Interrupt 2025 大会已圆满落下帷幕!今年,来自全球各地的 800 多位人士齐聚旧金山,参加了 LangChain 首次举办的行业盛会,共同聆听各团队分享构建 AI Agent 的经验故事——会议的精彩和余温至今仍令人振奋! 思科、优步、Replit、领英、贝莱德、摩根大通、Harvey 等众多公司都分享了他们在架构、评估 (evals)、可观测性 (observability) 以及 Prompting(提示设计)策略方面的宝贵经验,涵盖了遇到的挑战和取得的成功。
精彩回顾 ✨
主旨演讲要点:
Harrison 在 Interrupt 大会上的开幕主旨演讲强调了几个核心理念:
-
AI Agent 工程是一门全新的学科——它融合了软件工程、Prompting(提示设计)、产品和机器学习领域的精髓。我们认为,Agent 工程师需要具备多方面能力:编写代码、针对正确的上下文精心设计 Prompt、理解业务流程并将其转化为 Agent,还需要像机器学习工程师一样理解概率分布。精通这四个领域无疑是一项艰巨的任务。为了实现我们让 AI Agent 普及的目标,我们希望赋能每个人成为效率提升 100 倍的 Agent 工程师,无论其起始背景或相对优势如何。
-
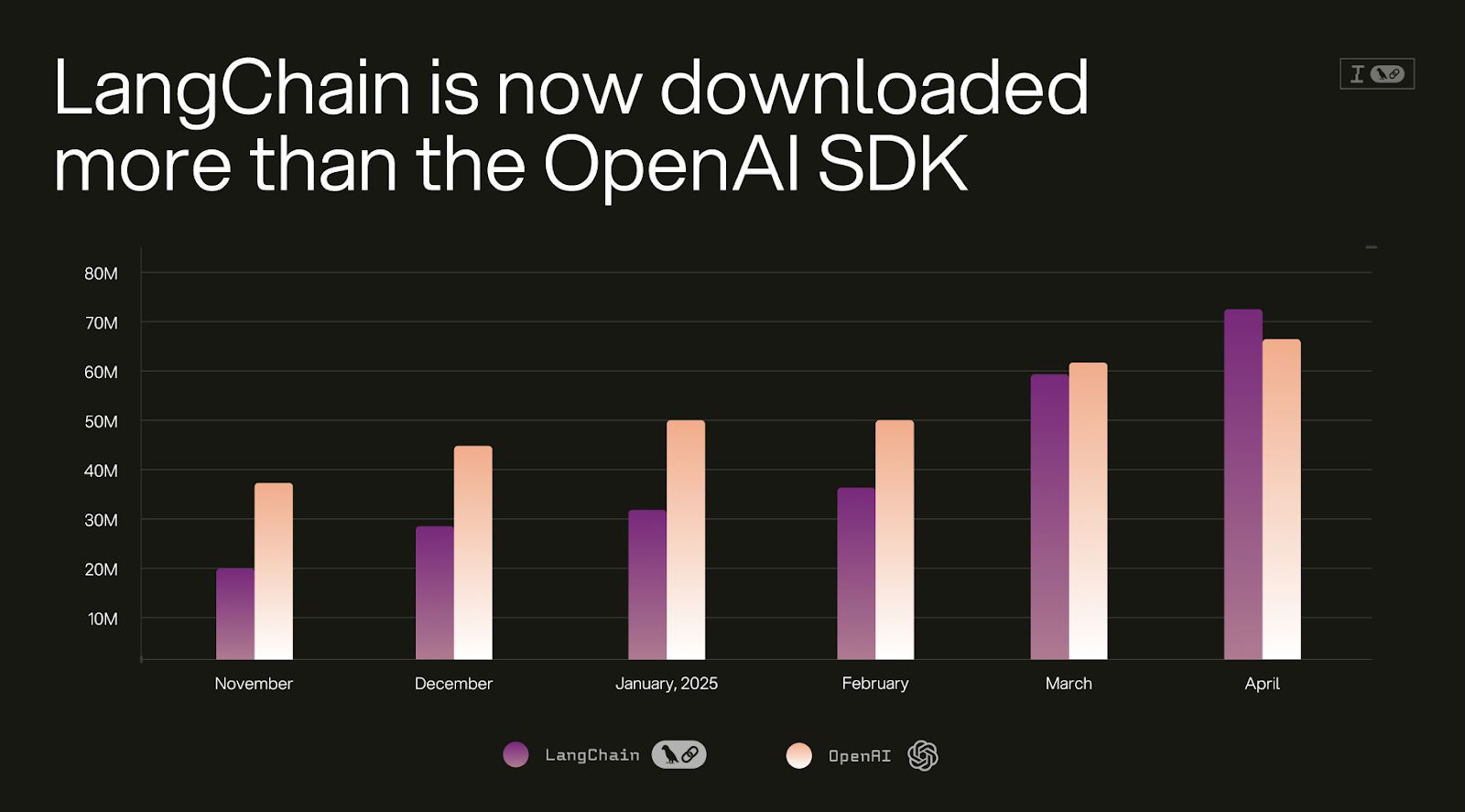
