在我们学习并发编程之前就得先知道线程是什么
什么是线程?
线程是cpu的执行最小单元,是进程中一个独立的任务,一个进程中可以有多个线程
重点区别进程:进程是操作系统分配资源的最小单位。
Java创建线程的方式?
1、继承Thread类
2、实现Runable接口
3、实现Callable接口
4、使用线程池创建
线程中常用到的方法:
run () -- 线程执行的任务写在这一个方法中
start() --启动线程
sleep () -- 线程睡眠制定的时间,是Thread类中的提供的静态方法,通过类名去调用
wait() -- 线程等待,通过notify()唤醒线程或者notifyAll()唤醒所有线程,wait是Object类中的 方法
join() -- 等待线程结束执行
yiled() 线程让步,主动让出cpu执行权
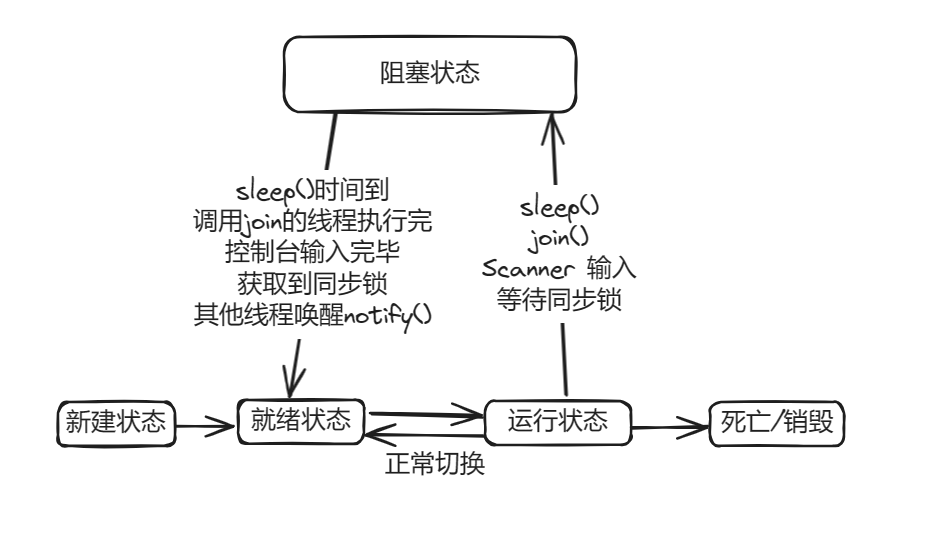
线程状态
新建状态:new Thread()
就绪状态:start() 等待操作系统的调用
运行状态:获得cpu的执行权
阻塞状态:sleep()、wait()、输入、等待获取锁;sleep时间到,调用完join()的线程,输入完毕、获取到同步锁,唤醒等就会从阻塞状态进入就绪状态
死亡或销毁:线程任务执行完了,或者出现异常了
什么是多线程?
一个进程中可以创建多个线程、执行多个任务,提高程序运行效率。
多线程访问共享数据,就会出现线程安全。
解决线程安全问题:
原子类:java.util.concurrent.atomic包下的一系列原子类,如AtomicInteger,通过CAS(comper And Swap)确保操作原子性
加锁
synchronized锁:
1、同步方法,方法加锁,确保线程一个一个执行
2、同步代码块,静态方法中,同步对象是类的class对象、非静态方法中,同步对象是this
public void increment() {// 同步代码块,同一时刻只有一个线程能进入该代码块synchronized (同步对象) {count++;}}ReentrantLock锁:是Java提供的可重入锁,相比synchronized更加灵活。
public void increment() {// 获取锁lock.lock();try {count++;} finally {// 释放锁lock.unlock();}}使用线程安全的集合类:ConcurrentHashMap、CopyOnWriteArrayList、CopyOnWriteSet
线程通信
多个线程在同步的情况下,互相牵制执行
wait、notify、notifyAll,以上只能在同步代码块中使用,调用的对象只能是锁对象
wait和sleep的区别:
wait是object类中的方法,只能等待线程唤醒,等待时可以释放锁
sleep是Thread类中的方法,休眠时间结束后自动唤醒,进入就绪状态,休眠期间不会释放锁,其他线程进不来。
并发编程
前提是多线程场景
多线程优点:在一个进程中,可以有多个线程,同时执行不同的任务,提高程序的响应速度,提高cpu的利用率,同时提高压榨硬件的剩余价值。
多线程存在的问题:多个线程同时访问共享数据(买票、抢购、秒杀等场景)用户同时向后端发送多个请求。多个请求同时访问数据会出现问题,并发编程就是让多个请求并发的执行(在一个时间段内,线程依次的执行)
并发执行:在计算机层面,是指在一个时间段内,多个线程依次执行的意思
并行执行 :在一个节点上,同时执行
并发编程的核心问题
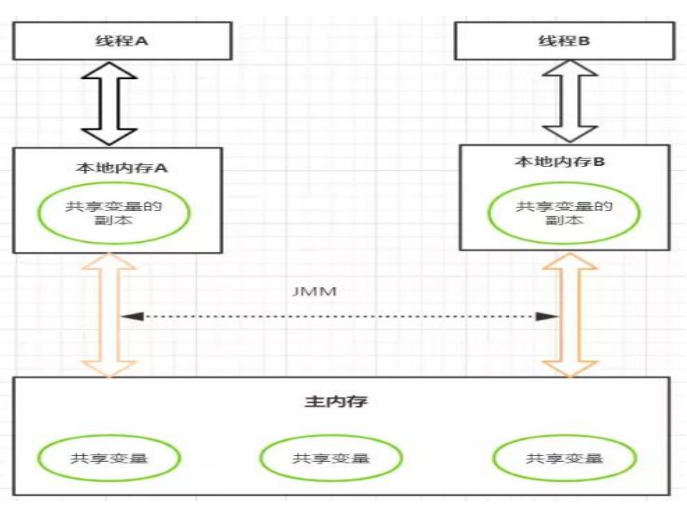
1、不可见性
由于Java内存模型(JMM Java Memory Model)分为主内存和工作内存(缓存区),所有的共享变量存储在主内存中,当线程要对主内存的数据进行操作时,首先要将变量加载到工作内存中才能进行操作,这样就产生了不可见性,当两个线程同时操作一个数据时,一个线程修改了数据,另一个线程是不知到的。
2、乱序性
编译器为了进一步优化,在cpu执行指令是,有的指令需要等待数据的加载,此时会将后面某些指令提前执行,这样指令的顺序就被打乱了,这种就会出现乱序性。
乱序执行也是有基本原则的,两条直接有关系的指令是不会被打乱的。
3、非原子性
操作系统中线程的切换带来非原子性问题。
cpu的执行在指令层面是原子性的,但是在高级语言中,一条语句往往需要被编成成多条指令执行,这样在多线程情况下,切换线程执行时也会造成指令切换,线程切换等导致了非原子性问题。
总结:Java的内存模型导致了不可见性,编译器优化导致了乱序性,前程切换导致了非原子性
volatile关键字
volatile关键字修饰变量,有两个作用:
1、解决不可见性
两个线程同时执行时,一个线程改变了数据,另一个线程是立即可见的
2、解决乱序性
当volatile修饰变量,编译器是不能对其进行重新排序的
如何解决非原子性?
