文章目录
- 前言
- 一、深度学习
- 1、定义
- 2、核心
- 深层神经网络架构
- 自动特征学习
- 非线性变换与复杂模式建模
- 数据与算力驱动
- 典型模型包括
- 3、从神经元到神经网络
- 二、深度学习的工作原理
- 三、优缺点
- 优点
- 1、自动化特征学习与复杂任务处理
- 2、规模化性能优势
- 缺点
- 1、数据与算力强依赖
- 2、模型局限性
- 总结
前言
深度学习是机器学习的重要分支,它基于深层神经网络架构(如卷积神经网络、循环神经网络等),通过多层非线性变换自动从海量数据中学习抽象的特征表示,无需人工手动设计特征,从而实现对复杂数据(如图像、语音、文本等)的分类、预测、生成等任务。其发展源于人工神经网络的研究,2006 年后随着计算能力提升和数据量增长逐步兴起,在计算机视觉、自然语言处理、语音识别等领域取得突破性成果,具备处理非线性问题的强大能力,但也面临依赖大量数据与算力、模型可解释性较弱等挑战。
一、深度学习
1、定义
深度学习是机器学习的一个分支,其核心是通过构建多层非线性神经网络模型(如卷积神经网络、循环神经网络等),让计算机从海量数据中自动学习数据的层次化特征表示,进而实现对复杂模式的建模与任务求解(如图像识别、自然语言处理、生成任务等)。它无需人工手动设计特征,而是通过数据驱动的方式,让模型在训练过程中自主发现数据中的关键特征和规律。
2、核心
深层神经网络架构
深度学习模型由多层(少则几层,多则数百 / 千层)网络组成,包括输入层、隐藏层和输出层。每层通过非线性变换对数据进行逐步抽象,例如底层学习边缘、纹理等简单特征,高层学习物体形状、语义等复杂特征。
自动特征学习
区别于传统机器学习依赖人工设计特征(如手工提取图像的 SIFT 特征),深度学习通过端到端的训练,让模型自动从原始数据(如图像像素、文本序列)中提取分层特征,大大减少了特征工程的人力成本。
非线性变换与复杂模式建模
通过多层非线性激活函数(如 ReLU、Sigmoid)的叠加,深度学习能够捕捉数据中复杂的非线性关系,适用于处理传统方法难以解决的高维、非结构化数据(如图像、语音、文本)。
数据与算力驱动
深度学习的成功依赖于大规模标注数据(用于训练模型)和强大计算资源(如 GPU/TPU 加速训练),通过反向传播算法优化模型参数,最小化预测误差。
典型模型包括
CNN(卷积神经网络):擅长处理图像和空间数据(如图像分类、目标检测);
RNN/LSTM/Transformer:适用于序列数据(如自然语言处理、语音识别);
生成模型(GAN、VAE):用于数据生成(如图像生成、文本创作)。
3、从神经元到神经网络
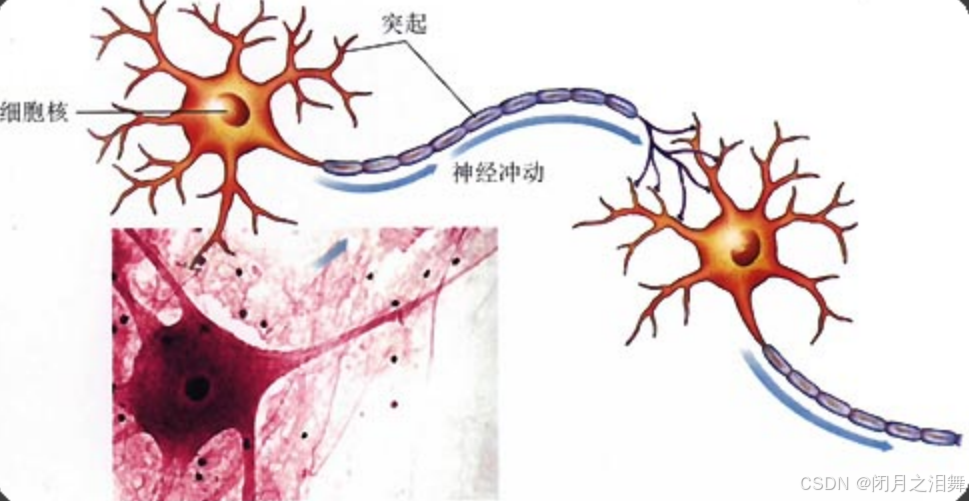
人脑神经元通过树突接收信号、细胞体整合信号、轴突传递信号,并通过突触可塑性动态调整连接强度,形成复杂的生物神经网络。这一机制直接启发了人工神经网络的设计 —— 将神经元抽象为节点,突触抽象为权重,信号整合与激活抽象为数学运算(加权求和 + 激活函数),多层网络的层级处理模拟大脑的分层特征提取。这种跨学科的联想,使计算机能够以工程化的方式模仿生物智能的核心原理,推动了深度学习在图像识别、自然语言处理等领域的突破。
二、深度学习的工作原理
- 数据输入与网络结构
原始数据(如图像像素、文本序列、语音信号)输入到神经网络的输入层。
网络由多层隐藏层(如卷积层、循环层、全连接层)和输出层组成,每层包含大量 “神经元”(节点),节点间通过 ** 权重(Weight)** 连接,权重代表信号传递的强度。 - 前向传播:特征提取与预测
数据从输入层逐层传递到输出层,每层节点对输入信号进行加权求和,并通过非线性激活函数(如 ReLU、Sigmoid)处理,生成该层的输出。
低层网络学习基础特征(如图像的边缘、纹理,文本的单词含义);
高层网络整合低层特征,形成抽象语义(如图像中的物体、文本的句子逻辑)。
最终,输出层根据任务类型(分类、回归、生成等)输出结果(如分类概率、数值预测、生成数据)。 - 计算损失:衡量预测误差
通过损失函数(如交叉熵、均方误差)计算模型预测值与真实标签的差距,衡量模型当前的 “错误程度”。 - 反向传播:优化权重参数
利用反向传播算法,从输出层向输入层反向传递损失梯度,逐层调整网络中的权重和偏差(Bias),使损失函数最小化。
优化算法(如随机梯度下降 SGD、Adam)决定权重更新的步长和方向,通过多次迭代(训练轮次,Epoch)逐步提升模型性能。
深度学习的工作原理本质是:通过多层神经网络的前向传播提取层次化特征,借助反向传播优化参数,使模型在海量数据中自动学习复杂规律,最终实现对图像、语音、文本等复杂数据的高效处理。这一过程模拟了人类大脑的分层信息处理机制,但通过工程化的数学建模和算法优化,在计算机上实现了强大的模式识别和生成能力。
三、优缺点
优点
1、自动化特征学习与复杂任务处理
无需人工设计特征,通过多层网络自动提取数据的层次化特征(如从图像像素到物体语义),高效处理图像、语音、文本等非结构化数据,解决分类、生成、跨模态等复杂任务(如 AI 绘图、语音识别),并通过端到端学习简化系统设计(输入原始数据直接输出结果)。
2、规模化性能优势
在大规模数据和算力支撑下,模型表现随数据量和参数规模增长而提升(规模效应),可通过预训练迁移到多种相似任务(如 BERT 处理各类 NLP 任务),适配高维复杂场景(如自动驾驶、药物研发)。
缺点
1、数据与算力强依赖
需海量标注数据(标注成本高、隐私限制多)和高性能硬件(GPU/TPU)支撑训练,中小企业难以负担;低数据场景(小语种、罕见病)性能差,且模型泛化能力受数据分布影响大(如训练与测试环境差异导致误判)。
2、模型局限性
决策过程如 “黑箱”,难以解释具体逻辑(影响医疗、金融等信任敏感领域应用),可能隐含数据偏见;鲁棒性不足,易受对抗样本攻击,且对新场景(如新物体、动态环境)适应能力弱,需重新训练,调参依赖经验而非理论指导。
总结
深度学习在数据丰富、任务复杂、可解释性要求低的领域(如图像识别、推荐系统、语音助手)具有不可替代的优势;但在小样本、高风险决策、需透明性的场景(如医疗诊断、金融风控、法律判决)中需谨慎应用,需结合传统方法(如符号逻辑)或引入可解释性技术。未来研究方向包括提升数据效率(自监督学习)、降低算力需求(模型轻量化)、增强鲁棒性与可解释性,以推动技术更广泛落地。






