every blog every motto: Although the world is full of suffering, it is full also of the overcoming of it
0. 前言
IMAGEBIND 多模态论文梗概
IMAGEBIND是一种夸模态的神经网络,以图片为中心,联合六中模态的网络(图片、文字、音频、深度图、热力图、惯性测量单元)
1. 正文
1.1 梗概
一张照片可以将许多经历联系在一起——一张海滩的照片可以让我们想起海浪的声音、沙子的质地、微风,甚至激发一首诗的灵感。图像的这种“绑定”属性为学习视觉特征提供了许多监督来源,通过将它们与任何与图像相关的感官体验相结合。
之前的工作主要集中在image-text,或videoaudio and captions等少数几种模态。
而IMAGEBIND将每种模态和图片对齐。
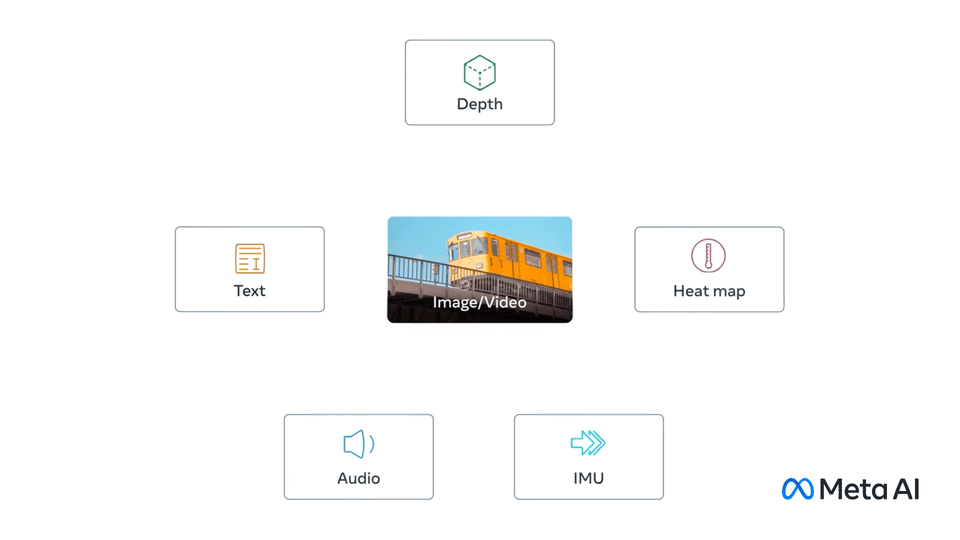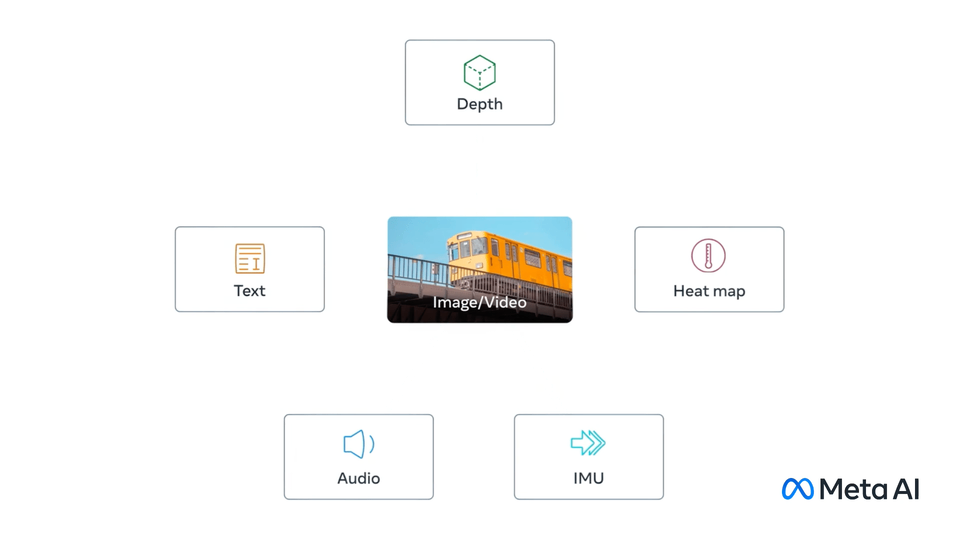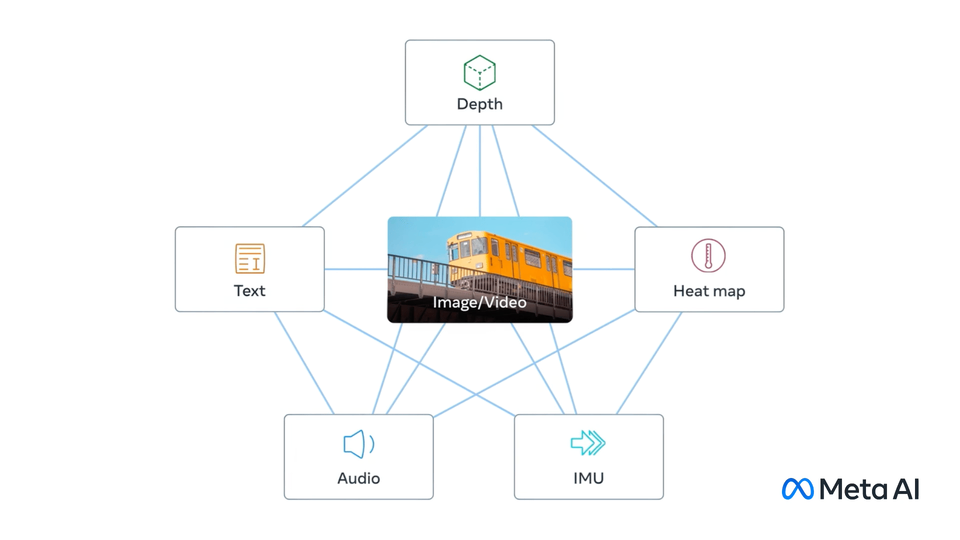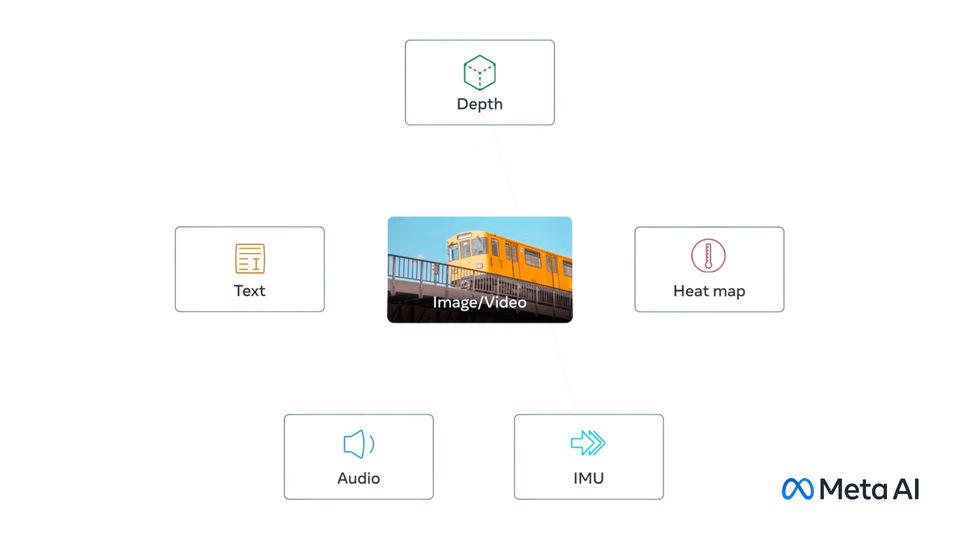
理想情况是同一张图片找到和其对齐的其他模态,而这在实际中是不可获得的。
其他5种模态和图片对齐:

6中模型主要都是VIT类。
1.2 损失函数
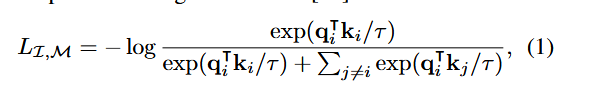
上式为I和M的损失,I表示image,M表示其他模态的数据。