LLM 应用将依赖于多种不同的模型。 当前的 LangChain 软件包主要是为了给各类公司提供模型的选择性。LangChain 已经发布了 3 个稳定版本,我们正致力于深化和扩展与各种模型的集成。开发者们都渴望 LangChain 提供的选择和灵活性。得益于此,仅上个月 LangChain 的下载量就超过了 7000 万次,甚至比 OpenAI SDK的下载量还要高 🤯!
-
LangGraph 是构建可靠 Agent 的关键。 构建 Agent 面临的最大挑战之一是向大型语言模型 (LLM) 提供正确的上下文。LangGraph 作为我们的 Agent 编排框架,赋予了开发者对认知架构的完全掌控权,从而能够精确控制工作流和信息流。正是这种底层的控制能力,使得 LangGraph 在 Agent 编排框架中显得独树一帜。
-
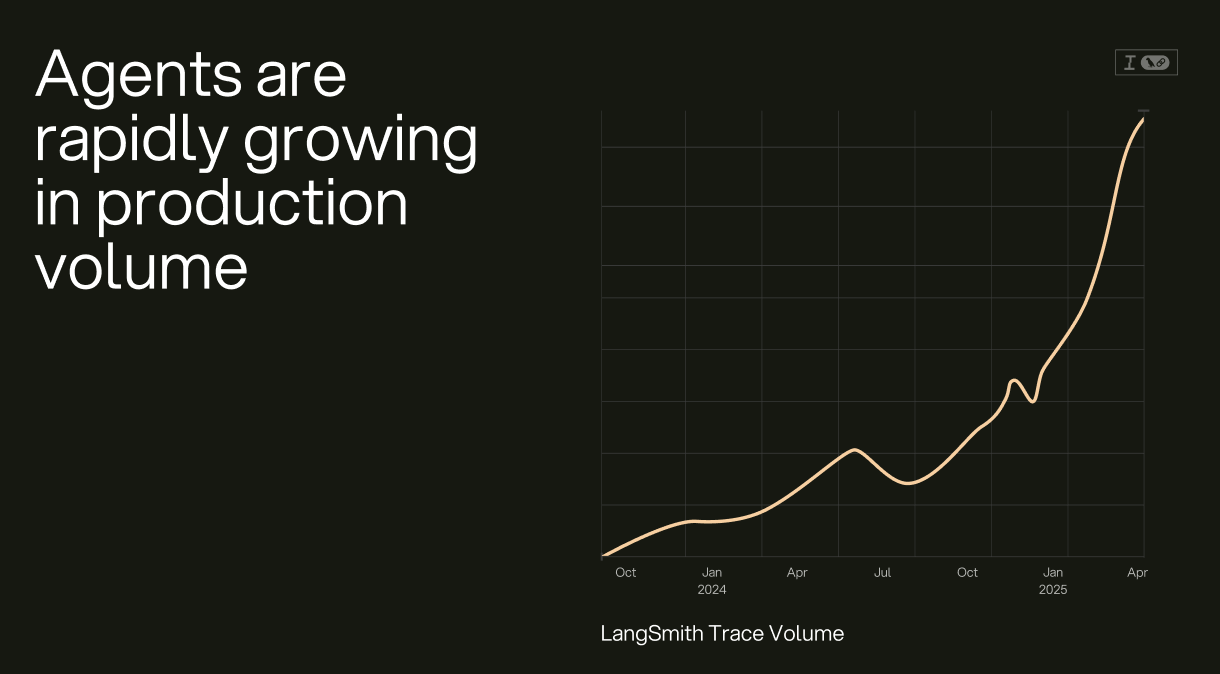
AI 可观测性与传统模式不同。 构建生成式 AI (GenAI) 应用时,需要处理的是密集且非结构化的信息,通常以文本、音频或图像的形式存在。Agent 工程师需要了解应用程序的运行状况,这与传统可观测性工具主要服务于的 SRE(站点可靠性工程师)是完全不同的用户群体,需求也截然不同。如果 LangSmith 的聚合追踪量反映了整个行业的趋势,那就意味着越来越多的 Agent 正在进入生产环境——这使得对一套专门的 AI 可观测性堆栈的需求比以往任何时候都更加迫切。
新产品发布!
