豆瓣图书分析可视化系统开发文档
一、项目概述
1.1 项目简介
本项目是一个基于Python的豆瓣图书分析可视化与推荐系统,通过爬取豆瓣网站的图书数据,对数据进行分析、可视化和推荐。系统采用Django框架作为后端,结合各种数据分析和机器学习算法,为用户提供图书数据的可视化展示和个性化推荐服务。
1.2 系统架构
系统主要包括以下几个部分:
- 数据采集模块:基于Python爬虫技术,爬取豆瓣网站的图书数据
- 数据存储模块:使用MySQL数据库存储爬取的数据
- 数据分析模块:对图书数据进行统计分析
- 数据可视化模块:使用ECharts等工具将分析结果以图表形式展示
- 推荐系统模块:基于多种推荐算法为用户推荐图书
- Web应用模块:基于Django框架的Web应用,提供用户界面
1.3 技术栈
- 前端:HTML, CSS, JavaScript, ECharts
- 后端:Python, Django
- 数据库:MySQL
- 数据分析:Pandas, NumPy
- 机器学习:Scikit-learn
- 自然语言处理:Jieba
- 可视化:ECharts, Matplotlib, WordCloud
二、数据库设计
2.1 数据库模型设计
系统主要包含以下数据表:
-
BookList(图书表)
- id:主键,自增
- bookId:图书编号
- tag:图书类型
- title:书名
- cover:封面图片链接
- author:作者
- press:出版社
- year:出版年份
- pageNum:页码
- price:价格
- rate:评分
- startList:星级列表
- summary:图书简介
- detailLink:详情链接
- createTime:创建时间
- comment_len:评论数量
- commentList:评论列表
-
User(用户表)
- id:主键,自增
- username:用户名
- password:密码
- creatTime:创建时间
-
UserBookRating(用户图书评分表)
- id:主键,自增
- user_id:外键,关联User表
- book_id:外键,关联BookList表
- rating:评分
- created_at:评分时间
三、系统功能模块
3.1 用户管理模块
- 用户注册:新用户注册账号
- 用户登录:已注册用户登录系统
- 用户信息管理:用户修改个人信息和密码
3.2 数据爬虫模块
系统通过爬虫模块从豆瓣网站爬取图书信息,包括:
- 图书基本信息爬取
- 图书评论信息爬取
- 数据清洗与存储
爬虫使用Python的requests库和lxml库实现,通过解析HTML页面获取数据。
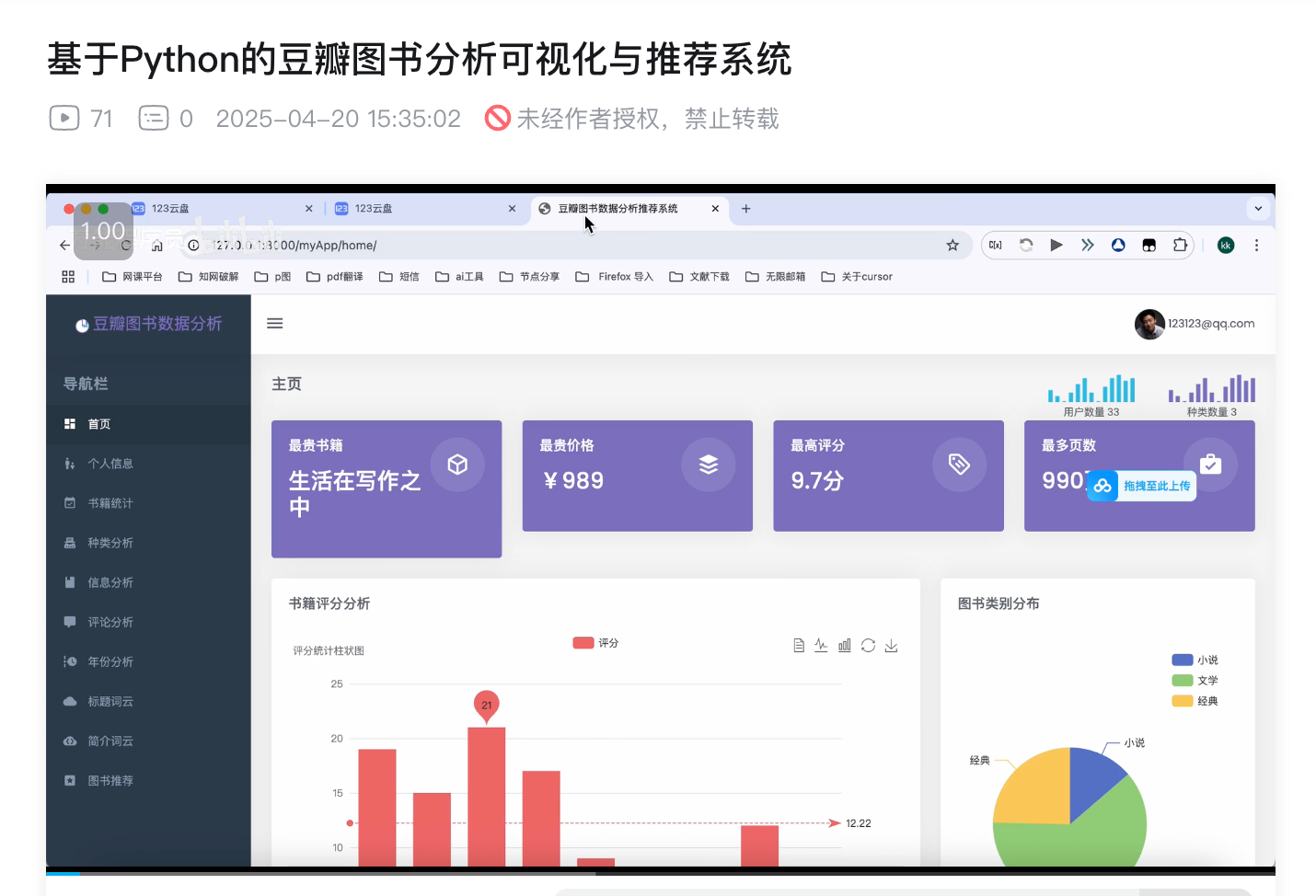
3.3 数据分析与可视化模块
系统提供多种数据分析与可视化功能:
- 图书类型分布分析
- 图书评分分析
- 图书价格分析
- 图书页数分析
- 图书评论量分析
- 图书出版年份分析
- 书名词云分析
- 简介词云分析
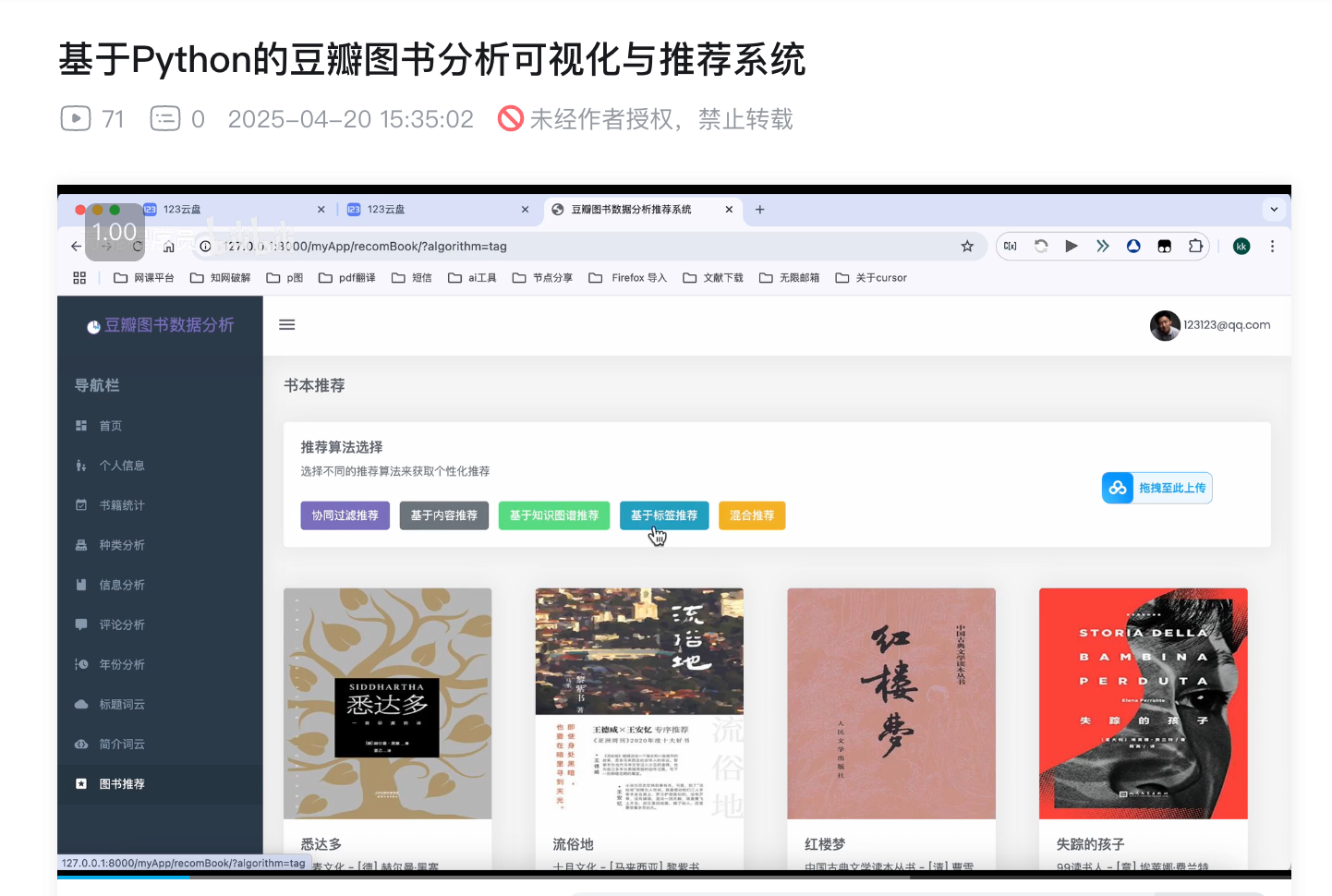
3.4 图书推荐模块
系统提供多种推荐算法,为用户推荐感兴趣的图书。
四、推荐算法详解
4.1 协同过滤算法(Collaborative Filtering)
协同过滤算法基于矩阵分解(Matrix Factorization, MF)实现,通过分析用户的历史评分数据,预测用户对未评分图书的可能评分。
class MF:def __init__(self, R, k=2, alpha=0.1, beta=0.8, iterations=10):"""初始化矩阵分解模型R: 用户-物品评分矩阵k: 隐藏因子的数量(即矩阵分解后的维度)alpha: 学习率beta: 正则化参数iterations: 训练的迭代次数"""self.R = R # 用户-物品评分矩阵self.k = k # 隐藏因子的数量self.alpha = alpha # 学习率self.beta = beta # 正则化参数self.iterations = iterations # 训练迭代次数self.num_users, self.num_items = R.shape # 获取用户数和物品数# 随机初始化用户矩阵P和物品矩阵Qself.P = np.random.rand(self.num_users, self.k)self.Q = np.random.rand(self.num_items, self.k)# 用户和物品的偏置项self.b_u = np.zeros(self.num_users)self.b_i = np.zeros(self.num_items)# 全局偏置项(全体用户对全体物品的平均评分)self.b = np.mean(R[R > 0])
矩阵分解的核心思想是将用户-物品评分矩阵分解为两个低维矩阵的乘积:用户矩阵P和物品矩阵Q。通过随机梯度下降(SGD)算法优化这两个矩阵,使得预测评分与实际评分之间的误差最小化。
训练过程如下:
def train(self):"""训练模型使用随机梯度下降算法(SGD)来优化用户和物品的特征矩阵"""for _ in range(self.iterations):for i in range(self.num_users):for j in range(self.num_items):if self.R[i][j] > 0: # 仅考虑用户评分过的物品# 计算预测评分与实际评分之间的误差eij = self.R[i][j] - self.full_matrix()[i][j]for f in range(self.k):# 更新用户矩阵P和物品矩阵Q的隐因子self.P[i][f] += self.alpha * (2 * eij * self.Q[j][f] - self.beta * self.P[i][f])self.Q[j][f] += self.alpha * (2 * eij * self.P[i][f] - self.beta * self.Q[j][f])# 更新用户和物品的偏置项self.b_u[i] += self.alpha * (eij - self.beta * self.b_u[i])self.b_i[j] += self.alpha * (eij - self.beta * self.b_i[j])
4.2 基于内容的推荐算法(Content-Based Recommendation)
基于内容的推荐算法通过分析图书的内容特征(如标题、作者、简介和标签等),寻找与用户喜欢的图书在内容上相似的其他图书进行推荐。
该算法主要步骤:
- 特征提取:将图书的各种特征(标题、作者、标签、简介等)组合成内容文本
- 文本向量化:使用TF-IDF(词频-逆文档频率)方法将文本转换为向量
- 相似度计算:使用余弦相似度计算图书之间的内容相似度
- 推荐生成:为用户推荐与其已评分图书内容相似的新图书
class ContentBasedRecommender:def __init__(self):# 获取所有图书self.books = list(BookList.objects.all())# 使用bookId存储映射关系,方便后续查找self.book_id_map = {book.id: book for book in self.books}self.book_ids = [book.id for book in self.books]# 准备图书内容数据self.book_contents = []for book in self.books:# 组合图书的各种特征作为内容,增加标签和作者的权重content = f"{book.title} {book.title} {book.author} {book.author} {book.author} {book.tag} {book.tag} {book.tag} {book.press} {book.summary}"self.book_contents.append(content)# 使用TF-IDF向量化图书内容self.vectorizer = TfidfVectorizer(stop_words='english')try:self.tfidf_matrix = self.vectorizer.fit_transform(self.book_contents)# 计算余弦相似度矩阵self.cosine_sim = cosine_similarity(self.tfidf_matrix, self.tfidf_matrix)self.initialized = Trueexcept Exception as e:print(f"TF-IDF计算错误: {e}")# 如果向量化失败,创建一个简单的相似度矩阵self.cosine_sim = np.eye(len(self.books)) # 单位矩阵self.initialized = False
4.3 基于知识图谱的推荐算法(Knowledge Graph Based Recommendation)
基于知识图谱的推荐算法通过构建图书的知识图谱(作者、类型、出版社等关系),基于用户的历史评分偏好,推荐相关联的图书。
具体实现:
class KnowledgeGraphRecommender:def __init__(self):# 获取所有图书self.books = list(BookList.objects.all())self.book_ids = [book.id for book in self.books]# 构建作者、类型、出版社与图书的关系图谱self.author_books = {} # 作者到图书的映射self.tag_books = {} # 类型到图书的映射self.press_books = {} # 出版社到图书的映射self.year_books = {} # 出版年份到图书的映射for book in self.books:# 添加作者关系if book.author not in self.author_books:self.author_books[book.author] = []self.author_books[book.author].append(book.id)# 添加类型关系if book.tag not in self.tag_books:self.tag_books[book.tag] = []self.tag_books[book.tag].append(book.id)# 添加出版社关系if book.press not in self.press_books:self.press_books[book.press] = []self.press_books[book.press].append(book.id)# 添加出版年份关系if book.year not in self.year_books:self.year_books[book.year] = []self.year_books[book.year].append(book.id)
在推荐过程中,算法会根据用户对不同属性(作者、类型、出版社、年份)的偏好程度,为每个可能的推荐图书计算一个加权得分:
# 基于作者推荐
for author, score in author_scores.items():if author in self.author_books:for book_id in self.author_books[author]:if book_id not in rated_books and book_id in self.valid_ids:if book_id not in book_scores:book_scores[book_id] = 0book_scores[book_id] += score * 0.35 # 作者权重0.35# 基于类型推荐
for tag, score in tag_scores.items():if tag in self.tag_books:for book_id in self.tag_books[tag]:if book_id not in rated_books and book_id in self.valid_ids:if book_id not in book_scores:book_scores[book_id] = 0book_scores[book_id] += score * 0.35 # 类型权重0.35