q = f ( I ) , k = g ( M ) q = f(I), k = g(M) q=f(I),k=g(M) ,其中 f , g f,g f,g表示深度网络。
τ \tau τ 温度标量,用于控制softmax的平滑。
j j j 表示不相关的pairs。
在实际中, L o s s = L I , M + L M , I Loss = L_{I,M} + L_{M,I} Loss=LI,M+LM,I
1.3 涌现的对齐能力
在IMAGEBIND中,对于未出现的pairs涌现了对齐能力。如,只训练了(I,M1),和(I,M2)出现了(M1,M2)之前的对齐。
zero-shot: 在CLIP中,使用的image-text训练,使用text-prompts去证明zero-shot能力,
emergent zero-shot(涌现的零样本学习能力): 而在IMAGEBIND中,使用image-text和image-audio训练,IMAGEBIND可以用text prompts对audio进行分类,
1.4 应用
1.4.1 多模态嵌入空间算法
图片+音频–> 新的图片

1.4.2 text-based detector to audio-based
有基于文字的检测,升级到基于音频的检测。
在Detic中,是基于文字对图片中的物体进行检测,替换其中的CLIP为IMAGEBIND,实现audio-based的检测。
说明:
这里有点不确定,是基于一段狗吠的音频对图片中狗进行检测,还是“狗吠”这两个字用语音说出来对图片中的狗进行检测。
不管哪种,感觉都挺有意思的,随着技术的发展,不远的将来一定能实现。

