目录
一 全量复制
板书:
1)全量复制的流程
2)全量复制的无硬盘模式
3)关于replid 和 runid
二 部分复制
板书:
1)部分复制的流程
复制积压缓冲区
2)实时复制的流程
板书:
复制流程:
三 主从复制小结
1)板书:
2)主从复制的特点,解决的问题
四 问题补充
板书:
1)关于从节点何时晋升成主节点的问题
2)关于redis 主节点无法重启的问题
一 全量复制
板书:

1)全量复制的流程
全量复制是 Redis 最早⽀持的复制⽅式,也是主从第⼀次建⽴复制时必须经历的阶段。全量复制的运⾏流程如图所⽰。
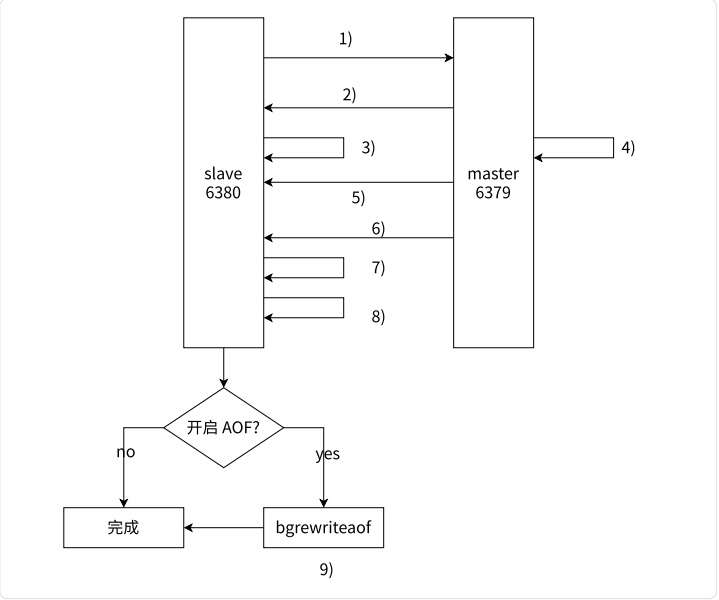
1)从节点发送 psync 命令给主节点进⾏数据同步,由于是第⼀次进⾏复制,从节点没有主节点的运⾏ ID 和复制偏移量,所以发送 psync ? -1。
2)主节点根据命令,解析出要进⾏全量复制,回复 +FULLRESYNC 响应。 3)从节点接收主节点的运⾏信息进⾏保存。 4)主节点执⾏ bgsave 进⾏ RDB ⽂件的持久化。 5)从节点发送 RDB ⽂件给从节点,从节点保存 RDB 数据到本地硬盘。
6)主节点将从⽣成 RDB 到接收完成期间执⾏的写命令,写⼊缓冲区中,等从节点保存完 RDB ⽂件后,主节点再将缓冲区内的数据补发给从节点,补发的数据仍然按照 rdb 的⼆进制格式追加写⼊到收到的 rdb ⽂件中. 保持主从⼀致性。
7)从节点清空⾃⾝原有旧数据。 8)从节点加载 RDB ⽂件得到与主节点⼀致的数据。9)如果从节点加载 RDB 完成之后,并且开启了 AOF 持久化功能,它会进⾏ bgrewrite 操 作,得到最近的 AOF ⽂件。
通过分析全量复制的所有流程,我们会发现全量复制是⼀件⾼成本的操作:主节点 bgsave 的时间, RDB 在⽹络传输的时间,从节点清空旧数据的时间,从节点加载 RDB 的时间等。所以⼀般应该尽可能避免对已经有⼤量数据集的 Redis 进⾏全量复制。
2)全量复制的无硬盘模式
原因:由于全量复制是一个重量级的操作,所以通过一些手段进行成本控制


3)关于replid 和 runid
直接看板书:

二 部分复制
板书:

1)部分复制的流程
部分复制主要是 Redis 针对全量复制的过⾼开销做出的⼀种优化措施,使⽤ psync replicationId offset 命令实现。当从节点正在复制主节点时,如果出现⽹络闪断或者命令丢失等异常情况时,从节点会向主节点要求补发丢失的命令数据,如果主节点的复制积压缓冲区存在数据则直接发送给从节点,这样就可以保持主从节点复制的⼀致性。补发的这部分数据⼀般远远⼩于全量数据,所以开销很⼩。整体流程如图所⽰
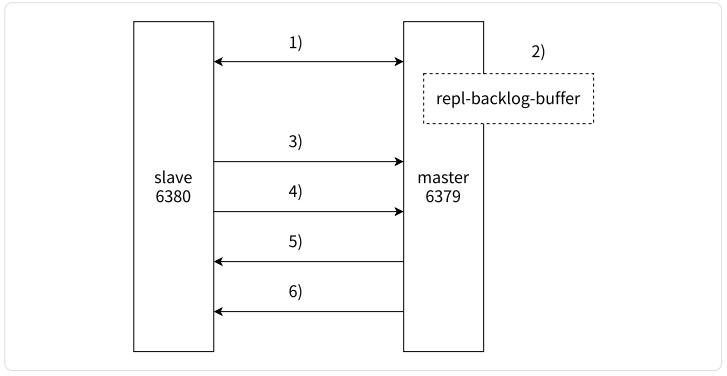
1)当主从节点之间出现⽹络中断时,如果超过 repl-timeout 时间,主节点会认为从节点故障并终端复制连接。
2)主从连接中断期间主节点依然响应命令,但这些复制命令都因⽹络中断⽆法及时发送给从节点,所以暂时将这些命令滞留在复制积压缓冲区中。3)当主从节点⽹络恢复后,从节点再次连上主节点。 4)从节点将之前保存的 replicationId 和 复制偏移量作为 psync 的参数发送给主节点,请求进⾏部分复制。 5)主节点接到 psync 请求后,进⾏必要的验证。随后根据 offset 去复制积压缓冲区查找合适的数据,并响应 +CONTINUE 给从节点。 6)主节点将需要从节点同步的数据发送给从节点,最终完成⼀致性。
例子:如果某个课件传输失败了, 助教可以单独要这个缺失的课件.
复制积压缓冲区
复制积压缓冲区是保存在主节点上的⼀个固定⻓度的队列,默认⼤⼩为 1MB,当主节点有连接的从节点(slave)时被创建,这时主节点(master)响应写命令时,不但会把命令发送给从节点,还会写⼊复制积压缓冲区,如图所⽰。
 由于缓冲区本质上是先进先出的定⻓队列,所以能实现保存最近已复制数据的功能,⽤于部分复制和复制命令丢失的数据补救。复制缓冲区相关统计信息可以通过主节点的 info replication 中:
由于缓冲区本质上是先进先出的定⻓队列,所以能实现保存最近已复制数据的功能,⽤于部分复制和复制命令丢失的数据补救。复制缓冲区相关统计信息可以通过主节点的 info replication 中:
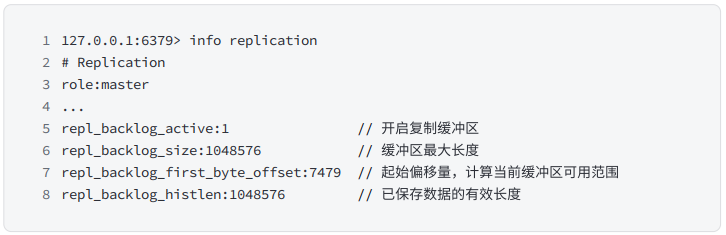
根据统计指标,可算出复制积压缓冲区内的可⽤偏移量范围:[repl_backlog_first_byte_offset, repl_backlog_first_byte_offset + repl_backlog_histlen]。
这个相当于⼀个基于数组实现的环形队列. 上述区间中的值就是 "数组下标" .

2)实时复制的流程
板书:

复制流程:
主从节点在建⽴复制连接后,主节点会把⾃⼰收到的 修改操作 , 通过 tcp ⻓连接的⽅式, 源源不断的传输给从节点. 从节点就会根据这些请求来同时修改⾃⾝的数据. 从⽽保持和主节点数据的⼀致性.
另外, 这样的⻓连接, 需要通过⼼跳包的⽅式来维护连接状态. (这⾥的⼼跳是指应⽤层⾃⼰实现的⼼跳,⽽不是 TCP ⾃带的⼼跳).1)主从节点彼此都有⼼跳检测机制,各⾃模拟成对⽅的客⼾端进⾏通信。
2)主节点默认每隔 10 秒对从节点发送 ping 命令,判断从节点的存活性和连接状态。
3)从节点默认每隔 1 秒向主节点发送 replconf ack {offset} 命令,给主节点上报⾃⾝当前的复制偏移量。
如果主节点发现从节点通信延迟超过 repl-timeout 配置的值(默认 60 秒),则判定从节点下线,断开复制客⼾端连接。从节点恢复连接后,⼼跳机制继续进⾏。
三 主从复制小结
1)板书:

2)主从复制的特点,解决的问题
主从复制解决的问题:
单点问题
1. 单个 redis 节点, 可⽤性不⾼.2. 单个 redis 节点, 性能有限.
主从复制的特点:
2. 主节点⽤来写, 从节点⽤来读. 这样做可以降低主节点的访问压⼒. 3. 复制⽀持多种拓扑结构,可以在适当的场景选择合适的拓扑结构。
1. Redis 通过复制功能实现主节点的多个副本。4. 复制分为全量复制, 部分复制和实时复制。
5. 主从节点之间通过⼼跳机制保证主从节点通信正常和数据⼀致性。
主从复制配置的过程:
1. 主节点配置不需要改动.2. 从节点在配置⽂件中加⼊ slaveof 主节点ip 主节点端⼝ 的形式即可.
主从复制的缺点:
1. 从机多了, 复制数据的延时⾮常明显.2. 主机挂了, 从机不会升级成主机. 只能通过⼈⼯⼲预的⽅式恢复.
四 问题补充
板书:
1)关于从节点何时晋升成主节点的问题
看板书
2)关于redis 主节点无法重启的问题
看板书


)



