Python+Selenium4 Web自动化测试框架是一个强大的工具,它可以帮助开发者自动化测试Web应用程序。Selenium是一个开源的自动化测试工具,它可以模拟用户在浏览器中的行为。
实现
安装库:
pip install selenium打开浏览器
driver = webdriver.Edge() # 打开Edge浏览器# driver_Chrome = webdriver.Chrome() # 打开Chrome浏览器# driver_Firefox = webdriver.Firefox() # 打开Firefox浏览器发送请求
driver.get("https://www.bilibili.com") # 请求网页,传网址常用的元素定位
| 定位方式 | 描述 |
| By.ID | 通过元素的id属性来定位 |
| By.CLASS_NAME | 通过元素的class属性来定位 |
| By.NAME | 通过元素的name属性来定位 |
| By.XPATH | 通过元素的xpath属性来定位 |
| By.LINK_TEXT | 通过元素的link_text属性来定位 |
| By.PARTIAL_LINK_TEXT | 通过元素的partial_link_text属性来定位 |
| By.TAG_NAME | 通过元素的tag_name属性来定位 |
| By.CSS_SELECTOR | 通过元素的css_selector属性来定位 |
下面直接讲解常用的元素定位代码
import time # 导入时间模块,用于等待from selenium import webdriver # 导入Selenium的浏览器驱动from selenium.webdriver import Keys # 导入Keys类,用于模拟键盘操作from selenium.webdriver.common.by import By # 导入By类,提供不同的定位方式# 不同的元素定位方法说明"""By.ID : 通过元素的id属性来定位By.CLASS_NAME : 通过元素的class属性来定位By.NAME : 通过元素的name属性来定位By.XPATH : 通过元素的xpath属性来定位By.LINK_TEXT : 通过元素的link_text属性来定位By.PARTIAL_LINK_TEXT : 通过元素的partial_link_text属性来定位By.TAG_NAME : 通过元素的tag_name属性来定位By.CSS_SELECTOR : 通过元素的css_selector属性来定位"""def By_ID(): # 通过ID定位元素的操作函数driver.get("https://www.baidu.com") # 打开百度网页driver.find_element(By.ID, "kw").send_keys("selenium") # 找到ID为kw的元素(搜索框)并输入文本"selenium"driver.find_element(By.ID, "su").click() # 找到ID为su的元素(搜索按钮)并点击driver.close() # 关闭浏览器def By_CLASS_NAME(): # 通过Class Name定位元素的操作函数driver.get("https://www.bilibili.com") # 打开Bilibili网页driver.find_element(By.CLASS_NAME, "s_ipt").send_keys("python") # 找到Class为s_ipt的元素(搜索框)并输入文本"python"driver.find_element(By.CLASS_NAME, "s_btn").click() # 找到Class为s_btn的元素(搜索按钮)并点击time.sleep(3) # 等待3秒for i in driver.find_elements(By.CLASS_NAME, "c-container"): # 循环打印Class为c-container的元素(搜索结果)print(i.text)driver.close() # 关闭浏览器# 通过Tag Name定位元素的操作函数def By_TAG_NAME():driver.get("https://www.bilibili.com") # 打开Bilibili网页driver.find_element(By.TAG_NAME, "input").send_keys("Python") # 找到标签名为input的元素并输入文本"Python"driver.find_element(By.TAG_NAME, "input").send_keys(Keys.ENTER) # 模拟按下回车键time.sleep(3) # 等待3秒driver.close() # 关闭浏览器def By_NAME(): # 通过Name定位元素的操作函数driver.get("https://www.baidu.com") # 打开百度网页driver.find_element(By.NAME, "wd").send_keys("selenium") # 找到Name为wd的元素(搜索框)并输入文本"selenium"driver.find_element(By.NAME, "wd").send_keys(Keys.ENTER) # 模拟按下回车键time.sleep(3) # 等待3秒driver.close() # 关闭浏览器# 通过CSS Selector定位元素的操作函数def By_CSS_SELECTOR():"""通过Class属性定位: class值前面加 . 