1.URL
(1)资源访问
我们所有的上网行为,都可理解为把远端的数据拿到本地,或者把我的数据给别人。本质上这就是通过网卡的IO行为,就是不同主机上的进程间通信。因此,访问图片、视频、音频、文本等资源,看直播,买东西等本质都是IO,而URL(IP + Port)帮助我们确认要IO的资源的对象在哪一台服务器上。
除了上网以外,URL还可以用于本地资源的访问,组成与访问网页的URL组成均一致。URL格式是有规定的,可以实现不同方式的资源定位,如prodrafts://note/?uuid=A81F2C83-4989-4563-A27B-961059F6D0BE
(2)URL定位的唯一性
URL就是统一资源定位符。如网址(域名 + 路径),news.qq.com是一个域名,域名可被解析为目标的IP地址,定位主机。域名后面跟有目标文件的相对路径信息,如news.qq.com/a/b.html就是要访问目标主机上Web根目录下的a目录下的b.html文件。因此,公网IP定位主机(IP具有唯一性) + 该主机上的资源路径定位(路径具有唯一性),就实现了网络层面资源的唯一定位,这和系统文件定位一模一样。同样地,请求的资源本质就是文件,我们直接照搬Linux下的文件结构即可理解。
这里需要强调的是URL中/不是指的根目录,而是指的web根目录。在搭建HTTP服务器时,用户可以选择将/home/SGlow/Web_root这个文件夹设置为Web根目录,当后续访问/a/b.html时,实际在服务器定位的资源位置是/home/SGlow/Web_root/a/b.html,服务器会自动拼接Web根目录的路径。
(3)端口号
在一个URL中,有没有体现端口号?有的,如访问1.12.229.104:8080/a.b.html就是访问其8080端口号。
但成熟的应用层协议往往和端口号是强关联的,只要知道协议名,那么其端口号就是定死的,一般是1024以内的数字。因此http://www.baidu.com中没有体现出端口号,其实是因为早就定好了,默认会访问80端口号。就像我们报火警都知道是打119,急救是120,这些规则都已经订好了。
这里有个误区,http://www.baidu.com默认是访问80端口号,那么http://www.baidu.com:8080什么意思呢?是先访问80端口号,再通过这个端口再访问8080吗?注意只要指定了端口号,默认访问的端口号就失效了。协议指明是http,虽然默认是访问80,但若指明了8080后,数据会直接去找8080端口,而不会去访问80端口号了。
(4)登录信息
有人肯定很好奇,别人问我们邮箱时我们都会说74xxxxx43@qq.com,这是什么意思呢?其实后面的qq.com我们已经知道是域名了,它可以转为IP地址,而@前面的就是登录信息,这也是URL的一部分。登录信息组成为:用户名:密码,在ssh中我们就可以添加登录信息。
不过这种操作也确实有风险,密码直接明文暴露会直接泄露我们的隐私,在一般情况下就算写也只是写写用户名。在访问网站中,登录信息可以直接被省略,并且多数浏览器不会让我们直接见到user:pass@,但不意味着它没有,我们是可以主动加的。
(5)协议
" 协议:// " 也是URL的一部分,我们浏览器访问网站时使用的是http或https,因此前缀都是https://www.baidu.com,就算有的时候我们没输前面的协议,实际浏览器会自动补上。此外还有其它协议,如file、ftp等,不同协议对应不同访问资源的方式(安全策略、如何解析等),默认端口号也不同。
(6)参数