4.4 基于标签的推荐算法(Tag-Based Recommendation)
基于标签的推荐算法专注于用户对不同标签(图书类别)的偏好,通过分析用户对不同标签图书的评分情况,为用户推荐其喜爱标签中的高评分图书。
class TagBasedRecommender:def __init__(self):# 获取所有标签并构建标签到图书的映射self.tags = {}for book in self.books:if book.tag not in self.tags:self.tags[book.tag] = []self.tags[book.tag].append(book.id)# 计算每个标签下的图书平均评分self.tag_avg_ratings = {}for tag, book_ids in self.tags.items():total_rating = 0count = 0for book_id in book_ids:book = self.book_dict.get(book_id)if book and book.rate:try:rating = float(book.rate)total_rating += ratingcount += 1except (ValueError, TypeError):passif count > 0:self.tag_avg_ratings[tag] = total_rating / countelse:self.tag_avg_ratings[tag] = 0
在推荐过程中,算法首先统计用户对各标签的评分情况,然后按标签偏好顺序推荐未评分过的高评分图书:
# 统计用户对各标签的评分
tag_ratings = {}
for rating in user_ratings:book = rating.bookif book.tag not in tag_ratings:tag_ratings[book.tag] = {'sum': 0, 'count': 0}tag_ratings[book.tag]['sum'] += rating.ratingtag_ratings[book.tag]['count'] += 1# 计算各标签的平均评分
for tag in tag_ratings:tag_ratings[tag]['avg'] = tag_ratings[tag]['sum'] / tag_ratings[tag]['count']# 根据标签评分排序
sorted_tags = sorted(tag_ratings.items(), key=lambda x: x[1]['avg'], reverse=True)
4.5 混合推荐算法(Hybrid Recommendation)
混合推荐算法综合了以上四种算法的结果,取各个算法的优势,提高推荐的准确性和多样性。
def modelFn(user_id, algorithm='hybrid'):# 混合推荐算法:综合多种算法的结果if algorithm == 'hybrid':recommendations = []# 收集各算法的推荐结果(每个算法3本)algos = ['cf', 'content', 'kg', 'tag']for algo in algos:try:algo_recs = modelFn(user_id, algo)[:3] # 每个算法取前3本recommendations.extend(algo_recs)except Exception as e:print(f"算法 {algo} 出错: {e}")# 去重unique_recommendations = []for book_id in recommendations:if book_id not in unique_recommendations:unique_recommendations.append(book_id)# 如果推荐数量不足,用协同过滤补充if len(unique_recommendations) < 12:cf_recs = modelFn(user_id, 'cf')for book_id in cf_recs:if book_id not in unique_recommendations:unique_recommendations.append(book_id)if len(unique_recommendations) >= 12:breakreturn unique_recommendations[:12]
