pandas库学习
文章目录
- pandas库学习
- 前言
- Series
- 创建series类对象
- 获取索引和数据
- DataFrame对象
- 构造方法
- 传入字典创建 DataFrame
- 传入二维数组(ndarray)创建 DataFrame
- 自定义行索引和列索引创建 DataFrame
- 操作方法
- 获取一列数据
- 查看摘要信息
- 索引和切片操作
- 索引对象
- Index类的子类
- 特性
- 重置索引
- 通过索引和切片获取数据
- Series的索引和切片操作
- DataFrame的索引和切片操作
- 通过loc和iloc属性获取数据
- 总结
前言
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
Series
series是类似于一维数组的数据结构, 主要由一组数据和与之相关的索引两部分组成, 其中数据可以是任意类型, 比如整数、字符串、浮点数、python对象等。
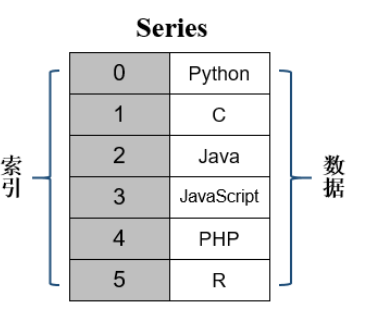
创建series类对象
首先要导入pandas库:
import pandas as pd
通过向series构造方法中传入一个列表创建一个Series对象
ser_obj = pd.Series([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
ser_obj
可传参数:
data表示数据,它的值可以是ndarray对象、列表、字典、标量等。index表示索引,他的值必须是可散列的,且于数据的长度相同。如果没有传入index参数,默认从0开始递增;如果data参数的值是字典类型且index参数的
obj = {"name": "John","age": 30,"city": "New York"
}
ser_obj = pd.Series(data=obj)
ser_obj

当创建Series类的对象时,也可以显式地给数据指定标签索引
ser_obj = pd.Series(data=['Python', 'C', 'Java', 'JavaScript', 'PHP', 'R'],
index=['a', 'b', 'c', 'd', 'e', 'f'])
虽然我们现在只能看到用户指定的标签索引,但是系统仍然会生成一组位置索引,只是位置索引是隐藏的。
获取索引和数据
通过index属性获取Series类对象的索引
ser_obj.index
通过values属性获取Series类对象的数据
ser_obj.values
二者皆为可迭代对象,皆可循环通过索引访问。
DataFrame对象
DataFrame是一个类似于二维数组或表格的数据结构,它通过行列的形式组织数据,每列数据可以是不同的数据类型。与Series相比,DataFrame也是由索引和数据两部分组成,不同的是,DataFrame既有行索引又有列索引。
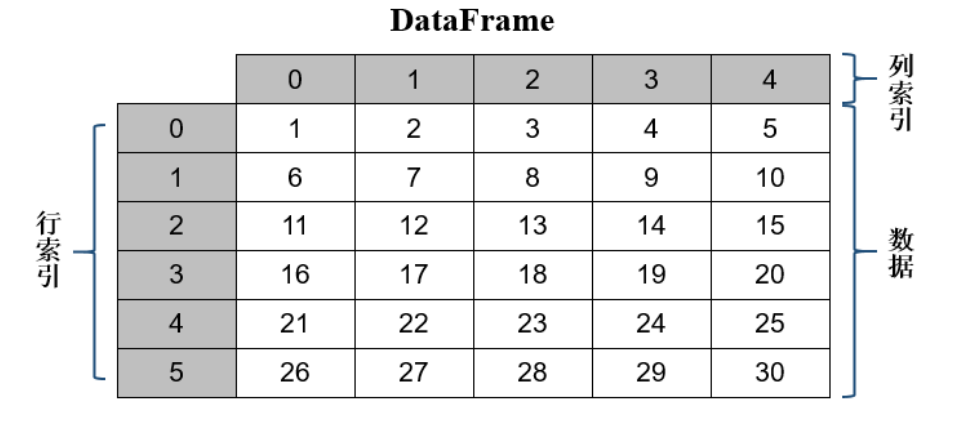
DataFrame可以看作多个Series类对象的组合,它里面每一列数据是一个Series类的对象,这些对象之间共用同一个行索引
构造方法
DataFrame(data=None, index=None, columns=None, dtype=None, copy=None)
data数据,该参数可以接收ndarray对象、列表、字典或其他DataFrame类的对象。index行索引,如果没有传入该参数,则默认会自动生成0~N的整数。columns列索引。如果没有传入索引参数,则默认会自动生成0~N的整数。
传入字典创建 DataFrame
data = {'name': ['Alice', 'Bob', 'Charlie'],'age': [25, 30, 35]}
df = pd.DataFrame(data)
print(df)

