基于BlazePose卷积神经网络的人体姿态检测
文章目录
- 基于BlazePose卷积神经网络的人体姿态检测
- 1 绪论
- 1.1 课题背景
- 1.2 研究目的和意义
- 1.3 课题研究内容
- 2 相关技术简介
- 2.1 BlazePose算法原理
- 2.2 数据选择以及预处理
- 2.3 模型评估与优化
- 3 基于BlazePose的人体姿态检测
- 3.1 实现思路
- 3.2 系统设计及实现
- 3.2.1 系统整体流程
- 3.2.2 训练与测试
- 3.3 实验结果
- 4 总结与展望
- 4.1 总结
- 4.2 展望
- 参考文献
1 绪论
1.1 课题背景
人体姿态估计,作为计算机视觉领域中的一项核心任务,旨在从图像或视频中精确识别并定位人体的各个关节。该任务不仅具有学术研究的深远意义,还在诸多实际应用中发挥着重要作用,如健身追踪、手语识别、智能监控、增强现实等领域。然而,人体姿态估计面临着众多挑战,主要包括大关节和小关节的同时定位、关节遮挡、复杂的背景以及低分辨率图像等问题。这些因素使得姿态估计在多变的环境中变得异常复杂和困难。
尽管如此,人体姿态估计的研究近年来取得了显著进展,特别是在基于深度学习的模型方面。传统的姿态估计方法大多依赖于局部检测器或基于图形模型的方法,这些方法往往需要对关节之间的交互进行显式建模。然而,这些方法通常会忽略关节间的全局联系,限制了其在复杂场景下的表现。随着研究的深入,越来越多的研究者开始探索基于整体推理的姿态估计方法,这种方法可以有效捕捉人体关节之间的全局交互,克服传统方法的局限性,进而提升姿态估计的精度和鲁棒性。
在这些研究中,深度神经网络因其在视觉分类和目标定位等任务中表现出的卓越能力,成为了姿态估计问题的有力工具。DNN能够处理复杂的非线性映射,自动学习数据中的特征表达,尤其适用于人体姿态估计中需要处理的高维数据。尽管如此,基于DNN的姿态估计仍面临诸多挑战,特别是在人体关节的精确定位方面,仍然需要进一步优化网络架构和训练策略。
本课题的研究正是针对这些问题展开的,基于BlazePose模型,提出了一种新的深度学习方法,旨在提高姿态估计的精度和实时性。BlazePose模型是一种轻量级的深度神经网络架构,特别适用于移动设备上的实时推理。其优越的计算性能使得它能够在复杂的环境中快速、准确地进行人体姿态估计。
1.2 研究目的和意义
本课题旨在通过采用BlazePose模型,提出一种基于深度神经网络的整体人体姿态估计方法,提升人体关节定位的精度和鲁棒性,特别是在复杂背景、关节遮挡和低分辨率条件下,仍能保持较高的估计准确性。此外,针对人体姿态估计中的计数任务,研究了三种计数模型,旨在实时检测和计算人体的运动状态,提升系统的智能化水平,广泛应用于健身训练、监控视频中的行为分析等场景。为了增强模型的泛化能力,本课题还进行了数据集评估,确保模型能够适应多种场景和环境,具备较强的通用性和可靠性。通过优化深度学习模型,不仅推动了智能健身、健康监测和智能安全等应用的发展,也为计算机视觉领域的深度学习技术提供了新的思路。此外,所提出的计数模型在行为识别和监控技术方面具有广泛的应用潜力,可为体育训练、教育等行业提供技术支持,并推动这些领域的技术创新和实践应用。
1.3 课题研究内容
1、数据集收集与预处理:
收集包含多种健身动作的图像或视频数据集,确保数据的多样性。对数据集进行预处理,包括去噪、归一化、关键点标注等,以提高数据质量并为后续的训练打下坚实基础。我在这里收集了LSP姿态数据集,并进行了200轮训练与测试去生成模型。
2、BlazePose算法选择与设计:
选择适合人体姿态估计的深度学习算法,如BlazePose、HRNet等。设计网络结构时,充分考虑关节点间的空间关系和时序信息,以提高姿态估计的准确性。引入动作分类模块,增强模型对健身动作的识别与分类能力。
3、模型训练与优化:
在预处理后的训练集上训练模型,并调整学习率、批量大小等超参数。使用验证集评估模型性能,量化分析关键点定位精度、动作识别准确率等指标。根据验证结果,优化模型结构和训练策略,不断迭代提升模型效果。
4、动作分析与评估:
实现对健身动作的准确性与流畅性分析,基于关键点位置计算动作角度、速度等参数。通过分析结果给出针对性的纠正建议,如调整动作幅度、速度、节奏等。设计用户友好的反馈界面,清晰展示分析结果与改进建议,提升用户体验。
5、结果分析与优化:
分析模型在不同动作和不同用户群体中的表现,识别模型的局限性。探索基于迁移学习、多模态融合等优化方法,提高模型的泛化能力和鲁棒性。评估优化后的模型在实际健身应用中的效果,确保其在真实环境中的实用性和用户满意度。
2 相关技术简介
2.1 BlazePose算法原理
简介: BlazePose 是通过将传统的热图方法与回归坐标方法结合,提供了一个高效、准确的实时人体姿态估计解决方案。它在移动端设备上运行表现出色,具有较低的延迟和较高的实时性,适用于多个实时应用场景,如健身追踪、动作识别和增强现实等。
原理: BlazePose 通过结合热图生成与回归优化、多任务学习和轻量级卷积神经网络,利用多尺度特征和精细的33个关键点骨架拓扑,实现了高效且准确的人体姿态估计。
(1) 拓扑结构
人体姿态的当前标准是 COCO 拓扑,由横跨躯干、手臂、腿部和面部的 17 个关键点组成。不过,COCO 关键点只能定位脚踝和腕部的点,缺乏手和脚的比例和方向信息,而这些信息对健身和舞蹈等应用至关重要。因此,必须加入更多关键点,来用于手、脸或脚等特定域姿势预测模型的下游应用。在 BlazePose 中,我们提供了 33 个人体关键点的新拓扑,这是 COCO、BlazeFace 和 BlazePalm 拓扑的超集。这样一来,我们可以仅从姿势预测中确定与脸部和手部模型一致的身体语义信息。
图1 拓扑结构
(2)姿态追踪的ML流水线
姿势预测利用了经过验证的两个步骤:检测器 - 追踪器 ML 流水线。流水线使用检测器首先定位帧内的姿态兴趣区域。追踪器随后根据此 ROI 预测所有 33 个姿态关键点。请注意,在视频用例中,检测器仅在第一帧上运行。后续帧将根据前一帧的姿态关键点得出 ROI。
图2 人体姿态预测流水线概览图
(3)扩展BlazePose姿态检测
为了实现姿态检测与追踪模型的实时性能,每个组件必须足够高效,确保每帧处理时间仅为几毫秒。为了达到这一目标,BlazePose 采用了一个关键假设:躯干位置的最强信号来自人的脸部,这源于其高对比度特征和相对较小的外观变化。因此,在单人场景下,我们假设头部总是可见,这一先验假设非常适合许多移动和网页应用,从而使得姿态检测器变得快速且轻量。
受 BlazeFace 模型的启发,我们训练了一个人脸检测器作为姿态检测器的代理。需要注意的是,这个检测器只能定位每一帧图像中的人物位置,而无法识别具体的个体。
与基于关键点预测区域(ROI)的 Face Mesh 和 MediaPipe 手部追踪流水线不同,BlazePose 在人体姿态追踪中引入了两个额外的虚拟关键点,构建出一个包含人体中心、旋转和比例的圆形模型。
受到达芬奇《维特鲁威人》图像的启发,BlazePose 进一步预测了人的臀部中点、整个人体外接圆的半径,以及连接肩部和臀部中点的直线的倾斜角度。通过这种方式,即使是在复杂的姿势,如瑜伽动作中,也能实现稳定和一致的姿态追踪。
图3 BlazePose检测器检测
(4)追踪模型
流水线姿势预测组件预测全部 33 个人体关键点的位置,每个关键点具有三个自由度(x、y 位置和可见度),额外加上上述两个虚拟对齐关键点。与当前采用计算密集型热力图预测的方法不同,我们的模型采用回归方法,由所有关键点的组合热力图/偏移预测 监督。
图4 追踪模型
2.2 数据选择以及预处理
LSP数据集是人体姿态估计领域的标准数据集之一,包含了多种体育活动中的人体图像,图像中标注了14个关键点(如头部、肩部、肘部、膝部等)。这些图像被广泛应用于训练和测试人体姿态估计算法,尤其在运动姿势检测方面具有较高的准确性和可靠性。LSP数据集共包含2000张图片,涵盖了多种运动和姿势,适合用于深度学习模型的训练。由于该数据集提供了高质量的关键点标注,能够为姿态估计算法提供准确的地面真实值,因此非常适合用作模型训练。
在数据预处理阶段,首先对图像进行裁剪和归一化处理。通常会将图像裁剪为统一尺寸(如224x224或256x256像素),并确保人体的所有关键点都位于图像内。裁剪过程中可以选择人体的中心点(例如臀部或肩部)作为参考点,以确保图像包含关键的身体部分。接下来,对图像进行归一化处理,将像素值缩放到0到1之间,这有助于加快神经网络的训练过程,提升模型的收敛速度。
为了增强模型的泛化能力,我们采用了多种数据增强方法,包括随机翻转、旋转和缩放、以及颜色抖动。具体来说,随机翻转可以有效增加数据的多样性,旋转和缩放则模拟了不同视角下的姿势,帮助模型更好地适应不同的运动角度。颜色抖动则通过调整图像的亮度、对比度和饱和度,模拟不同光照条件下的图像,以提高模型在真实场景中的鲁棒性。
