文章目录
- 概要
- 项目使用的技术
- 电商平台的页面解析及数据采集分析
- 数据采集python代码编写
- 小结
概要
先叠个甲,本文章只讨论技术和实现,请大家在合法的途径下使用(爬虫不是)数据采集技术,请勿使用技术做违法之事!文章底部有完整的项目地址,欢迎大家自取,能给个starter就更好了。

项目使用的技术
既然是数据采集,当然是我们的python语言了,博主使用了大江狗(django)框架,主要是我们后续采集的数据会做一些报表的分析,数据的处理,也可能需要对外展示,所以博主就选用了这个web框架。项目采用的是通过定时任务去采集数据,所以引入了django_apscheduler框架,然后http请求框架request,以及html解析框架beautifulsoup4
requirements.txt配置如下
Django==4.0
django-apscheduler==0.7.0
apscheduler==3.11.0
pymysql==1.1.1
requests==2.32.0
beautifulsoup4==4.13.4
电商平台的页面解析及数据采集分析
我们在采集数据时,需要分析页面的展示结构,根据html页面的响应结果去获取对应的元素的指定内容,如下是我获取的国外的一个电商平台的数据的过程。数据采集最麻烦的过程是分析网页是如何渲染的。不要亲信网上可能已经写死的代码逻辑,知其然也要知其所以然,不然别人数据有任何变动只能干瞪眼
