PDF解析对于包括文档分类、信息提取和检索在内的多种自然语言处理任务至关重要,尤其是RAG的背景下。尽管存在各种PDF解析工具,但它们在不同文档类型中的有效性仍缺乏充分研究,尤其是超出学术文档范畴。通过使用DocLayNet数据集,比较10款流行的PDF解析工具在6种文档类别中的表现,以填补这一空白。这些工具包括PyPDF、pdfminer.six、PyMuPDF、pdfplumber、pypdflum2、Unstructured、Tabula、Camelot以及基于深度学习的工具Nougat和Table Transformer(TATR)。
对于基于深度学习的相关技术方法,笔者在前期介绍了完整的技术链路,可以参考《文档智能专栏(点击跳转)》
对于对pdf解析质量要求不高并且要求速度比较快的场景,基于规则引擎的相关pdf parser工具可以依旧满足相关业务场景,那么该如何选择pdf解析工具呢?
pdf解析的挑战:
- 复杂性:PDF解析面临多个挑战,包括单词识别、词序保持、段落完整性以及表格提取等。这些挑战要求解析工具能够准确地识别和处理文档中的各种元素。
- 技术需求:PDF解析方法可以分为基于规则的方法和基于深度学习的方法。基于规则的方法通常在计算效率和部署速度上具有优势,而基于学习的方法在处理复杂文档时表现出色。
本文通过比较10种流行的PDF解析工具在6种不同文档类别上的表现,提供对工具性能的全面评估。供参考。
评估方法

评测数据集
DocLayNet 是一个包含约80,000个文档页面的大型数据集,文档被标注为11种不同的元素(如脚注、公式、列表项、页脚、页眉、图片、节头、表格、文本和标题)。这些文档分为六个不同的类别:财务报告、手册、科学文章、法律法规、专利和政府招标。
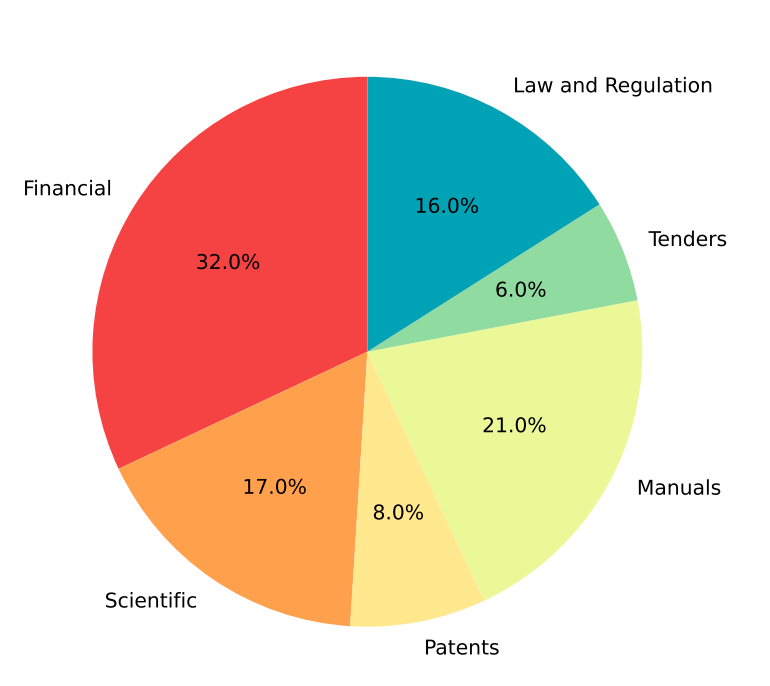
文档主要用英语标注(95%),少量用德语(2.5%)、法语(1%)和日语(1%)。为了确保标注的高质量和可靠性,大约7,059个文档进行了双重标注,1,591个文档进行了三重标注。
评估指标
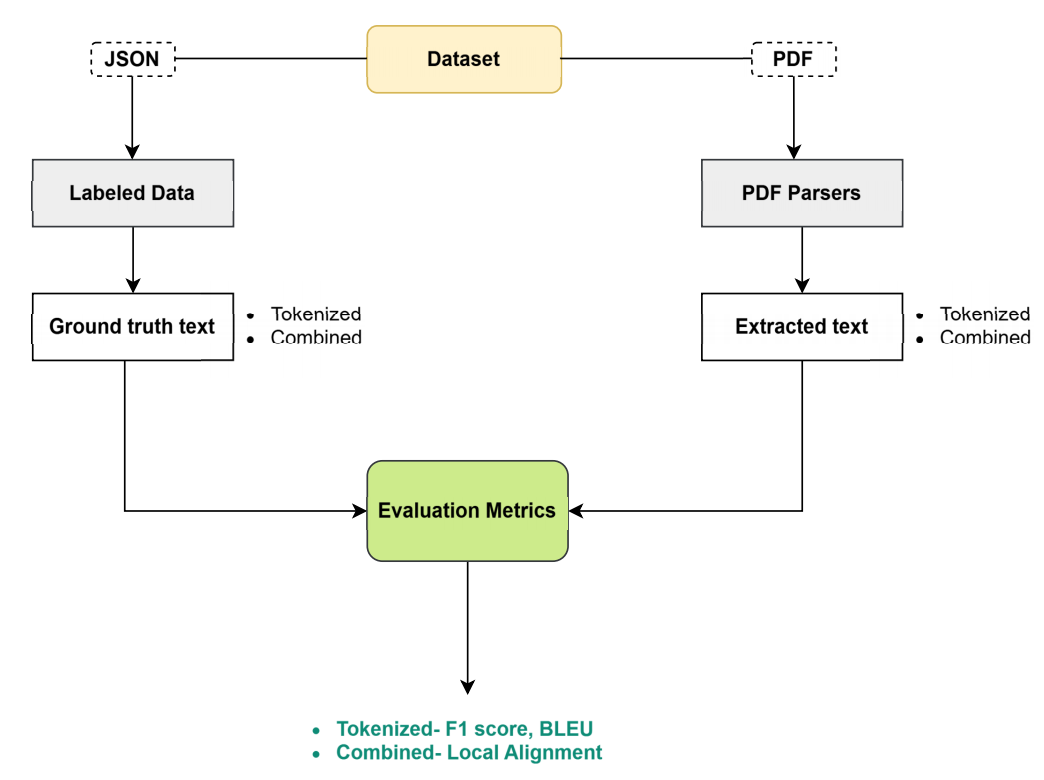
并使用多种评估指标进行比较,包括F1分数、BLEU分数和局部对齐分数。
在文档中,评估策略特别关注于文本提取的质量,尤其是当涉及到复杂的文档结构和内容时。以下是如何结合具体的公式和评估指标来详细讲解评估策略:
文本提取的评估策略
1.Levenshtein 相似性
L s ( s 1 , s 2 ) = 1 − L d ( s 1 , s 2 ) max ( l 1 , l 2 ) L_s(s_1, s_2) = 1 - \frac{L_d(s_1, s_2)}{\max(l_1, l_2)} Ls(s1,s2)=1−max(l1,l2)Ld(s1,s2)
2.F1 分数
3.BLEU 分数
B L E U = B P ⋅ exp ( ∑ n = 1 N w n log p n ) BLEU = BP \cdot \exp\left(\sum_{n=1}^{N} w_n \log p_n\right) BLEU=BP⋅exp(n=1∑Nwnlogpn)
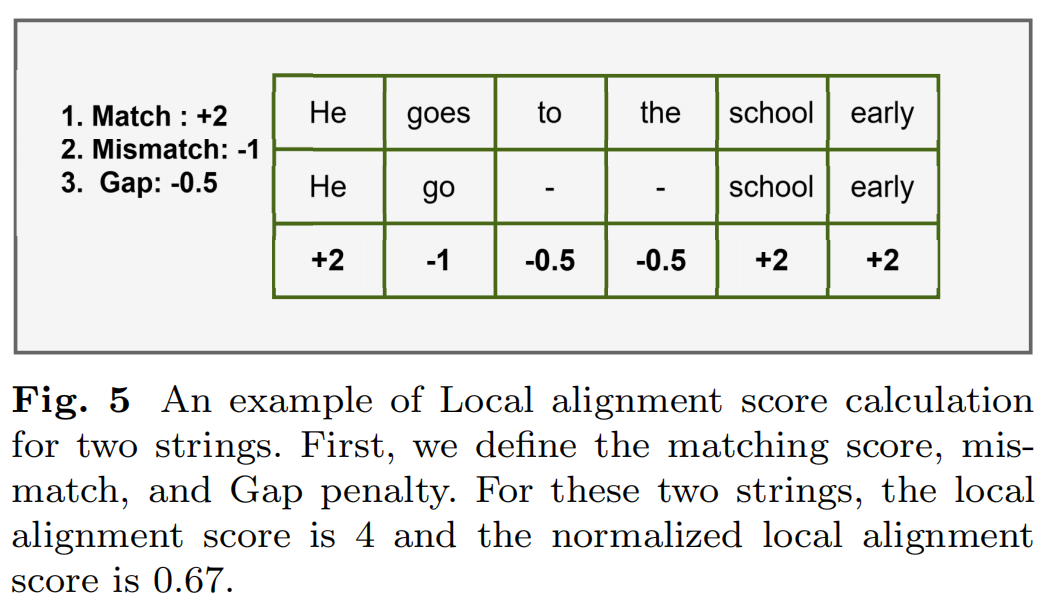
4.局部对齐分数
局部对齐分数用于评估文本提取的整体质量,特别是在处理复杂布局和段落结构时。局部对齐通过寻找两个字符串中最相似的子串来实现,使用匹配得分、不匹配和间隙惩罚来计算相似性。
表格检测评价指标
使用交并比(IoU)来比较解析器提取的表格与GT表格的相似性。如果解析器不提供边界框信息,则使用Jaccard系数计算检测的精确度和召回率。
IoU = ∣ A ∩ B ∣ ∣ A ∪ B ∣ \text{IoU} = \frac{|A \cap B|}{|A \cup B|} IoU=∣A∪B∣∣A∩B∣
评测工具
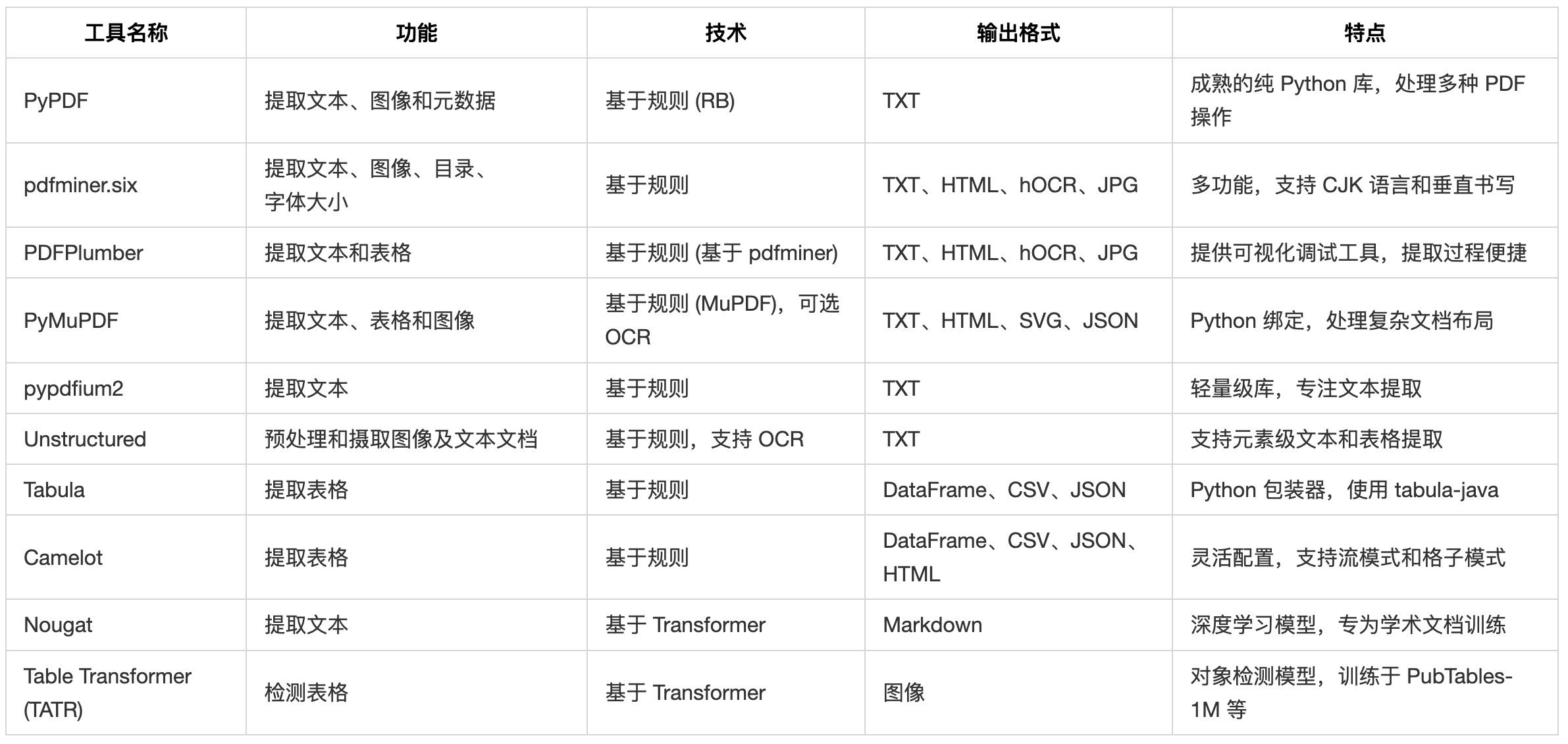
| 工具名称 | 功能 | 技术 | 输出格式 | 特点 |
|---|---|---|---|---|
| PyPDF | 提取文本、图像和元数据 | 基于规则 (RB) | TXT | 成熟的纯 Python 库,处理多种 PDF 操作 |
| pdfminer.six | 提取文本、图像、目录、字体大小 | 基于规则 | TXT、HTML、hOCR、JPG | 多功能,支持 CJK 语言和垂直书写 |
| PDFPlumber | 提取文本和表格 | 基于规则 (基于 pdfminer) | TXT、HTML、hOCR、JPG | 提供可视化调试工具,提取过程便捷 |
| PyMuPDF | 提取文本、表格和图像 | 基于规则 (MuPDF),可选 OCR | TXT、HTML、SVG、JSON | Python 绑定,处理复杂文档布局 |
| pypdfium2 | 提取文本 | 基于规则 | TXT | 轻量级库,专注文本提取 |
| Unstructured | 预处理和摄取图像及文本文档 | 基于规则,支持 OCR | TXT | 支持元素级文本和表格提取 |
| Tabula | 提取表格 | 基于规则 | DataFrame、CSV、JSON | Python 包装器,使用 tabula-java |
| Camelot | 提取表格 | 基于规则 | DataFrame、CSV、JSON、HTML | 灵活配置,支持流模式和格子模式 |
| Nougat | 提取文本 | 基于 Transformer | Markdown | 深度学习模型,专为学术文档训练 |
| Table Transformer (TATR) | 检测表格 | 基于 Transformer | 图像 | 对象检测模型,训练于 PubTables-1M 等 |
评测结论
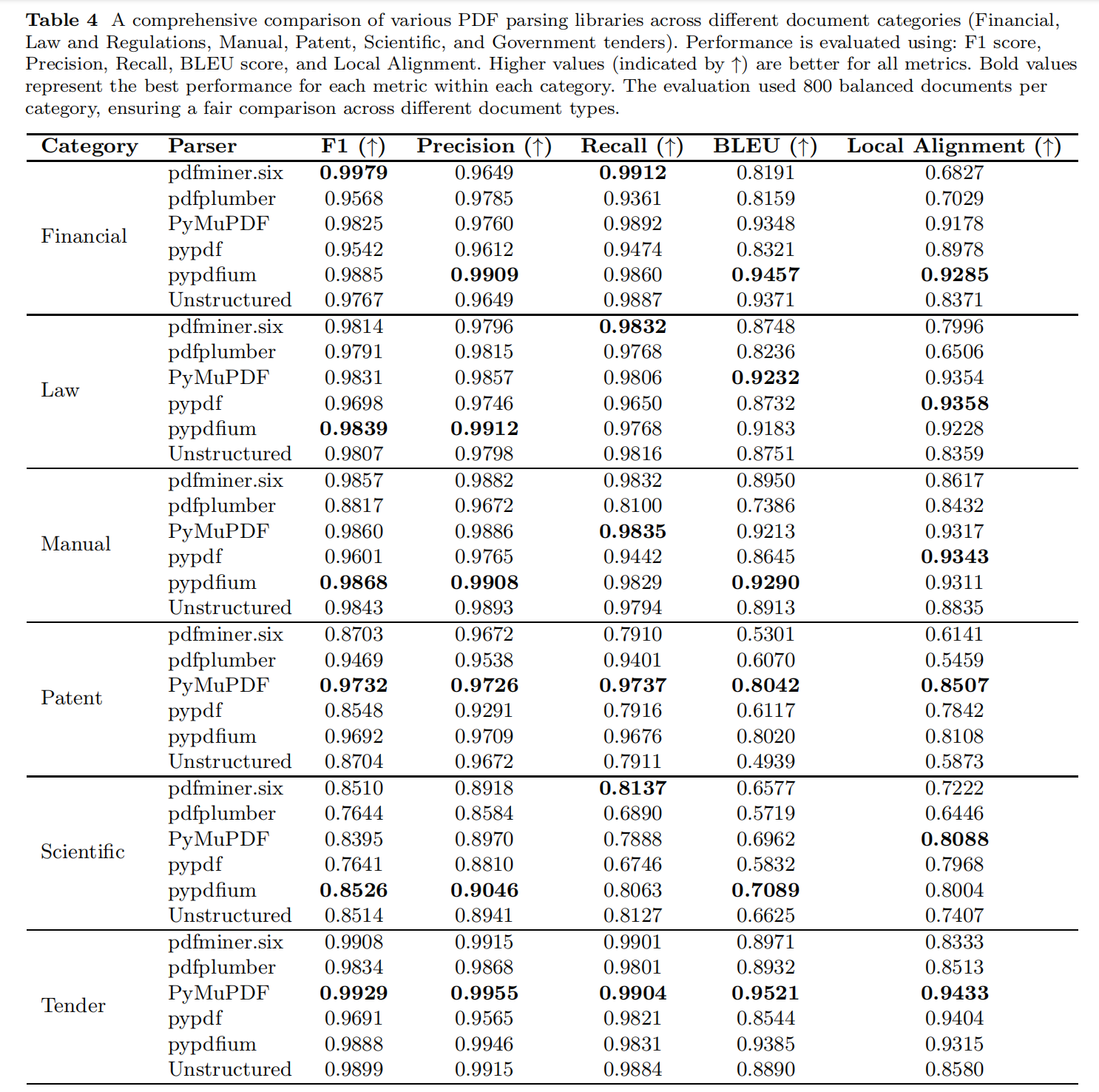
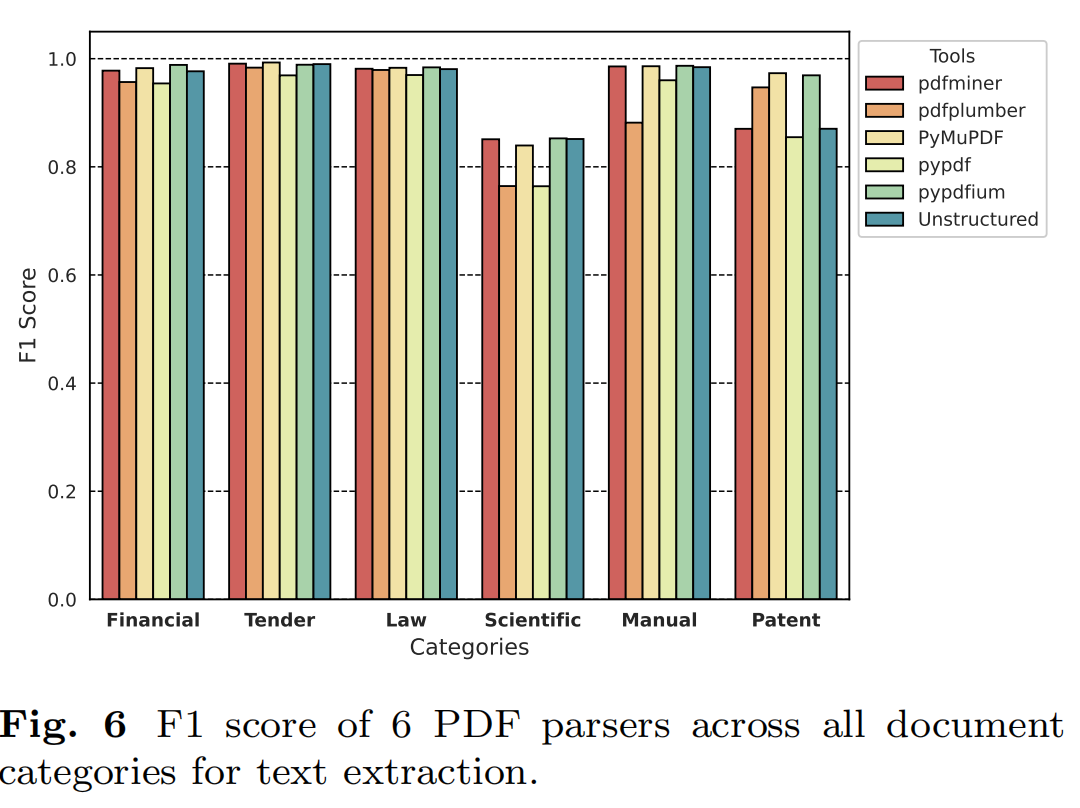
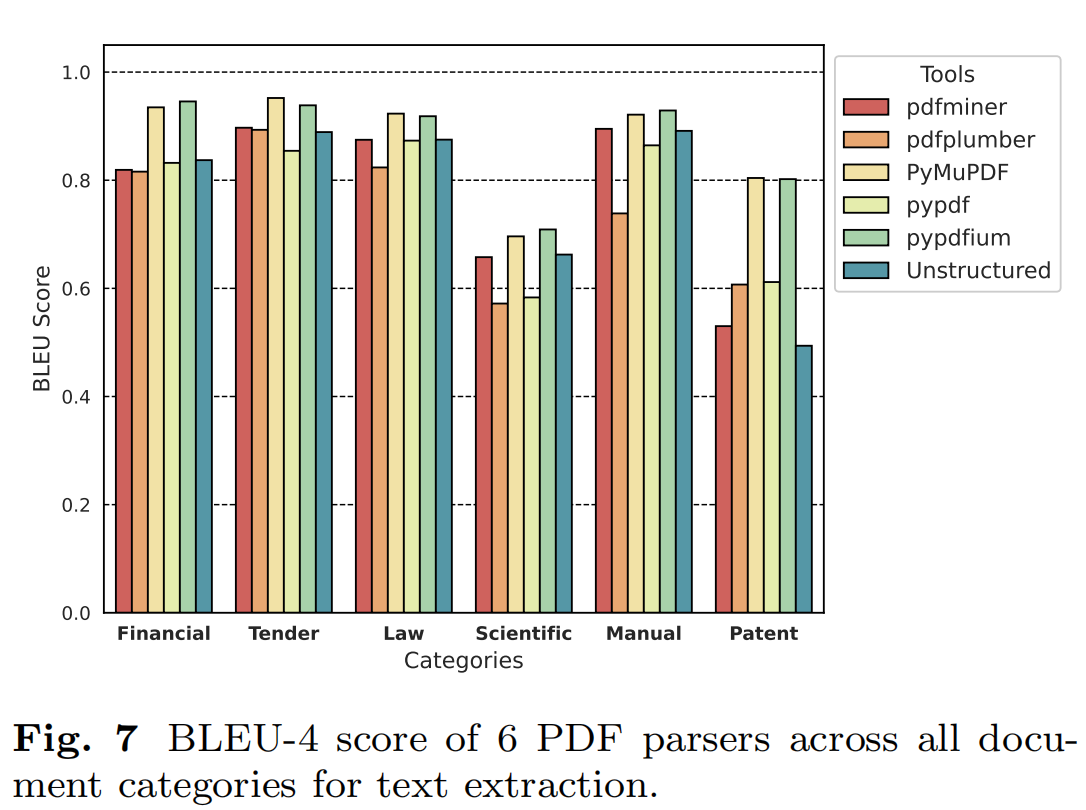
- 文本提取结论
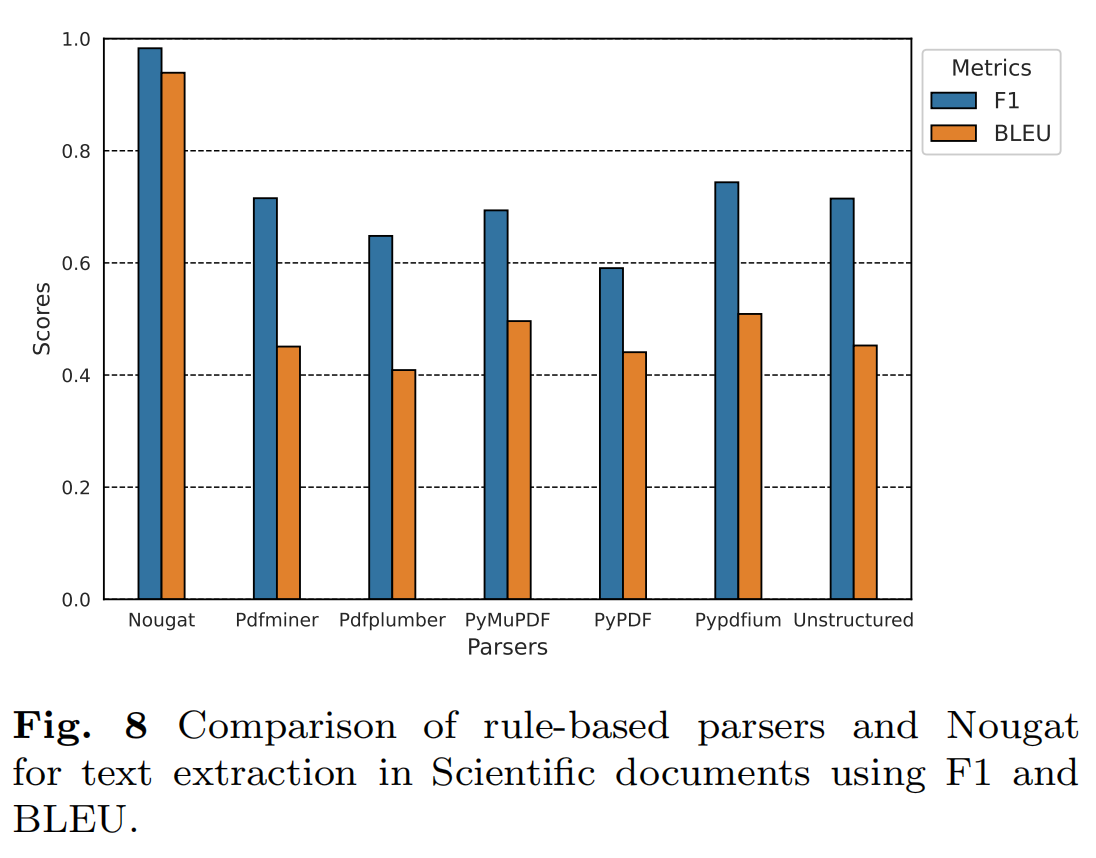
在财务、招标、法律法规和手册类别中,大多数工具表现较好,PyMuPDF和pypdfium在这些类别中表现尤为突出。在科学和专利类别中,所有工具的表现均有所下降。PyMuPDF和pypdfium在专利类别中表现相对较好,但科学类别仍然是一个挑战。Nougat作为一个基于视觉变换器的模型,在科学文档的文本提取中表现出色。Nougat在科学文档中表现优于所有基于规则的工具。
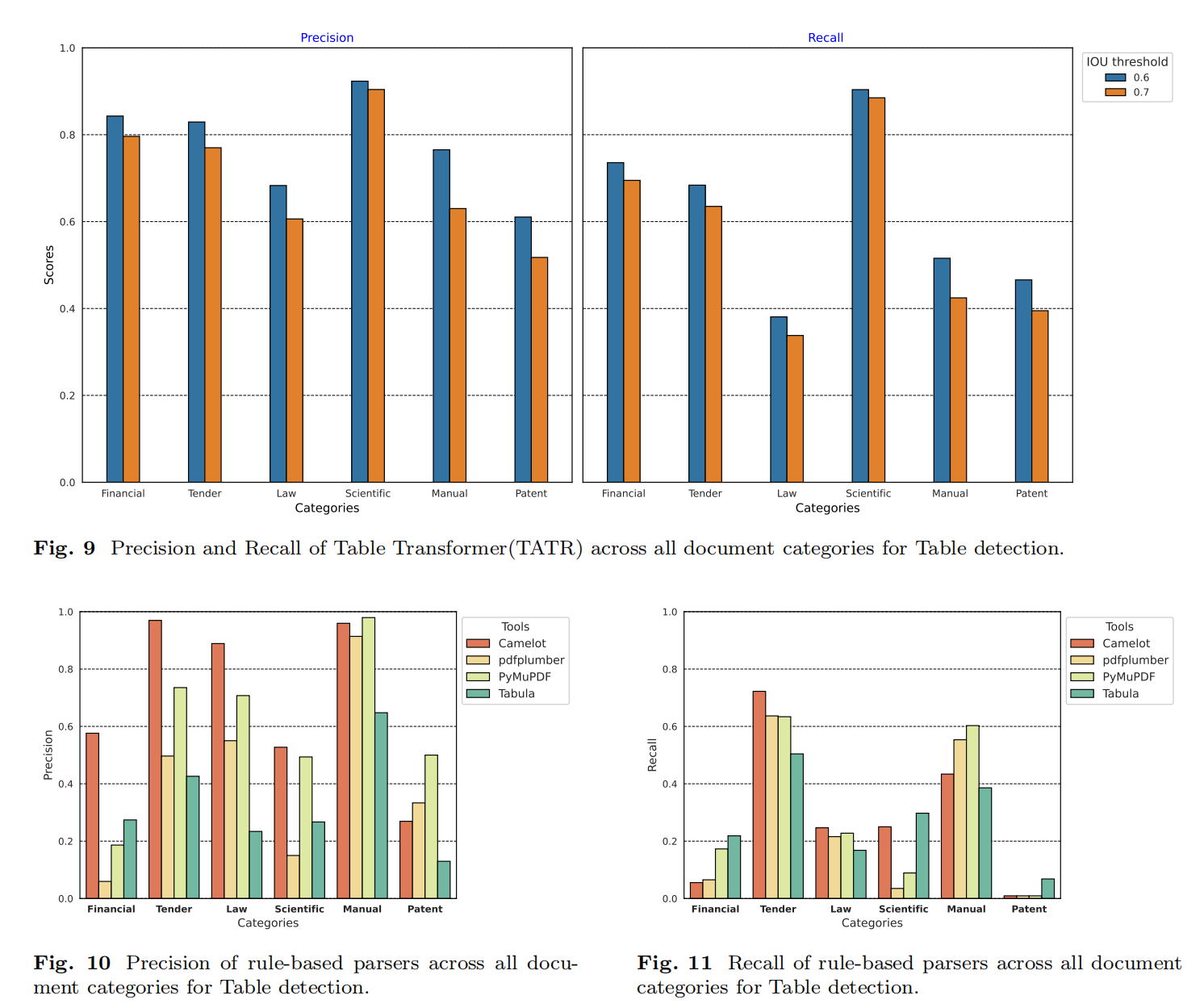
- 表格检测结论
评估了四种基于规则的PDF表格提取工具(Camelot、pdfplumber、PyMuPDF、Tabula)和一个基于Transformer的模型(TATR)在表格检测任务中的表现。规则工具在特定文档类型中表现良好,但在其他类别中表现不佳。Camelot在政府招标类别中表现最佳,Tabula在手册、科学和专利类别中表现较好。TATR在所有类别中表现出较高的召回率和一致性。在科学、财务和招标类别中,TATR的召回率较高,显示出其在处理复杂表格结构时的优势。
总结
其实,全文看下来,这个评测的粒度还是比较粗的,但是其中的对于基于规则的pdf parser工具结论还是值得看一看的。在具体的业务场景中,选择合适的解析工具需要考虑文档类型和具体任务的需求。
参考文献:A Comparative Study of PDF Parsing Tools Across Diverse
Document Categories,https://arxiv.org/pdf/2410.09871v2