http://user:pass@www.baidu.com:8080/a/b.html还差一个部分,即参数。在访问路径的最后用?做分隔符,?右边表示要传的参数,如?user_id=123456&name=xiaoming,其中&是不同参数之间的分隔符。在我们搜索的时候,搜索的内容就会出现在这个参数里面。
有一个情况需要处理,如果我想要传的参数就是一个&、?或者=之类的特殊字符,怎么办呢?对于这类会引起解析歧义的特殊字符,通常会被编码,转为如%3A、%2F等字符号。这个过程叫做URL编码。接收端收到之后会复原解析,叫URL解码。URL编码的转换格式是%XY,具体转换可以借助工具实现。
至此,URL的所有组成都已讲解完毕,后面的HTTP会详细用到。
完整URL示例:http://SGlow:123456@www.baidu.com:8888/a/b/c.html?id=2&name=SGlow
(7)URN和URI
我们可以认为URI = URN + URL,URL可以唯一定位资源,最主要的是通过URL可以找到该资源;而URN就只有定位唯一资源的特点,它并不提供找到这个资源的方法,如urn:home:user可以定位一个user,但它没有寻找该用户的路径等。URN的书写也有相应的规定,我们了解即可,区分它和URL即可。
URI就是统一的说法,既可以指URL也可指URN,所以有的时候会说URI,其实也没问题,知道URI是兼容URL的特性的。
2.HTTP
(1)HTTP简介
应用层协议是很多的,且大多都有现成方案了,因此可以满足用户不同的需求,其中最具代表性的就是HTTP协议。HTTP超文本传输协议(无连接、无状态)定义了客户端(如浏览器)和服务器的通信,是客户端和服务器通信的基础。HTTPS主要就是多了一层加密。
HTTP是基于TCP的,具有收发完整性(TCP保证可靠传输,有相应的重传机制等)。什么叫做基于TCP?当客户端和服务器建立连接时采用的就是TCP,相互发数据也都是遵循TCP的规则来的,和普通的TCP通信没什么区别。不同之处在于而客户端和服务器互相通信的数据有相应的格式,这个格式遵循HTTP协议的规定,因此我们说HTTP基于TCP。更简单来说,客户端和服务器本质的通信还是TCP,只不过它们通信的内容互相有约定,HTTP协议指的就是这个约定,它是在TCP的基础上搭建的。
(2)请求报文
请求报文 = 请求行 + 请求报头 + 空行 + 请求正文
①请求行
组成:<请求方法>(空格)<请求的URL>(空格)<HTTP协议版本>\r\n
请求方法简单来说就是IO方法(操作资源),报文发送方一来就向对方指明自己是来获取数据还是发送数据的,其中最常用的就是GET和POST,当然还有一些其它方法,了解即可:

请求的URL就是上述所讲,包含完整的URL信息(路径参数等)。
HTTP协议版本很重要,上面讲过HTTP协议只是在TCP上搭建的一个的约定,因此约定的内容很重要,不然互相听不懂互相说的话。发送自己的HTTP协议版本,接收方才知道怎么读取。回复的时候也要说明自己的协议,这样对方才能看懂。
②请求报头
请求报头包含多行内容,每一行均为key: value固定结构(英文冒号后有一个空格),一行以\r\n为结束,通过请求报头浏览器能够知道应当如何读取、解析和处理请求正文。如Content-Type: application/json; charset=utf-8,接收方就知道请求正文的数据的格式类型是JSON,数据的字符编码是 UTF-8。
当请求报头最后一对key: value结束后,下一行会是空行\r\n。无论有没有请求正文,请求报头 + 空行就是固定搭配,本质上空行就是请求报头和请求正文的分隔行,读到空行就意味着报头读完了。