例如:博主现在想采集一个电商平台的所有的商品类目,假设现在这个页面上的顶级类目如下,使我们想要采集的顶级类目,它的二级类目html地址都是通过顶级类目的地址进行渲染的,所以找到顶级类目的加载逻辑至关重要。:
-
通过元素采集器,我们可以知道元素都是被加载到了
<div id='departments-grid'>元素下。
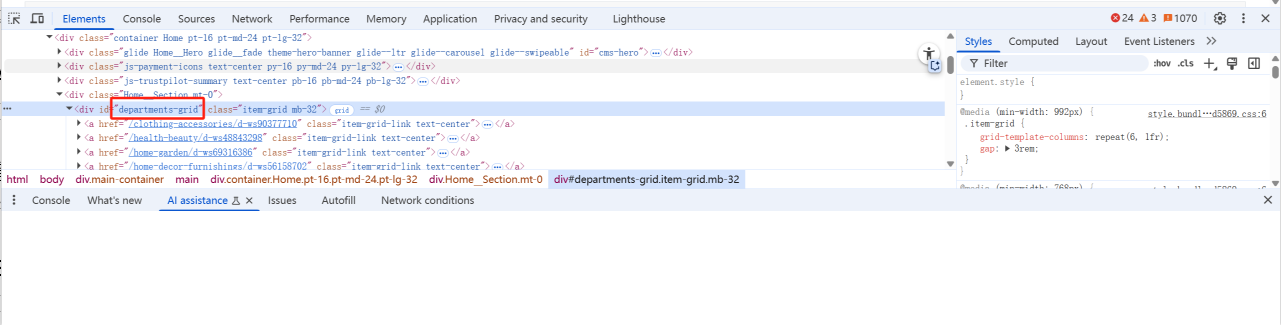
-
观察所有的想用的html的接口,找到了具体的接口返回的那个接口路径,但是同时我们发现了另外一个问题,就是这个html渲染出来的顶级类目都是通过
<a>标签进行加载的,但是herf属性却不存在,就这说明这个顶级类目的数据是通过js去加载渲染的。接下来我们在js文件当中搜索departments-grid,看一下js的处理逻辑
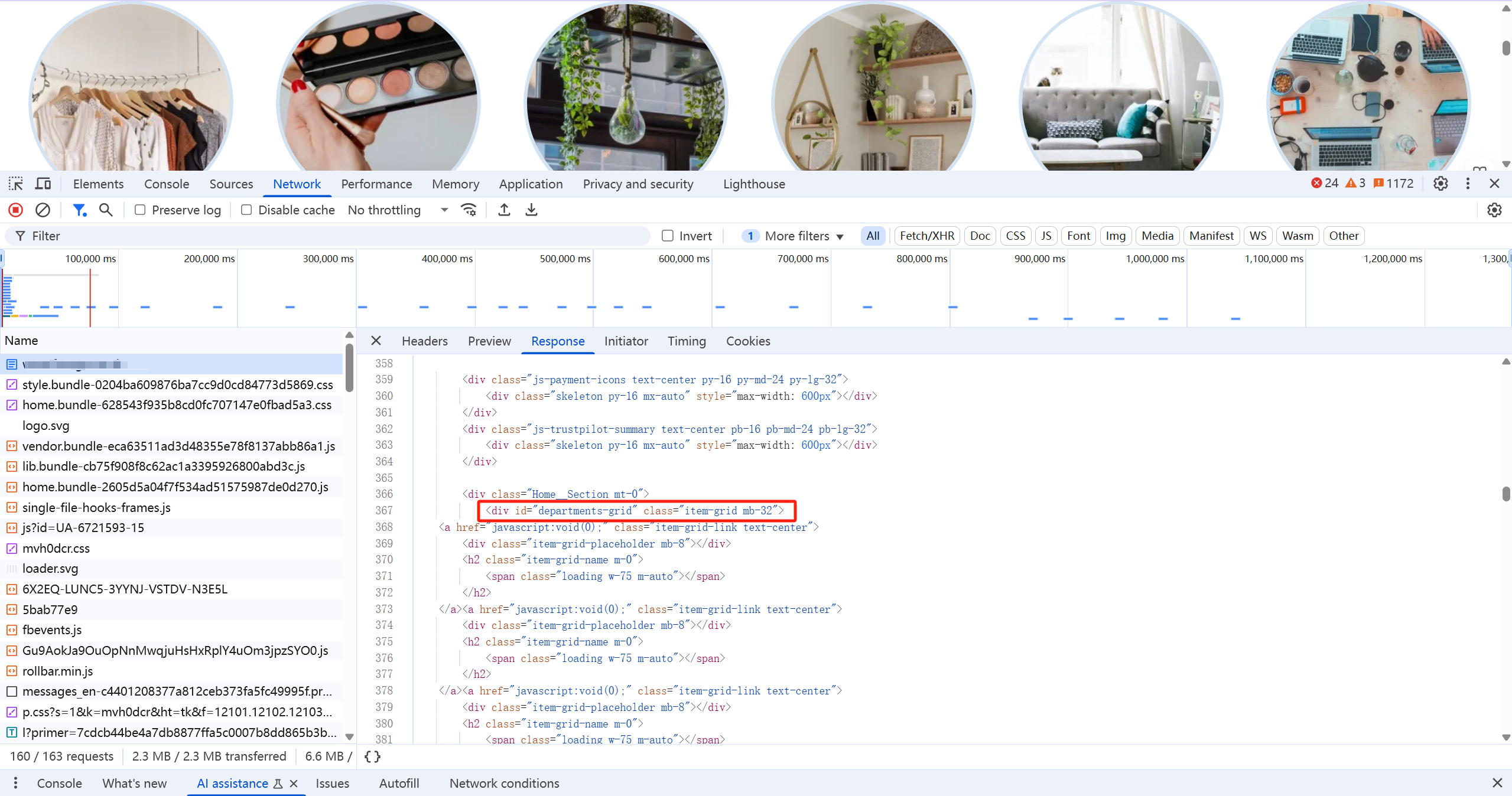
-
最终我们在一个js文件当中找到了对我们需要的元素的处理,此时我们可以看到顶级类目的数据并不是通过接口去请求渲染,而是存储在sessionStorage当中的
-
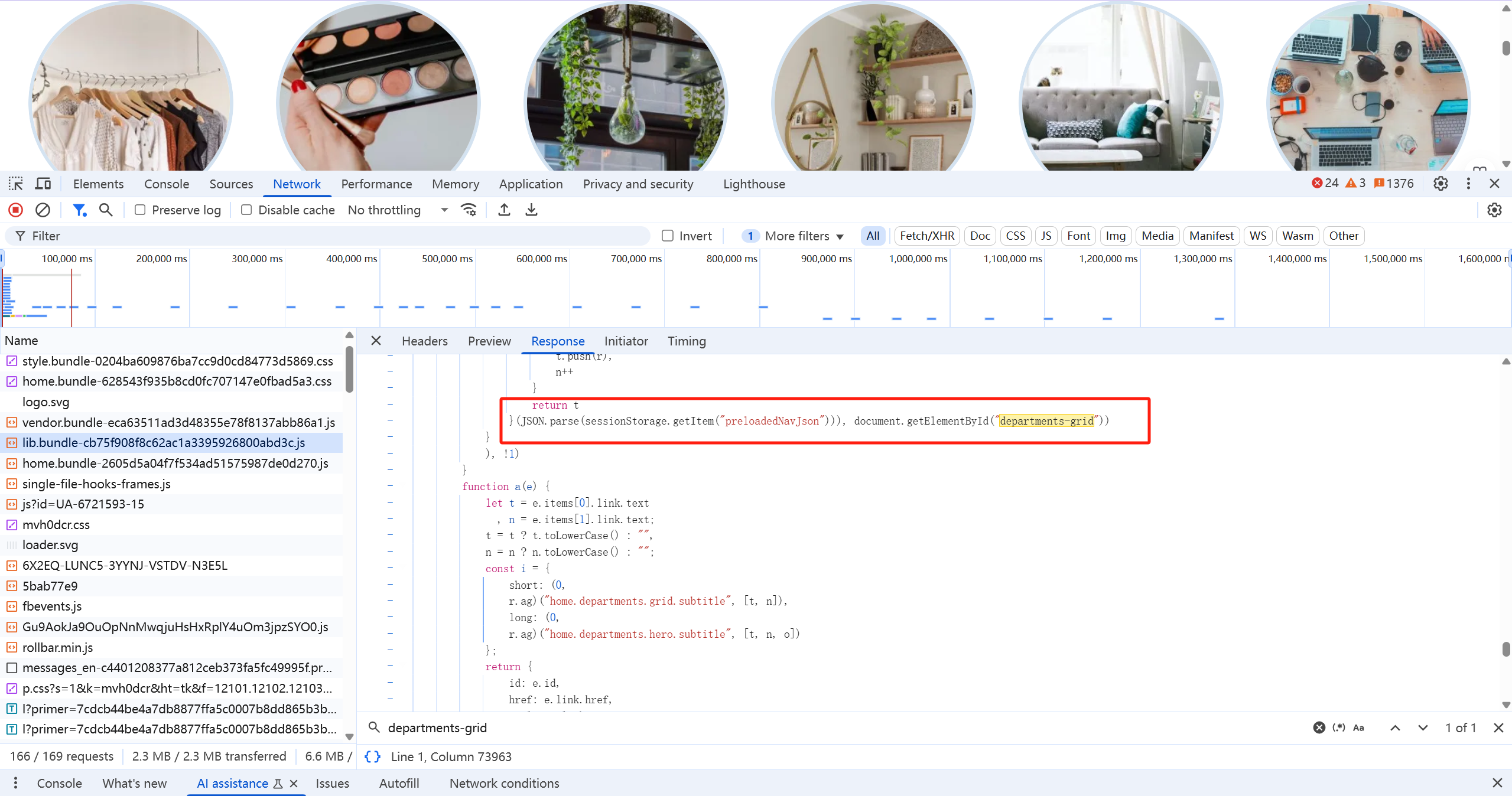
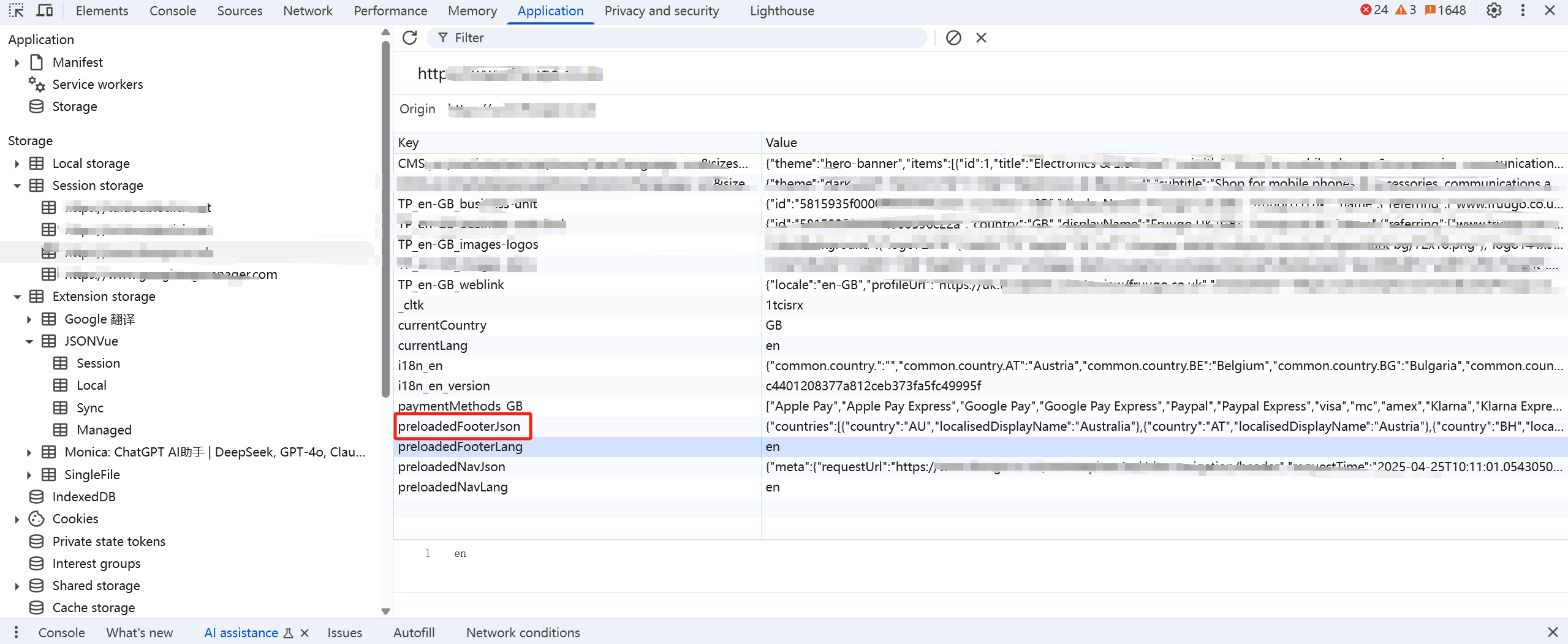
现在我们已经找到了顶级类目的数据,就开始进行python代码的编码
数据采集python代码编写
- 启动一个定时器,每三十天执行一次,定义好了采集定时任务后,处理数据采集