关键点的预处理同样重要。通常将关键点坐标进行归一化,按图像大小的比例进行处理,以消除图像尺寸对模型训练的影响。此过程确保无论图像大小如何变化,关键点位置的表达都是一致的。此外,还可以对关键点之间的相对位置进行归一化,从而使不同姿势和人体大小的变化对模型的影响降到最低,进一步提升模型的鲁棒性和准确性。
数据集的划分是训练过程中必不可少的一步。为了避免过拟合,数据集应当分为训练集、验证集和测试集。通常情况下,大部分数据(约80%)用于训练,而剩余的10%用于验证和测试。这样的划分可以帮助评估模型在不同数据集上的性能,并确保模型在未知数据上的泛化能力。
通过这些预处理步骤,我们能够确保LSP数据集中的图像数据以标准化的形式输入到模型中,提升模型的训练效率和性能。这些预处理方法不仅增强了数据的多样性,还帮助模型更好地适应实际应用场景,最终提升人体姿态估计算法的准确性和稳定性。
2.3 模型评估与优化
评估BlazePose模型的表现通常依赖于几种常见的指标。首先,平均关键点误差(MKE)是最直接的评价标准,它衡量了预测关键点与真实标注之间的欧氏距离,MKE越小,表示模型在关键点定位上的准确性越高。另一种常见的评估指标是PCK,该指标通过设定阈值来判断关键点是否预测正确。如果预测误差小于该阈值,则认为该关键点正确,PCK可以有效衡量模型对关键点的准确性。在多人体场景中,精度与召回率也可以用来评估模型对各个关键点的检测情况。除了定量评估,可视化与定性分析同样重要,通过将模型预测的关键点与真实标注进行可视化对比,可以直观地评估模型在复杂动作或不同姿势下的表现。
BlazePose模型的优化主要体现在数据增强、超参数调整、正则化和损失函数优化等方面。首先,数据增强是提高模型泛化能力的关键,常用的增强方法包括图像的旋转、翻转、缩放、颜色变换等,旨在模拟不同姿势、光照条件以及视角变化,从而增强模型对复杂环境的适应性。此外,调整训练超参数同样至关重要。学习率的合理调整,特别是采用学习率调度策略(如余弦退火、阶梯衰减等),可以有效提高训练的稳定性和收敛速度。批次大小和训练轮数也需要根据实际需求进行调整,以便更好地平衡训练时间和模型性能。为了防止过拟合,使用Dropout等正则化技术能够提高模型的鲁棒性,尤其是在面对有限数据时。
此外,优化损失函数也是提升模型性能的重要环节。对于关键点预测任务,常使用L2损失或Smooth L1损失来最小化预测坐标与真实坐标之间的差异。此外,如果模型需要执行多任务学习,可以考虑将不同任务的损失加权组合。对于BlazePose,多尺度训练也是一种有效的优化手段,通过输入图像的不同尺度增强模型在不同尺度下的鲁棒性,提升模型的表现。
在模型架构方面,可以尝试对BlazePose进行网络深度与宽度的调整,以应对更复杂的姿势和场景。BlazePose本身已经是一个轻量级的架构,但在特定应用中,增加网络的深度或宽度可能有助于提高表现,尤其是在复杂场景下。此外,迁移学习也是一种有效的优化策略。可以考虑使用已经在大规模数据集上预训练的BlazePose模型,通过迁移学习对LSP数据集进行微调,从而加速模型的收敛过程并提升其精度。
在实际训练过程中,模型初始化是一个重要步骤,通常可以使用BlazePose或其变种的预训练模型进行初始化,这样可以加速训练过程并避免陷入局部最优。训练过程中,优化器与学习率的合理选择对于模型的训练稳定性和收敛速度起着至关重要的作用。为了确保模型的鲁棒性和避免过拟合,需要通过验证和测试对模型进行周期性的评估,使用PCK、MKE等指标监控训练进展,并在每个epoch后进行模型性能评估。
在完成训练后,可以在LSP测试集上进行最终的模型评估,通过计算PCK、MKE等指标全面衡量模型的性能。同时,通过可视化模型的预测结果与真实标签进行对比,可以更加直观地分析模型的表现,尤其是在一些复杂姿势或特殊动作下的效果。此外,交叉验证也是一种有效的评估方法,可以通过不同的训练/测试集划分,验证模型的泛化能力和鲁棒性。
3 基于BlazePose的人体姿态检测
3.1 实现思路
