场景:
群里有小伙伴咨询kettle从Elasticsearch中抽取数据,群里老师们纷纷响应,vip小伙伴是不是有中受宠若惊的感觉。
今天我们使用kettle通过es的原生rest接口来进行操作es,开整。
前提:本篇文章基于elasticsearch:7.17.9版本进行测试,在 Elasticsearch 7.x 及以上版本中,_doc 不能自定义。在 Elasticsearch 6.x 及之前的版本中,一个索引里可以有多个文档类型(类似于 MySQL 中一个数据库里有多个表),文档类型可以自定义。
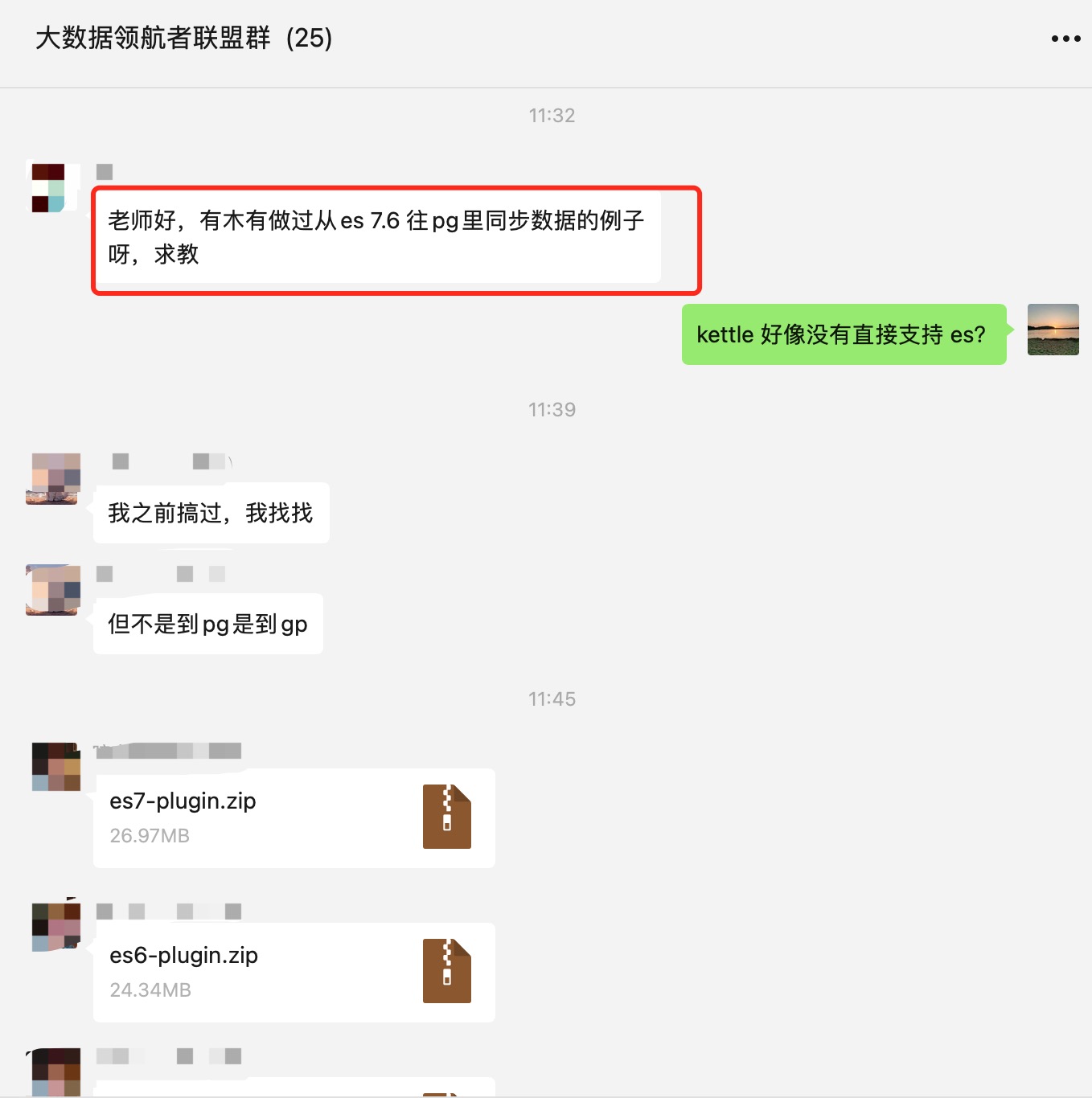
1、创建es索引
创建一个索引,名字为xiaojingang,如下所示
PUT http://127.0.0.1:9200/xiaojingang
{"settings": {"number_of_shards": 1,"number_of_replicas": 0}
}
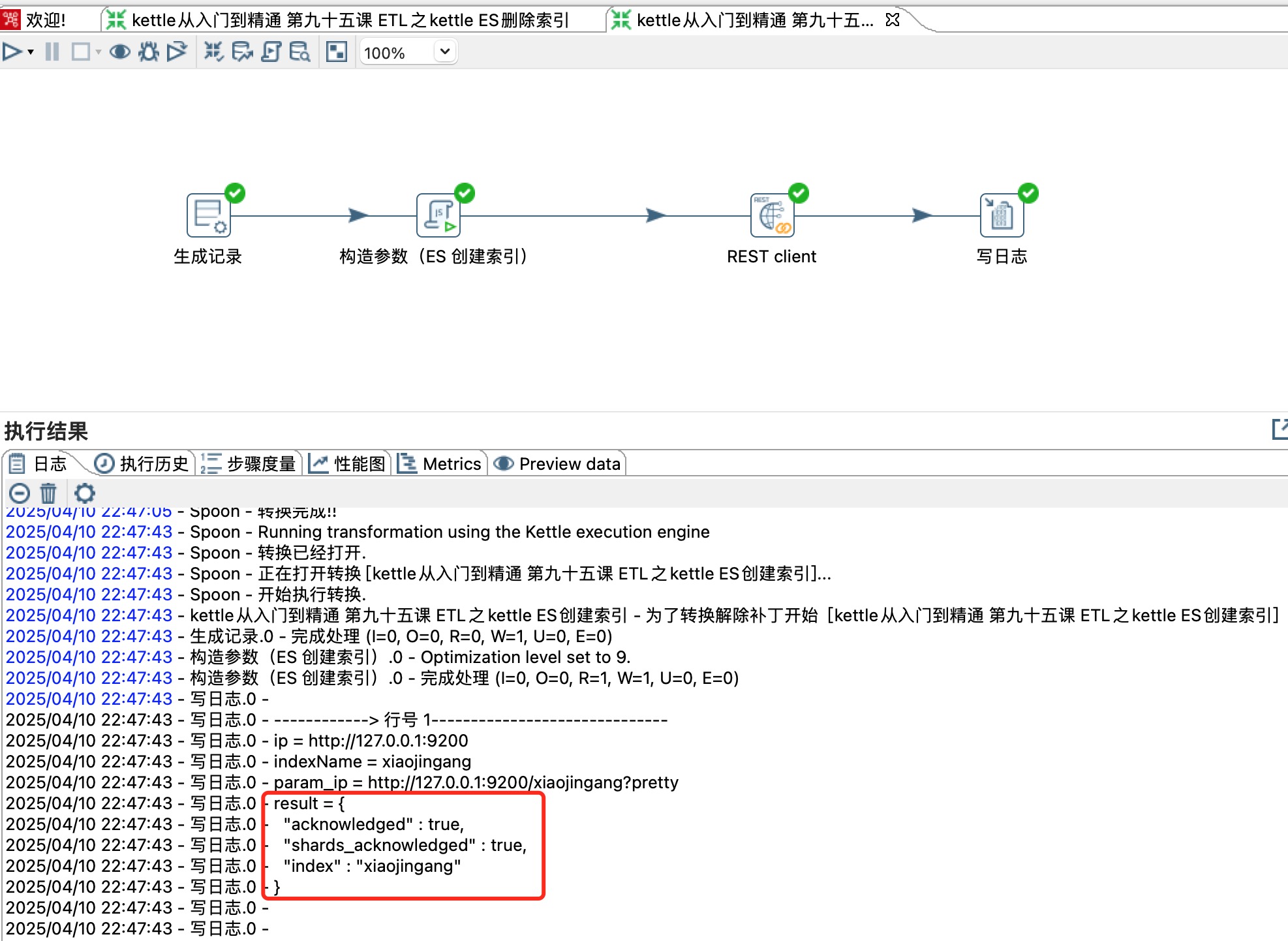
2、删除es索引
删除es索引xiaojingang,如下图所示:
DELETE http://127.0.0.1:9200/xiaojingang
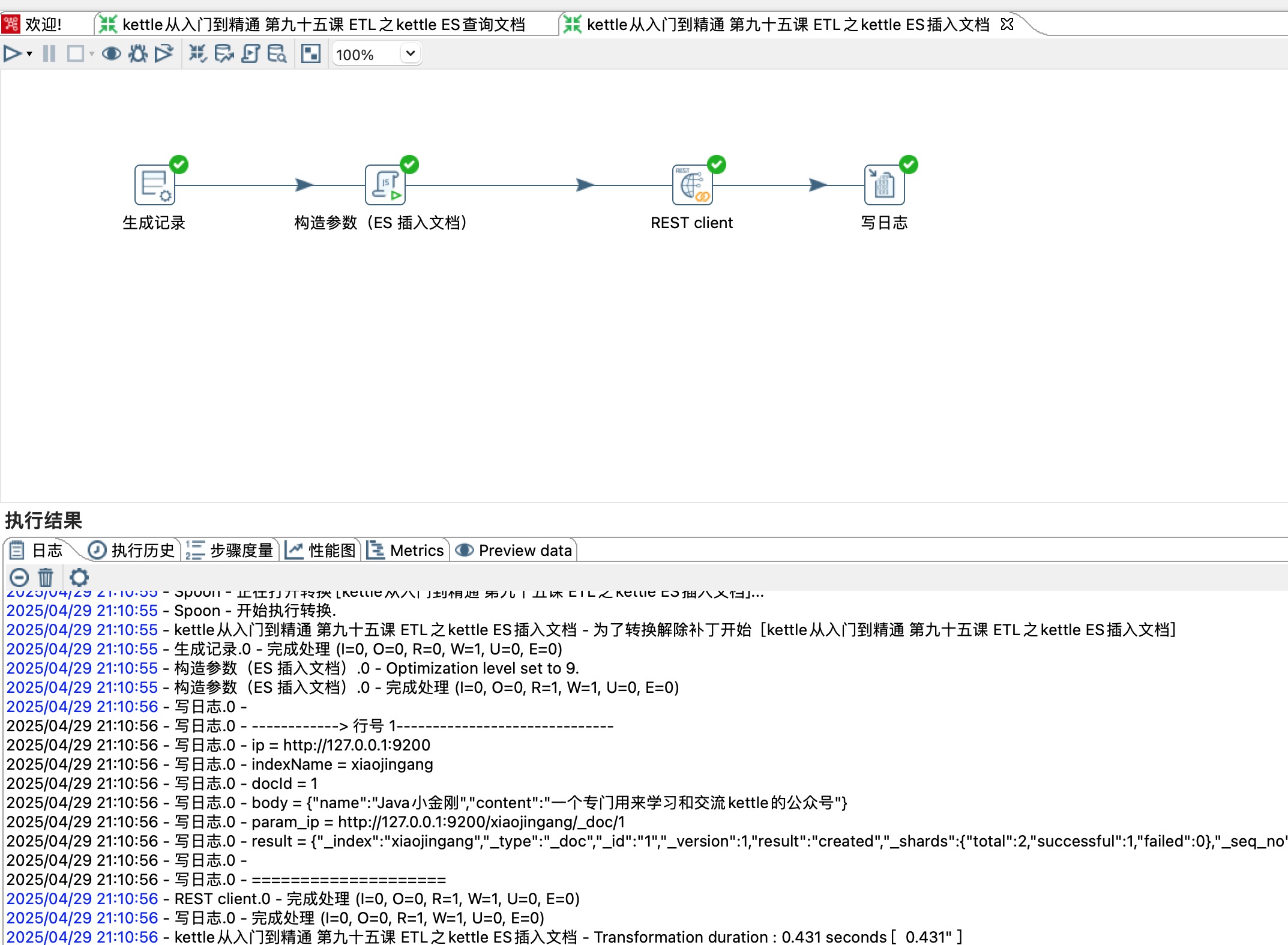
3、写入文档
POST http://localhost:9200/xiaojingang/_doc/1
{"name": "Java小金刚","content": "一个专门用来学习和交流kettle的公众号"
}
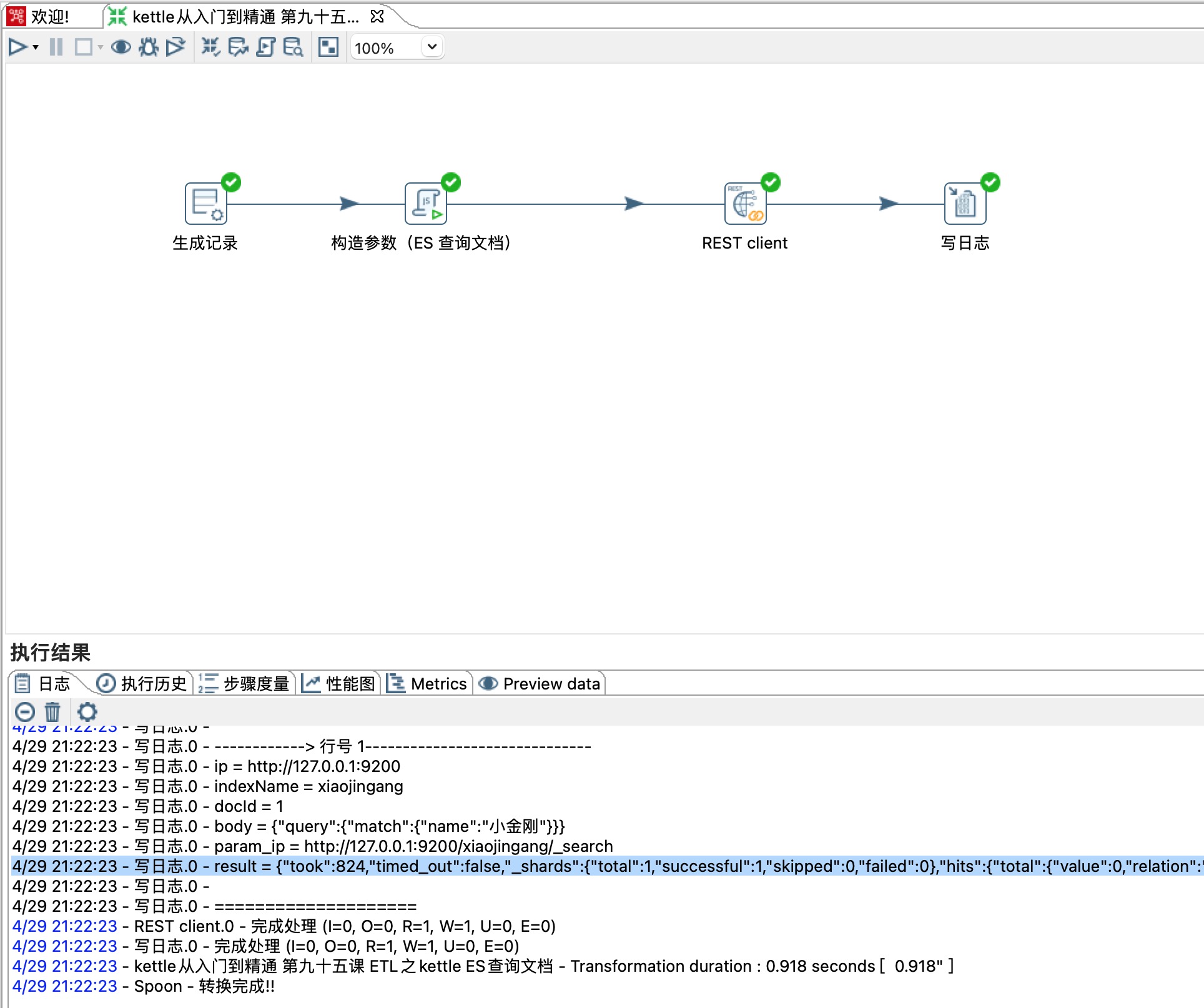
4、查询文档
GET http://localhost:9200/xiaojingang/_search
{"query": {"match": {"name": "小金刚"}}
}
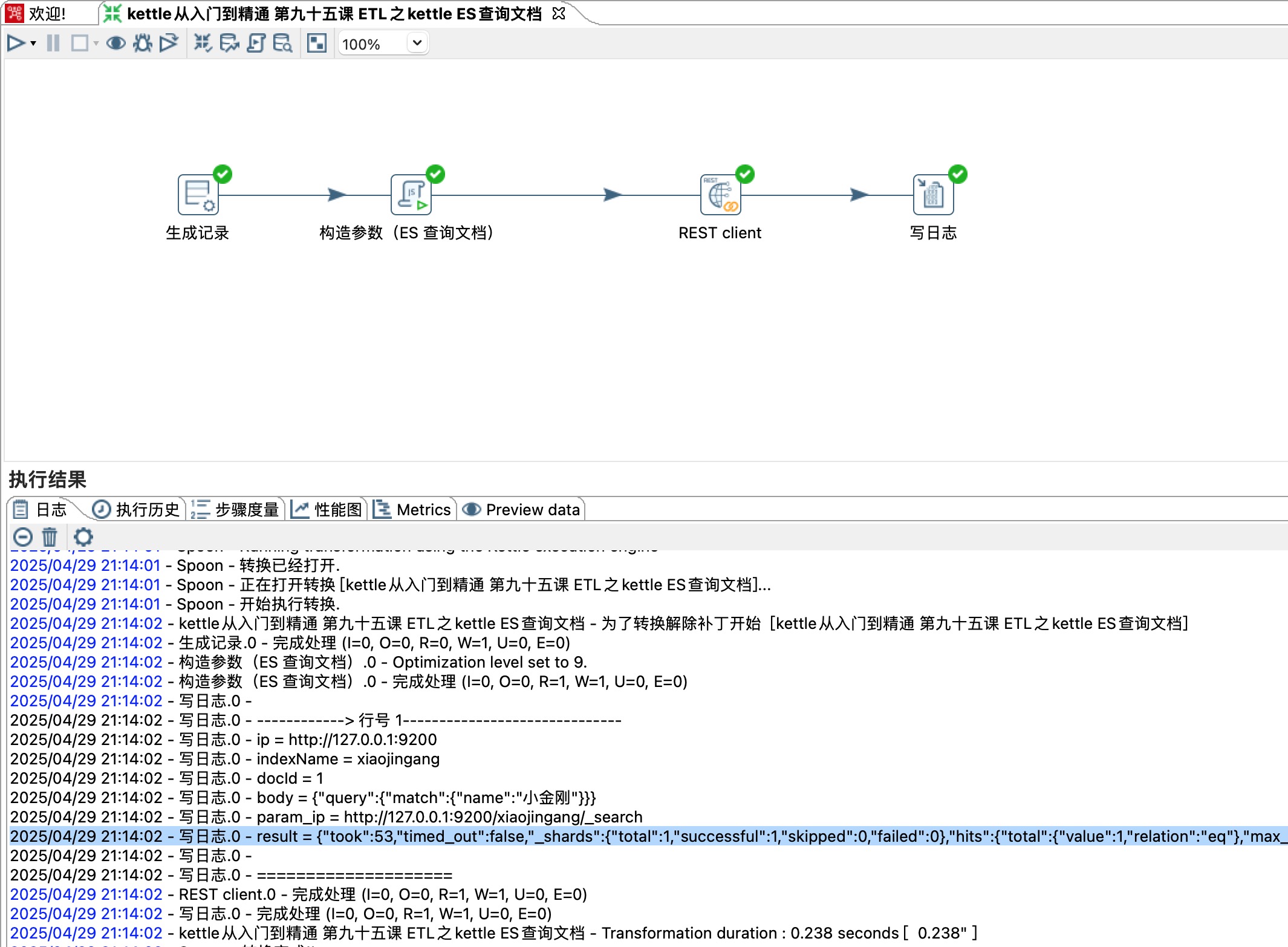
5、更新文档
POST http://localhost:9200/xiaojingang/_update/1
{"doc": {"name": "Java大金刚","content": "这是更新后的示例文章内容。"}
}
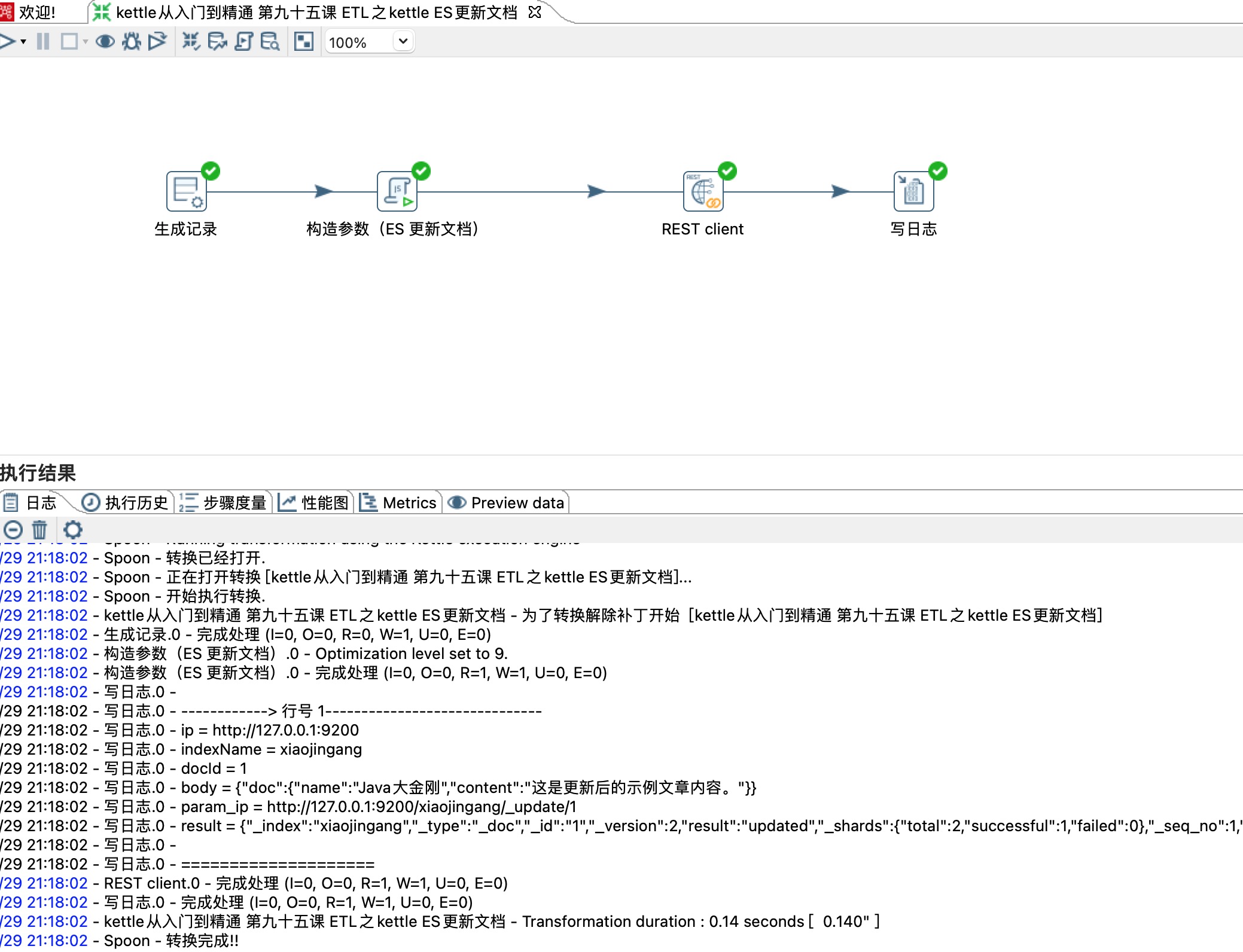