LangChain 热衷于不断推出新功能和产品,在本次大会上,我们发布了大量更新!
- LangGraph Platform 正式发布 (GA)。 LangGraph Platform 是一个专门用于部署和管理长期运行、有状态 (stateful) Agent 的平台。现在您可以轻松一键部署您的 Agent,并且支持云部署、混合部署以及完全自托管等多种部署模式。请查阅文档了解更多详情,或观看我们这段 4 分钟的上手视频。

- Open Agent Platform——开源、无代码的 Agent 构建器。 现在,即使非开发者也能轻松构建 Agent 了——通过用户界面 (UI),您可以方便地选择各种工具、定制 Prompt、选择模型、连接数据源,甚至与其他 Agent 进行联动。Open Agent Platform 背后的核心是 LangGraph Platform。立即在此注册试用,或查阅文档按指引自行搭建。
- LangGraph Studio v2 版本发布。 LangGraph Studio 现在可以在本地运行,无需安装桌面应用。它是一款 Agent 的集成开发环境 (IDE),能够帮助您可视化并调试 Agent 的交互流程。在 v2 版本中,我们新增了多项功能:您可以将运行追踪数据导入 Studio 进行详细分析,将示例添加到数据集中用于性能评估,以及直接在用户界面 (UI) 中方便地修改 Prompt。
- LangGraph Pre-Builts 降低 Agent 构建难度。 在构建 Agent 的过程中,我们注意到一些常用的架构模式反复出现,例如群组 (Swarm)、协调者 (Supervisor)、工具调用 Agent 等。为了降低在应用中实现这些架构的门槛,LangGraph Pre-builts 允许您直接利用这些常用架构,显著减少所需的配置代码。了解更多请查看这里。
- LangSmith 可观测性现已支持 Agent 专属指标。 我们新增了对工具调用 (tool calling) 和轨迹追踪 (trajectory tracking) 功能的支持。通过这些指标,您可以清晰地看到 Agent 的常见执行路径,并轻松识别出那些成本较高、执行缓慢或表现不稳定的调用过程。
- 开放评估库 (Open Evals) 与聊天模拟 (Chat Simulations)。 编写评估器通常既繁琐又耗时。虽然某些评估器高度依赖于具体的应用程序或用例,但有些评估器却是通用的——好消息是,这些通用的评估器我们可以为您实现。我们现在提供一个开源评估器目录,可用于代码检查、信息提取、RAG(检索增强生成)、Agent 轨迹测试等多种场景。此外,我们也很高兴地发布了针对多轮对话的聊天模拟和评估功能。在此查看我们的 GitHub 仓库!
- LLM 判官:校准与对齐(私有预览)。 将大型语言模型用作“判官”是一种出色的评估技术,特别适用于那些需要更多主观判断或裁量权的场景。然而,即使是作为判官的 LLM 也可能存在偏差。我们非常高兴地宣布启动私有预览计划,旨在探索一种新方法:通过人类反馈分数来引导 LLM 判官评估器的初始化,并持续进行分数校准和审计,以确保判官的评估表现准确可靠。如果您对此感兴趣,可以在此注册申请访问权限!