在这个例子中,data 是一个字典,键 ‘name’ 和 ‘age’ 成为 DataFrame 的列名,对应的值列表分别构成了这两列的数据。运行代码会输出一个包含两列(name 和 age)和三行数据的 DataFrame 。
传入二维数组(ndarray)创建 DataFrame
import numpy as np
import pandas as pdarr = np.array([[1, 2, 3],[4, 5, 6]])
df = pd.DataFrame(arr)
print(df)

这里没有设置行、列索引,所以默认值从0开始递增。
自定义行索引和列索引创建 DataFrame
data = {'math': [85, 90], 'english': [92, 88]}
df = pd.DataFrame(data, index=['student1','student2'], columns=['math', 'english'])
print(df)

操作方法
获取一列数据
如果想要从DataFrame类的对象中获取一列数据,则可以通过访问属性的方式获取,返回的结果是一个Series类的对象
result = df_obj.No2
result = df_obj['No_2']
result
如果索引的标签名称中有一些特殊的字符,比如空格、下画线等,那么通过访问属性的方式获取数据显得不太合适了,这时可以
使用索引获取数据。
查看摘要信息
df_obj.info()

索引和切片操作
索引对象
Index类的子类
在pandas中,无论是位置索引还是标签索引,它们都属于Index类的对象,也就是索引对象。Index类是一个基类,它派生了很多子类,每个子类代表不同形式的索引。
| 类 | 说明 | 示例 |
|---|---|---|
| RangeIndex | 位置索引(默认) | 0、1、2、3……N |
| Int64Index | 整数索引 | 1、-5、8、10、-9 |
| Float64Index | 浮点数索引 | -1.0、-5.5、10.2、9.8、6.3 |
| DatetimeIndex | 时间戳索引 | 2022-11-25 17:00:00、2022-11-28 17:00:00、2022-12-25 17:00:00 |
| PeriodIndex | 时间间隔索引 | 2022-11-25 00:00:00、2022-11-25 01:00:00、2022-11-25 02:00:00…… |
| MultiIndex | 分层索引 | a a、a b、a c、b d、b e |
特性
不可变性:
索引对象一旦创建是不可以被修改的,也就是说,索引的值是固定不变的,这样做能够维护从索引到数据的唯一映射关系,并保证Series或DataFrame中数据的安全
ser_obj = pd.Series(range(5), index=['a', 'b', 'c', 'd', 'e'])
ser_index['2'] = 'cc'
TypeError: Index does not support mutable operations
可重复性:
索引对象的值是可以重复的
ser_obj = pd.Series(range(5), index=['a', 'a', 'c', 'd', 'e'])
ser_index = ser_obj.index
ser_index
检索唯一性
ser_index.is_unique