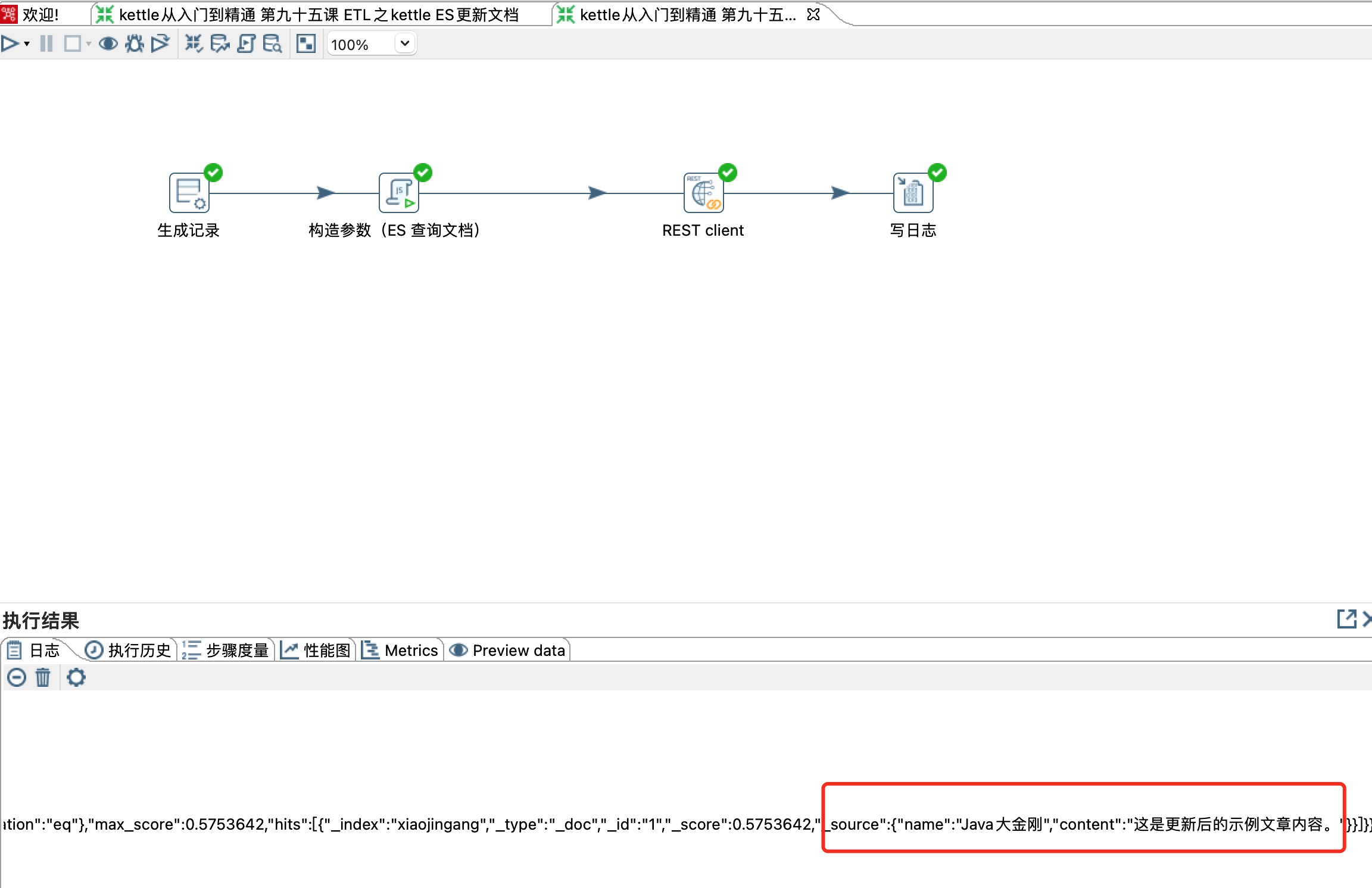
重新读取
6、删除文档
DELETE http://localhost:9200/xiaojingang/_doc/1
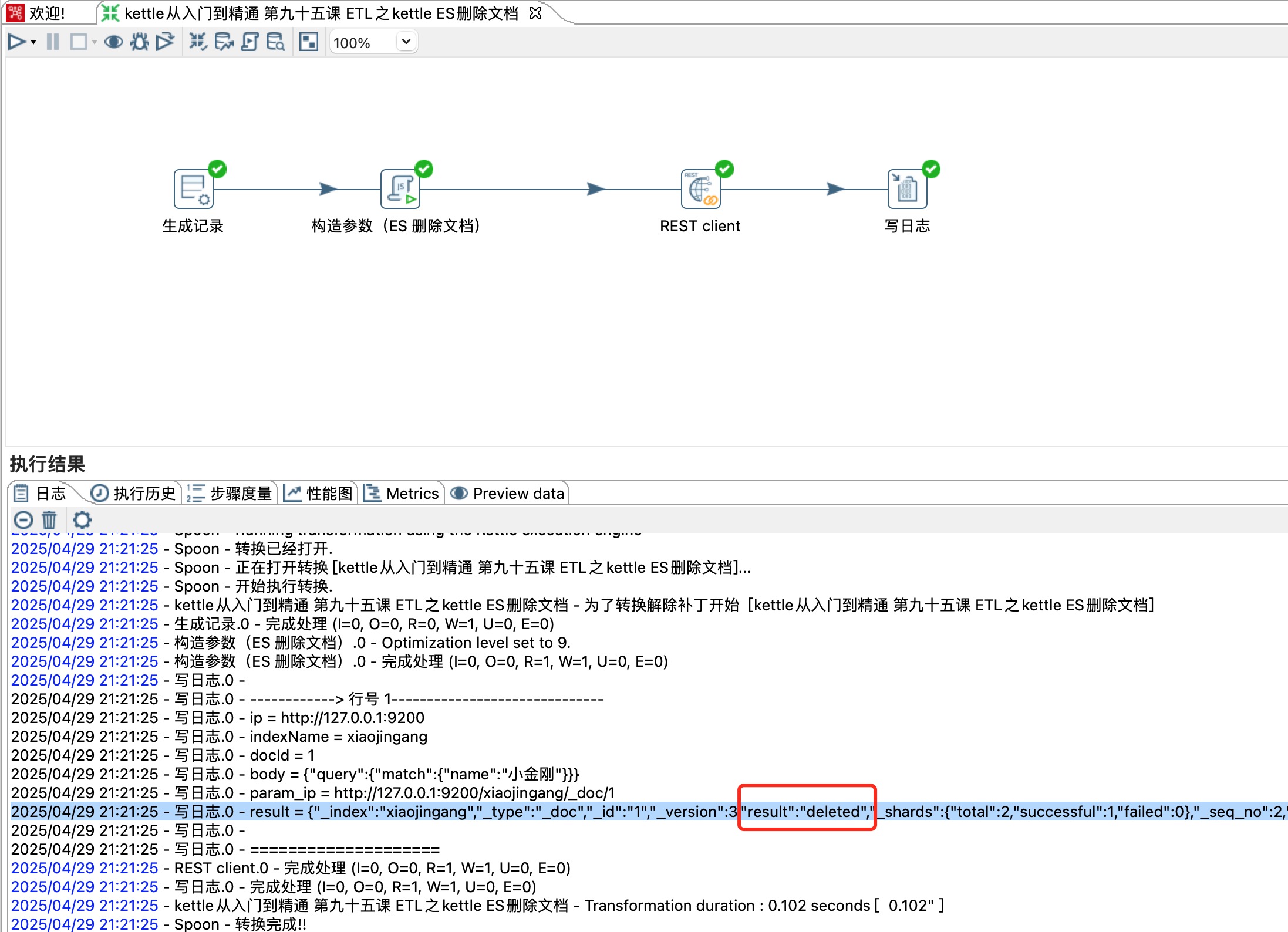
重新读取
7、分页读取,使用 Scroll API
Scroll API 适用于需要处理大量数据的场景,它通过创建一个快照来避免每次请求都进行排序和合并操作。
请求示例:
# 初始化 scroll 请求
curl -X GET "localhost:9200/my_index/_search?scroll=1m" -H 'Content-Type: application/json' -d'
{"query": {"match_all": {}},"size": 10
}
'
上述请求中,scroll=1m 表示这个快照的有效期为 1 分钟,size=10 表示每次返回 10 个文档。响应中会包含一个 _scroll_id,用于后续的滚动请求。
# 后续的滚动请求
curl -X GET "localhost:9200/_search/scroll" -H 'Content-Type: application/json' -d'
{"scroll": "1m","scroll_id": "your_scroll_id"
}
'


)