加锁:synchronzied和ReentrantLock加锁解决非原子性
加锁可以解决不可见性和乱序性
原子类
概念:原子类是具有原子性的类,原子性的意思是对于一组操作,要么全部执行成功,要么全部执行失败,不能只有其中某几个执行成功。
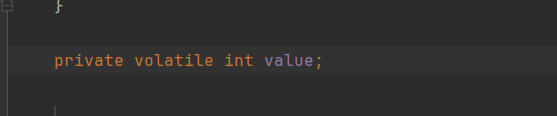
原子类的原子性是通过volatile+CAS实现原子操作的,以AtomicInteger为例子:
AtomicInteger类中的value是volatile关键字修饰的,保证了value的内存可见性,这也为后面的CAS实现提高了基础。
CAS思想(Compare-And-Swap)比较并交换
CAS说是乐观锁的一种实现,他采用的是自旋的思想,是一种轻量级的锁机制。(实际并不是锁,而是实现了的锁效果)
思想:每次判断预期值和内存中的值是不是相同的,如果不相同则说明该内存值已经被其他线程修改了,因此需要拿到改最新值作为预期值,重新判断,而该线程不断的循环判断是否该内存值已经被其他线程修改了,这就是自旋思想。
当一个线程A从内存中读取一个值(期望值),在工作内存中进行改变,往主内存写之前先从内存中读取这个值进行对比,如果第一次拿到的值(期望值)和主内存中读取的值不一样,说明其他线程已经修改了该值,线程A需要重新操作值,再次重复之前的操作,如果相同,线程A将更新后的值写到主内存中。
CAS适合在线程数较少的情况下,由于不加锁,线程不会阻塞,所有线程一直尝试对变量进行操作,效率高于加锁。但是线程数量加多时,所有线程一直自旋,尝试操作,cpu工作量会增大。
CAS可能出现ABA问题:
若一个变量的值从 A 变为 B,再从 B 变回 A,此时 CAS 操作会认为该变量的值没有发生变化,但实际上它已经经历了变化。在 Java 中,可以使用 AtomicStampedReference 类来解决 ABA 问题。
AtomicStampedReference 类是带版本号的原子类来区分是否值发生了改变
AtomicStampedReference stampedReference = new AtomicStampedReference(100, 0);//0就是版本号锁的分类
首先Java中有很多锁的名词,这些并不是全是指锁,有的指锁的特性,有的指锁的设计,有的指锁的状态。
1、乐观锁/悲观锁
乐观锁:认为在多线程操作时,不加锁不会出现问题的,例如原子类:采用volatile+CAS的思想,称为乐观锁。
悲观锁:认为在多线程操作时,不加锁是会出现问题的,是一种加锁的实现。例如synchronized和ReentrantLock都属于锁,称为悲观锁。
2、可重入锁
可重入锁又称为递归锁,当一个线程进入到外层方法获得锁时,仍然可以进入到内层方法,而且外层和内层方法使用的是同一把锁
public synchronized void setA(){System.out.println("进入到外层方法");setB();//如果不可重入setB就不会被执行}public synchronized void setB(){System.out.println("进入到内层方法");}如果不可重入,就会导致无法进入内层方法,就会导致死锁。