重置索引
重置索引是指重新为对象设定索引,以构建一个符合新索引的对象
reindex()方法会对Series类或DataFrame类对象的原索引和新索引进行匹配,如果新索引跟原索引的值相同,则新索引对应的数据会被设置为原数据;如果新索引跟原索引的值不同,则新索引对应的空缺位置会被填充为NaN或指定的其他值。
下面以DataFrame类的reindex()方法为例,介绍reindex()方法的语法格式。
reindex(labels=None, index=None, columns=None, axis=None, method=None, copy=True, level=None, fill_value=nan,limit=None, tolerance=None)
以下是 reindex() 方法各参数的介绍:
- index:可选参数,用于指定新的
行索引。可以是列表、数组等序列形式。若指定,DataFrame的行索引会按其重新排列,新增索引对应位置会根据填充策略处理,没有对应数据时可能填充缺失值 。 - columns:可选参数,用于指定新的列索引 。形式要求和
index类似。指定后,DataFrame列索引会按其调整,新增列索引对应位置按填充策略处理 。 - method:可选参数,用于指定空缺位置的填充方式 。取值及含义如下:
None:默认值,不填充空缺位置,新索引对应无原始数据位置为缺失值 。'ffill'或'pad':前向填充,用前一个有效数据填充空缺 。'bfill'或'backfill':后向填充,用后一个有效数据填充空缺 。'nearest':根据最近的值填充空缺位置 。要求数据在对应轴上单调增减 。
- level:可选参数,当索引是多层索引(
MultiIndex)时使用 。用于指定在多层索引的哪个层级上进行广播和匹配索引值 。比如对有两层行索引的DataFrame,指定level可在特定层级调整索引 。 - fill_value:可选参数,默认值为
nan。用于在计算前填充已存在的缺失值 。在新索引与原数据对齐时,若有缺失值(NaN),可用该参数指定的值替换 。 - limit:可选参数,用于限定前向或后向填充的最大连续元素数量 。比如
method='ffill'时,设置limit = 2,则连续空缺最多填充 2 个元素 。 - tolerance:可选参数,用于指定不精确匹配时,原始标签和新标签之间的最大距离 。在匹配位置,索引值需满足
abs(index(indexer) - target) <= tolerance。适用于数值型索引的近似匹配场景 。
# 创建一个DataFrame
data = {'A': [1, 2, 3],'B': [4, 5, 6]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
print(df)
# 使用reindex方法修改行索引
print("----------------------------")
new_index = ['a', 'b', 'c', 'd']
new_df = df.reindex(index=new_index, method='ffill')
print(new_df)
print("----------------------------")
# 使用reindex方法修改列索引
new_columns = ['A', 'B', 'C']
new_df_2 = df.reindex(columns=new_columns, fill_value=0)
print(new_df_2)

df_obj = pd.DataFrame({'no1': [1.0, 2.0, 3.0], 'no2': [4.0, 5.0, 6.0]}, index=['a', 'b', 'c'])
new_df = df_obj.reindex(index=['a', 'c', 'e'], fill_value=9)
print(df_obj)
print(new_df)