1.5 消融实验
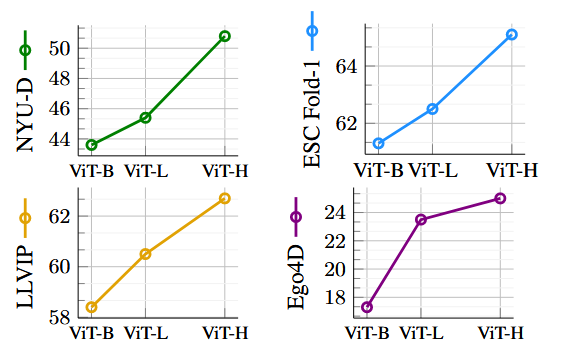
1.5.1 scaling image encoder
由于是以image为中心,所以比较一下image encoder网络对性能影响。
结果表明:更强的视觉网络,效果更好,甚至在非视觉模态中。
1.5.2 损失和网络结构
1). 损失参数 τ \tau τ
在深度图、音频、IMU数据分类中,固定 τ \tau τ 效果更好。
除此以外,在depth,thermal, IMU数据训练中,更高的温度训练更好;audio中低温度更好。
2). 投影头
在两种模态中(SUN-D,ESC),linear 好于MLP。
3). epoch
更大的epoch能够提高”涌现的零样本学习能力“(emergent zero-shot)
4). 数据增强
当对SUN RGB-D数据集的少量(图像,深度)对进行训练时,更强的增强有助于深度分类。然而,对于音频,强烈增强视频使任务过于具有挑战性,导致ESC显着下降34%。
5). Depth specific design choices
空间不对齐,降低性能。
6). Audio specific design choices
时间对齐的样本会带来更好的性能。
7). Capacity of the audio and depth encoders
较小的深度编码器可以提高性能,可能是因为(image, depth)数据集的大小相对较小。相反,我们观察到更大的音频编码器提高了性能,特别是当与高容量图像编码器配对时。



