阿里通义实验室推出了 QVQ-Max 视觉推理模型,它犹如为 AI 装上了一双敏锐的眼睛和一颗聪慧的大脑,使其能够“看懂”图片和视频,并进行深度分析与推理,为解决各类复杂问题提供了全新的思路与方法。
视觉推理:AI 发展的必然趋势
在现实生活中,我们获取信息的主要途径之一便是视觉。无论是精美的建筑设计图,还是晦涩难懂的医学影像,亦或是充满趣味的短视频,其中蕴含着丰富的语义信息,仅靠文字描述往往难以完整传达。传统图文模型虽然能够识别物体并进行简单描述,但在逻辑推理方面存在明显不足,无法满足人们对于复杂视觉信息深度理解的需求。
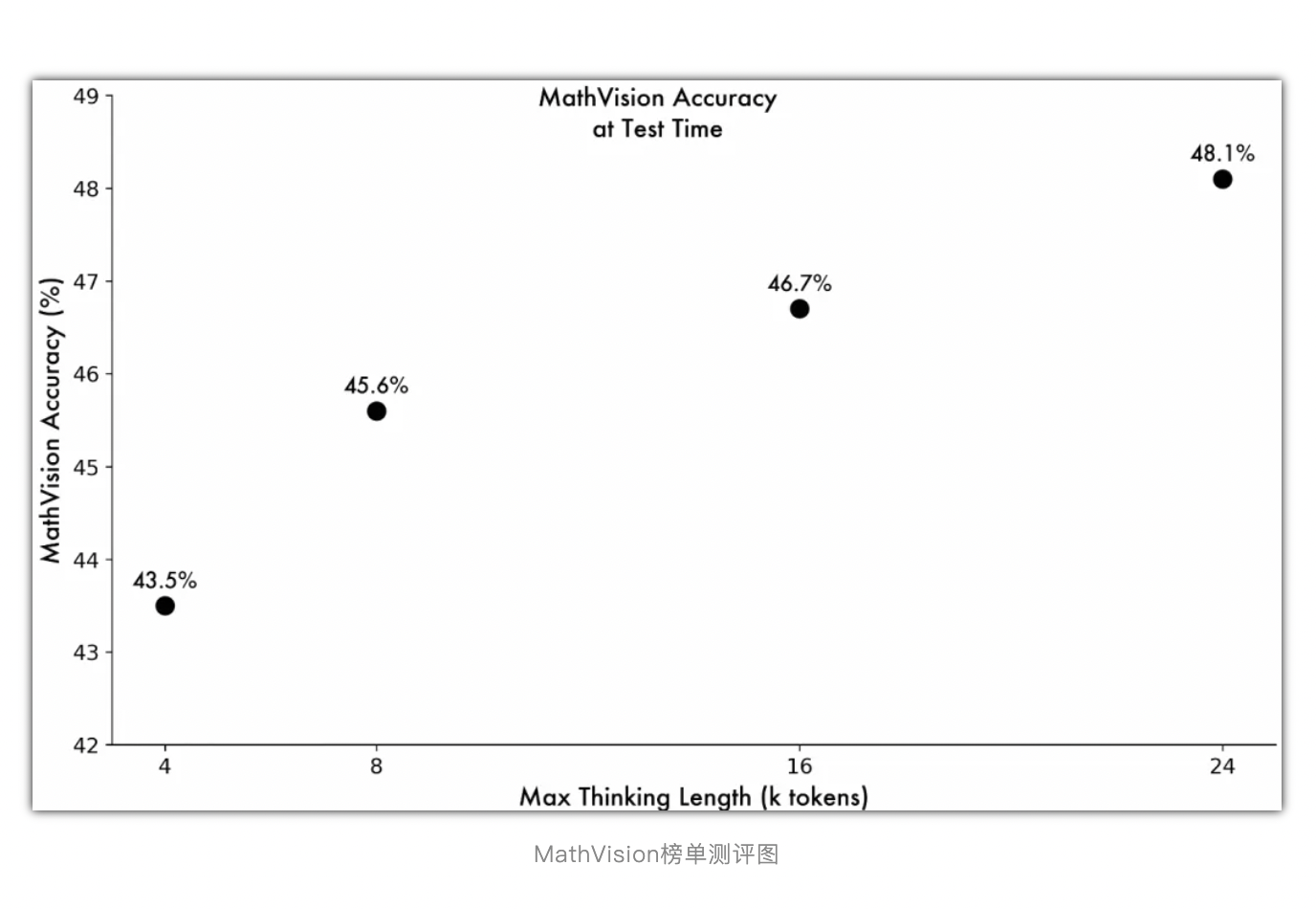
QVQ-Max 的出现,正是顺应了这一时代需求。它致力于打破传统 AI 的局限,实现从“视觉输入 - 语义理解 - 逻辑推导 - 解决方案”的完整闭环。在 MathVision 多模态数学推理榜单中,QVQ-Max 通过调整思维链长度,展现出持续提升的准确率,这一成绩不仅证明了其强大的视觉推理能力,更为多模态 AI 的发展树立了新的标杆。

QVQ-Max 核心能力深度剖析
像素级细粒度观察:洞察微小细节
QVQ-Max 拥有像素级的细粒度观察能力,这使得它在处理复杂图表和生活场景时表现出色。面对学术论文中的多曲线对比图,它能够精准识别坐标轴单位、趋势变化等关键细节。而在日常生活中,通过衣柜照片,它不仅能分析衣物的材质、颜色搭配,甚至还能敏锐地发现袖口磨损等细微特征。
多模态联合推理:跨越领域的智慧
多模态联合推理是 QVQ-Max 的又一核心能力。在数学解题方面,它能够结合几何图形推导三角函数关系,并以 latex 公式的形式输出。在视频分析领域,它通过对实验操作视频的深度解析,能够指出未佩戴护目镜等安全隐患。
跨模态创作能力:激发无限创意
除了强大的分析与推理能力,QVQ-Max 还具备跨模态创作的天赋。作为设计助手,它可以根据用户提供的草图生成矢量设计图,并提供专业的色彩搭配方案。在内容创作方面,它能够解析电影片段,自动生成分镜脚本和台词建议。
全场景覆盖:从学术到生活的广泛应用
科研论文图表解析:提升科研效率
在科研领域,QVQ-Max 能够快速解析论文中的复合图表,自动提取关键数据点,并验证结论的一致性。这一功能极大地提升了科研人员的工作效率,使他们能够将更多的时间和精力投入到核心研究工作中,加速科研成果的产出。
编程学习辅助:助力代码生成与理解
对于编程学习者而言,QVQ-Max 是一位出色的助手。它能够观看算法演示视频,输出对应的 Python 代码,并详细标注时间复杂度的计算过程。例如,在快速排序算法的学习中,它不仅提供了完整的代码实现,还清晰地解释了其时间复杂度在不同情况下的表现。
Python
def quick_sort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr)//2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right)
# 时间复杂度:最佳O(n log n),最差O(n²)工业质检优化:保障生产质量
在工业生产中,QVQ-Max 通过对生产线拍摄的零件图像进行解析,并结合 CAD 图纸比对尺寸公差,实时生成检测报告。这一应用不仅提高了质检的效率和准确性,还降低了人工质检的成本和误差,为工业生产的质量控制提供了有力保障。
技术架构与未来展望
QVQ-Max 采用了先进的混合专家架构(MoE),通过动态路由机制激活不同领域的专业处理模块。这种架构设计使得模型能够灵活应对各种复杂的任务,并充分发挥各领域专家模块的优势。在未来的发展中,QVQ-Max 将持续优化其技术架构,引入 Grounding 机制验证观察准确性,进一步提升视觉校验能力。同时,它还将朝着多模态 Agent 的方向发展,实现跨设备控制,如操作手机 APP、工业机器人等。此外,交互方式的升级也是 QVQ-Max 的重要发展方向之一,未来它将支持流程图、3D 模型等多模态输出,为用户提供更加丰富和直观的交互体验。
即刻体验:开启智能之旅
目前,QVQ-Max 已经在 QwenChat 平台上线,用户可以轻松访问并体验其强大的功能。无论是上传数学题照片获取分步解析,还是输入产品设计草图生成多方案建议,亦或是分析监控视频输出异常事件报告,QVQ-Max 都能够快速给出准确的结果。通过 QwenChat 平台,用户可以直观地感受到 QVQ-Max 带来的便利与高效,开启属于自己的智能之旅。