3、读写锁
ReentrantReadWriteLock类,实现读写锁,有读锁也有写锁
读读不互斥:多个线程都是进入读锁,此时没有其他线程进入写锁,那么多个线程同时进入到读锁区域(提高了读的效率),一旦有线程进行写操作,那么读操作就不能进入。
读写互斥、写写互斥
public class RRW{private int data;private ReentrantReadWriteLock lock=new ReentrantReadWriteLock();public void set(int data) throws InterruptedException {lock.writeLock().lock();//获取写锁System.out.println(Thread.currentThread().getName()+"获取写锁");try {Thread.sleep(2000);System.out.println(Thread.currentThread().getName()+"准备写入数据");this.data=data;System.out.println(Thread.currentThread().getName()+"写入"+this.data);}finally {System.out.println(Thread.currentThread().getName()+"释放写锁");lock.writeLock().unlock();//关闭写锁}}public void get() throws InterruptedException {lock.readLock().lock();//获取读锁System.out.println(Thread.currentThread().getName()+"获取读锁");try {Thread.sleep(2000);System.out.println(Thread.currentThread().getName()+"准备读数据");System.out.println(Thread.currentThread().getName()+"读数据"+this.data);}finally {System.out.println(Thread.currentThread().getName()+"释放读锁");lock.readLock().unlock();//关闭读锁}}}适合多个线程读,少量线程写的场景,提高了吞吐量和并发性
4、共享锁/独占锁
读写锁中的读锁就是共享锁,在没有写的操作下,可以有多个线程进入到读锁代码块
读写锁中的写锁就是一个独占锁,synchronized和ReentrantLock都属于独占锁,一次只允许一个线程进入。
5、分段锁
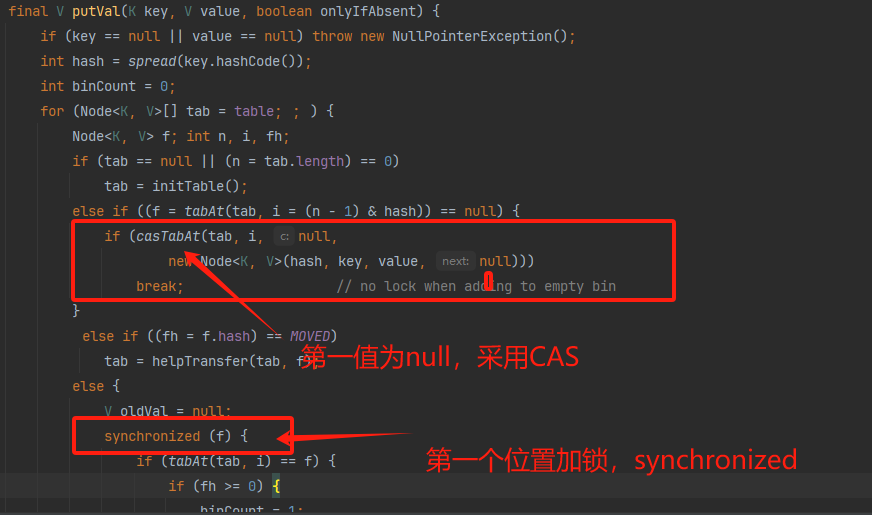
也不是一种实际的锁,是一种锁的实现思想,用于将数据分段,给每个分段都会单独加一个锁,将锁的粒度细化,提高效率。
