解释器模式:自定义语言解析与执行的设计模式
一、模式核心:定义语言文法并实现解释器处理句子
在软件开发中,当需要处理特定领域的语言(如数学表达式、正则表达式、自定义配置语言)时,可以通过解释器模式定义语言的文法规则,并实现一个解释器来解析和执行该语言的句子。
解释器模式(Interpreter Pattern) 通过将语言的文法规则分解为终结符表达式和非终结符表达式,利用递归调用的方式解析句子。核心解决:
- 自定义语言解析:无需借助第三方解析工具(如 ANTLR),直接实现简单语言的解释器。
- 文法扩展灵活:新增文法规则时,只需扩展表达式类,符合开闭原则。
- 语法树构建:将语言句子转换为抽象语法树(AST),便于可视化和优化。
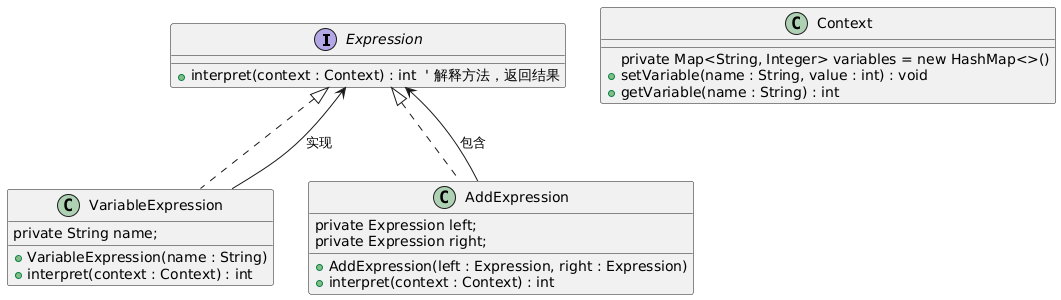
核心思想与 UML 类图
解释器模式包含以下角色:
- 抽象表达式(Expression):定义解释器的公共接口(如
interpret())。 - 终结符表达式(Terminal Expression):对应文法中的终结符(如表达式中的变量、常量),实现具体解释逻辑。
- 非终结符表达式(Non-terminal Expression):对应文法中的非终结符(如运算符),组合其他表达式进行解释。
- 上下文(Context):包含解释器所需的全局信息(如变量映射表)。
- 客户端(Client):构建抽象语法树并触发解释过程。
二、核心实现:简单数学表达式解释器
场景:解析形如 X + Y * 2 的表达式(简化文法,不考虑优先级)
1. 定义抽象表达式接口
public interface Expression { int interpret(Context context); // 解释表达式,返回结果
}
2. 实现终结符表达式(变量或常量)
变量表达式(如 X、Y)
import java.util.Map;
import java.util.HashMap; public class VariableExpression implements Expression { private String name; public VariableExpression(String name) { this.name = name; } @Override public int interpret(Context context) { return context.getVariable(name); // 从上下文中获取变量值 }
}
常量表达式(如 2、3)
public class ConstantExpression implements Expression { private int value; public ConstantExpression(int value) { this.value = value; } @Override public int interpret(Context context) { return value; // 直接返回常量值 }
}
3. 实现非终结符表达式(运算符)
加法表达式
public class AddExpression implements Expression { private Expression left; private Expression right; public AddExpression(Expression left, Expression right) { this.left = left; this.right = right; } @Override public int interpret(Context context) { return left.interpret(context) + right.interpret(context); // 递归解释左右表达式 }
}
乘法表达式
public class MultiplyExpression implements Expression { private Expression left; private Expression right; public MultiplyExpression(Expression left, Expression right) { this.left = left; this.right = right; } @Override public int interpret(Context context) { return left.interpret(context) * right.interpret(context); // 递归解释左右表达式 }
}
4. 定义上下文(管理变量值)
import java.util.HashMap;
import java.util.Map; public class Context { private Map<String, Integer> variables = new HashMap<>(); public void setVariable(String name, int value) { variables.put(name, value); } public int getVariable(String name) { return variables.getOrDefault(name, 0); }
}
5. 客户端构建语法树并解释表达式
public class ClientDemo { public static void main(String[] args) { // 定义表达式:X + Y * 2 // 语法树结构:Add(X, Multiply(Y, 2)) Expression X = new VariableExpression("X"); Expression Y = new VariableExpression("Y"); Expression constant2 = new ConstantExpression(2); Expression multiply = new MultiplyExpression(Y, constant2); Expression expression = new AddExpression(X, multiply); // 设置变量值:X=3,Y=4 Context context = new Context(); context.setVariable("X", 3); context.setVariable("Y", 4); // 解释表达式 int result = expression.interpret(context); System.out.println("表达式结果:" + result); // 输出:3 + 4*2 = 11 }
}
输出结果:
表达式结果:11
三、进阶:处理复杂文法与优先级
问题:上述示例未处理运算符优先级(如乘法应先于加法计算)
解决方案:引入优先级规则,构建带优先级的语法树
1. 定义文法规则(BNF 表示)
expression = term + term | term
term = factor * factor | factor
factor = variable | constant
variable = [A-Za-z]+
constant = [0-9]+
2. 实现带优先级的表达式解析(递归下降解析器)
import java.util.Stack; public class Parser { private final String[] tokens; private int index = 0; public Parser(String expressionStr) { tokens = expressionStr.split(" "); // 假设表达式用空格分隔,如 "X + Y * 2" } // 解析顶级表达式(处理加法) public Expression parseExpression() { Expression expr = parseTerm(); while (index < tokens.length && tokens[index].equals("+")) { index++; expr = new AddExpression(expr, parseTerm()); } return expr; } // 解析项(处理乘法) private Expression parseTerm() { Expression term = parseFactor(); while (index < tokens.length && tokens[index].equals("*")) { index++; term = new MultiplyExpression(term, parseFactor()); } return term; } // 解析因子(变量或常量) private Expression parseFactor() { String token = tokens[index++]; if (token.matches("\\d+")) { return new ConstantExpression(Integer.parseInt(token)); } else { return new VariableExpression(token); } }
}
3. 客户端使用解析器构建语法树
public class ClientDemo { public static void main(String[] args) { String expressionStr = "X + Y * 2"; Parser parser = new Parser(expressionStr); Expression expression = parser.parseExpression(); Context context = new Context(); context.setVariable("X", 3); context.setVariable("Y", 4); int result = expression.interpret(context); System.out.println("带优先级表达式结果:" + result); // 输出:11 }
}
四、框架与源码中的解释器实践
1. 正则表达式引擎
正则表达式引擎(如 Java 的 Pattern 类)使用解释器模式解析正则表达式字符串(如 \\d+),构建状态机并匹配输入文本。
2. SQL 解析器
部分轻量级数据库(如 SQLite)的 SQL 解析模块通过解释器模式将 SQL 语句转换为执行计划,虽然现代数据库更多使用编译型方案,但解释器模式是基础实现思路之一。
3. 模板引擎(如 Velocity、Freemarker)
模板引擎解析模板字符串(如 ${name}),将变量替换和逻辑判断(如 if、foreach)转换为可执行的字节码或直接解释执行,本质上是解释器模式的应用。
五、避坑指南:正确使用解释器模式的 3 个要点
1. 避免处理复杂文法
解释器模式适用于简单文法(如四则运算、简单规则表达式),对于复杂文法(如完整的编程语言),应使用专业的解析工具(如 ANTLR、LLVM),避免解释器过于臃肿。
2. 性能优化
解释器的递归调用和语法树遍历可能导致性能瓶颈,对于高频执行的表达式,可通过以下方式优化:
- 缓存解释结果:对相同表达式缓存解释后的结果。
- 编译为字节码:将表达式编译为可执行字节码(如 Java 的
ClassLoader)。
3. 错误处理
解释器需完善语法错误处理(如非法字符、括号不匹配),避免解析时抛出未检查异常。可通过自定义异常类(如 ParseException)捕获错误并提示用户。
六、总结:何时该用解释器模式?
| 适用场景 | 核心特征 | 典型案例 |
|---|---|---|
| 简单领域语言 | 语言文法简单,无需高性能解析 | 配置文件解析(如自定义 .cfg 文件) |
| 教学或演示用途 | 需要直观展示语言解析过程 | 编译器原理教学、脚本语言入门示例 |
| 快速原型开发 | 无需引入复杂解析工具,快速实现功能 | 小游戏中的自定义指令系统(如 move up 10) |
解释器模式通过将语言解析逻辑分解为表达式层次结构,提供了一种灵活的自定义语言实现方式。至此,23 种设计模式已全部讲解完毕!如果需要回顾某一模式或深入探讨具体应用,可以随时告诉我!
扩展思考:解释器模式的缺点
- 效率低下:解释执行速度通常低于编译执行,不适合高性能要求的场景。
- 维护成本高:复杂文法会导致表达式类数量激增,维护难度加大。


![[C++] STL数据结构小结](http://pic.xiahunao.cn/nshx/[C++] STL数据结构小结)