QVQ-Max 使用方法
图像 Token 计算
QVQ-Max 支持视觉输入及思维链输出,在处理图像时,每 28x28 像素对应一个 Token,一张图最少需要 4 个 Token。以下是一个 Python 示例代码,用于估算图像的 Token 数量:
Python
import math
from PIL import Imagedef token_calculate(image_path):image = Image.open(image_path)height = image.heightwidth = image.widthh_bar = round(height / 28) * 28w_bar = round(width / 28) * 28min_pixels = 28 * 28 * 4max_pixels = 1280 * 28 * 28if h_bar * w_bar > max_pixels:beta = math.sqrt((height * width) / max_pixels)h_bar = math.floor(height / beta / 28) * 28w_bar = math.floor(width / beta / 28) * 28elif h_bar * w_bar < min_pixels:beta = math.sqrt(min_pixels / (height * width))h_bar = math.ceil(height * beta / 28) * 28w_bar = math.ceil(width * beta / 28) * 28token = int((h_bar * w_bar) / (28 * 28)) + 2return token# 示例
image_path = "test.png"
token = token_calculate(image_path)
print(f"图像的 Token 数为:{token}")视频 Token 计算
对于视频输入,QVQ-Max 会根据视频的帧率和分辨率计算 Token 数量。以下是一个 Python 示例代码:
Python
import cv2
import mathdef get_video_info(video_path):cap = cv2.VideoCapture(video_path)frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))video_fps = cap.get(cv2.CAP_PROP_FPS)return frame_height, frame_width, total_frames, video_fpsdef token_calculate(video_path, fps):height, width, total_frames, video_fps = get_video_info(video_path)min_pixels = 128 * 28 * 28max_pixels = 768 * 28 * 28total_pixels = 65536 * 28 * 28nframes = int(total_frames / video_fps * fps)max_pixels = max(min(max_pixels, total_pixels / nframes * 2), min_pixels * 1.05)h_bar = max(28, round(height / 28) * 28)w_bar = max(28, round(width / 28) * 28)if h_bar * w_bar > max_pixels:beta = math.sqrt((height * width) / max_pixels)h_bar = math.floor(height / beta / 28) * 28w_bar = math.floor(width / beta / 28) * 28elif h_bar * w_bar < min_pixels:beta = math.sqrt(min_pixels / (height * width))h_bar = math.ceil(height * beta / 28) * 欢迎留言、一键三连!BuluAI 算力平台新上线通义推理模型QwQ-32B,也可一键部署deepseek!!再也不用为算力发愁嘞, 点击官网了解吧!