例如:ConcurrentHashMap的实现,由于ConcurrentHashMap的底层哈希表有16个空间,可以利用每一个位置上的第一个节点当作锁,这样就可以由不同的线程操作不同的位置,只是同一个位置不可以有多个线程操作,如果第一个位置位null时,就采用CAS机制
6、自旋锁
自旋锁也不是一种实际的锁,是通过不断自旋重试的方式抢锁,在低并发的场景下效率较高。
线程尝试不断的获取锁,当第一次取不到时,线程不阻塞,会尝试继续获取锁,有可能后面尝试几次后,有其他线程释放锁了,此时可以获取锁,当尝试获取一定次数后(默认是10次,可以通过参数设置),仍然没有获取到锁,就会进入阻塞状态。
synchronized就是一种自旋锁,在并发量低的情况下就适合自旋锁
自旋是比较消耗cpu的,因为需要不断的自旋循环重试,不会释放cpu的
优点
- 减少上下文切换开销:由于线程在等待锁的过程中不会进入阻塞状态,避免了线程上下文切换带来的时间和资源开销,在锁被持有的时间较短时,性能表现较好。
- 响应速度快:一旦锁被释放,自旋的线程可以立即获得锁并继续执行,无需等待操作系统的调度,响应速度更快。
缺点
- CPU 资源浪费:在自旋等待期间,线程会持续占用 CPU 资源进行无意义的循环检查,当锁被持有的时间较长时,会导致大量的 CPU 资源被浪费,降低系统的整体性能。
- 优先级反转问题:如果低优先级的线程持有锁,高优先级的线程需要等待低优先级线程释放锁,这可能导致高优先级线程的任务无法及时执行,出现优先级反转的情况。
-
使用场景
自旋锁适用于以下场景:
- 锁持有时间短:当临界区代码执行时间较短,锁被持有的时间也相应较短时,使用自旋锁可以避免线程上下文切换的开销,提高性能。
- 多核处理器:在多核处理器系统中,多个线程可以同时运行,一个线程自旋等待时,其他线程可以继续在其他 CPU 核心上执行,从而减少了等待时间。
7、公平锁和非公平锁
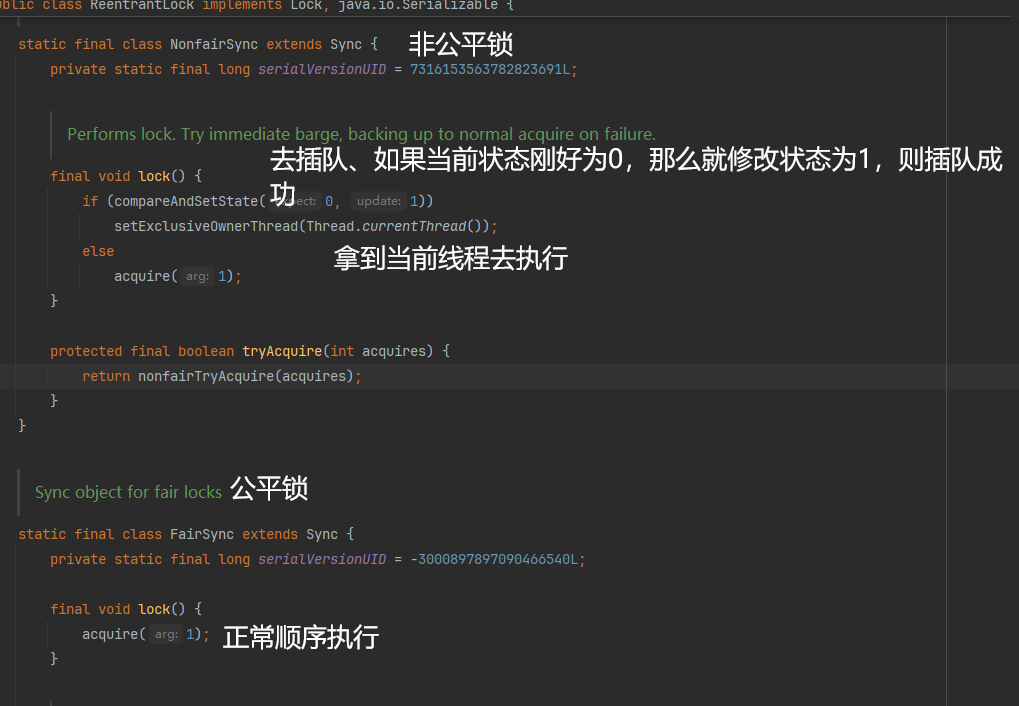
公平锁:可以做到按照请求顺序分配锁,可以进行排队,ReentrantLock底层两种实现,默认是非公平的,也可以通过AQS队列实现公平。

非公平锁:就是不分先来后到,谁先抢到谁先执行,synchronized就是非公平锁
四种锁状态
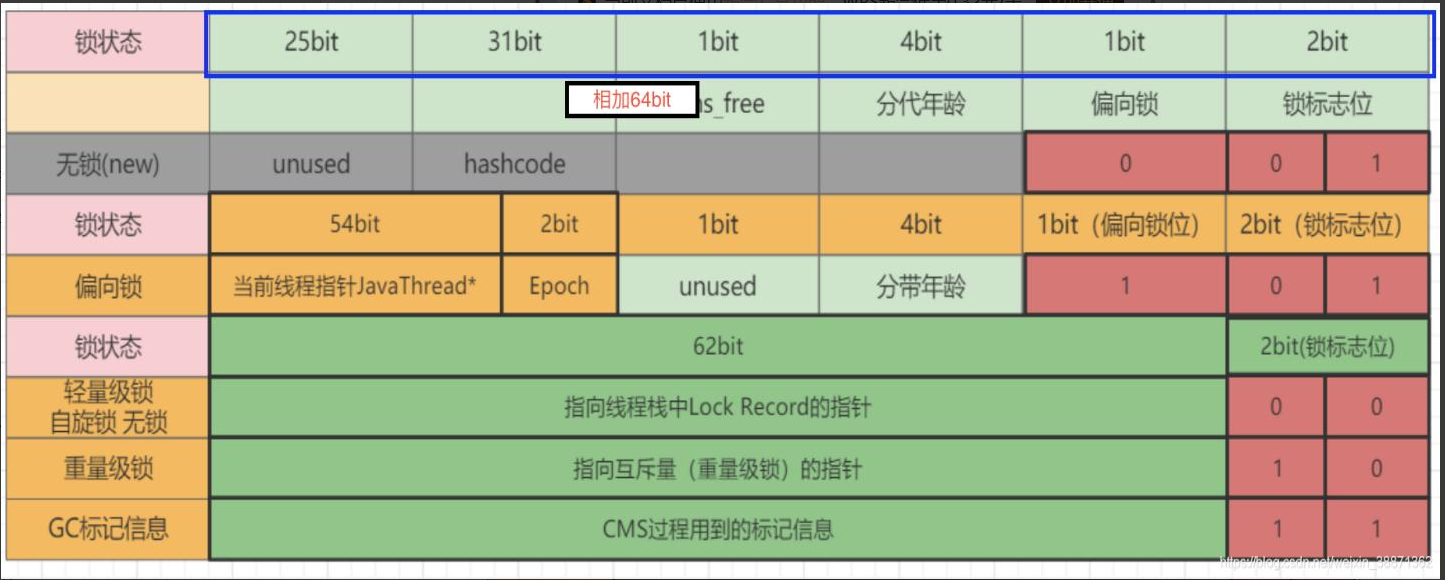
Java中为了synchronized进行优化,提供了四种锁状态(这四种锁状态都不是Java语言中的锁,而是JVM为了提高锁的获取和释放效率,而做的优化),在synchronized锁实现时,在同步对象可以记录锁的状态,锁的状态是通过对象监视器在对象头中的字段来表明的。
1、无锁状态:就是本来的状态
2、偏向锁状态:一段同步代码块一直有一个线程执行,那么在锁对象中记录下线程信息,可以直接获得锁。
3、轻量级锁状态:当锁状态为偏向锁时,还有其他线程访问,锁状态升级为轻量级锁,线程不阻塞,采用自旋方式获取锁。
4、重量级锁状态:当锁状态为轻量级锁时,如果有大量的线程到来,大量的线程自旋,锁状态升级为重量级锁,自旋的线程会进入阻塞状态,由操作系统去调度。
对象结构