在请求报头中一般会携带请求正文的长度信息Content-Length,这样浏览器能够快速知道读到空行后应该紧接着读多少字节数据。不带Content-Length的话,浏览器还能通过Transfer-Encoding来判断结尾。就算也没有,当今浏览器一般也能保证读取成功。浏览器实现非常复杂,会处理很多不规范的事情。
③请求正文
正文就是真正要通信的数据了,可以携带用户数据,如用户名、用户密码、头像等个人信息,以及一些请求数据。请求报头中的属性会协助对方解析正文内容的,包括长度、编码、格式等。
在这里,我们也能更好理解应用层协议是怎样达成协议的了,本质上传输的请求报文就只是一个字符串,只不过这个字符串遵循第一行请求行、第二行开始请求报头,请求报头中又约定一些互相都能看懂的信息说明,最后包含正文的规则,这一切的规则都会由相应的http_request结构体描述。
在更下一层,双方主机就是通过TCP通信的,TCP是面向字节流传输的,读取方按照字节流的形式读取的,因此消息的边界难以区分,有可能接收的数据并不全,还在网络中;也有可能一次性读到了两块数据,因此需要序列化和反序列化。报文的每一行结束都有\r\n,所以都是利用每行的结束符\r\n作为标识符按行序列化,合并成一个长字符串,之后也能按行反序列化。
(3)响应报文
当服务端收到请求报文之后,就会根据请求头里的URL访问自己Web根目录下的文件,读取里面的内容,这个内容会被放在响应报文中,回应给请求方,这样请求方就成功得到了自己想要得到的文件。这个回应的报文就是响应报文。响应报文遵循的格式和请求报文略有不一样。通过刚才简单的流程就可理解,返回的响应应该包含读取请求URL文件的状态(成功与否)以及描述状态的文本。
①状态行
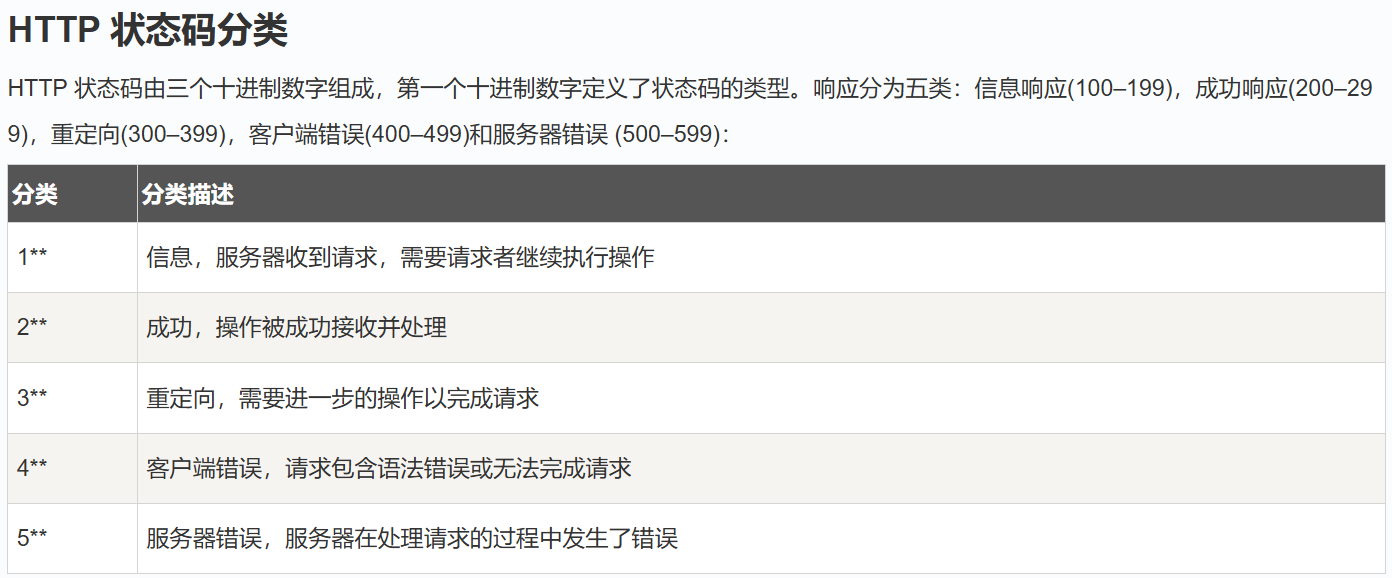
组成:<HTTP协议版本>(空格)<状态码>(空格)<状态码描述>\r\n
HTTP协议是为了保证对方能够看懂自己的报文。服务端会根据路径访问自己的Web根目录,如果没有指明路径或者是/,那就默认去访问/index.html,如果指明了就直接访问。状态码就是服务端访问URL指示文件的状态,不同状态码意味不同结果。我们常见的404就是指的这个,它对应的状态码描述是Not Found。200对应的就是成功读取。状态码描述一般和状态码绑定,但也可以自己设置描述。
以常见的404来说,当我们随便访问一个文件,服务端拿着URL肯定找不到,找不到后就会去读取404.html,同时设置状态码404,返回给请求端。请求端收到响应后就知道访问资源不存在,并且将404.html里面的内容渲染给用户看。
这里有个需要分清楚的概念,用户看到的404画面并不是状态码,而是由服务端主动写入响应正文的404.html经浏览器渲染给用户看的,状态码和用户看到的画面是分离的。因此,可能出现用户看到404,但其实状态码是200的情况。状态码更多是一种规范,但不同人和公司有不同的处理,加之搜索引擎的竞争,所以状态码的使用一直都是没有完全统一的。
②响应报头、响应正文
响应报头也是KV式字符串,用于属性信息传递。响应正文被请求端收到后浏览器会对其进行解析渲染,最后呈现出画面,可以简单理解为浏览器收到的是代码,执行代码并将结果返回给用户看。因此用户会发现自己看到的404界面对于不同网站都不一样,这是因为不同服务端返回的404.html都不一样。实际上客户端和服务端是建立了通信的,只不过用户要的资源服务器没有找到。


)



