在VLA基础上,训练一个视觉-语言-动作模型,使其能够在选择机器人动作之前,根据指令和图像生成思考决策的推理步骤,从而实现更佳的性能、可解释性和泛化能力。
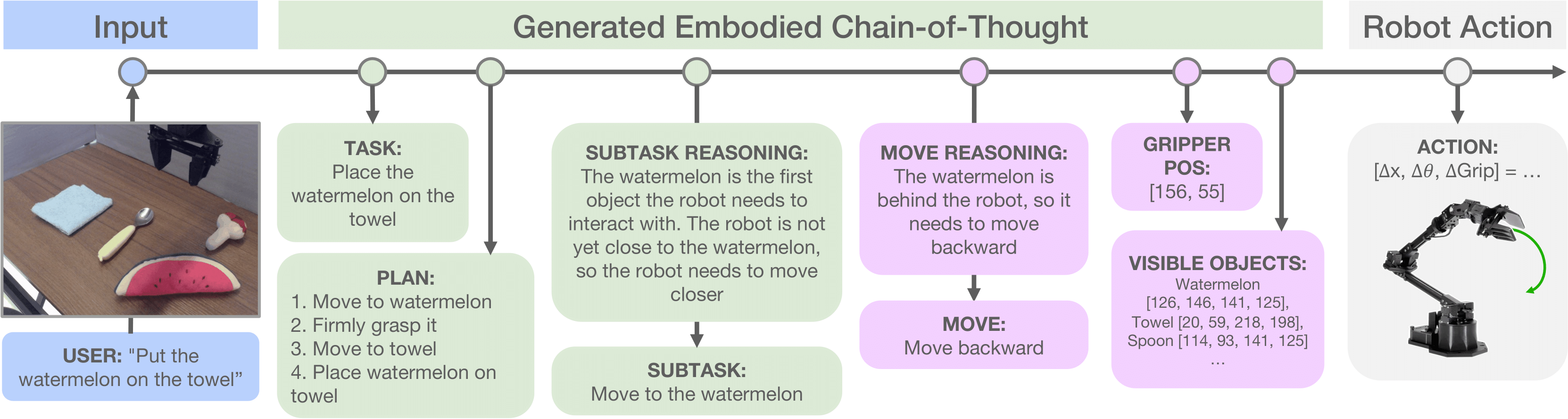
下面是一些示例,输入指令和图像数据,输出任务目标、子任务拆分(生成计划)、子任务推理、控制指令

项目地址:https://embodied-cot.github.io/
论文地址:Robotic Control via Embodied Chain-of-Thought Reasoning
代码地址:https://github.com/MichalZawalski/embodied-CoT/
了解一下ECoT的思路框架:
1、创建Conda环境
首先创建一个Conda环境,名字为ECoT,python版本为3.10
然后进行ECoT环境
conda create -n ECoT python=3.10
conda activate ECoT然后下载代码,安装环境依赖
pip install git+https://github.com/MichalZawalski/embodied-CoT/安装成功后是这样的:
然后安装opencv-python 和 imageio
pip install opencv-python imageio2、安装相关依赖库
除了安装上面的基本,还需安装timm,升级ml_dtypes版本等
pip install timm==0.9.16pip install --upgrade ml_dtypes3、运行推理
首先下载ECoT需要的具身特征和推理数据 embodied_features_bridge.json,大约1.3G
下载地址:https://huggingface.co/datasets/Embodied-CoT/embodied_features_bridge/tree/main
然后修改dataset.py代码,路径:prismatic/vla/datasets/rlds/dataset.py
在第60行,修改embodied_features_bridge.json的存放路径
# ruff: noqa: B006
def make_dataset_from_rlds(name: str,data_dir: str,*,train: bool,standardize_fn: Optional[Callable[[dict], dict]] = None,shuffle: bool = True,image_obs_keys: Dict[str, Optional[str]] = {},depth_obs_keys: Dict[str, Optional[str]] = {},state_obs_keys: List[Optional[str]] = (),language_key: Optional[str] = None,action_proprio_normalization_type: NormalizationType = NormalizationType.NORMAL,dataset_statistics: Optional[Union[dict, str]] = None,absolute_action_mask: Optional[List[bool]] = None,action_normalization_mask: Optional[List[bool]] = None,num_parallel_reads: int = tf.data.AUTOTUNE,num_parallel_calls: int = tf.data.AUTOTUNE,# reasoning_dataset_path: str = "~/.cache/reasonings_dataset.json",reasoning_dataset_path: str = "./model_weight/reasonings_dataset.json",
) -> Tuple[dl.DLataset, dict]:然后下载模型权重ecot-openvla-7b-bridge
下载地址:https://huggingface.co/Embodied-CoT/ecot-openvla-7b-bridge/tree/main
下载上面的文件,存放在model_weight/ecot-openvla-7b-bridge目录下
ecot-openvla-7b-bridge内容的文件:
整理了一个demo代码,大家可以参考一下:
"""
Embodied-CoT 可视化推理演示脚本
"""import torch
import argparse
from transformers import AutoProcessor, AutoModelForVision2Seq
import time
import numpy as np
import cv2
import textwrap
from PIL import Image, ImageDraw, ImageFont
import enum
import sys
import os# 定义推理步骤标签
class CotTag(enum.Enum):TASK = "TASK:"PLAN = "PLAN:"VISIBLE_OBJECTS = "VISIBLE OBJECTS:"SUBTASK_REASONING = "SUBTASK REASONING:"SUBTASK = "SUBTASK:"MOVE_REASONING = "MOVE REASONING:"MOVE = "MOVE:"GRIPPER_POSITION = "GRIPPER POSITION:"ACTION = "ACTION:"# 工具函数定义
def split_reasoning(text, tags):"""分割推理文本为结构化字典"""new_parts = {None: text}for tag in tags:parts = new_partsnew_parts = {}for k, v in parts.items():if tag in v:s = v.split(tag, 1)new_parts[k] = s[0]new_parts[tag] = s[1] if len(s) > 1 else ""else:new_parts[k] = vreturn new_partsdef name_to_random_color(name):"""生成确定性颜色"""return [(hash(name) // (256**i)) % 256 for i in range(3)]def draw_gripper(img, pos_list, img_size=(640, 480)):"""绘制机械手轨迹"""for i, pos in enumerate(reversed(pos_list)):pos = resize_pos(pos, img_size)scale = 255 - int(255 * i / len(pos_list))cv2.circle(img, pos, 6, (0, 0, 0), -1)cv2.circle(img, pos, 5, (scale, scale, 255), -1)def get_metadata(reasoning):"""解析元数据"""metadata = {"gripper": [], "bboxes": {}}# 解析机械手位置if CotTag.GRIPPER_POSITION.value in reasoning:pos_str = reasoning[CotTag.GRIPPER_POSITION.value].strip()if pos_str.startswith("[") and pos_str.endswith("]"):try:coords = [int(x) for x in pos_str[1:-1].split(",")]metadata["gripper"] = [(coords[i], coords[i+1]) for i in range(0, len(coords), 2)]except:pass# 解析物体边界框if CotTag.VISIBLE_OBJECTS.value in reasoning:for obj_str in reasoning[CotTag.VISIBLE_OBJECTS.value].split(";"):obj_str = obj_str.strip()if obj_str:parts = obj_str.split("[")if len(parts) == 2:name = parts[0].strip()coords = [int(x) for x in parts[1].strip("] ").split(",")]if len(coords) == 4:metadata["bboxes"][name] = coordsreturn metadatadef resize_pos(pos, img_size):"""坐标转换"""return [int(pos[0] * img_size[0] / 256), int(pos[1] * img_size[1] / 256)]def draw_bboxes(img, bboxes, img_size=(640, 480)):"""绘制边界框"""for name, bbox in bboxes.items():if len(bbox) != 4:continuecolor = name_to_random_color(name)start = resize_pos((bbox[0], bbox[1]), img_size)end = resize_pos((bbox[2], bbox[3]), img_size)cv2.rectangle(img, start, end, color, 2)cv2.putText(img, name, (start[0], start[1]+15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,255,255), 1)def main(args):"""主函数"""# 检查输入文件if not os.path.exists(args.image_path):print(f"错误:输入图像文件不存在 {args.image_path}")return# 初始化模型device = "cuda" if torch.cuda.is_available() else "cpu"print(f"使用设备: {device}")try:processor = AutoProcessor.from_pretrained(args.model_path, trust_remote_code=True)model = AutoModelForVision2Seq.from_pretrained(args.model_path,torch_dtype=torch.bfloat16,low_cpu_mem_usage=True,trust_remote_code=True).to(device)except Exception as e:print(f"模型加载失败: {str(e)}")return# 准备输入system_prompt = "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions."prompt = f"{system_prompt} USER: What action should the robot take to {args.instruction.lower()}? ASSISTANT: TASK:"try:image = Image.open(args.image_path).convert("RGB")except:print("无法读取图像文件,请检查是否为有效图片格式")return# 运行推理start_time = time.time()try:inputs = processor(prompt, image).to(device, dtype=torch.bfloat16)action, generated_ids = model.predict_action(**inputs,do_sample=False,max_new_tokens=1024)generated_text = processor.batch_decode(generated_ids)[0]except Exception as e:print(f"推理失败: {str(e)}")returnprint(f"推理耗时: {time.time()-start_time:.2f}s")print("最终动作:", action)# 解析推理结果tags = [t.value for t in CotTag]reasoning = split_reasoning(generated_text, tags)metadata = get_metadata(reasoning)# 生成可视化try:# 绘制文本说明base = Image.new("RGB", (640, 480), (255,255,255))draw = ImageDraw.Draw(base)font = ImageFont.load_default(size=14)text_lines = []for tag in [t.value for t in CotTag]:if tag in reasoning and reasoning[tag].strip():# 特殊处理ACTION字段if tag == CotTag.ACTION.value:action_str = f"ACTION: {action.tolist()}" # 使用真实的动作向量text_lines.append(action_str)else:text_lines.append(f"{tag} {reasoning[tag].strip()}")wrapped_text = "\n\n".join([textwrap.fill(line, width=80) for line in text_lines])draw.text((10,10), wrapped_text, (0,0,0), font=font)# 绘制原始图像img_array = np.array(image)if img_array.shape[-1] == 4: # 处理RGBA图像img_array = cv2.cvtColor(img_array, cv2.COLOR_RGBA2RGB)# 添加可视化元素draw_gripper(img_array, metadata["gripper"], image.size)draw_bboxes(img_array, metadata["bboxes"], image.size)# 合并图像final_img = Image.fromarray(np.concatenate([img_array, np.array(base)], axis=1))final_img.save(args.output_path)print(f"结果已保存至: {args.output_path}")except Exception as e:print(f"可视化生成失败: {str(e)}")if __name__ == "__main__":parser = argparse.ArgumentParser(description="Embodied-CoT 可视化推理演示(带默认参数)")parser.add_argument("--image_path", type=str, default="./test_obs.png", help="输入图像路径 (默认: %(default)s)")parser.add_argument("--instruction", type=str, default="place the watermelon on the towel", help="任务指令 (默认: '%(default)s')")parser.add_argument("--output_path", type=str, default="./output.jpg", help="输出图像路径 (默认: %(default)s)")parser.add_argument("--model_path", type=str, default="./model_weight/ecot-openvla-7b-bridge", help="预训练模型路径 (默认: %(default)s)")args = parser.parse_args()# 打印带默认值的参数信息print("运行配置:")print(f" - 输入图像: {os.path.abspath(args.image_path)}")print(f" - 任务指令: {args.instruction!r}")print(f" - 输出路径: {os.path.abspath(args.output_path)}")print(f" - 模型路径: {os.path.abspath(args.model_path)}")print("-"*60)main(args)程序的需要的参数:
if __name__ == "__main__":parser = argparse.ArgumentParser(description="Embodied-CoT 可视化推理演示(带默认参数)")parser.add_argument("--image_path", type=str, default="./test_obs.png", help="输入图像路径 (默认: %(default)s)")parser.add_argument("--instruction", type=str, default="place the watermelon on the towel", help="任务指令 (默认: '%(default)s')")parser.add_argument("--output_path", type=str, default="./output.jpg", help="输出图像路径 (默认: %(default)s)")parser.add_argument("--model_path", type=str, default="./model_weight/ecot-openvla-7b-bridge", help="预训练模型路径 (默认: %(default)s)")运行结果:
2025-05-12 00:51:38.185651: I tensorflow/core/util/port.cc:113] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2025-05-12 00:51:38.203069: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2025-05-12 00:51:38.203089: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2025-05-12 00:51:38.203554: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2025-05-12 00:51:38.206371: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2025-05-12 00:51:38.544293: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
运行配置:- 输入图像: /home/lgp/2025_project/embodied-CoT-main/test_obs.png- 任务指令: 'place the watermelon on the towel'- 输出路径: /home/lgp/2025_project/embodied-CoT-main/output.jpg- 模型路径: /home/lgp/2025_project/embodied-CoT-main/model_weight/ecot-openvla-7b-bridge
------------------------------------------------------------
使用设备: cuda
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 12.70it/s]
推理耗时: 8.21s
最终动作: [ 0.01321167 -0.03668522 0.00027841 -0.0205739 -0.02891492 -0.080656620. ]
结果已保存至: ./output.jpg看看保存结果:

分享完成~