def start_scheduler():logger.info("Starting scheduler...")"""Start the main scheduler"""# 定义一个后台线程进行数据处理scheduler = BackgroundScheduler()# 顶级类目因为是静态数据,所以博主直接定义成字典存储在本地identifier = level_1_classify['xxx']scheduler.add_job(spider_data,args=[identifier ], # 参数通过args传递trigger=IntervalTrigger(days=30),next_run_time=datetime.now() )try:logger.info("Starting scheduler...")scheduler.start()except (KeyboardInterrupt, SystemExit):logger.info("Stopping scheduler...")scheduler.shutdown()- 根据顶级类目递归查询子级类目
def spider_data(identifier: str):# 设置请求头,模拟浏览器访问headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}# 拼接网站的基础路径+需要查看类目的路径地址url = BASE_URl + identifierresponse = requests.get(url, headers=headers)# 解析采集下来的网页数据soup = BeautifulSoup(response.text, 'html.parser')# 查找所有子标签,这个需要根据实际的网站上页面的展示为准,大家切勿所有网站照搬child = soup.find_all('div', class_='container pt-16 pt-md-24 pt-lg-32')tail_child = soup.find_all('div', class_='container Search pt-16 pt-md-24 pt-lg-32')if len(child) == 0 and len(tail_child) == 0:raise Exception(f'没有菜单节点也不是最后一层节点,请调整代码')# 根据自己类目判断是否下级还是类目页,还是商品页,分别进行处理if tail_child:# 递归到了最后一层,根据最后一层的目录数据,查询商品信息page = soup.find('a', class_='d-none d-xl-flex').get_text()page = int(page)# 查询最热销的商品信息product_search_url = url + '?sorting=bestsellingdesc'# 