在Hotspot虚拟机中,对象在内存中的布局为三块区域:对象头、实例数据、对其填充;对象头是实现synchronized的锁状态的基础,synchronizd的使用,锁对象存储在对象投中,是轻量级锁和偏向锁的关键。
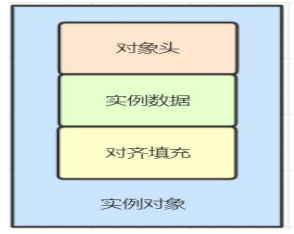
对象头中一块区域为Mark Word,用于存储对象自身运行时的数据,如:HashCode、GC分代年龄、锁状态标志、线程持有的锁、偏向锁的ID等等。
synchronized锁实现
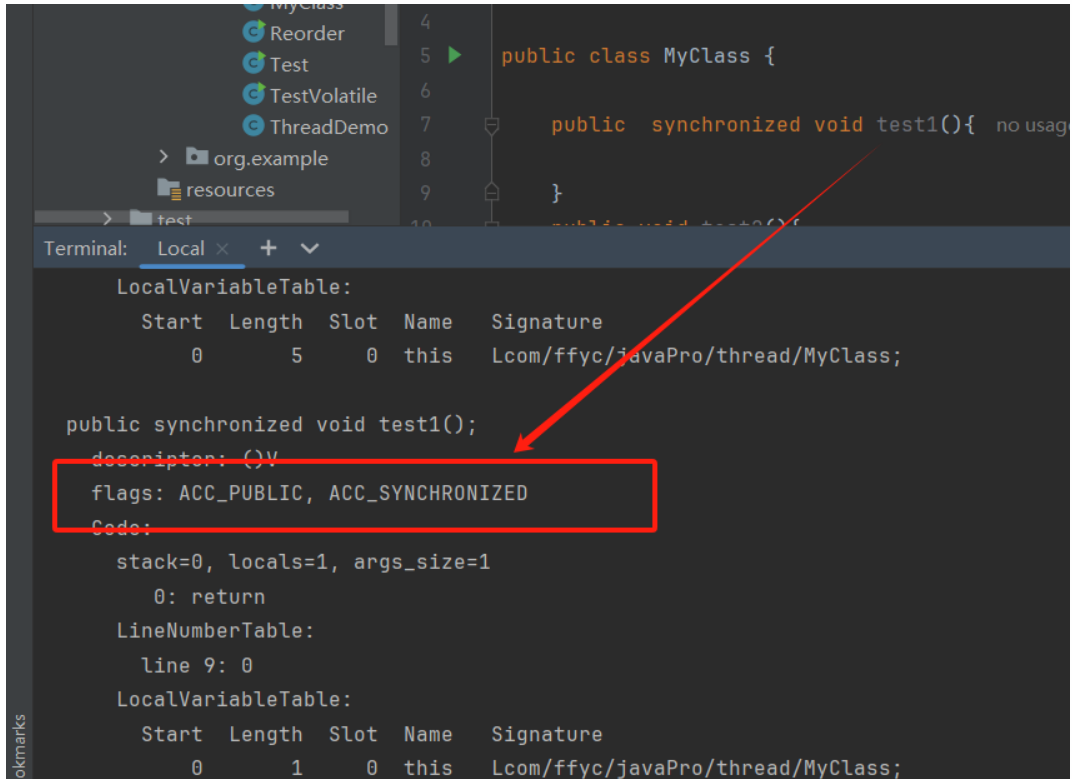
synchronized是一个关键字,实现同步,还需要我们提供一个锁同步对象,记录锁状态,记录线程信息。
synchronized锁实现是隐式的,可以修饰方法,也可以修饰代码块,底层实现是依赖字节码指令的。
修饰方法时,会在方法上添加一个ACC_SYNCHRONIZED标志,依赖底层的监视器实现锁的控制
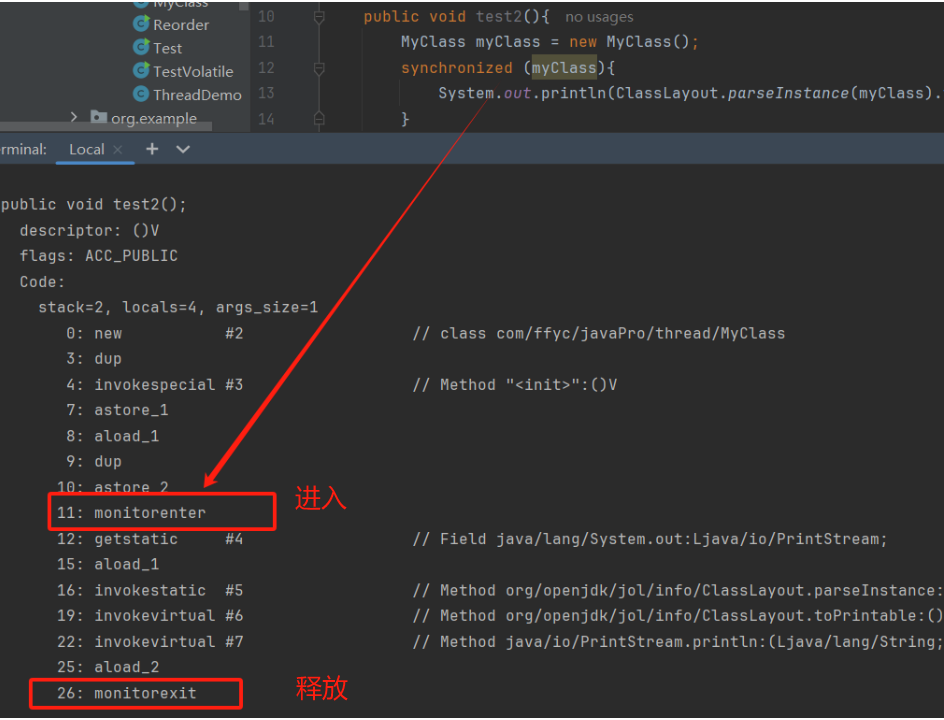
修饰代码快时,为同步代码块添加一个monitorenter指令进行监视,执行结束,执行monitorenxit指令,有线程进入,计数器加1,线程执行结束计数器减1
AQS
AQS的全称:AbstractQueuedSynchronizer,在java.util.concurrent.locks包下,是实现线程同步的框架。
抽象同步队列,是并发编程中许多实现类的基础,例如:ReentrantLock底层就用了AQS
AQS类中维护了一个状态, private volatile int state;
当有线程获取时,首先获取状态变量,以ReentrantLock为例,
if state==0 当前线程可进入 state++,大于 0 表示锁已被持有,且重入次数为 state 的值。
线程可以通过 CAS(Compare-And-Swap)操作来原子性地修改 state 的值,
以此来实现对共享资源的控制。还有一个内部类 节点static final class Node{//重点信息volatile node prev;volatile Node next;volatile Thread thread;//存储等待的线程}private transient volatile Node head;队列头private transient volatile Node tail;队列尾维护了一个双向链表FIFO 双向队列:当多个线程竞争同一个同步资源时,
那些没有获取到资源的线程会被封装成一个节点(Node)加入到这个队列中进行等待。
队列中的线程会按照先进先出的顺序依次尝试获取资源ReentrantLock底层实现
ReentrantLock是Java.util.concurrent.locks包下的类,实现了Lock接口,比synchronized加锁更加灵活
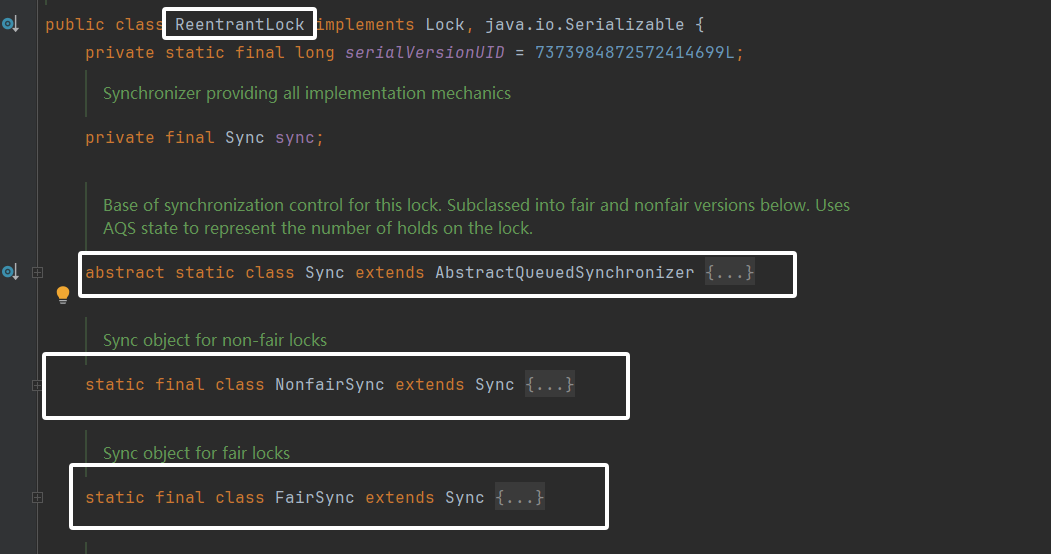
类结构
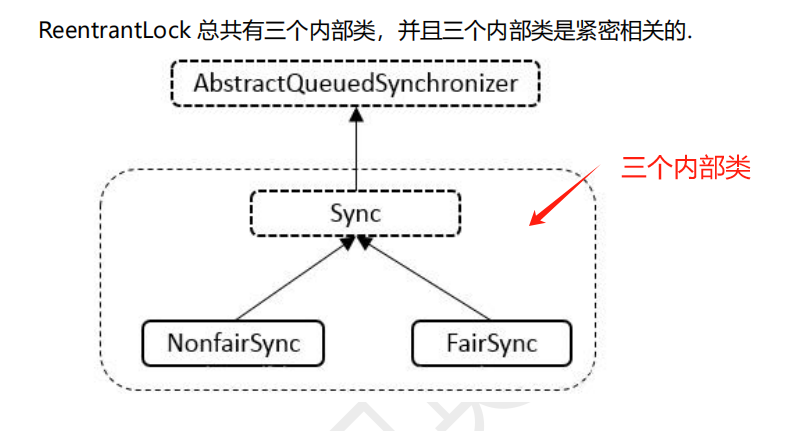 ReentrantLock底层实现两种方式:
ReentrantLock底层实现两种方式:
1、默认是非公平锁实现。2、通过参数控制实现公平锁
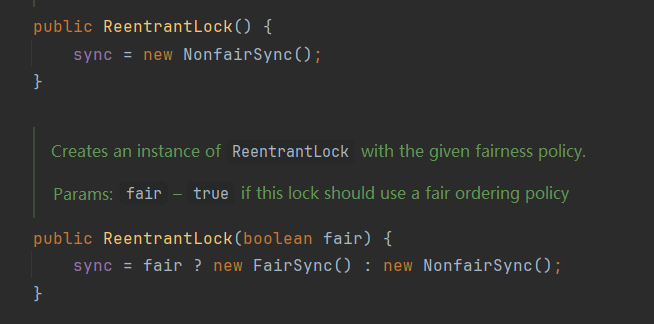
当线程刚进去时,先去插队,如果插队不成功,则走正常流程排队取锁
JUC常用类
前提复习HashMap:
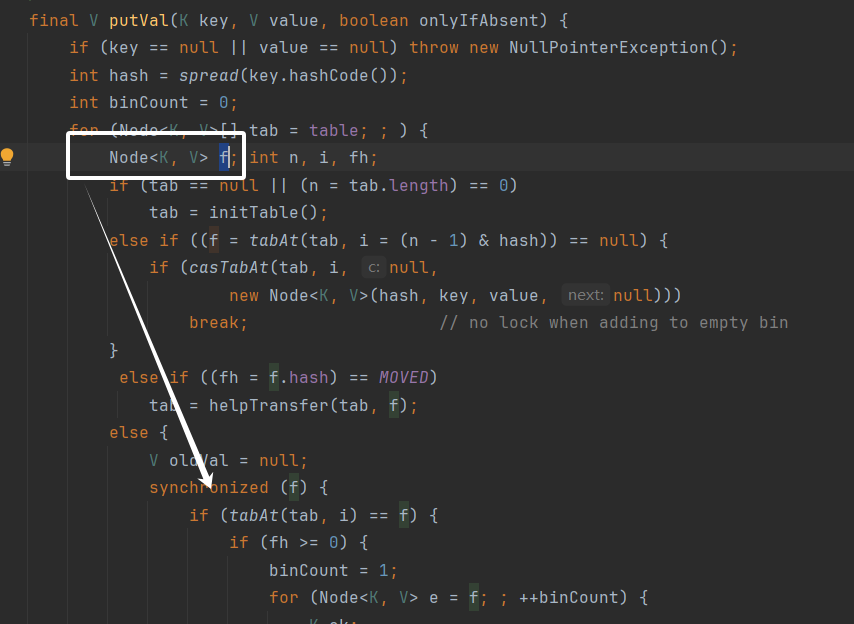
HashMap是双列集合,实现了Map接口,是键值对存储,键不能重复,值可以重复,只能存储一个为null的键,键是无序的,是线程不安全的,多线程操作会抛出异常的(ConcurrentModificationException,并发修改异常) ,判断键是否重复:hashcode()和equails()
数据结构:
1、哈希表,默认长度是16。
2、链表长度>8,哈希表长度<64,哈希表扩容(哈希表长度为原来的2倍,哈希表的负载因子为0.75),哈希表长度>64,转为红黑树。
3、红黑树
复习HashTable:
线程安全的,但是是给方法上加了synchronized,效率低。
ConcurrentHashMap
线程安全的,但是也是HashTable的线程安全实现是不同的。其没有给方法上加锁,而是给哈希表的每一个位置加锁,将键的粒度细化,提高了锁的并发效率。
如何细化锁的?
不是专门的分段锁,而是采用每一个位置上的第一个节点Node对象作为锁对象
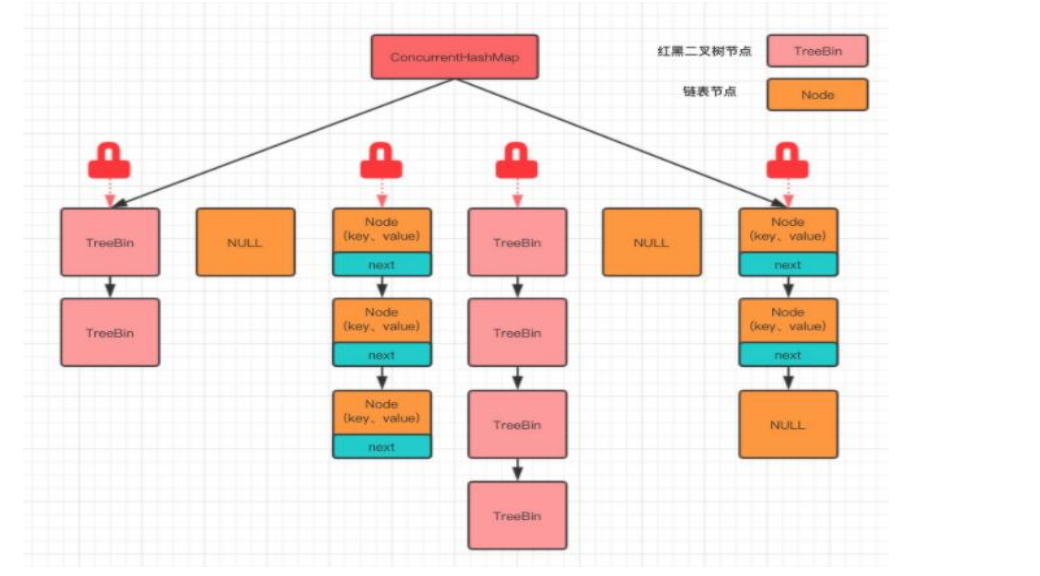
使用CAS+synchronized实现线程安全:当哈希表上还没有Node对象是,此时有多个线程操作,就采用CAS机制进行比较判断,如果某个位置上已经有了Node对象,那么直接使用node对象作为键即可。
和HashTable有一个共同点都不支持 键null和值为null
不能put null是因为,无法分辨key是否没有找到为null还是有key值为null,这在多线程里面是含糊不清的,所以就不让为null。
二者都是支持并发的,这样会有一个问题,当通过get(key)获取对应的value是,如果获取到的是null时,无法判断是put(key,value)时为null,还是就就key就没有做个映射。
CopyOnWriteArrayList
ArrayList:数组链表,线程不安全的
Vevtor:数据链表,线程安全的,是给方法加锁的synchronized,效率低,同时也给get()方法加了锁。
CopyOnWriteArrayList:
将读写效率进一步提升,读操作get()是不加锁的,只给可以改变数据的方法(add、set、remove)加锁(通过ReentrantLock加锁),而且为写操作时不影响读操作,操作前将数组进行复制,在副本上进行操作,写完之后将副本重新赋值到原数组中,所以到底只有写写是互斥的,读写、读读不互斥,适用于读操作多,写操作少场景。
CopyOnWriteArraySet
CopyOnWriteArraySet是基于CopyOnWriteArrayList实现的,不能存储重复数据
辅助类CountDownLatch
