前言
为什么海量数据需要分布式存储技术?
文件过大时,单台服务器无法承担,要靠数量来解决。数量的提升带来的是网络传输、磁盘读写、CPU、内存等各方面的提升。
众多的服务器一起工作,如何保证高效且不出错 ?
大数据体系中,分布式的调度有2类架构模式:去中心化模式、中心化模式
大数据框架大多是:中心化模式:一个中心节点(服务器)来统筹其它服务器的工作,统一指挥,统一调派。 也称:一主多从模式,简称主从模式(Master And Slaves)
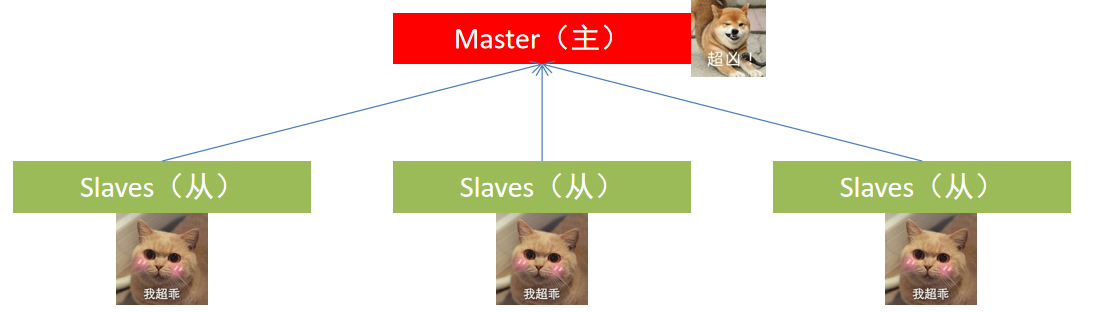
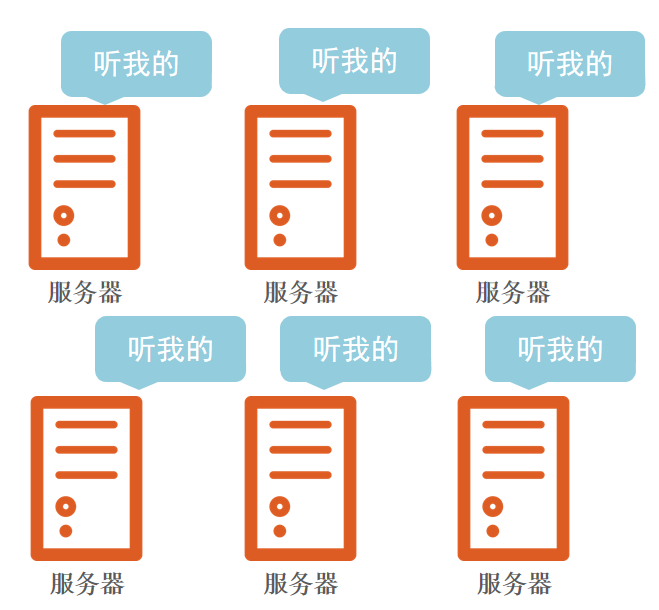
去中心化模式:没有明确的中心。 众多服务器之间协调工作。
HDFS的简介
- Hadoop三大组件(HDFS、MapReduce、YARN)之一
- 全称:Hadoop Distributed File System(Hadoop 分布式文件系统)
- 是Hadoop技术栈内的分布式数据存储解决方案
- 可以在多台服务器上构建集群,存储海量数据
- 典型的主从模式架构
HDFS的基础架构