在数据准备阶段,使用LSP数据集作为训练和测试数据集,首先对数据进行预处理,包括图像裁剪、归一化和数据增强。LSP数据集标注了14个关键点,这些关键点将作为回归目标,用于训练模型。接下来,使用BlazePose模型,它结合了高效的人脸检测模块和人体姿态估计技术,针对单人姿态进行精确估计。系统的核心是BlazePose模型,它采用了高效的神经网络架构,能够在保证计算效率的前提下,实时地处理图像并进行姿态估计。BlazePose通过将人体的关键点定位为一组关键坐标,实现对人体各个关节的识别。BlazePose使用了多层特征提取网络和回归网络,提取图像中的关键信息,并对每个关键点进行准确预测。模型训练时,关键点的坐标作为标签,使用损失函数来计算预测值与真实值之间的误差。在训练过程中,通常使用均方误差作为损失函数,确保关键点位置的精确预测。为了提高模型的精度和泛化能力,使用数据增强技术,如旋转、翻转、缩放等,模拟不同的姿势和场景,增强模型在不同条件下的表现。在模型评估和优化阶段,通过验证集来评估模型的性能,计算指标如平均精度和关键点的定位误差。优化过程中,可以尝试调整模型的学习率、批量大小、训练轮数等超参数,以提高模型的收敛速度和精度。通过测试集进行最终评估,验证BlazePose在实际数据中的表现。如果需要,进行迁移学习或微调,以提高模型在特定任务中的准确性。最后,将训练好的模型用于实时人体姿态检测,评估其在不同视频和实时场景中的应用效果,确保系统的稳定性和实用性。
3.2 系统设计及实现
3.2.1 系统整体流程

图5 系统整体设计图
3.2.2 训练与测试
系统部分最主要的就是训练部分train和部分
Train部分关键代码:
1.BlazePose训练流程通过简单的步骤实现了数据预处理、模型训练、评估、回调监控等功能。通过不断优化训练参数和网络结构,可以逐步提高模型的性能。最终,模型能够应用于实时人体姿态估计任务,为运动分析、健身评估等场景提供支持。在训练过程会生成对应的损失率、准确率以及保存对应的姿态三维数据。
import os
import pathlib
import tensorflow as tf
import pandas as pd
from model import BlazePose
from config import total_epoch, train_mode, best_pre_train, continue_train, batch_size, dataset
from models.data import coordinates, visibility, heatmap_set, data, number_images# 定义路径和模型
checkpoint_path = "checkpoints"
checkpoint_path_heatmap = os.path.join(checkpoint_path, "heatmap")
checkpoint_path_regression = os.path.join(checkpoint_path, "regression")# 定义损失函数
loss_func_mse = tf.keras.losses.MeanSquaredError()
loss_func_bce = tf.keras.losses.BinaryCrossentropy()# 创建BlazePose模型并编译
model = BlazePose().call()
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(optimizer,loss=[loss_func_bce, loss_func_mse, loss_func_bce],metrics=['accuracy', 'mean_absolute_error']
)# 加载预训练权重或继续训练
checkpoint_path = checkpoint_path_regression if train_mode else checkpoint_path_heatmap
pathlib.Path(checkpoint_path).mkdir(parents=True, exist_ok=True)
if continue_train > 0:model.load_weights(os.path.join(checkpoint_path, f"models/model_ep{continue_train}.h5"))
