → 更新状态 → 再调用 → 完成任务🛠 示例代码(LangChain工具型Agent):
from langchain.agents import initialize_agent, load_tools
from langchain.llms import OpenAIllm = OpenAI(temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=llm) # 搜索+计算工具agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)result = agent.run("查一下北京今天的气温,加上5是多少?")
print(result)- ✅ 应用案例:AutoGPT、ChatGPT Plugins、AI助理自动化办公、科研任务规划。
🧩 三、小模型(Small Model)与大模型的协同
✅ 为什么需要小模型?
大模型虽然能力强,但:
- 成本高(部署/推理贵)
- 速度慢
- 数据隐私问题
- 某些任务泛化差(特定场景如医疗、安防)
解决方案:小模型 + 知识蒸馏 + 特定任务精调 + 边缘部署
🎯 小模型常用方案:
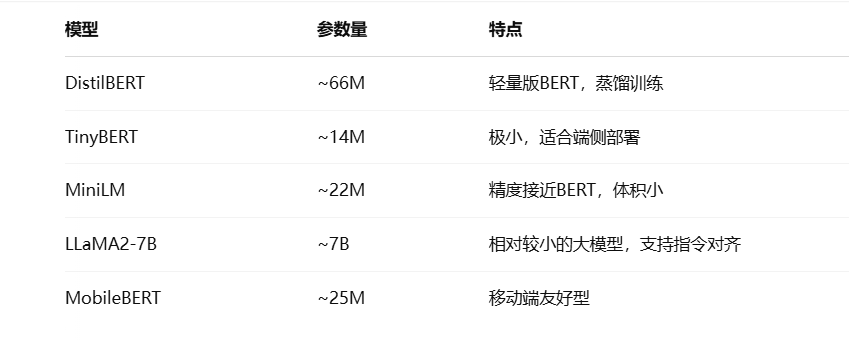
🛠 Python代码:使用DistilBERT情感分析
from transformers import pipelineclassifier = pipeline("sentiment-analysis", model="distilbert-base-uncased-finetuned-sst-2-english")
result = classifier("I really enjoy using small language models.")
print(result)输出:
[{'label': 'POSITIVE', 'score': 0.9995}]🔄 四、三者的融合前景:RAG × Agent × 小模型
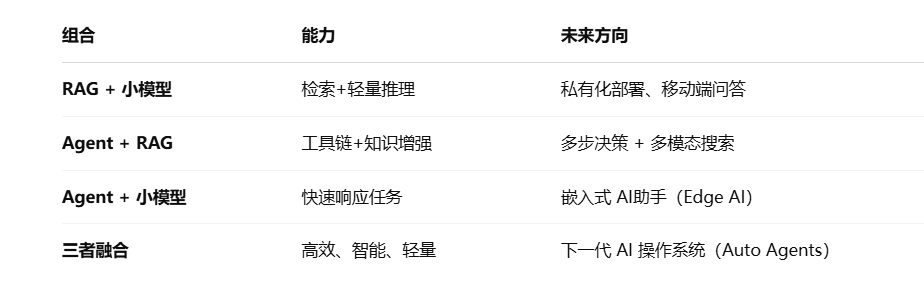
✅ 总结图示
┌──────────────┐│ 大模型 │└─────┬────────┘│┌──────────┴──────────┐↓ ↓┌──────────────┐ ┌────────────┐│ RAG系统 │ │ LLM Agent │└──────────────┘ └────────────┘↓ ↓+ 文档库 + 工具链/插件+ 小模型协同 + 状态更新/控制↓🧠 智能AI助手/系统📌 你可以进一步探索的方向:







