监督学习
使用传统训练集学习一个模型,模型训练好之后,给模型看新的图片做预测。
测试样本图片属于已知类别,模型未见过的图片。

小样本学习:
小样本学习的目标:
让机器学会学习。学习的目的是理解事物的异同,学会区分不同的事物。
给两张图片,不是让模型识别出是什么,而是两张图片是相同的东西还是不同的东西。
训练后的目标是,在没有进行训练的类别中,模型是否可以识别未知类别是否是同一内容。


1、支持集(Support Set):
少量标注样本,即有标签样本。小就体现在这里。
其中,任务形式通常描述为N-way,K-shot形式定义:
- N-way:分类任务包括N个类别;
- K-shot:每个类别提供K个标注样本(支持集)
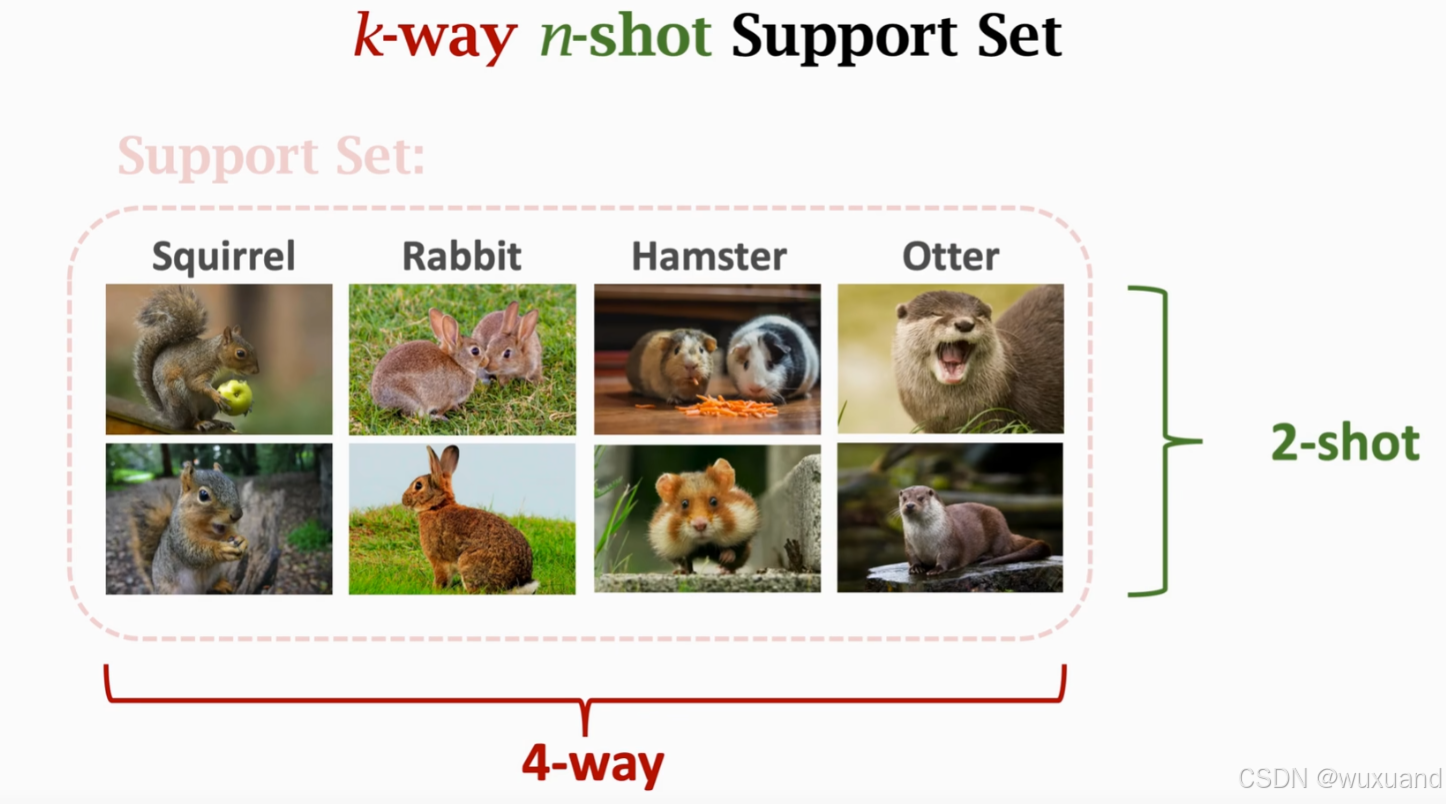
例如,下面图片中,
1、支持集分为四类,每类有两张标注样本,此时,该任务描述为4-way 2-shot
2、支持集分为两类(犰狳和穿山甲),每类有两张标注样本(两张犰狳和两张穿山甲)。此时,该任务可以描述为:2-way 2-shot
2、查询集(Query Set):
模型需对未知样本进行分类,即无标签样本。
例如,下面图片中,需要识别当前图片为哪一类。
其中,支持集和查询集类别一致。