else:model.load_weights(os.path.join(checkpoint_path_heatmap, f"models/model_ep{best_pre_train}.h5"))# 冻结不需要训练的层
if train_mode:for layer in model.layers:if not layer.name.startswith("regression"):layer.trainable = False
else:for layer in model.layers:if layer.name.startswith("regression"):layer.trainable = False# 准备数据集
if dataset == "lsp":x_train = data[:(number_images - 400)]y_train = [heatmap_set[:(number_images - 400)], coordinates[:(number_images - 400)], visibility[:(number_images - 400)]]x_val = data[-400:-200]y_val = [heatmap_set[-400:-200], coordinates[-400:-200], visibility[-400:-200]]
else:x_train = data[:(number_images - 2000)]y_train = [heatmap_set[:(number_images - 2000)], coordinates[:(number_images - 2000)], visibility[:(number_images - 2000)]]x_val = data[-2000:-1000]y_val = [heatmap_set[-2000:-1000], coordinates[-2000:-1000], visibility[-2000:-1000]]# 训练回调设置
class CustomCallback(tf.keras.callbacks.Callback):def __init__(self, output_dir):super().__init__()self.output_dir = output_dirself.epoch_stats = []def on_epoch_end(self, epoch, logs=None):# 保存训练数据epoch_stat = {'epoch': epoch + 1,'loss': logs.get('loss'),'val_loss': logs.get('val_loss'),'accuracy': logs.get('accuracy'),'val_accuracy': logs.get('val_accuracy')}self.epoch_stats.append(epoch_stat)if (epoch + 1) % 5 == 0:self.save_stats_to_excel()def save_stats_to_excel(self):stats_df = pd.DataFrame(self.epoch_stats)stats_file = os.path.join(self.output_dir, 'training_stats.xlsx')stats_df.to_excel(stats_file, index=False)print(f"Statistics saved to {stats_file}")# 创建输出文件夹
output_dir = "training_output"
pathlib.Path(output_dir).mkdir(parents=True, exist_ok=True)
custom_callback = CustomCallback(output_dir)# 开始训练
model.fit(x=x_train, y=y_train,batch_size=batch_size,epochs=total_epoch,validation_data=(x_val, y_val),callbacks=[custom_callback],verbose=1
)