五、数据可视化实现
5.1 ECharts可视化
系统使用ECharts实现了多种图表可视化:
- 饼图:展示图书类型分布
- 柱状图:展示图书价格、页数分布
- 折线图:展示图书评分、出版年份趋势
- 散点图:展示图书评论数量分布
5.2 词云可视化
系统使用Python的WordCloud库实现了书名和简介的词云可视化:
def get_img(field, targetImageSrc, resImageSrc):# 从数据库中获取文本数据conn = connect(host="localhost", user="root", passwd="chuankangkk", database="design_douban_book", charset="utf8mb4")cursor = conn.cursor()sql = f"SELECT {field} FROM booklist"cursor.execute(sql)data = cursor.fetchall()# 组合文本数据text = ''for i in data:if i[0] != '':tarArr = ifor j in tarArr:text += j# 分词处理data_cut = jieba.cut(text, cut_all=False)string = ' '.join(data_cut)# 加载掩码图片img = Image.open(targetImageSrc)ima_arr = np.array(img)# 创建词云wc = WordCloud(background_color='#fff', mask=ima_arr, font_path=get_available_font())wc.generate_from_text(string)# 保存词云图片plt.figure(1)plt.imshow(wc, interpolation='bilinear')plt.axis('off')plt.savefig(resImageSrc, dpi=800, bbox_inches='tight', pad_inches=-0.1)
六、系统部署
6.1 环境要求
- Python 3.6+
- MySQL 5.7+
- Django 3.1.14
- 其他依赖项:见requirements.txt
6.2 部署步骤
- 克隆项目代码
- 安装依赖:
pip install -r requirements.txt - 配置数据库:修改settings.py中的数据库配置
- 导入数据库结构:
mysql -u root -p < design_douban_book.sql - 运行爬虫程序:
python spider/spiderMain.py - 生成词云:
python wordCloud.py - 启动Django服务器:
python manage.py runserver
七、未来展望
7.1 功能优化
- 改进推荐算法的精度和效率
- 增强用户交互体验
- 完善数据分析功能
7.2 扩展方向
- 加入深度学习推荐模型
- 增加社交功能,用户可以分享阅读体验
- 开发移动端应用
- 整合其他图书资源平台数据
八、总结
本项目通过爬取豆瓣图书数据,结合多种推荐算法和数据可视化技术,构建了一个完整的图书分析与推荐系统。系统不仅为用户提供了图书的多维度分析展示,还能根据用户的偏好进行个性化图书推荐,具有较好的实用价值和扩展性。
作者:Vx:1837620622
邮箱:2040168455@qq.com
视频:https://www.bilibili.com/video/BV1kgLczbEHf