新的索引中a、c是原来就有的,所有直接覆盖原来的,e索引又是没有的,所以通过fill_value 填充为9
通过索引和切片获取数据
pandas中通过索引或切片可以获取Series类和DataFrame类对象的数据,由于Series类和DataFrame类对象的结构有所不同,所以它们的索引和切片操作也会有所不同。
Series的索引和切片操作
Series类对象与NumPy一维数组的索引用法相似,不同的是,Series类对象的索引既可以是位置索引,也可以是标签索引。如果需要获取Series类对象的单个数据,则可以通过位置索引和标签索引进行获取。
import pandas as pd
ser_obj = pd.Series([10, 20, 30, 40, 50], index=['one', 'two', 'three', 'four', 'five'])
# 通过位置索引获取
ser_obj[2]
# 通过参数索引获取
ser_obj['three']
如果想要获取多个数据,则可以传入一个数组。
ser_obj[[0, 2, 3]]
ser_obj[['one', 'three', 'four']]
布尔索引同样适用于pandas,具体用法与一维数组的布尔索引用法相同,即将Series类的对象中每个数据进行逻辑运算,只要运算结果为True,就返回Series类对象中位置为True对应的数据
ser_obj[ser_obj > 20]
通过切片也可以获取Series类的对象中的部分数据。如果切片使用的索引是位置索引,则切片结果包含起始位置但不包含结束位置对应的数据;如果切片使用的索引是标签索引,则切片结果既包含起始位置又包含结束位置对应的数据。
ser_obj[1:3]
ser_obj['two':'four']
DataFrame的索引和切片操作
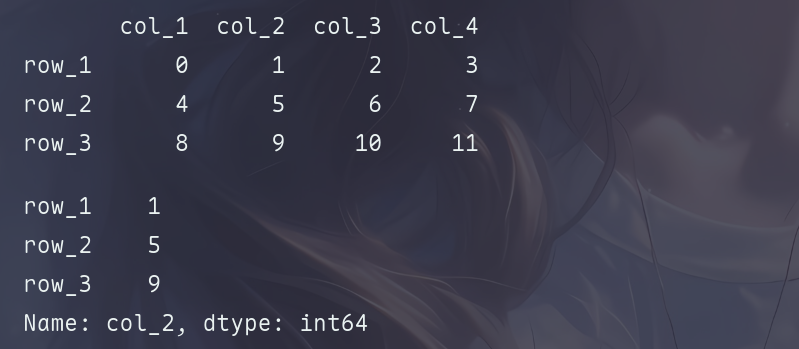
DataFrame类对象与NumPy二维数组的索引用法相似,它里面每一列数据都是一个Series类的对象,可以通过列索引进行获取。
arr = np.arange(12).reshape(3, 4)
df_obj = pd.DataFrame(arr, index=['row_1', 'row_2', 'row_3'], columns=['col_1', 'col_2', 'col_3', 'col_4'])
print(df_obj)
df_obj['col_2']
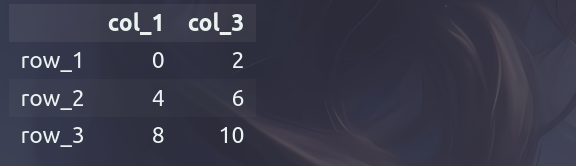
如果想要从DataFrame类对象中获取多列数据,那么可以将多个索引存放到列表中,再分别根据列表里面的每个索引进行获取,此过程相当于利用花式索引获取二维数组元素的操作。
df_obj[['col_1', 'col_3']]
如果想要获取多行数据,那么已通过切片完成
df_obj[1:3]

还可以通过切片获取部分行部分列
df_obj[1:3][['col_1','col_3']]

列好像不能这样切片
通过loc和iloc属性获取数据
前面介绍索引和切片的相关操作时,既可以单独使用位置索引或标签索引来获取数据,也可以混合使用位置索引、标签索引进行获取,这对刚接触pandas的开发人员来说是十分混乱的。为了从严格意义上区分位置索引和标签索引的相关操作,pandas中提供了两个非常重要的属性,分别是loc和iloc,其中loc是基于标签索引的索引器, iloc是基于位置索引的索引器。
loc属性用于根据标签索引来获取数据。
语法
Series.loc[参数]DataFrame.loc[参数1, 参数2]
可使用的标签索引形式
- 单个标签索引,比如
a、No1、row_1、col_1等。 - 标签索引构成的列表或数组,比如
['a', 'b', 'c']、['col_1','col_3']等。 - 基于标签索引的切片,比如
'a':'c'、'two':'four'。 - 布尔类型的列表或数组,比如
[True, False, True]。
注意:参数1和参数2中涉及的索引分别是行索引和列索引,如果省略参数2,则此时获取的结果是DataFrame类的对象的一行或多行数据。
获取Series类对象的数据
import pandas as pd
ser_obj = pd.Series([10, 20, 30, 40, 50],index=['row1', 'row2', 'row3', 'row4', 'row5'])
- 获取单个数据
ser_obj.loc['row2']
- 获取多个数据
ser_obj.loc[['row2', 'row5']]
- 获取多个连续数据
ser_obj.loc['row3':'row5']
- 获取符合条件的数据
ser_bool = ser_obj < 30
ser_obj.loc[ser_bool]
获取DataFrame类对象的数据
import numpy as np
import pandas as pd
arr = np.arange(12).reshape(3, 4)
df_obj = pd.DataFrame(arr, index=['row_1', 'row_2', 'row_3'],columns=['col_1', 'col_2', 'col_3', 'col_4'])
行数据获取
- 获取一行数据
df_obj.loc['row_1']
- 获取多行数据
df_obj.loc[['row_1', 'row_3']]
- 获取连续多行数据
df_obj.loc['row_1':'row_2']
- 获取符合条件多行数据
df_obj.loc[[True, False, True]]
行列数据获取
- 获取单个数据
df_obj.loc['row_3', 'col_3']