开始查询数据if page <= 100:# 查询page页的数据for i in range(page):# 这边是对商品数据的解析,题主不在上传代码,处理和类目页是一样的parser_page_product(product_search_url)else:# 查询一百页的数据for i in range(100):parser_page_product(product_search_url)else:for child in child:all_links = child.find('div', class_='item-grid mb-48').find_all('a')for a in all_links:# 递归调用href_id = a.get("href")logger.info(f'find link: {href_id}')spider_data(href_id)
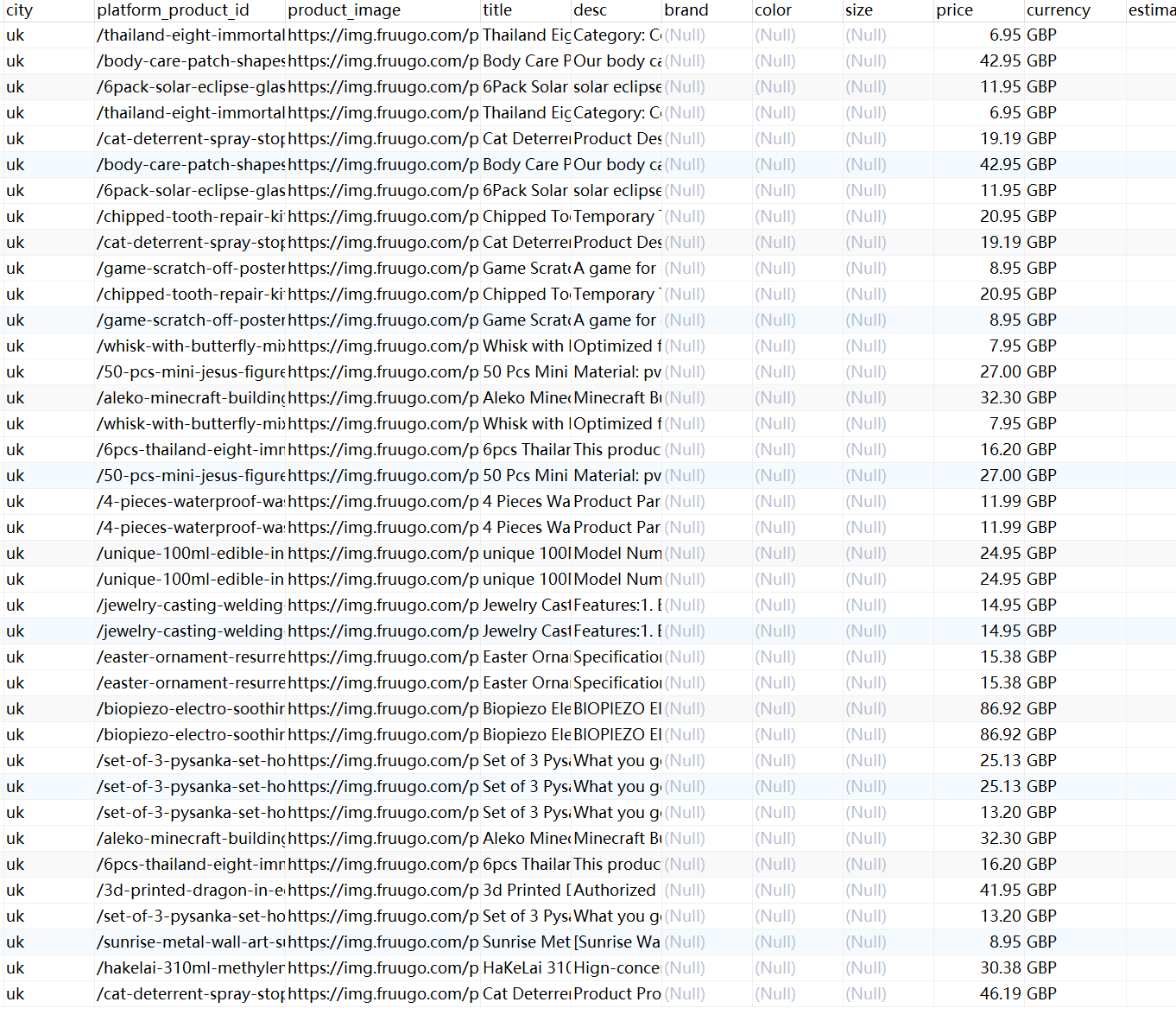
最终保存到数据库数据的效果如下,不同的平台数据需要不同的处理。
完整的项目github地址
小结
以上就是博主在采集数据时的经验总结,html的数据解析不是难点,难点是如何去分析html,从哪个地方去入手才能获取到我们想要的数据,如果我们只能采集单一个页面的数据是没有任何意义的,需要采集规则能够兼容所有的处理,比如说多层级类目的采集,不同城市选择的处理,这些都是在做系统设计时需要考虑到的。