| 主角色:NameNode | 主角色的辅助: SecondaryNameNode |
| 从角色:DataNode |
| NameNode | SecondaryNameNode | DataNode |
|
|
|
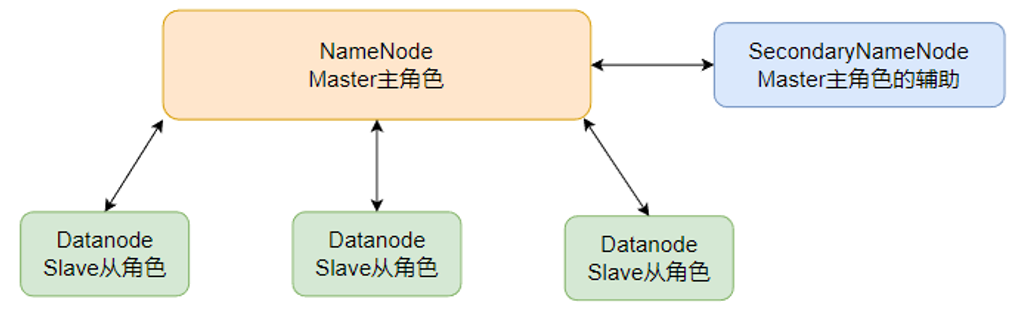
一个典型的HDFS集群,就是由1个DataNode加若干(至少一个)DataNode组成
在VMware 虚拟机中部署HDFS 集群
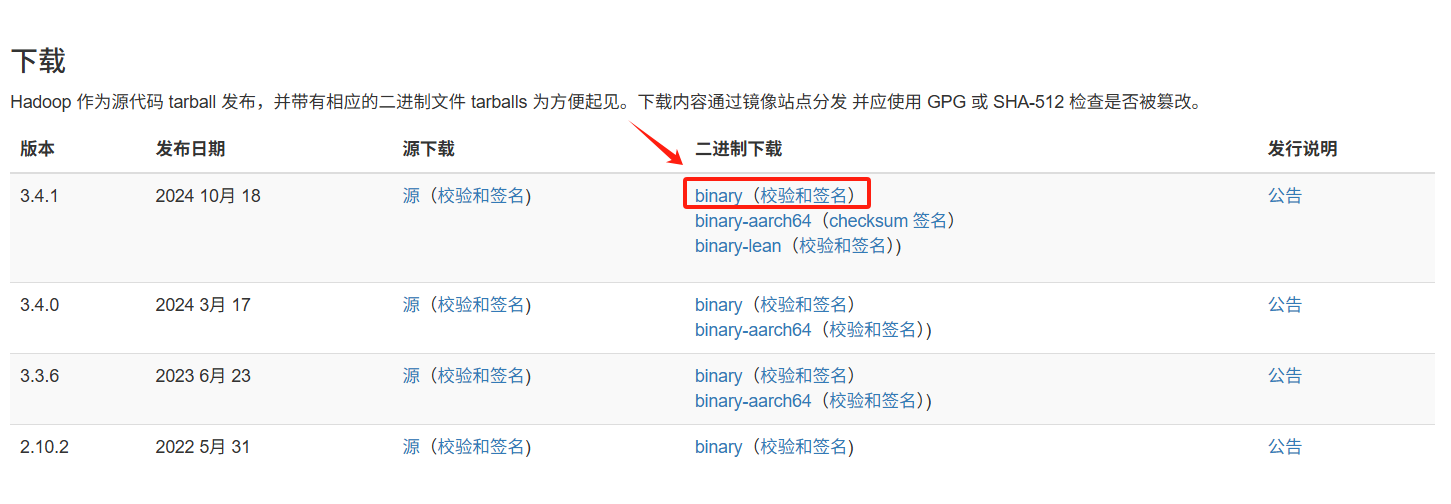
安装包下载
下载地址:Apache Hadoop
集群规划
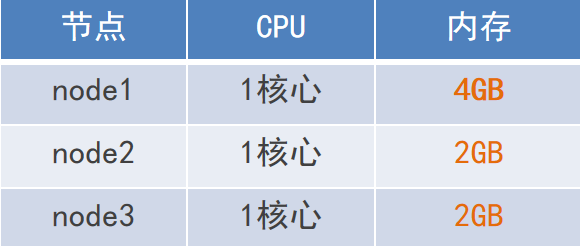
第一步:VMware 准备3台虚拟机。硬件配置如下:
服务规划

前言
什么是分布式计算?
分布式计算:多台服务器协同工作,共同完成一个计算任务
分布式计算常见的 2 种工作模式
分散->汇总 (MapReduce是这种模式)
中心调度->步骤执行 (大数据体系的Spark、Flink是这种模式)


全生态接入系统技术白皮书)