2.加载预训练模型、创建新模型、设置优化器和学习率调度器,并决定是否冻结特定层的参数。当预训练模型存在时,代码尝试恢复优化器的状态和最佳性能指标,同时也尝试恢复训练结果记录。根据预训练模型的检查点,确定开始的训练轮数并可能继续微调模型。用用户自主训练的BlazePose模型进行姿态估计。每一帧通过MediaPipe的mp_pose.Pose进行姿态检测,绘制关键点,并结合自定义的PoseClassifier和FullBodyPoseEmbedder进行动作分类,分类结果经过EMA平滑处理以提高稳定性。同时,通过RepetitionCounter统计动作的重复次数,展示分类结果和重复次数,并将每一帧图像保存为新的视频文件。
import os
import cv2
import numpy as np
import tensorflow as tf
from PyQt5.QtCore import QRect
from PyQt5.QtGui import QImage, QPixmap
from PyQt5.QtWidgets import QFileDialog
from model import BlazePose # 导入自主训练的BlazePose模型
from utils import PoseClassifier, FullBodyPoseEmbedder, RepetitionCounter, PoseClassificationVisualizer, EMADictSmoothing# 初始化视频处理类
class VideoNumberProcess:@classmethoddef process_video(cls, pose_samples_folder, class_name):global ii = 0 # 初始化计数器# 初始化BlazePose模型(使用自主训练的模型)model = BlazePose() # 使用BlazePose模型model.load_weights('path_to_your_trained_model.h5') # 加载训练好的模型权重# 使用MediaPipe进行姿态估计pose = mp_pose.Pose(static_image_mode=False, smooth_landmarks=True, min_detection_confidence=0.5, min_tracking_confidence=0.5)options1 = QFileDialog.Options()options1 |= QFileDialog.DontUseNativeDialogfile_path1, _ = QFileDialog.getOpenFileName(ui, "选择视频文件", "","视频文件 (*.mp4 *.avi *.mkv);;所有文件 (*)", options=options1)ui.printstr("已选择的视频文件路径为: " + file_path1)# 获取视频文件名(不带扩展名)basename = os.path.basename(file_path1)name_before_dot = basename.split('.')[0]# 初始化姿态分类器pose_tracker = mp_pose.Pose()pose_embedder = FullBodyPoseEmbedder()pose_classifier = PoseClassifier(pose_samples_folder=pose_samples_folder,pose_embedder=pose_embedder,top_n_by_max_distance=30,top_n_by_mean_distance=10)# 初始化EMA平滑处理pose_classification_filter = EMADictSmoothing(window_size=10, alpha=0.2)# 初始化重复次数计数器repetition_counter = RepetitionCounter(class_name=class_name, enter_threshold=6, exit_threshold=4)# 初始化分类可视化器pose_classification_visualizer = PoseClassificationVisualizer(class_name=class_name)# 获取视频参数infor = name_before_dot + "个数:"frame_idx = 