CountDownLatch允许一个线程等待其他线程执行完毕之后在执行。底层实现是通过AQS来完成的,创建CountDownLatch对象时指定初始值是要等待线程的数量,每当一个线程执行完毕之后,AQS内部的sate就-1,当sate=0时,表示所有线程都执行完毕,然后在闭锁上等待的线程就可以恢复工作了。
池的概念
字符串常量池
String s1="abc";
String s2="abc";
s1==s2 // trueInteger自动装箱,缓存了-128~127
Integer i1=100;
Integer i2=100;
System.out.println( i1==i2);// true数据库连接池
阿里巴巴Druid数据库连接池
帮我们缓存一定数量的链接对象,放在池子里用完还会到池子
中,减少了对象的频繁创建和销毁的实际开销
线程池
为了减少频繁的创建和销毁线程,jdk5开始引入线程池,建议使用ThreadPoolExecutor类来创建线程,提高效率
ThreadPoolExecutor类
重点是构造器
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler) 7个参数
corePoolSize:核心线程池中的数量(初始化的数量)5
maximumPoolSize:线程池的最大数量10(包含核心线程池的),(再次创建5个)
keepAliveTime:空闲线程存活的时间,当核心线程池中的线程足以应付任务时,非核心线程池的线程在指定空闲时间到期后就会销毁。
unit:时间单位
workQueue:5 等待队列,当核心线程池中的线程都在使用时,会先将等待的任务放到队列中,如果队列满了,才会创建新的线程(非核心线程池中的线程)
threadFactory:线程工厂,用来创建线程池的线程。
handler:拒绝理任务时的策略,有四种拒绝策略
线程池的工作流程:
当大量的任务到来时,先判断核心线程池中的线程是否都忙着,有空闲的,直接让核心线程中的线程执行任务,没有空闲的 ,判断等待队列是否已满,如果没有满,则加入等待队列,如果已满,判断非核心线程池中的线程是否都忙着,如果有空闲的,没满,交由非核心线程池中的线程执行,如果非核心线程池也满了,那么就是要拒绝策略处理。
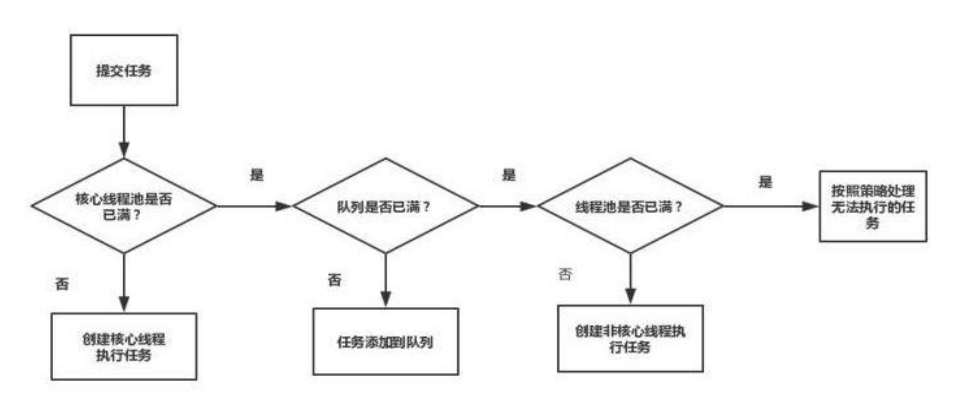
线程池中的四拒绝策略
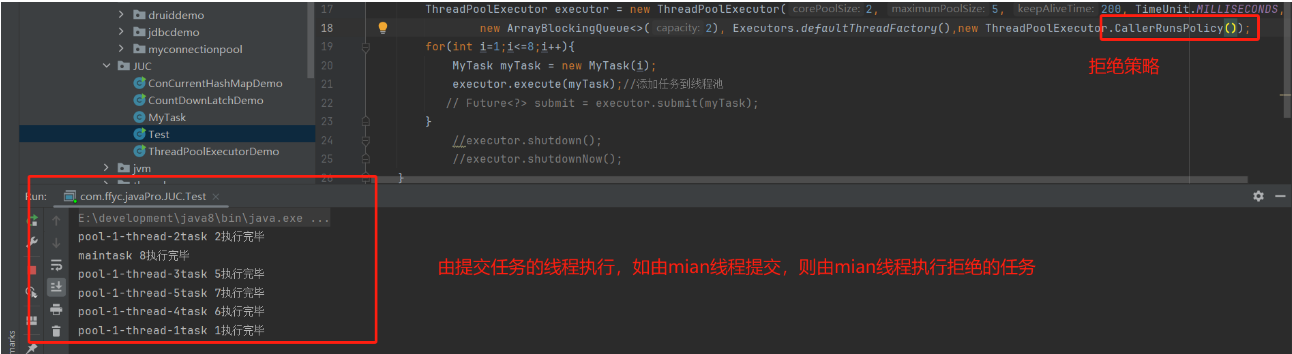
1、AbortPolicy 抛异常策略

2、CallerRunsPolicy:由提交任务的线程执行,例如在mian线程提交,则由mian线程执行拒绝的任务
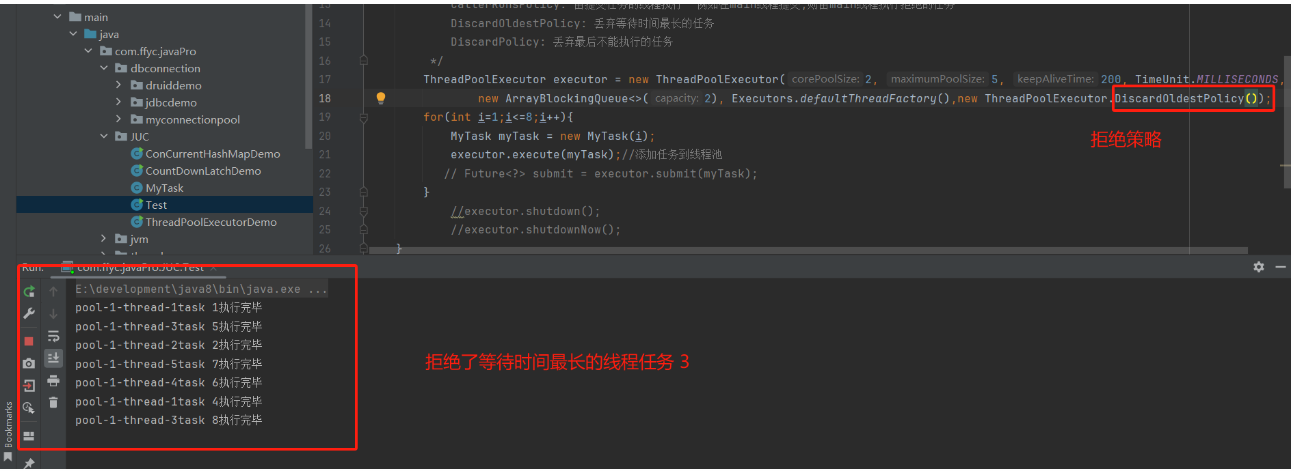
3、DiscardOldestPolicy:丢弃等待时间最长的任务
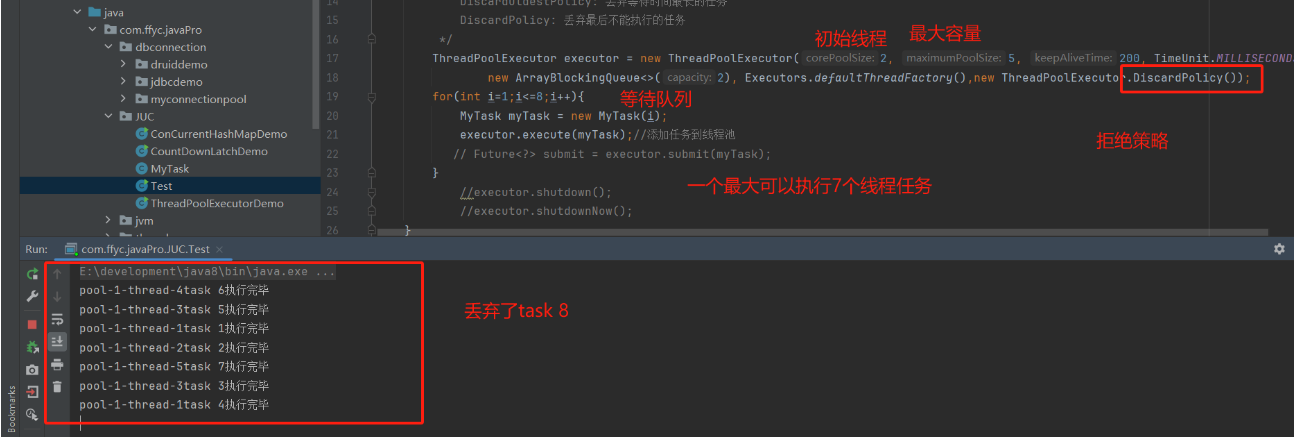
4、DiscardPolicy:丢弃最后来的任务。
关闭线程池
executor.shutdown();//不在接收新的任务,
会把线程池中还有等待队列中已有的任务执行完,在停止