比如 .kw通过ID属性定位: id值前面加 # 比如 #kw通过属性定位: 属性名加[属性值] 比如 [name='kw']组合定位 : 比如 input.kw input[name='kw']标签属性定位 :比如 input[type='text']模糊匹配-包含 : 'a[href*="image.baidu.com"]'模糊匹配-匹配开头 : 'a[href^="https://image.baidu"]'模糊匹配-匹配结尾 : 'a[href$="image.baidu.com/"]':return:"""driver.get("https://www.baidu.com") # 打开百度网页driver.find_element(By.CSS_SELECTOR, "#kw").send_keys("selenium") # 通过CSS Selector找到ID为kw的元素(搜索框)并输入文本"selenium"driver.find_element(By.CSS_SELECTOR, "#kw").send_keys(Keys.ENTER) # 模拟按下回车键time.sleep(3) # 等待3秒driver.close() # 关闭浏览器if __name__ == '__main__':driver = webdriver.Chrome() # 实例化Chrome浏览器驱动# driver = webdriver.Edge() # 使用Edge浏览器驱动# By_ID() # 调用通过ID定位的函数# By_CLASS_NAME() # 调用通过Class Name定位的函数# By_TAG_NAME() # 调用通过Tag Name定位的函数# By_NAME() # 调用通过Name定位的函数By_CSS_SELECTOR() # 调用通过CSS Selector定位的函数实例
from selenium import webdriver # 导入Selenium的浏览器驱动from selenium.webdriver.common.by import By # 导入By类,提供不同的定位方式from selenium.webdriver.common.keys import Keys # 导入Keys类,用于模拟键盘操作import time # 导入时间模块,用于等待def main(): # 定义主函数driver.find_element(By.ID, "q").send_keys("男装") # 找到ID为"q"的搜索框元素,输入"男装"driver.find_element(By.ID, "q").send_keys(Keys.ENTER) # 模拟按下回车键for a in range(4): # 循环翻页4次li = driver.find_elements(By.CLASS_NAME, "Card--doubleCardWrapper--L2XFE73") # 找到class为"Card--doubleCardWrapper--L2XFE73"的所有元素for i in li: # 遍历每个商品元素# 商品名称title = i.find_element(By.CLASS_NAME, "Title--descWrapper--HqxzYq0").text # 找到商品标题元素,获取文本信息# 价格price = i.find_element(By.CLASS_NAME, "Price--priceInt--ZlsSi_M").text + \i.find_element(By.CLASS_NAME, "Price--priceFloat--h2RR0RK").text # 角# 店铺名称shop = i.find_element(By.CLASS_NAME, "ShopInfo--TextAndPic--yH0AZfx").text # 找到店铺信息元素,获取文本信息# 打印商品信息print("商品名称:", title)print("价格:", price)print("店铺名称:", shop)time.sleep(3) # 等待3秒driver.find_element(By.CLASS_NAME, "next-next").click() # 找到class为"next-next"的元素(下一页按钮),点击翻下一页if __name__ == '__main__':driver = webdriver.Chrome() # 实例化Chrome浏览器驱动driver.get('https://www.taobao.com/') # 打开淘宝网页main() # 调用主函数执行搜索和信息抓取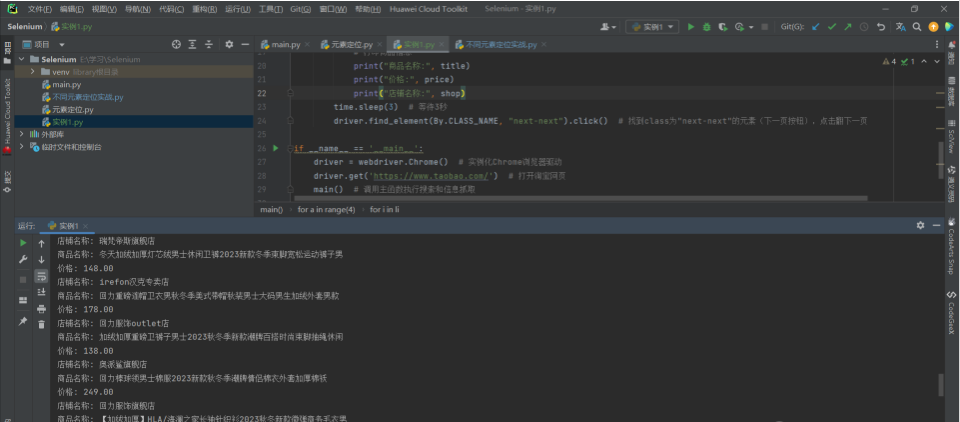
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!