- 获取多列数据
df_obj.loc['row_1':'row_3', ['col_1', 'col_3']]
通过iloc属性获取数据
iloc属性用于根据位置索引来获取数据。
语法
Series.iloc[参数]DataFrame.iloc[参数1, 参数2]
可使用的位置索引形式
- 单个位置索引,比如
0、1、2、3等。 - 位置索引构成的列表或数组,比如
[0, 2, 3]等。 - 基于位置索引的切片,比如
0:2、2:5。 - 布尔类型的列表或数组,比如
[True, False, True]。
示例
假设有df_obj :
- 获取一行数据
df_obj.iloc[0]
- 获取多行数据
df_obj.iloc[[0, 2]]
- 获取连续多行数据
df_obj.iloc[0:2]
- 获取符合条件多行数据
df_obj.iloc[[True, False, True]]
- 获取单个数据
df_obj.iloc[2, 2]
- 获取多列数据
df_obj.iloc[0:3, [0, 2]]
总结
在机器学习领域蓬勃发展的当下,pandas库成为数据处理与分析的关键利器。本文聚焦pandas核心知识,涵盖Series和DataFrame数据结构、索引与切片操作,助力读者快速上手,为机器学习实践筑牢根基。
Series数据结构:Series类似一维数组,由数据和索引构成,数据类型丰富多样。创建时,可传入列表、字典等,还能自定义索引。比如,pd.Series([1, 2, 3], index=['a', 'b', 'c'])。通过index和values属性,能便捷获取索引和数据,二者均支持迭代访问。DataFrame数据结构:DataFrame类似二维数组或表格,兼具行索引与列索引,各列数据类型可不同,可视为多个Series的组合。创建方式多元,如传入字典时,键为列名,值列表为列数据;传入二维数组时,默认生成行列索引;还能自定义行列索引。获取列数据时,普通列名可用属性访问,特殊字符列名需用索引获取,info()方法则用于查看数据摘要。- 索引对象详解:索引对象隶属
Index类,其包含多种子类,如RangeIndex(默认位置索引)、Int64Index(整数索引)等,满足不同场景需求。索引对象具备不可变性,确保数据映射稳定;同时支持可重复性,is_unique方法可判断索引唯一性。reindex()方法用于重置索引,可灵活调整行列索引,依据填充策略处理新索引空缺值,method参数可选填充方式,fill_value指定填充值 。 - 索引和切片操作:
Series的索引和切片操作灵活,可依位置或标签索引获取单个、多个数据,布尔索引筛选数据,切片时位置索引和标签索引规则有别。DataFrame可通过列索引获取列数据,切片获取行数据,还能同时获取部分行列数据。loc和iloc属性则精准区分标签索引和位置索引操作,按相应索引规则获取数据,使数据获取更严谨、高效。
熟练掌握pandas这些关键内容,能大幅提升数据处理效率。无论是数据清洗、预处理,还是后续深度分析,都能游刃有余。希望读者持续探索,在机器学习与数据分析领域收获更多成果。