executor.shutdownNow();//立即停止,队列中等待的任务不在执行线程池中的等待队列
ArrayBlockingQueue:是一个用数组实现的有界阻塞队列,创建时必须设置长度,按FIFO排序量。
LinkedBlockingQueue:基于链表结构的阻塞队列,按FIFO排序任务,容量可以选择进行设置,不设置是一个最大长度为Integer.MAX.VLAUE。
ThreadLocal
本地线程变量,为每一个线程提供一个变量副本,只在当前线程中使用,相互是隔离的。
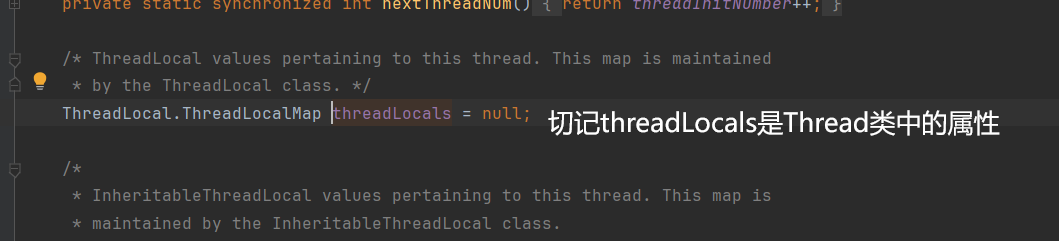
底层结构:
为每一个线程对象创建ThreadLocalMap对象,赋给Thread类中的threadLocals,用threadLocals存储每个线程的变量。
set()方法


get()方法


对象引用
1、强引用
Object obj=new Object();
obj.hashCode();
obj=null;
对象如果有强引用关联那么肯定是不能被回收的
2、软引用
Object o1=new Object();
SoftReference<Object> softReference=new SoftReference<Object>(o1);
被softReference类包裹的对象,当内存充足时,不会被回收,当内存不足时,即便有引用指向,也会被回收。
3、弱引用
被WeakReference类包裹的对象,只要发生垃圾回收,该对象都会被回收掉,不管内存是否充足
Object o1=new Object();
WeakReference<Object> weakReference=new WeakReference<Object>(o1);
ThreadLocal 被弱引用管理 static class Entry extends WeakReference<ThreadLocal<?>>(){}
当发生垃圾回收时,被回收掉,value还和外界保持引用关系,不能被回收掉
4、虚引用
被PhantomReference类包裹的对象,随时可以被回收,通过虚引用对象跟踪对象回收的状态
ThreadLocal内存泄漏
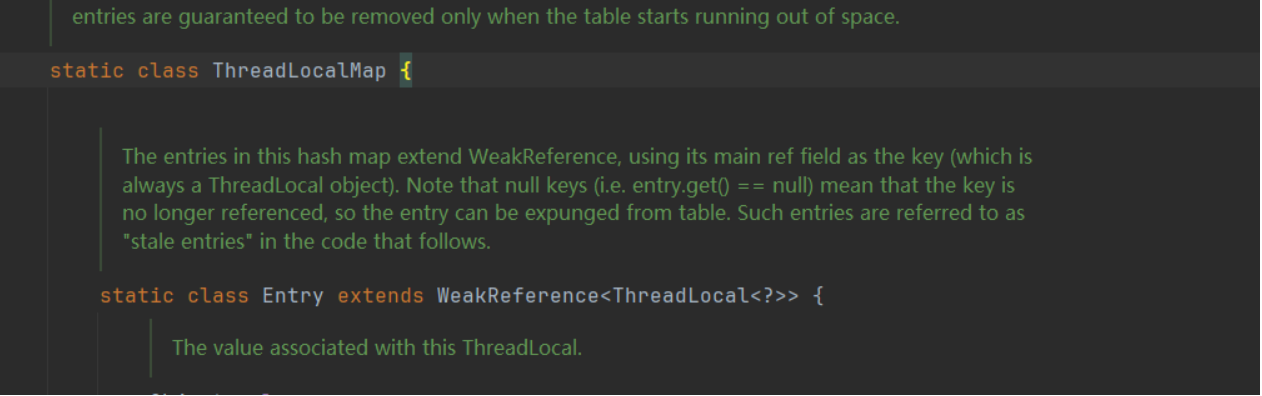
readLocalMap 使用 ThreadLocal 的弱引用作为 key,如果一个 ThreadLocal不存在外部强引用时,Key(ThreadLocal)势必会被 GC 回收,这样就会导致ThreadLocalMap 中 key 为 null, 而 value 还存在着强引用,只有 thead 线程退出以后,value 的强引用链条才会断掉。但如果当前线程再迟迟不结束的话,这些 key 为 null 的 Entry 的 value 就会一直存在一条强引用链:
Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value永远无法回收,造成内存泄漏。
ThreadLocal 正确的使用方法
每次使用完 ThreadLocal 都调用它的 remove()方法清除数据。






