欠拟合(Underfitting)全面解析:原因、表现与解决方案
本文详细解读深度学习与机器学习中的欠拟合现象,结合直观图示,探讨其成因与实用解决方法,助力你构建更优秀的模型!
一、什么是欠拟合?
在机器学习中,当模型无法充分捕捉训练数据中的潜在模式时,就会发生欠拟合(Underfitting)现象。
简单来说,欠拟合的模型在训练集上的表现就已经很差,自然无法在测试集上有好的效果。
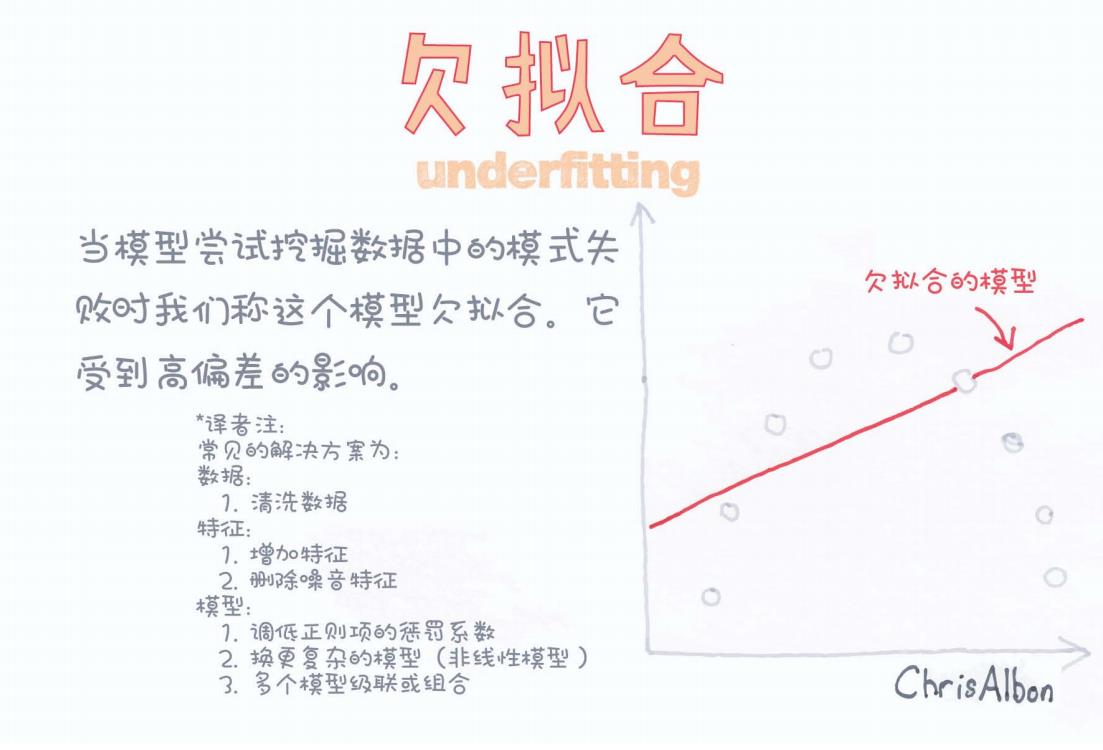
如上图所示,一条红色的直线勉强穿过了稀疏的样本点,但显然未能合理拟合数据的实际分布。这就是典型的欠拟合模型。
关键词:
-
高偏差(High Bias)
-
低复杂度
-
学习不足
二、欠拟合的表现
欠拟合通常表现为:
-
训练误差高,测试误差也高。
-
无论训练多少轮次,训练准确率始终无法提升。
-
预测输出呈现过于简单的模式(例如用线性函数拟合明显非线性的数据)。
图中红线代表的拟合曲线明显偏离了数据的真实分布,说明模型过于简单,无法学习到数据内部的复杂关系。
三、为什么会发生欠拟合?
造成欠拟合的原因可能包括:
-
模型过于简单
-
例如,用线性回归去拟合复杂的曲线数据。
-
-
特征不足或特征处理不当
-
输入特征无法提供足够的信息支撑学习。
-
-
训练不充分
-
训练轮数太少,学习率设置不合理。
-
-
过强的正则化
-
正则化项太强,会抑制模型的拟合能力。
-
-
数据质量问题
-
脏数据、噪声数据或异常值过多影响学习。
-
四、欠拟合的解决方案
在图中,Chris Albon和译者总结了常见的解决欠拟合的方法,具体包括:
1. 数据层面
-
清洗数据
移除异常值、修正错误数据、规范化处理,确保输入数据的质量。
2. 特征层面
-
增加特征数量
引入更多有意义的特征(如多项式特征、交互特征)来丰富模型输入。 -
去除噪声特征
删除无关或者误导性的特征,提升有效特征占比。
3. 模型层面
-
降低正则化强度
调小L1、L2正则项的系数,让模型有更大的自由度拟合数据。 -
采用更复杂的模型
选择更高阶、非线性的模型,比如决策树、神经网络等。 -
集成多个模型
通过集成方法(如Bagging、Boosting)提升模型的整体表现。
五、实际应用中的经验
在实际项目中,处理欠拟合时可以遵循以下流程:
-
观察训练集性能
-
如果训练集准确率低 → 可能是欠拟合。
-
-
尝试提升模型容量
-
使用更复杂的模型结构(如增加层数、节点数)。
-
-
丰富特征工程
-
特征构造往往比单纯换模型效果更好。
-
-
调参,减少正则化力度
-
尝试减小L2正则权重或Dropout率。
-
-
延长训练时间
-
适当增加训练轮次(epoch数)。
-
六、总结
欠拟合(Underfitting)是深度学习和机器学习训练中常见的挑战之一。
通过合理调整数据、特征和模型结构,可以有效缓解欠拟合,提升模型在训练集与测试集上的表现。
记住,欠拟合主要是高偏差问题,要解决偏差,就需要让模型有更强的拟合能力。
七、参考资料
-
Chris Albon — [Machine Learning Flashcards]
-
Ian Goodfellow — [Deep Learning Book]
-
Andrew Ng — [Machine Learning Course (Coursera)]
如果你喜欢这样的技术分享,欢迎点赞、收藏,也可以留言交流你的看法和经验!
:屏障(Barrier))
)
生成 API 文档)