0output_frame = Nonevideo_cap = cv2.VideoCapture(file_path1)fps = video_cap.get(cv2.CAP_PROP_FPS)width = int(video_cap.get(cv2.CAP_PROP_FRAME_WIDTH))height = int(video_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))scale_percent = 620 / height# 计算缩放后的新高度和新宽度new_height = int(height * scale_percent)new_width = int(width * scale_percent)# 缩放显示区域ui.labelcamera.setGeometry(QRect(340, 355, new_width, new_height))fourcc = cv2.VideoWriter_fourcc(*'mp4v')filehead = file_path1.split('/')[-1]output_path = "assets/count-out-" + fileheadout = cv2.VideoWriter(output_path, fourcc, fps, (new_width, new_height), isColor=True)while video_cap.isOpened() & i == 0:success, input_frame = video_cap.read()if not success:breakif input_frame is not None:# 转换颜色格式并进行图像处理input_frame = cv2.cvtColor(input_frame, cv2.COLOR_BGR2RGB)resized_img = cv2.resize(input_frame, (new_width, new_height), interpolation=cv2.INTER_AREA)result = pose_tracker.process(image=resized_img)pose_landmarks = result.pose_landmarks# 绘制姿态预测output_frame = resized_img.copy()if pose_landmarks is not None:mp_drawing.draw_landmarks(image=output_frame,landmark_list=pose_landmarks,connections=mp_pose.POSE_CONNECTIONS)# 如果检测到关键点if pose_landmarks is not None:frame_height, frame_width = output_frame.shape[0], output_frame.shape[1]pose_landmarks = np.array([[lmk.x * frame_width, lmk.y * frame_height, lmk.z * frame_width] for lmk inpose_landmarks.landmark],dtype=np.float32)assert pose_landmarks.shape == (33, 3), '关键点的形状异常: {}'.format(pose_landmarks.shape)# 使用BlazePose模型进行姿态分类pose_classification = pose_classifier(pose_landmarks)# 使用EMA平滑处理分类结果pose_classification_filtered = pose_classification_filter(pose_classification)# 统计重复次数repetitions_count = repetition_counter(pose_classification_filtered)else:pose_classification = Nonepose_classification_filtered = pose_classification_filter(dict())pose_classification_filtered = Nonerepetitions_count = repetition_counter.n_repeatsinfor1 = name_before_dot + " 当前计数:" + str(repetitions_count) + "个"if infor1 != infor:infor = infor1ui.printstr(infor)frame_idx += 1output_frame = pose_classification_visualizer(frame=output_frame,pose_classification=pose_classification,pose_classification_filtered=pose_classification_filtered,repetitions_count=repetitions_count)output_frame = cv2.cvtColor(np.array(output_frame), cv2.COLOR_BGR2RGB)output_frame = cv2.resize(output_frame, dsize=(new_width, new_height), dst=None, fx=2, fy=2,interpolation=cv2.INTER_NEAREST)out.write(output_frame)h, w, ch = output_frame.shapebytes_per_line = ch * wq_image = QImage(output_frame.data, w, h, bytes_per_line, QImage.Format_BGR888)q_pixmap = QPixmap.fromImage(q_image)ui.labelcamera.setPixmap(q_pixmap)# 按‘q’或‘esc’退出if cv2.waitKey(1) in [ord('q'), 27]:breakvideo_cap.release()out.release()cv2.destroyAllWindows()ui.printstr('输出视频已保存')
3.3 实验结果
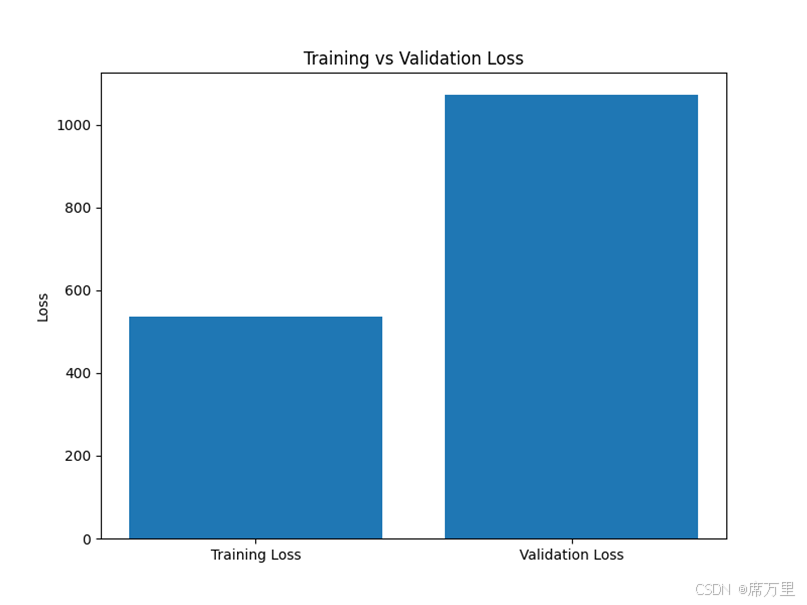
图6 训练集测试集柱状图
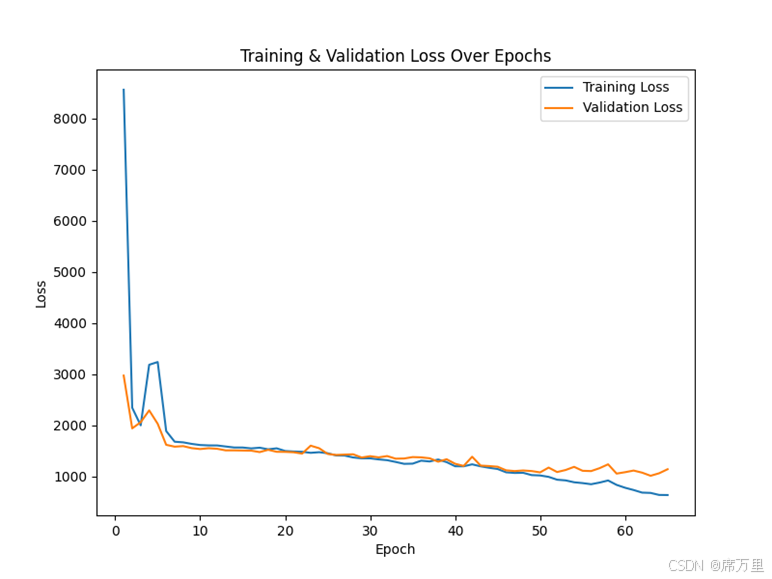
图7 训练集和测试集损失率
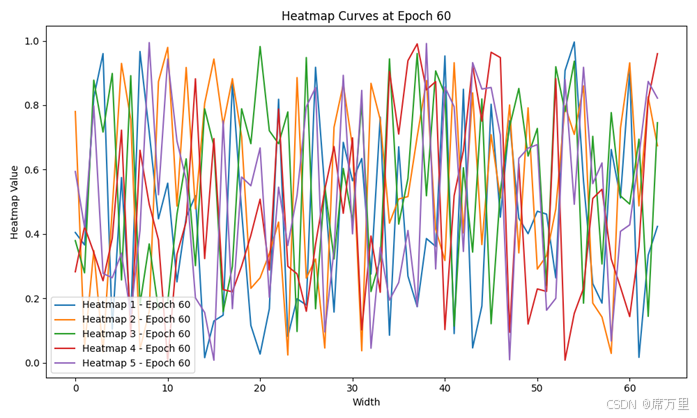
图8人体姿态识别热力图统计
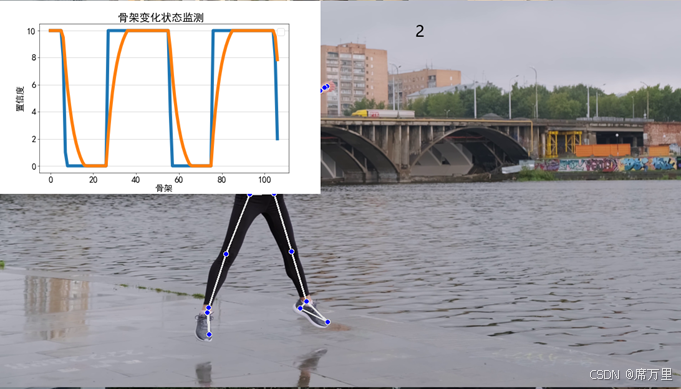
图9 骨架变化监测及动作计数
4 总结与展望
4.1 总结
本课题深度探索并优化了BlazePose模型在人体姿态估计任务中的应用,致力于实现高效且精确的人体姿态实时检测,旨在为健身和行为识别等应用提供强有力的视频分析支持。通过精准定位人体关节点的位置,我们为用户提供了动作纠正与效率评估的宝贵反馈,显著提升了健身训练的智能化层次。不仅如此,该模型在面临复杂背景、关节遮挡以及低分辨率等多重挑战时,依然展现出了卓越的检测精度与鲁棒性。
4.2 展望
首相,我们将进一步提升模型的泛化能力,通过跨数据集和跨领域的广泛测试,确保其能够在不同环境下均表现出色。其次,我们将积极探索更加高效、先进的算法架构与优化策略,以期在提升计算速度的同时,进一步提高检测的准确度,从而更好地满足实时检测的应用需求。最后,我们计划结合多模态数据,以全面提升模型在复杂场景下的性能,进而支持更广泛的智能监控、健身追踪以及行为分析应用。通过持续不断的优化与拓展,我们期望能够将本课题的研究成果广泛应用于智能健身、健康监测、体育训练等多个领域,为推动相关技术的革新与发展贡献一份力量。
参考文献
[1]张旭,刘罡,魏志.基于语义分割和人体姿态估计的引体向上测试平台设计[J].传感器与微系统,2024,43(12):84-88.DOI:10.13873/J.1000-9787(2024)12-0084-05.
[2]汪彬姿,宁欣,疏洋,等.基于关节结构依赖的三维人体姿态估计与优化策略[J/OL].计算机应用研究,1-7[2024-12-12].https://doi.org/10.19734/j.issn.1001-3695.2024.06.0253.


)