3、训练集(Training Set):
训练集规模很大,每一类下面都有很多图片,足以训练一个神经网络。
训练的目的是让模型知道事物的异同。
之后,靠支撑集提供的一点信息,去识别查询集中的内容是什么。

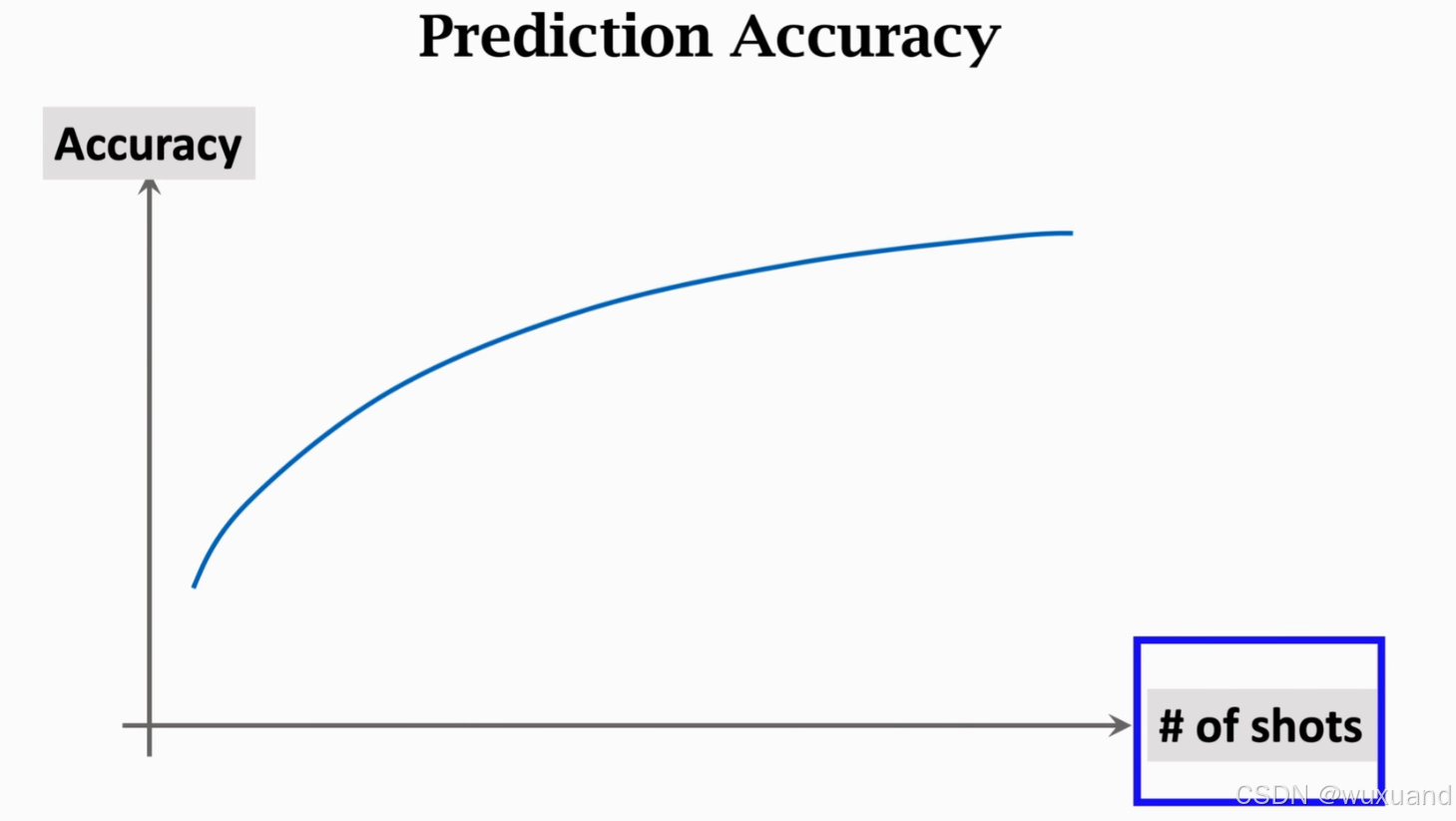
4、预测准确率:
随着类别增加,分类准确率会降低。

每个类别的样本越多,做预测越准确。

)



